
有权最短路径问题:狄克斯特拉(Dijkstra)算法 & Java 实现
一、有权图
之前我们知道,在无权重的图中,求两个顶点之间的最短路径,可以使用 广度优先搜索 算法。但是,当边存在权重(也可以理解为路程的长度)时,广度优先搜索不再适用。
针对有权图中的两点间最短路径,目前主要有 狄克斯特拉算法 和 贝尔曼福德算法 两种解决方法。本博客以狄克斯特拉算法为例。
备注:
广度优先搜索不了解的,可以戳这个链接:https://blog.csdn.net/afei__/article/details/83242507
二、狄克斯特拉算法
1. 简介
狄克斯特拉(Dijkstra)算法解决的是带权重的有向图上单源最短路径问题,该算法有一个限制条件即:所有边的权重都必须为非负数。如果存在负数边,则推荐使用贝尔曼福德(Bellman-Ford)算法。
2. 算法思想
狄克斯特拉算法的思想还是贪婪算法。
首先,我们从起点开始,更新起点到其直接相邻点的路程距离;
其次,我们在剩余点中找到离起点最近的一个点,并更新该点所有直接相邻点到起点的路程距离;
接下来,我们一直重复上一步,始终在剩余点中找一个距离起点最近的点,并更新其所有邻居点到起点的距离;
最后,遍历完所有顶点,完成计算。
3. 图解过程
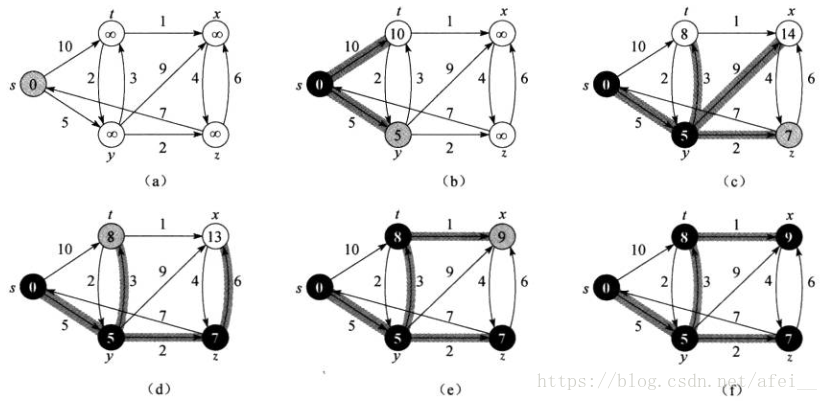
下图中,起点为 s 点。灰色点表示当前处理的结点,黑色点表示已经处理过的结点,白色点表示未处理的结点。开始时我们设定起点的距离为 0,其余点均为无穷大(∞)。我们从起点开始,依次更新其邻居结点到起点的距离,直至完成。带阴影的边表示当前最优的路径。(图片引用自《算法导论》一书)
三、代码实现
以上图为例吧,当然我们需要将图中的元素都抽象为 Java 中的类,即:
1. Vertex 类
大致有四个属性:
- 第一我们需要知道这个顶点是谁,即顶点的
id; - 第二我们需要知道这个顶点能到达的邻居顶点都有哪些,并且还要知道到达邻居顶点的路程有多长。所以我选择使用一个 HashMap<Vertext, Integer> 存储,其键为邻居顶点 Vertex,其值为到达该顶点的路程长度;
- 第三我们想要知道完整路径是怎样的话,我们还得知道上一个顶点是谁,即
predecessor; - 最后,我们保存一个变量
distance,存储该顶点离起始点的距离。
import java.util.HashMap;
public class Vertex {
private char id; // 顶点的标识
private HashMap<Vertex, Integer> neighbors; // 当前顶点可直接达到的顶点及其长度(权重)
private Vertex predecessor; // 上一个顶点是谁(前驱),用来记录路径的
private int distance = Integer.MAX_VALUE; // 距离起始点的距离
public Vertex(char id) {
this.id = id;
this.neighbors = new HashMap<>();
}
public char getId() {
return id;
}
public HashMap<Vertex, Integer> getNeighbors() {
return neighbors;
}
public void addNeighbor(Vertex vertex, int weight) {
neighbors.put(vertex, weight);
}
public Vertex getPredecessor() {
return predecessor;
}
public void setPredecessor(Vertex predecessor) {
this.predecessor = predecessor;
}
public int getDistance() {
return distance;
}
public void setDistance(int distance) {
this.distance = distance;
}
@Override
public String toString() {
return String.format("Vertex[%c]: distance is %d , predecessor is "%s"", id, distance,
predecessor == null ? "null" : predecessor.id);
}
}
2. 场景类
主要有三个方法:
- dijkstra 方法接收和执行计算
- extractMin 方法从剩余顶点中找出一个
distance最小的顶点返回 - relax 意为松弛操作,即更新某个顶点所有邻居点的
distance值
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Vertex> list = getTestData();
dijkstra(list);
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i).toString());
}
}
public static void dijkstra(List<Vertex> list) {
List<Vertex> copy = new LinkedList<>(); // copy一份出来
copy.addAll(list);
while (!copy.isEmpty()) {
// 每次从 copy 中选取一个距离起始点最近的点
// 并将这个点从 copy 中移除
Vertex vertex = extractMin(copy);
relax(vertex);
}
}
public static Vertex extractMin(List<Vertex> list) {
int index = 0;
for (int i = 1; i < list.size(); i++) {
if (list.get(index).getDistance() > list.get(i).getDistance()) {
index = i;
}
}
return list.remove(index);
}
public static void relax(Vertex vertex) {
HashMap<Vertex, Integer> map = vertex.getNeighbors();
for (Vertex neighbor : map.keySet()) {
int distance = vertex.getDistance() + map.get(neighbor);
if (neighbor.getDistance() > distance) {
neighbor.setDistance(distance);
neighbor.setPredecessor(vertex);
}
}
}
public static List<Vertex> getTestData() {
Vertex s = new Vertex("s");
Vertex t = new Vertex("t");
Vertex x = new Vertex("x");
Vertex y = new Vertex("y");
Vertex z = new Vertex("z");
s.addNeighbor(t, 10); // s->t : 10
s.addNeighbor(y, 5); // s->y : 5
t.addNeighbor(x, 1); // t->x : 1
t.addNeighbor(y, 2); // t->y : 2
x.addNeighbor(z, 4); // x->z : 4
y.addNeighbor(t, 3); // y->t : 3
y.addNeighbor(x, 9); // y->x : 9
y.addNeighbor(z, 2); // y->z : 2
z.addNeighbor(x, 6); // z->x : 6
z.addNeighbor(s, 7); // z->s : 7
// 起始点离起始点距离为0
s.setDistance(0);
LinkedList<Vertex> list = new LinkedList<>();
list.add(s);
list.add(t);
list.add(x);
list.add(y);
list.add(z);
return list;
}
}
3. 执行结果
Vertex[s]: distance is 0 , predecessor is "null"
Vertex[t]: distance is 8 , predecessor is "y"
Vertex[x]: distance is 9 , predecessor is "t"
Vertex[y]: distance is 5 , predecessor is "s"
Vertex[z]: distance is 7 , predecessor is "y"
对应下图,结果正确。
例如 x 点,其最短距离为 9,路径为 x ← t ← y ← s (反过来看)。
4. 继续优化策略
主要是针对 extractMin 方法的一些改进吧。
上述代码是通过遍历所有剩余点找出一个最小的 distance。如果我们将剩余点保存在一个最小堆实现的优先队列中,那么我们只需要直接取出队首元素即可,并且松弛操作更新 distance 时,调整最小堆的操作耗时也只是 log2 级别的,顶点数较多时比较适用。
如果,我们使用斐波那契堆实现最小优先队列,将会更加改善其效率,因为它调整堆的操作摊还代价为 O(1),而算法中由于更新 distance 的操作更频繁所以更适用。不过这个我也没尝试过了。
最后,就是第一次执行 extractMin 方法肯定是返回起始点,其实可以少做一次 extractMin 方法。
