
hadoop
一、配置主机名
执行:vim /etc/sysconfig/network(需要重启)。
临时使用:hostname hadoop01
二、配置hosts文件
执行:vim /etc/hosts(配置主键名和ip的映射关系)
三、配置免秘钥
执行:ssh-keygen 然后一直回车
生成节点的公钥和私钥,生成的文件会自动放在/root/.ssh目录下。然后把公钥发往远程机器,比如hadoop01向hadoop02发送执行:ssh-copy-id root@hadoop02此时,hadoop02节点就是把收到的hadoop秘钥保存在
/root/.ssh/authorized_keys 这个文件里,这个文件相当于访问白名单,凡是在此白明白存储的秘钥对应的机器,登录时都是免密码登录的。当hadoop01再次通过ssh远程登录hadoop02时,发现不需要输入密码了。如果是单机的伪分布式环境,节点需要登录自己节点,即hadoop01要登录hadoop01但是此时是需要输入密码的,所以要在hadoop01节点上执行:ssh-copy-id root@hadoop01
四、安装和配置jdk
执行: vi /etc/profile
2)在尾行添加
#set java environment
JAVA_HOME=/usr/local/src/java/jdk1.7.0_51
PATH=JAVAHOME/bin:PATH
CLASSPATH=.:$JAVAHOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME PATH CLASSPATH保存退出
3)source /etc/profile 使更改的配置立即生效
4)java -version 查看JDK版本信息。如显示1.7.0证明成功
五、Hadoop-HDFS命令


六、HDFS细节
1、namenode:名字节点。最主要功能是管理元数据信息。此外,通过心跳管理机制来检测和管理各datanode节点。注意,namenode不存储文件块。
2、元数据信息会存在namenode节点的内存里,目的是供快速查询访问。此外,为了元数据断电不丢失,要把元数据信息持久化到磁盘上。
3、namenode用两个文件:①fsimage文件 ②edits 文件来持久化元数据信息。
4、 fsimage文件是元数据信息的存储文件,edits文件会记录每次的操作。这两个文件会定期合并一次,确保fsimage文件里数据是最新的。默认的合并周期是3600s。
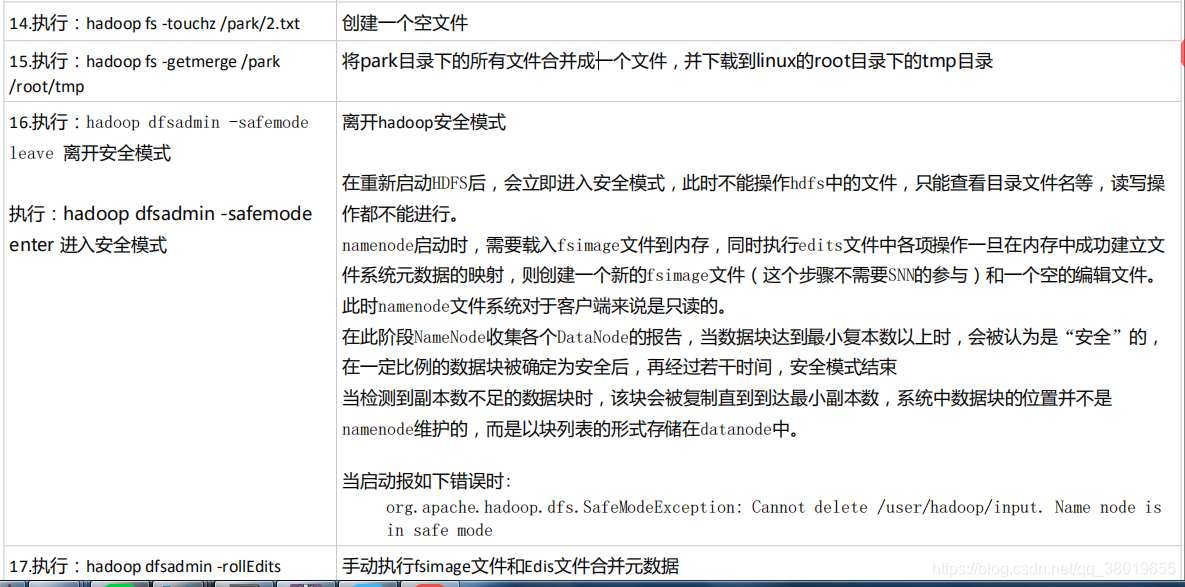
5、hadoop namenode -format 是namenode的格式化指令,这个指令的作用是生成新的fsimage和edits文件。这个指令是用于第一次搭建Hadoop集群后,执行的指令。
6、当出现少进程的情况,处理方式:①停掉进程 ②删掉tmp ③创建一个新的tmp④格式化指令 ⑤启动进程 ⑥jps查看进程确认。在练习环境中,但是注意,此指令很危险。在工作里,一般会通过文件的方式,使此指令失效。另外的稳妥的处理方式:在sbin目录下,执行:sh hadoop-daemon.sh start namnode|datanode。
7、fsimage和edits合并工作是由SNN来做的。
8、SNN这种合并机制可能造成元数据丢失的情况=》即SNN机制不能元数据的热备,从而namenode还是会存在单点故障问题。SNN机制是Hadoop1.0的机制,2.0已经舍弃此机制。如果用的是2.0的伪分布式,会有SNN,但是完全分布式下,没有SNN机制了。
9、每次启动HDFS的时候,namenode都会把fsimage和edits文件合并一次。目的是确保元数据信息是最新的。
10、每次启动HDFS的时候,每个datanode会将自身的文件块信息汇报给namenode。namenode收到这些信息后,会进行校验,校验数据是否有缺失,还有文件块的副本数量是否达到要求,如果发现有块的缺失,此时,HDFS会进入到安全模式。
11、安全模式下,HDFS只能提供读服务,不能提供写服务。可以手动进入或退出安全模式hadoop dfsadmin -safemode leave | enter (这也是为什么在伪分布模式下,副本数量只能为1的原因)。
12、.手动合并元数据文件的指令:hadoop dfsadmin -rollEdits。
13、datanode 数据节点,用来存储文件块的。datanode会定期的向namenode发送心跳包。
14、不适合存储小文件,因为海量的小文件都要被元数据管理进来,一条元数据信息大约占150b字节。所以会浪费namenode的内存资源。
15、 HDFS不允许修改文件,HDFS的适用场景:once-write-many-read 一次写入,多次读取场景。Hadoop2.0允许数据的追加。
七、HDFS 回收站机制
Hadoop回收站trash,默认是关闭的。修改conf/core-site.xml,增加。value的时间单位是分钟,如果配置成0,表示不开启HDFS的回收站。
1440=24*60,表示的一天的回收间隔,即文件在回收站存在一天后,被清空。
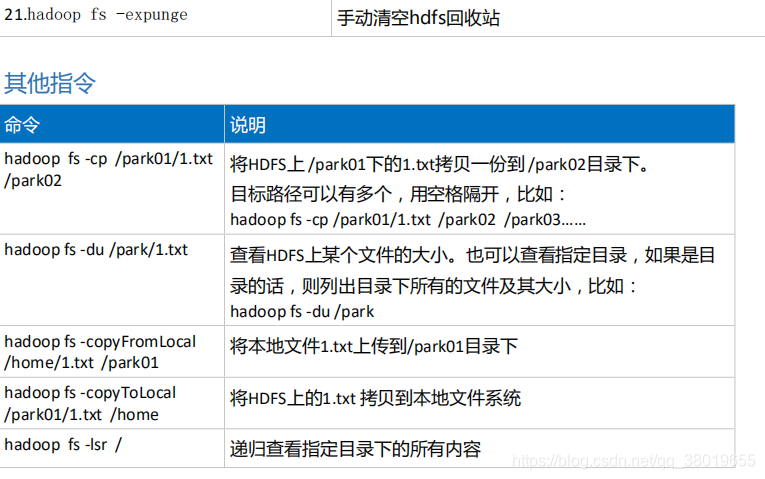
我们可以通过递归查看指令,找到我们要恢复的文件放在回收站的哪个目录下
执行:hadoop fs -lsr /user/root/.Trash找到文件路径后,如果想恢复,执行hdfs 的mv 指令即可,(mv指令可用于文件的移动)。
- 上一篇:定时生成分月表sql语句
- 下一篇:向MongoDB中存储文件
