
mysql查询表里的重复数据方法:
| 1 2 3 4 |
INSERT INTO hk_test(username, passwd) VALUES
("qmf1", "qmf1"),("qmf2", "qmf11")
delete from hk_test where username="qmf1" and passwd="qmf1"
|

MySQL里查询表里的重复数据记录:
先查看重复的原始数据:
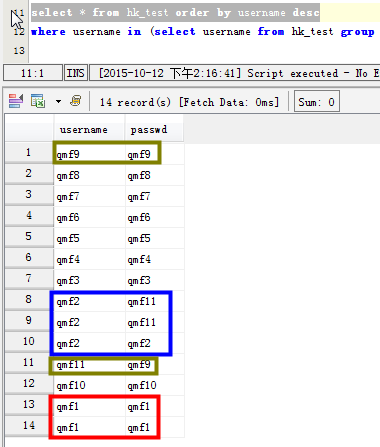
场景一:列出username字段有重读的数据
| 1 2 3 |
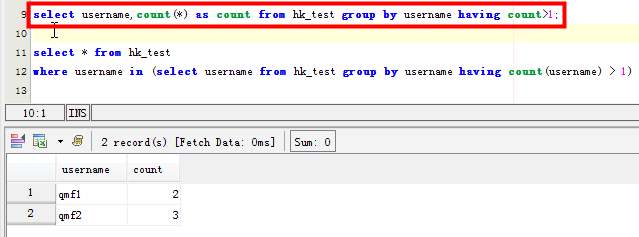
select username,count(*) as count from hk_test group by username having count>1;
SELECT username,count(username) as count FROM hk_test GROUP BY username HAVING count(username) >1 ORDER BY count DESC;
|
这种方法只是统计了该字段重复对应的具体的个数
场景二:列出username字段重复记录的具体指:
| 1 2 3 4 5 |
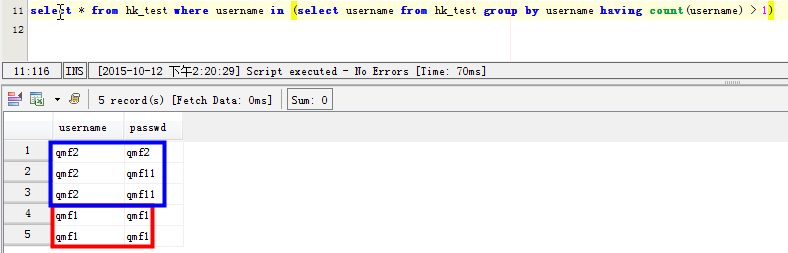
select * from hk_test where username in (select username from hk_test group by username having count(username) > 1)
SELECT username,passwd FROM hk_test WHERE username in ( SELECT username FROM hk_test GROUP BY username HAVING count(username)>1)
但是这条语句在mysql中效率太差,感觉mysql并没有为子查询生成临时表。在数据量大的时候,耗时很长时间
|
解决方法:

| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
于是使用先建立临时表
复制代码 代码如下:
create table `tmptable` as (
SELECT `name`
FROM `table`
GROUP BY `name` HAVING count(`name`) >1
);
然后使用多表连接查询
复制代码 代码如下:
SELECT a.`id`, a.`name`
FROM `table` a, `tmptable` t
WHERE a.`name` = t.`name`;
结果这次结果很快就出来了。
用 distinct去重复
复制代码 代码如下:
SELECT distinct a.`id`, a.`name`
FROM `table` a, `tmptable` t
WHERE a.`name` = t.`name`;
|
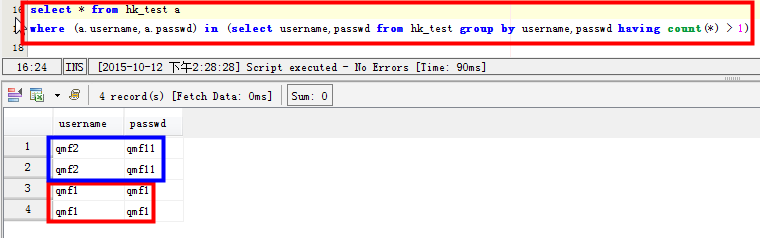
场景三:查看两个字段都重复的记录:比如username和passwd两个字段都有重复的记录:
| 1 2 |
select * from hk_test a
where (a.username,a.passwd) in (select username,passwd from hk_test group by username,passwd having count(*) > 1)
|
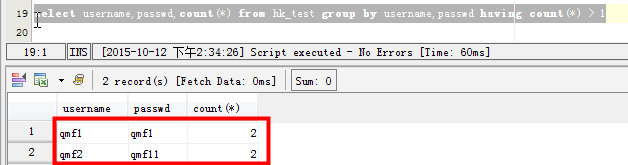
场景四:查询表中多个字段同时重复的记录:
| 1 |
select username,passwd,count(*) from hk_test group by username,passwd having count(*) > 1
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
MySQL查询表内重复记录
查询及删除重复记录的方法
(一)
1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断
select *
from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId)>1)
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有一个记录
delete from people
where peopleId in (select peopleId
from people group by peopleId
|
