
鼠标的轨迹识别
赛题
鼠标轨迹识别当前广泛运用于多种人机验证产品中,不仅便于用户的理解记忆,而且极大增加了暴力破解难度。但攻击者可通过黑产工具产生类人轨迹批量操作以绕过检测,并在对抗过程中不断升级其伪造数据以持续绕过同样升级的检测技术。我们期望用机器学习算法来提高人机验证中各种机器行为的检出率,其中包括对抗过程中出现的新的攻击手段的检测。
1.导入数据并进行处理及数据可视化
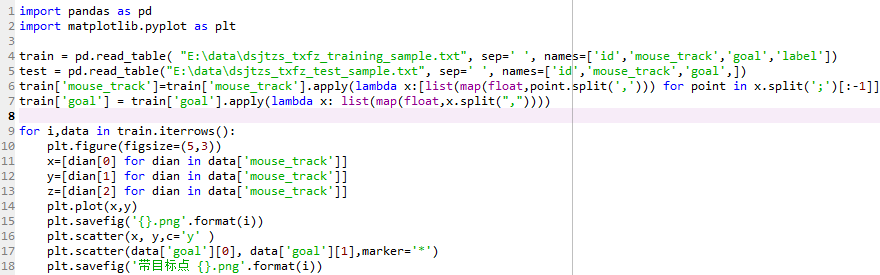
可视化结果为:
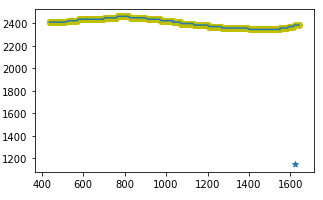
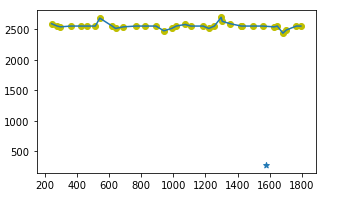
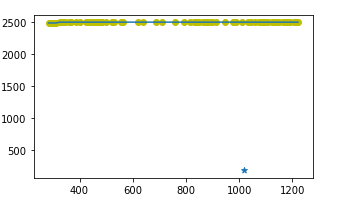
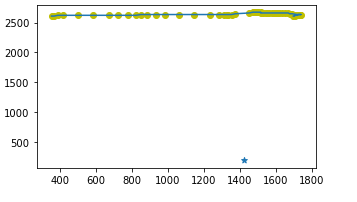
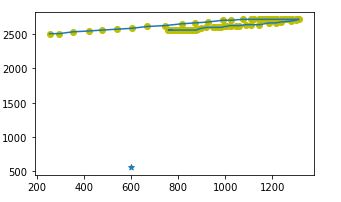
2.抽取特征
因为研究对象为鼠标轨迹,所以我们可以想到鼠标轨迹的速度是时刻改变的。我们可以计算出两个相邻轨迹点之间的距离及差分,可以对data数据进行一阶差分处理(diff函数),每一个轨迹点到目标点的距离,x,y到目标点x,y的距离,进一步求出差分,再有就是两个轨迹点之间的x的距离,y的距离;我们知道鼠标轨迹点时刻在变化,所以我们可以求出不同时刻鼠标轨迹点的速度,以及两点之间的x的速度差,y的速度差,获取两点之间的加速度,两点x的加速度,两点间y的加速度,分别进行差分处理;可以得到进行差分处理后的距离的最大最小值和方差,两点之间速度的最大最小值及均值中值方差,加速度的最大最小值及方差;对于各点的x,y分别获取最大最小值和方差;
3.特征选择
去掉低方差的特征
利用卡方检验对特征选择
4.模型
选择xgbost
import xgboost as xgb test_x=test.drop("id",1) train_x=train.drop(["id","label"],1) dtest = xgb.DMatrix(test_x) dtrain = xgb.DMatrix(train_x, label=train.label) params={ "booster":"gbtree", "objective": "binary:logistic", "eval_metric": "auc", "gamma":0.1, "subsample":0.7, "colsample_bytree":0.4 , # "min_child_weight":2.5, "eta": 0.007, "learning_rate":0.01, "seed":1024, "nthread":7, } watchlist = [(dtrain,"train"), evals=watchlist )声明:该文观点仅代表作者本人,牛骨文系教育信息发布平台,牛骨文仅提供信息存储空间服务。
- 上一篇: 常见验证码的弱点与验证码识别
- 下一篇: 第二届高校大数据比赛之鼠标轨迹识别
