

3.7. 读和写
读和写方法都进行类似的任务, 就是, 从和到应用程序代码拷贝数据. 因此, 它们的原型相当相似, 可以同时介绍它们:
ssize_t read(struct file *filp, char __user *buff, size_t count, loff_t *offp);
ssize_t write(struct file *filp, const char __user *buff, size_t count, loff_t *offp);
对于 2 个方法, filp 是文件指针, count 是请求的传输数据大小. buff 参数指向持有被写入数据的缓存, 或者放入新数据的空缓存. 最后, offp 是一个指针指向一个"long offset type"对象, 它指出用户正在存取的文件位置. 返回值是一个"signed size type"; 它的使用在后面讨论.
让我们重复一下, read 和 write 方法的 buff 参数是用户空间指针. 因此, 它不能被内核代码直接解引用. 这个限制有几个理由:
依赖于你的驱动运行的体系, 以及内核被如何配置的, 用户空间指针当运行于内核模式可能根本是无效的. 可能没有那个地址的映射, 或者它可能指向一些其他的随机数据.
就算这个指针在内核空间是同样的东西, 用户空间内存是分页的, 在做系统调用时这个内存可能没有在 RAM 中. 试图直接引用用户空间内存可能产生一个页面错, 这是内核代码不允许做的事情. 结果可能是一个"oops", 导致进行系统调用的进程死亡.
置疑中的指针由一个用户程序提供, 它可能是错误的或者恶意的. 如果你的驱动盲目地解引用一个用户提供的指针, 它提供了一个打开的门路使用户空间程序存取或覆盖系统任何地方的内存. 如果你不想负责你的用户的系统的安全危险, 你就不能直接解引用用户空间指针.
显然, 你的驱动必须能够存取用户空间缓存以完成它的工作. 但是, 为安全起见这个存取必须使用特殊的, 内核提供的函数. 我们介绍几个这样的函数(定义于 <asm/uaccess.h>), 剩下的在第一章"使用 ioctl 参数"一节中. 它们使用一些特殊的, 依赖体系的技巧来确保内核和用户空间的数据传输安全和正确.
scull 中的读写代码需要拷贝一整段数据到或者从用户地址空间. 这个能力由下列内核函数提供, 它们拷贝一个任意的字节数组, 并且位于大部分读写实现的核心中.
unsigned long copy_to_user(void __user *to,const void *from,unsigned long count);
unsigned long copy_from_user(void *to,const void __user *from,unsigned long count);
尽管这些函数表现象正常的 memcpy 函数, 必须加一点小心在从内核代码中存取用户空间. 寻址的用户也当前可能不在内存, 虚拟内存子系统会使进程睡眠在这个页被传送到位时. 例如, 这发生在必须从交换空间获取页的时候. 对于驱动编写者来说, 最终结果是任何存取用户空间的函数必须是可重入的, 必须能够和其他驱动函数并行执行, 并且, 特别的, 必须在一个它能够合法地睡眠的位置. 我们在第 5 章再回到这个主题.
这 2 个函数的角色不限于拷贝数据到和从用户空间: 它们还检查用户空间指针是否有效. 如果指针无效, 不进行拷贝; 如果在拷贝中遇到一个无效地址, 另一方面, 只拷贝部分数据. 在 2 种情况下, 返回值是还要拷贝的数据量. scull 代码查看这个错误返回, 并且如果它不是 0 就返回 -EFAULT 给用户.
用户空间存取和无效用户空间指针的主题有些高级, 在第 6 章讨论. 然而, 值得注意的是如果你不需要检查用户空间指针, 你可以调用 copy_to_user 和 copy_from_user 来代替. 这是有用处的, 例如, 如果你知道你已经检查了这些参数. 但是, 要小心; 事实上, 如果你不检查你传递给这些函数的用户空间指针, 那么你可能造成内核崩溃和/或安全漏洞.
至于实际的设备方法, read 方法的任务是从设备拷贝数据到用户空间(使用 copy_to_user), 而 write 方法必须从用户空间拷贝数据到设备(使用 copy_from_user). 每个 read 或 write 系统调用请求一个特定数目字节的传送, 但是驱动可自由传送较少数据 -- 对读和写这确切的规则稍微不同, 在本章后面描述.
不管这些方法传送多少数据, 它们通常应当更新 *offp 中的文件位置来表示在系统调用成功完成后当前的文件位置. 内核接着在适当时候传播文件位置的改变到文件结构. pread 和 pwrite 系统调用有不同的语义; 它们从一个给定的文件偏移操作, 并且不改变其他的系统调用看到的文件位置. 这些调用传递一个指向用户提供的位置的指针, 并且放弃你的驱动所做的改变.
图给 read 的参数表示了一个典型读实现是如何使用它的参数.
图 3.2. 给 read 的参数
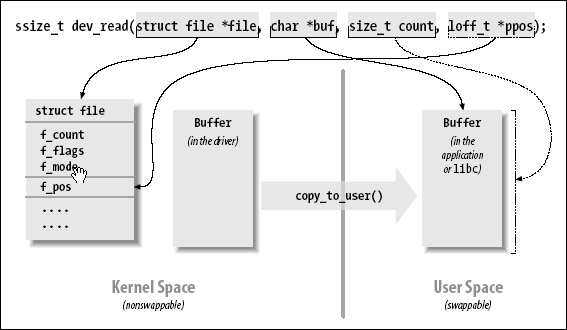
read 和 write 方法都在发生错误时返回一个负值. 相反, 大于或等于 0 的返回值告知调用程序有多少字节已经成功传送. 如果一些数据成功传送接着发生错误, 返回值必须是成功传送的字节数, 错误不报告直到函数下一次调用. 实现这个传统, 当然, 要求你的驱动记住错误已经发生, 以便它们可以在以后返回错误状态.
尽管内核函数返回一个负数指示一个错误, 这个数的值指出所发生的错误类型( 如第 2 章介绍 ), 用户空间运行的程序常常看到 -1 作为错误返回值. 它们需要存取 errno 变量来找出发生了什么. 用户空间的行为由 POSIX 标准来规定, 但是这个标准没有规定内核内部如何操作.
3.7.1. read 方法
read 的返回值由调用的应用程序解释:
如果这个值等于传递给 read 系统调用的 count 参数, 请求的字节数已经被传送. 这是最好的情况.
如果是正数, 但是小于 count, 只有部分数据被传送. 这可能由于几个原因, 依赖于设备. 常常, 应用程序重新试着读取. 例如, 如果你使用 fread 函数来读取, 库函数重新发出系统调用直到请求的数据传送完成.
如果值为 0, 到达了文件末尾(没有读取数据).
一个负值表示有一个错误. 这个值指出了什么错误, 根据 <linux/errno.h>. 出错的典型返回值包括 -EINTR( 被打断的系统调用) 或者 -EFAULT( 坏地址 ).
前面列表中漏掉的是这种情况"没有数据, 但是可能后来到达". 在这种情况下, read 系统调用应当阻塞. 我们将在第 6 章涉及阻塞.
scull 代码利用了这些规则. 特别地, 它利用了部分读规则. 每个 scull_read 调用只处理单个数据量子, 不实现一个循环来收集所有的数据; 这使得代码更短更易读. 如果读程序确实需要更多数据, 它重新调用. 如果标准 I/O 库(例如, fread)用来读取设备, 应用程序甚至不会注意到数据传送的量子化.
如果当前读取位置大于设备大小, scull 的 read 方法返回 0 来表示没有可用的数据(换句话说, 我们在文件尾). 这个情况发生在如果进程 A 在读设备, 同时进程 B 打开它写, 这样将设备截短为 0. 进程 A 突然发现自己过了文件尾, 下一个读调用返回 0.
这是 read 的代码( 忽略对 down_interruptible 的调用并且现在为 up; 我们在下一章中讨论它们):
ssize_t scull_read(struct file *filp, char __user *buf, size_t count, loff_t *f_pos)
{
struct scull_dev *dev = filp->private_data;
struct scull_qset *dptr; /* the first listitem */
int quantum = dev->quantum, qset = dev->qset;
int itemsize = quantum * qset; /* how many bytes in the listitem */
int item, s_pos, q_pos, rest;
ssize_t retval = 0;
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
if (*f_pos >= dev->size)
goto out;
if (*f_pos + count > dev->size)
count = dev->size - *f_pos;
/* find listitem, qset index, and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum;
q_pos = rest % quantum;
/* follow the list up to the right position (defined elsewhere) */
dptr = scull_follow(dev, item);
if (dptr == NULL || !dptr->data || ! dptr->data[s_pos])
goto out; /* don"t fill holes */
/* read only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_to_user(buf, dptr->data[s_pos] + q_pos, count))
{
retval = -EFAULT;
goto out;
}
*f_pos += count;
retval = count;
out:
up(&dev->sem);
return retval;
}
3.7.2. write 方法
write, 象 read, 可以传送少于要求的数据, 根据返回值的下列规则:
如果值等于 count, 要求的字节数已被传送.
如果正值, 但是小于 count, 只有部分数据被传送. 程序最可能重试写入剩下的数据.
如果值为 0, 什么没有写. 这个结果不是一个错误, 没有理由返回一个错误码. 再一次, 标准库重试写调用. 我们将在第 6 章查看这种情况的确切含义, 那里介绍了阻塞.
一个负值表示发生一个错误; 如同对于读, 有效的错误值是定义于 <linux/errno.h>中.
不幸的是, 仍然可能有发出错误消息的不当行为程序, 它在进行了部分传送时终止. 这是因为一些程序员习惯看写调用要么完全失败要么完全成功, 这实际上是大部分时间的情况, 应当也被设备支持. scull 实现的这个限制可以修改, 但是我们不想使代码不必要地复杂.
write 的 scull 代码一次处理单个量子, 如 read 方法做的:
ssize_t scull_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos)
{
struct scull_dev *dev = filp->private_data;
struct scull_qset *dptr;
int quantum = dev->quantum, qset = dev->qset;
int itemsize = quantum * qset;
int item, s_pos, q_pos, rest;
ssize_t retval = -ENOMEM; /* value used in "goto out" statements */
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
/* find listitem, qset index and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum;
q_pos = rest % quantum;
/* follow the list up to the right position */
dptr = scull_follow(dev, item);
if (dptr == NULL)
goto out;
if (!dptr->data)
{
dptr->data = kmalloc(qset * sizeof(char *), GFP_KERNEL);
if (!dptr->data)
goto out;
memset(dptr->data, 0, qset * sizeof(char *));
}
if (!dptr->data[s_pos])
{
dptr->data[s_pos] = kmalloc(quantum, GFP_KERNEL);
if (!dptr->data[s_pos])
goto out;
}
/* write only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_from_user(dptr->data[s_pos]+q_pos, buf, count))
{
retval = -EFAULT;
goto out;
}
*f_pos += count;
retval = count;
/* update the size */
if (dev->size < *f_pos)
dev->size = *f_pos;
out:
up(&dev->sem);
return retval;
}
3.7.3. readv 和 writev
Unix 系统已经长时间支持名为 readv 和 writev 的 2 个系统调用. 这些 read 和 write 的"矢量"版本使用一个结构数组, 每个包含一个缓存的指针和一个长度值. 一个 readv 调用被期望来轮流读取指示的数量到每个缓存. 相反, writev 要收集每个缓存的内容到一起并且作为单个写操作送出它们.
如果你的驱动不提供方法来处理矢量操作, readv 和 writev 由多次调用你的 read 和 write 方法来实现. 在许多情况, 但是, 直接实现 readv 和 writev 能获得更大的效率.
矢量操作的原型是:
ssize_t (*readv) (struct file *filp, const struct iovec *iov, unsigned long count, loff_t *ppos);
ssize_t (*writev) (struct file *filp, const struct iovec *iov, unsigned long count, loff_t *ppos);
这里, filp 和 ppos 参数与 read 和 write 的相同. iovec 结构, 定义于 <linux/uio.h>, 如同:
struct iovec
{
void __user *iov_base; __kernel_size_t iov_len;
};
每个 iovec 描述了一块要传送的数据; 它开始于 iov_base (在用户空间)并且有 iov_len 字节长. count 参数告诉有多少 iovec 结构. 这些结构由应用程序创建, 但是内核在调用驱动之前拷贝它们到内核空间.
矢量操作的最简单实现是一个直接的循环, 只是传递出去每个 iovec 的地址和长度给驱动的 read 和 write 函数. 然而, 有效的和正确的行为常常需要驱动更聪明. 例如, 一个磁带驱动上的 writev 应当将全部 iovec 结构中的内容作为磁带上的单个记录.
很多驱动, 但是, 没有从自己实现这些方法中获益. 因此, scull 省略它们. 内核使用 read 和 write 来模拟它们, 最终结果是相同的.