Python基础篇—Pandas应用(二)
好的!接下来我们将利用骑行路线的数据集!我住在Montreal,加拿大东南部港市,我比较好奇这座城市的人们喜欢乘坐公共车辆,还是喜欢骑车?骑车的话 ,是喜欢在周末,还是工作日呢?
加载数据
首先,我们需要载入数据。
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option("display.mpl_style", "default") # Make the graphs a bit prettier
plt.rcParams["figure.figsize"] = (15, 5)
plt.rcParams["font.family"] = "sans-serif"
# This is necessary to show lots of columns in pandas 0.12.
# Not necessary in pandas 0.13.
pd.set_option("display.width", 5000)
pd.set_option("display.max_columns", 60)
bikes = pd.read_csv("../data/bikes.csv", sep=";", encoding="latin1", parse_dates=["Date"], dayfirst=True, index_col="Date")我们来看一下数据:
bikes[:5]输出:
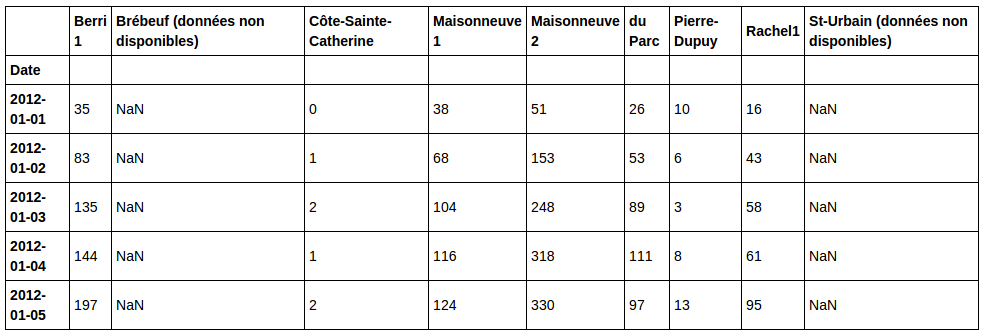
数据给出的是该地区平均每天选择7种骑行路线的人数统计。
接下来,我们将主要考虑Berri这条路线。Berri是Montreal的一条想当不错的骑行街道。现在,我经常选择这条路线去图书馆,但是之前我在Old Montreal住的时候,也经过这条街道去上班。
添加新的一列到数据框
我们将建立一个数据框,该数据框里只包含Berri路线。
berri_bikes = bikes[["Berri 1"]].copy()
berri_bikes[:5]输出:
接下来,我们需要为其增加一个“weekday”列。首先, 我们可以从索引来获得。索引就是位于数据框左侧“Date”下面的一列,它包含了一年中所有的日期。可以通过下面的命令查看:
berri_bikes.index输出:
<class "pandas.tseries.index.DatetimeIndex">
[2012-01-01, ..., 2012-11-05]
Length: 310, Freq: None, Timezone: None你可以看到,这里一共记录了一年中的310天的记录。Pandas拥有一系列的时间序列函数,所以,如果我们想要每一行记录数据的日期,我们可以这样做:
berri_bikes.index.day输出:
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 1, 2, 3,
4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 1, 2, 3, 4, 5, 6, 7, 8,
9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28,
29, 30, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 1,
2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 1, 2, 3, 4, 5,
6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,
23, 24, 25, 26, 27, 28, 29, 30, 31, 1, 2, 3, 4, 5, 6, 7, 8,
9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28,
29, 30, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 1,
2, 3, 4, 5], dtype=int32)事实上,我们想得到的是工作日,即周几:
berri_bikes.index.weekday输出:
array([6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0,
1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2,
3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4,
5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6,
0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1,
2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3,
4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5,
6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0,
1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2,
3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4,
5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6,
0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1,
2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3,
4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0], dtype=int32)这样就得到了weekday,其中,“0”代表周一。既然知道了如何获取weekday,我们就可以将其添加到数据框中,想这样:
berri_bikes.loc[:,"weekday"] = berri_bikes.index.weekday
berri_bikes[:5]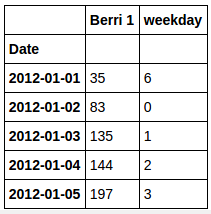
通过weekday将骑自行车的人加到一起
这是非常简单的!
数据框中有一个“.groupby()”的方法,如果你熟悉SQL的话,它就如同SQL中的groupby。这里不再详细地介绍这个方法——如果你想了解更多关于这个方法的知识,这个网页是个不错的选择!
“berri_bikes.groupby(‘weekday’).aggregate(sum)”的意思就是:按weekday将所有的行分组,然后再将相同的weekday的人数加起来:
weekday_counts = berri_bikes.groupby("weekday").aggregate(sum)
weekday_counts输出:
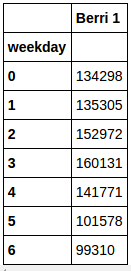
用0到6表示星期不方便记忆,所以可以这样:
weekday_counts.index = ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"]
weekday_counts输出:
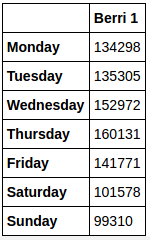
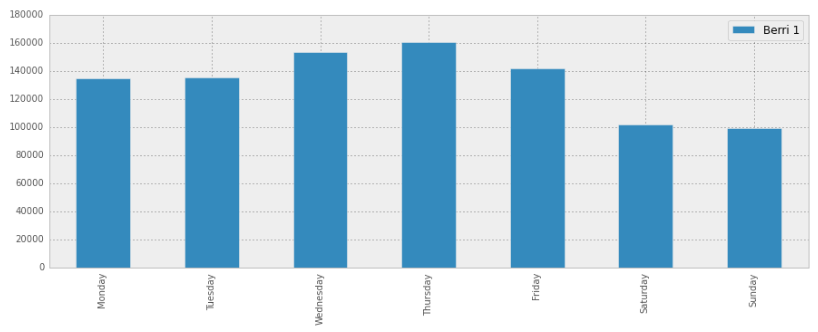
可视化:
weekday_counts.plot(kind="bar")输出: