牛骨文教育服务平台
(让学习变的简单)
课程搜索
老师搜索
文章搜索
手册搜索
手册文章
搜索
牛骨文首页
创新课程
编程语言
互联网运营
前端开发
大数据
学习手册
Web前端开发
服务端语言
数据库
移动端开发
开发框架
操作系统
学习手册
在线课程
博客笔记
软件商城
建站系统
博客笔记
当前位置:
牛骨文教育服务平台
>
博文笔记
15
2007-08
【
】
Javascript读取ACCESS数据库
2007-08-15
这些操作也许用不上,但也帖上来,网上也有很多相关例子,不多说帖出我自己改写的一段,欢迎指正 说明:在存html文件的目录下有一个存放数据
【
】
JSON入门Java篇-3-用json.org来构建JSON数据并输出
2017-09-27
前面文章,我们直接创建一个JSON数据,但是并不知道整个如何用Java代码来构造这个JSON数据的过程。这篇我们开始介绍JSON的使用,主要介
11
2015-06
【
】
hadoop 配置history server 和timeline server
2015-06-11
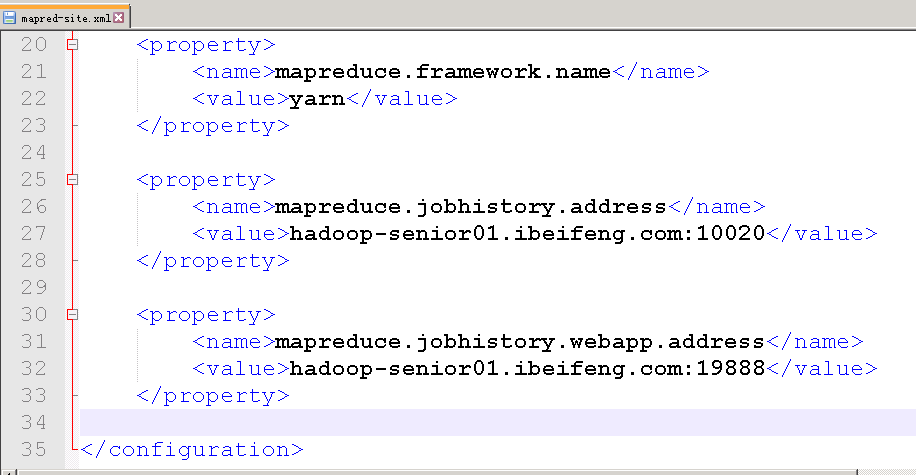
一,配置history server 1.配置history server,在etc/hadoop/mapred-site.xml中配置以下内容. mapreduce.jobhistory.address localhost:10020 mapreduce.jobhistory.webapp.
【
】
Spark学习-SparkSQL--02-Spark history Server
2017-08-03
Spark History Server配置使用 1。Spark history Server产生背景 以standalone运行模式为例,在运行Spark Application的时候,Spark会提供一个WEBUI列出应用程序的运行时信息;
【
】
配置 JobhistoryServer 历史服务器,日志聚集功能,HDFS 文件系统用户权限检查,取消HDFS警告提示
2016-10-30
配置 JobhistoryServer 历史服务器 historyServer:查看已经完成的历史作业记录 指定配置属性:mapred-site.xml mapreduce.jobhistory.address
08
2017-07
【
】
hadoop配置启动historyserver
2017-07-08
yarn-site.xml增加如下配置,不需要重启hadoop mapreduce.jobhistory.address 192.168.1.105:10020 mapreduce.jobhistory.webapp.address 192.168.1.105:19888 启动historyserver /usr/
20
2016-07
【
】
Hadoop集群的JobHistoryServer详解
2016-07-20
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、
【
】
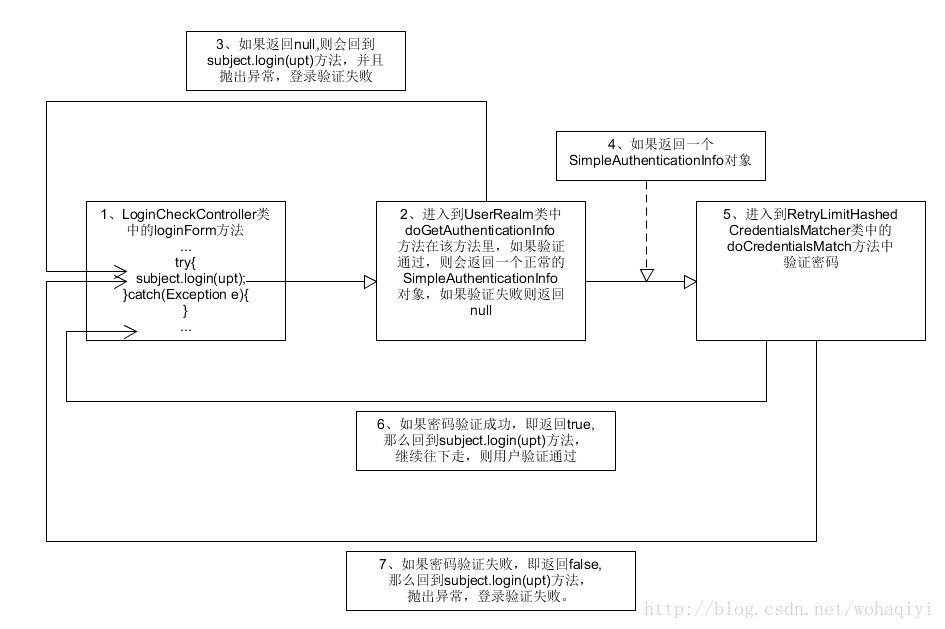
shiro框架---关于用户登录和权限验证功能的实现步骤(六)
2018-02-19
接上一篇文章shiro框架—关于用户登录和权限验证功能的实现步骤(五) 在我前几篇文章里有shiro配置的文件下载包,下载后里边有四个配置文件ShiroConfig、Ret
13
2017-04
【
】
Python中用list创建二维数组的方法
2017-04-13
b =[[1 for x in range(n)] for y in range(m)] 上面一句就初始化了一个m*n的二维数组,且初始值全为1 阅读更多
25
2018-01
【
】
基于springboot的shiro sso统一登录系统平台搭建遇到的坑
2018-01-25
概述: 项目微服务化,搭建sso统一登录平台,使用共享JID,完成统一登录授权功能,下文记录遇到的主要的坑。 1.策略选择问题 2.springboot,shirof
首页
上一页
421
422
423
424
425
426
427
428
429
430
下一页
末页
热门文章
CTF writeup 2_南邮网络攻防训...
SSM框架——详细整合教程(...
Linux Shell脚本编程--curl命...
HttpClient使用详解
Java面试题全集(上)
JAVA设计模式之单例模式
java.lang.OutOfMemoryError: PermGen ...
TCP协议中的三次握手和四次...
form表单的两种提交方式,su...
String,StringBuffer与StringBuilder...
最新文章
Java之品优购课程讲义_day20(7)
剑指 Offer - 8:跳台阶
Netty权威指南_札记02_NIO编程
mysql时间属性之时间戳和datetime之...
虚拟现实或许可以拯救古埃及的“...
spring cloud服务注册中心eureka---集群...
Java SE 第六章
HTTP请求+数据库
HIDL学习笔记之HIDL C++(第二天)
ubuntu系统下指定tomcat运行时为JDK1.8...
copyright © 2008-2026 亿联网络 版权所有 备案号:
粤ICP备14031511号-2