
Python3,通过re模块中的sub()和findall()2个方法提升爬虫提取数据的效率
直接上Demo:
测试数据 - HTML:
"""<div id="songs-list">" "<h2 class="title">各种汽车</h2>" "<p class="introduction">" "各种汽车列表" "</p>" "<ul id="list" class="list-group">" "<li data-view="2">奥迪TT</li>" "<li data-view="7">" "<a href="/2.png" type="大众">CC</a>" "</li>" "<li data-view="4" class="active">" "<a href="/3.png" type="宝马">Mini</a>" "</li>" "<li data-view="6"><a href="/4.png" type="奥迪">Q7</a></li>" "<li data-view="5"><a href="/5.png" type="吉利">金刚</a></li>" "<li data-view="5">" "<a href="/6.png" type="大众"><i class="fa fa-user"></i>速腾</a>" "</li>" "</ul>" "</div>"""
HTML结构分析,
思路1,若想要获取每类汽车下面的具体汽车名字,python需要去解析HTML中的节点,有的汽车名,
1。裸露在"<li></li>"标签下,
2。有的在"<li><a></a></li>"标签下,
通过上面分析,我们构造的正则需要匹配上面2种情况,如下:
"<li.*?>s*?(<a.*?>)?(w+)(</a>)?s*?</li>"
用于匹配HTML中所有标签:"<a></a>" ,
"<a.*?>|</a>"
"<li.*?>(w+)</li>"
测试Python代码:
import re
import time
def reTest1(str2):
"""
比较re模块下findall()
与findall()+sub()提取页面数据效率和复杂程度
"""
#匹配规则
part = r"<li.*?>s*?(<a.*?>)?(w+)(</a>)?s*?</li>"
#实际操作页面时,re.S,使通配符可以匹配换行符
ret = re.findall(part, str2, re.S)
for i in ret:
print(i[1])
def reTest2(str2):
"""
比较re模块下findall()
与findall()+sub()提取页面数据效率和复杂程度
"""
#匹配规则
part = r"<li.*?>s*?(<a.*?>)?(w+)(</a>)?s*?</li>"
#想法:通过re模块sub()方法去掉标签:<a></a>
#sub(RegExp, NewString, oldString, args)
#RegExp: 匹配规则
#NewString: 想要要替换的字符串
#oldString: 原始字符串
#args: re.S ...
subStr = re.sub("<a.*?>|</a>", "", str2, re.S)
#实际操作页面时,re.S,使通配符可以匹配换行符
ret = re.findall("<li.*?>(w+)</li>", subStr, re.S)
for i in ret:
print(i)
if __name__ == "__main__":
str2 = (""""<div id="Car-list">"
"<h2 class="title">各种汽车</h2>"
"<p class="introduction">"
"各种汽车列表"
"</p>"
"<ul id="list" class="list-group">"
"<li data-view="2">奥迪TT</li>"
"<li data-view="7">"
"<a href="/2.png" type="大众">CC</a>"
"</li>"
"<li data-view="4" class="active">"
"<a href="/3.png" type="宝马">Mini</a>"
"</li>"
"<li data-view="6"><a href="/4.png" type="奥迪">Q7</a></li>"
"<li data-view="5"><a href="/5.png" type="吉利">金刚</a></li>"
"<li data-view="5">"
"<a href="/6.png" type="大众"><i class="fa fa-user"></i>速腾</a>"
"</li>"
"</ul>"
"</div>"""")
#测试1:find()
start1 = time.time()
reTest1(str2)
end1 = time.time()
print("*"*50)
#测试2,find()+sub()
start2 = time.time()
reTest2(str2)
end2 = time.time()
print("*"*50)
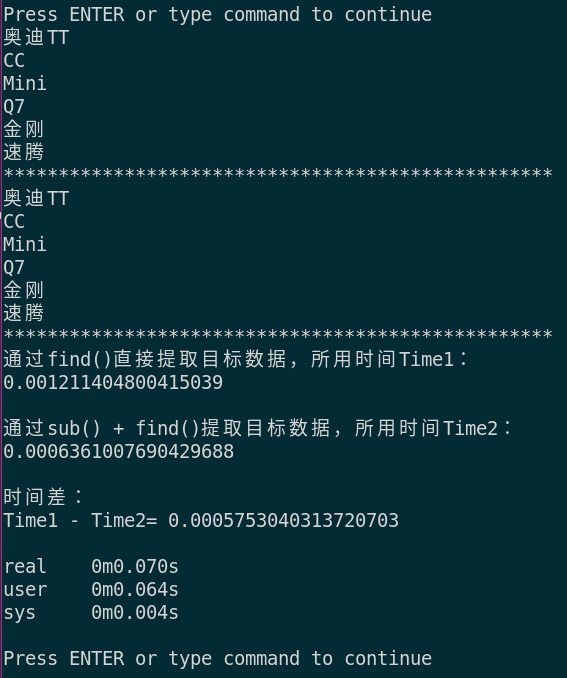
print("通过find()直接提取目标数据,所用时间Time1:")
print(end1 - start1)
print("")
print("通过sub() + find()提取目标数据,所用时间Time2:")
print(end2 - start2)
print("")
print("时间差:")
print("Time1 - Time2=", (end1-start1)-(end2-start2))
测试结果:
总结:
测试结果中,很明显,思路2比思路1提取数据效率明显高,re模块中各种方法组合一起有奇效
大量数据中,在保证精准的前提下,提升数去获取的效率也是很重要的
声明:该文观点仅代表作者本人,牛骨文系教育信息发布平台,牛骨文仅提供信息存储空间服务。
