
java整合solr5.5版本值solrj使用
首先导入solrj需要的jar包
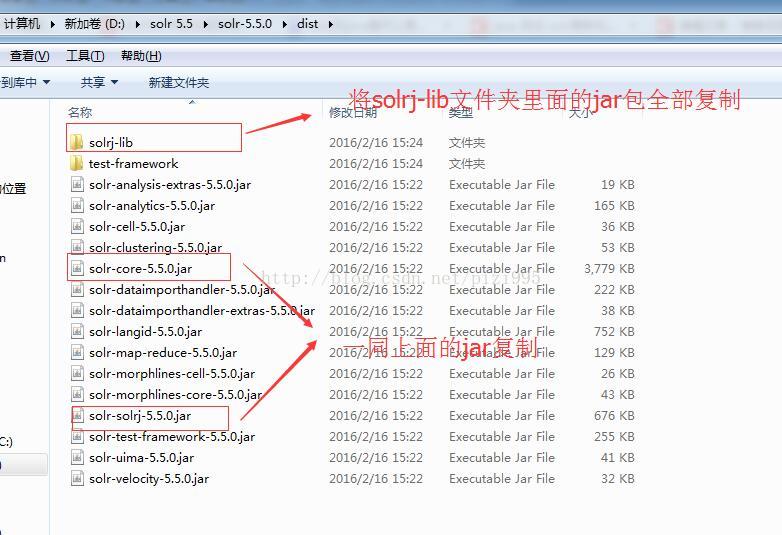
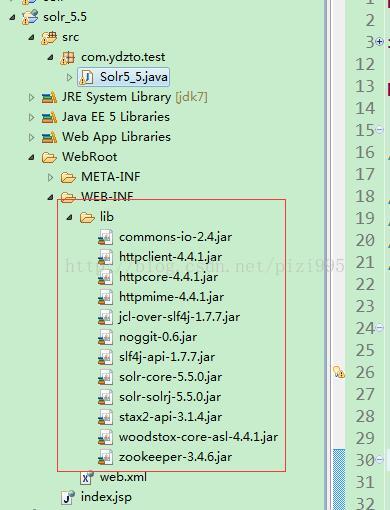
之后创建一个web项目(具体创建过程就不演示了)将jar导入 并创建一个类 稍后链接时候使用
接下来需要配置下core核心文件中的schema.xml文件
(schema.xml文件需要将同目录下的 managed-schema 改名而来)
自定义如下几个字段 将type 类型变成IK分词名称
name:字段名
type:之前定义过的各种FieldType
indexed:是否被索引
stored:是否被存储(如果不需要存储相应字段值,尽量设为false)
multiValued:是否有多个值(对可能存在多值的字段尽量设置为true,避免建索引时抛出错误)

配置上面之后(也是在schema.xml文件中添加)
将所有的 全文本 字段复制到一个字段中,以便进行统一的检索 如图

在solrconfig.xml中配置默认搜素域,这样我们就可以按照我们自己的域进行搜索如图

配置已经完成 接下来我们就可以进行代码的CRUD操作了
solrj在链接本地的core核心配置文件时候地址不用输入admin.html 就可以链接成功
配置core核心配置文件方法可参考 :solr 部署tomcat和core核心文件配置
1.链接本地core 并创建数据
public static void create() throws Exception{
//链接到本地的core1核心文件
String URL="http://127.0.0.1/solr/core1";
HttpSolrClient server = new HttpSolrClient(URL);
//创建数据
SolrInputDocument doc=new SolrInputDocument();
doc.addField("id", "1");
doc.addField("msg_title", "亮式企业");
doc.addField("msg_content", "这是一个伟大的企业");
server.add(doc);
server.commit();
}启动tomcat 页面查看 显示 链接成功 并且创建成功

2.查询
public static void query() throws Exception{
String URL="http://127.0.0.1/solr/core1";
HttpSolrClient server = new HttpSolrClient(URL);
//定义查询内容 * 代表查询所有 这个是基于结果集
SolrQuery query = new SolrQuery("亮"); //定义查询内容
query.setStart(0);//起始页
query.setRows(3);//每页显示数量
QueryResponse rsp = server.query( query );
SolrDocumentList results = rsp.getResults();
System.out.println(results.getNumFound());//查询总条数
for(SolrDocument doc:results){
System.out.println(doc);
}
}查询结果如下

3.删除
public static void Del() throws Exception{
//链接到本地的core1
String URL="http://127.0.0.1/solr/core1";
HttpSolrClient server = new HttpSolrClient(URL);
//删除所有分词
server.deleteByQuery("*:*");
//根据id删除所有分词
// server.deleteById("2");
server.commit();//先删除 基于query的删除 会删除所有建立的索引文件
}初步的了解 不足之处多多交流 声明:该文观点仅代表作者本人,牛骨文系教育信息发布平台,牛骨文仅提供信息存储空间服务。
- 上一篇: axios的拦截请求与响应
- 下一篇: 一些关于使用axios的心得
