
PHP爬虫框架Beanbun
Beanbun 是用 PHP 编写的多进程网络爬虫框架,具有良好的开放性、高可扩展性。
手册文档:http://beanbun.org/
支持守护进程与普通两种模式,守护模式在Linux环境命令运行,普通可以直接访问运行
如:普通模式直接访问,创建一个文件 start.php,包含以下内容
<?php
require_once(__DIR__ . "/vendor/autoload.php");
use BeanbunBeanbun;
$beanbun = new Beanbun;
$beanbun->seed = [
"http://www.950d.com/",
"http://www.950d.com/list-1.html",
"http://www.950d.com/list-2.html",
];
$beanbun->afterDownloadPage = function($beanbun) {
file_put_contents(__DIR__ . "/" . md5($beanbun->url), $beanbun->page);
};
$beanbun->start();

重点介绍多进程模式,支持多进程,可以让爬虫一直执行
普通模式下不依赖队列,而守护进程模式需要另外开启队列(内存队列、Redis
队列等),但拥有更多的功能,如可以自动发现页面中的链接加入队列,循环爬取。
首先建立一个队列文件
queue.php,写入下列内容
<?php require_once(__DIR__ . "/vendor/autoload.php"); // 启动队列 BeanbunQueueMemoryQueue::server();
启动 start.php 之前,先命令行启动queue.php,即 先启动队列进程,再启动爬虫。
$ php queue.php start
$ php start.php start这次爬虫以我csnd博客为例子,爬虫抓取所有博客标题
start.php 文件如下:
<?php
use BeanbunBeanbun;
use BeanbunLibHelper;
require_once(__DIR__ . "/vendor/autoload.php");
$beanbun = new Beanbun;
$beanbun->name = "blog"; //爬虫名称
$beanbun->count = 5; //爬虫进程数
$beanbun->seed = "http://blog.csdn.net/a519395243"; //爬虫地址
$beanbun->max = 20; //最大抓取网页数量
$beanbun->logFile = __DIR__ . "/qiubai_access.log"; //爬虫日志文件路径
$beanbun->afterDownloadPage = function($beanbun) { //爬取网页后执行此回调。
$aa=$beanbun->page;
$pa = "%<span class="link_title"><a href="/a519395243/article/details/.*?>(.*?)</a>s+</span>%si";
preg_match_all($pa,$aa,$match); //简单正则处理,选出文章标题
print_r($match[1]); //打印在日志上
};
$beanbun->start();
linux 命令行先启动 内存队列 再 启动爬虫

执行成功后,查看日记 ,成功爬虫抓取到自己的所有文章标题
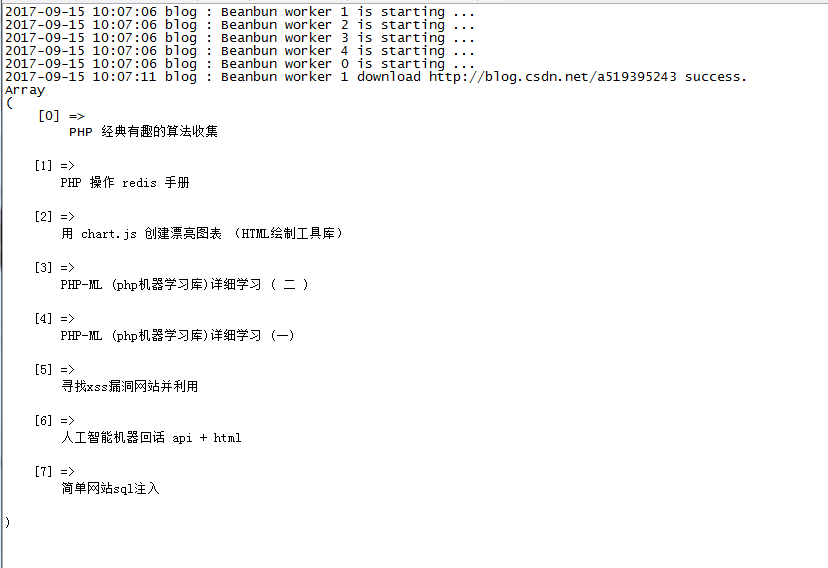
关闭爬虫
$ php queue.php stop
$ php start.php stop还可以设置 header 或者ua头,模拟人真实访问
$beanbun->userAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36";
$beanbun->options["headers"] = [ "Accept"=>"image/webp,image/*,*/*;q=0.8", "Accept-Encoding"=>"gzip, deflate, sdch, br", "Accept-Language"=>"zh-CN,zh;q=0.8", "Connection"=>"keep-alive", "Host":"hm.baidu.com", "Referer":"http://blog.csdn.net/a519395243" "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36" ]
抓取csdn博客不需要登录,如碰见需要登录的,可加上Cookie,模拟登录爬从
抓取网页后,可转化为JSON备用
$beanbun->afterDownloadPage = function($beanbun) {
$beanbun->page = json_decode($beanbun->page, true);
}或者存进数据库
use BeanbunLibDb;
Db::$config = [
"zhihu" => [
"server" => "127.0.0.1",
"port" => "3306",
"username" => "blog",
"password" => "xxxxxx",
"database_name" => "blog",
"database_type" => "mysql",
"charset" => "utf8",
]
];//插入数据库 ,其他请看手册
Db::instance("blog")->insert("account", [
"user_name" => "D丶",
"email" => "XXX",
"title" => "XXXX"
]);
Beanbun还有很多扩展,详细看手册
声明:该文观点仅代表作者本人,牛骨文系教育信息发布平台,牛骨文仅提供信息存储空间服务。
