

6.3. poll 和 select
使用非阻塞 I/O 的应用程序常常使用 poll, select, 和 epoll 系统调用. poll, select 和 epoll 本质上有相同的功能: 每个允许一个进程来决定它是否可读或者写一个或多个文件而不阻塞. 这些调用也可阻塞进程直到任何一个给定集合的文件描述符可用来读或写. 因此, 它们常常用在必须使用多输入输出流的应用程序, 而不必粘连在它们任何一个上. 相同的功能常常由多个函数提供, 因为 2 个是由不同的团队在几乎相同时间完成的: select 在 BSD Unix 中引入, 而 poll 是 System V 的解决方案. epoll 调用[[23](#)]添加在 2.5.45, 作为使查询函数扩展到几千个文件描述符的方法.
支持任何一个这些调用都需要来自设备驱动的支持. 这个支持(对所有 3 个调用)由驱动的 poll 方法调用. 这个方法由下列的原型:
unsigned int (*poll) (struct file *filp, poll_table *wait);
这个驱动方法被调用, 无论何时用户空间程序进行一个 poll, select, 或者 epoll 系统调用, 涉及一个和驱动相关的文件描述符. 这个设备方法负责这 2 步:
- 在一个或多个可指示查询状态变化的等待队列上调用 poll_wait. 如果没有文件描述符可用作 I/O, 内核使这个进程在等待队列上等待所有的传递给系统调用的文件描述符.
- 返回一个位掩码, 描述可能不必阻塞就立刻进行的操作.
这 2 个操作常常是直接的, 并且趋向与各个驱动看起来类似. 但是, 它们依赖只能由驱动提供的信息, 因此, 必须由每个驱动单独实现.
poll_table 结构, 给 poll 方法的第 2 个参数, 在内核中用来实现 poll, select, 和 epoll 调用; 它在 <linux/poll.h>中声明, 这个文件必须被驱动源码包含. 驱动编写者不必要知道所有它内容并且必须作为一个不透明的对象使用它; 它被传递给驱动方法以便驱动可用每个能唤醒进程的等待队列来加载它, 并且可改变 poll 操作状态. 驱动增加一个等待队列到 poll_table 结构通过调用函数 poll_wait:
void poll_wait (struct file *, wait_queue_head_t *, poll_table *);
poll 方法的第 2 个任务是返回位掩码, 它描述哪个操作可马上被实现; 这也是直接的. 例如, 如果设备有数据可用, 一个读可能不必睡眠而完成; poll 方法应当指示这个时间状态. 几个标志(通过 <linux/poll.h> 定义)用来指示可能的操作:
POLLIN
如果设备可被不阻塞地读, 这个位必须设置.
POLLRDNORM
这个位必须设置, 如果"正常"数据可用来读. 一个可读的设备返回( POLLIN|POLLRDNORM ).
POLLRDBAND
这个位指示带外数据可用来从设备中读取. 当前只用在 Linux 内核的一个地方( DECnet 代码 )并且通常对设备驱动不可用.
POLLPRI
高优先级数据(带外)可不阻塞地读取. 这个位使 select 报告在文件上遇到一个异常情况, 因为 selct 报告带外数据作为一个异常情况.
POLLHUP
当读这个设备的进程见到文件尾, 驱动必须设置 POLLUP(hang-up). 一个调用 select 的进程被告知设备是可读的, 如同 selcet 功能所规定的.
POLLERR
一个错误情况已在设备上发生. 当调用 poll, 设备被报告位可读可写, 因为读写都返回一个错误码而不阻塞.
POLLOUT
这个位在返回值中设置, 如果设备可被写入而不阻塞.
POLLWRNORM
这个位和 POLLOUT 有相同的含义, 并且有时它确实是相同的数. 一个可写的设备返回( POLLOUT|POLLWRNORM).
POLLWRBAND
如同 POLLRDBAND , 这个位意思是带有零优先级的数据可写入设备. 只有 poll 的数据报实现使用这个位, 因为一个数据报看传送带外数据.
应当重复一下 POLLRDBAND 和 POLLWRBAND 仅仅对关联到 socket 的文件描述符有意义: 通常设备驱动不使用这些标志.
poll 的描述使用了大量在实际使用中相对简单的东西. 考虑 poll 方法的 scullpipe 实现:
static unsigned int scull_p_poll(struct file *filp, poll_table *wait)
{
struct scull_pipe *dev = filp->private_data;
unsigned int mask = 0;
/*
* The buffer is circular; it is considered full
* if "wp" is right behind "rp" and empty if the
* two are equal.
*/
down(&dev->sem);
poll_wait(filp, &dev->inq, wait);
poll_wait(filp, &dev->outq, wait);
if (dev->rp != dev->wp)
mask |= POLLIN | POLLRDNORM; /* readable */
if (spacefree(dev))
mask |= POLLOUT | POLLWRNORM; /* writable */
up(&dev->sem);
return mask;
}
这个代码简单地增加了 2 个 scullpipe 等待队列到 poll_table, 接着设置正确的掩码位, 根据数据是否可以读或写.
所示的 poll 代码缺乏文件尾支持, 因为 scullpipe 不支持文件尾情况. 对大部分真实的设备, poll 方法应当返回 POLLHUP 如果没有更多数据(或者将)可用. 如果调用者使用 select 系统调用, 文件被报告为可读. 不管是使用 poll 还是 select, 应用程序知道它能够调用 read 而不必永远等待, 并且 read 方法返回 0 来指示文件尾.
例如, 对于 真正的FIFO, 读者见到一个文件尾当所有的写者关闭文件, 而在 scullpipe 中读者永远见不到文件尾. 这个做法不同是因为 FIFO 是用作一个 2 个进程的通讯通道, 而 scullpipe 是一个垃圾桶, 人人都可以放数据只要至少有一个读者. 更多地, 重新实现内核中已有的东西是没有意义的, 因此我们选择在我们的例子里实现一个不同的做法.
与 FIFO 相同的方式实现文件尾就意味着检查 dev->nwwriters, 在 read 和 poll 中, 并且报告文件尾(如刚刚描述过的)如果没有进程使设备写打开. 不幸的是, 使用这个实现方法, 如果一个读者打开 scullpipe 设备在写者之前, 它可能见到文件尾而没有机会来等待数据. 解决这个问题的最好的方式是在 open 中实现阻塞, 如同真正的 FIFO 所做的; 这个任务留作读者的一个练习.
6.3.1. 与 read 和 write 的交互
poll 和 select 调用的目的是提前决定是否一个 I/O 操作会阻塞. 在那个方面, 它们补充了 read 和 write. 更重要的是, poll 和 select , 因为它们使应用程序同时等待几个数据流, 尽管我们在 scull 例子里没有采用这个特性.
一个正确的实现对于使应用程序正确工作是必要的: 尽管下列的规则或多或少已经说明过, 我们在此总结它们.
6.3.1.1. 从设备中读数据
如果在输入缓冲中有数据, read 调用应当立刻返回, 没有可注意到的延迟, 即便数据少于应用程序要求的, 并且驱动确保其他的数据会很快到达. 你可一直返回小于你被请求的数据, 如果因为任何理由而方便这样(我们在 scull 中这样做), 如果你至少返回一个字节. 在这个情况下, poll 应当返回 POLLIN|POLLRDNORM.
如果在输入缓冲中没有数据, 缺省地 read 必须阻塞直到有一个字节. 如果 O_NONBLOCK 被置位, 另一方面, read 立刻返回 -EAGIN (尽管一些老版本 SYSTEM V 返回 0 在这个情况时). 在这些情况中, poll 必须报告这个设备是不可读的直到至少一个字节到达. 一旦在缓冲中有数据, 我们就回到前面的情况.
如果我们处于文件尾, read 应当立刻返回一个 0, 不管是否阻塞. 这种情况 poll 应该报告 POLLHUP.
6.3.1.2. 写入设备
如果在输出缓冲中有空间, write 应当不延迟返回. 它可接受小于这个调用所请求的数据, 但是它必须至少接受一个字节. 在这个情况下, poll 报告这个设备是可写的, 通过返回 POLLOUT|POLLWRNORM.
如果输出缓冲是满的, 缺省地 write 阻塞直到一些空间被释放. 如果 O_NOBLOCK 被设置, write 立刻返回一个 -EAGAIN(老式的 System V Unices 返回 0). 在这些情况下, poll 应当报告文件是不可写的. 另一方面, 如果设备不能接受任何多余数据, write 返回 -ENOSPC("设备上没有空间"), 不管是否设置了 O_NONBLOCK.
在返回之前不要调用 wait 来传送数据, 即便当 O_NONBLOCK 被清除. 这是因为许多应用程序选择来找出一个 write 是否会阻塞. 如果设备报告可写, 调用必须不阻塞. 如果使用设备的程序想保证它加入到输出缓冲中的数据被真正传送, 驱动必须提供一个 fsync 方法. 例如, 一个可移除的设备应当有一个 fsnyc 入口.
尽管有一套通用的规则, 还应当认识到每个设备是唯一的并且有时这些规则必须稍微弯曲一下. 例如, 面向记录的设备(例如磁带设备)无法执行部分写.
6.3.1.3. 刷新挂起的输出
我们已经见到 write 方法如何自己不能解决全部的输出需要. fsync 函数, 由同名的系统调用而调用, 填补了这个空缺. 这个方法原型是:
int (*fsync) (struct file *file, struct dentry *dentry, int datasync);
如果一些应用程序需要被确保数据被发送到设备, fsync 方法必须被实现为不管 O_NONBLOCK 是否被设置. 对 fsync 的调用应当只在设备被完全刷新时返回(即, 输出缓冲为空), 即便这需要一些时间. datasync 参数用来区分 fsync 和 fdatasync 系统调用; 这样, 它只对文件系统代码有用, 驱动可以忽略它.
fsync 方法没有不寻常的特性. 这个调用不是时间关键的, 因此每个设备驱动可根据作者的口味实现它. 大部分的时间, 字符驱动只有一个 NULL 指针在它们的 fops 中. 阻塞设备, 另一方面, 常常实现这个方法使用通用的 block_fsync, 它接着会刷新设备的所有的块.
6.3.2. 底层的数据结构
poll 和 select 系统调用的真正实现是相当地简单, 对那些感兴趣于它如何工作的人; epoll 更加复杂一点但是建立在同样的机制上. 无论何时用户应用程序调用 poll, select, 或者 epoll_ctl,[[24](#)] 内核调用这个系统调用所引用的所有文件的 poll 方法, 传递相同的 poll_table 到每个. poll_table 结构只是对一个函数的封装, 这个函数建立了实际的数据结构. 那个数据结构, 对于 poll和 select, 是一个内存页的链表, 其中包含 poll_table_entry 结构. 每个 poll_table_entry 持有被传递给 poll_wait 的 struct file 和 wait_queue_head_t 指针, 以及一个关联的等待队列入口. 对 poll_wait 的调用有时还添加这个进程到给定的等待队列. 整个的结构必须由内核维护以至于这个进程可被从所有的队列中去除, 在 poll 或者 select 返回之前.
如果被轮询的驱动没有一个指示 I/O 可不阻塞地发生, poll 调用简单地睡眠直到一个它所在的等待队列(可能许多)唤醒它.
在 poll 实现中有趣的是驱动的 poll 方法可能被用一个 NULL 指针作为 poll_table 参数. 这个情况出现由于几个理由. 如果调用 poll 的应用程序已提供了一个 0 的超时值(指示不应当做等待), 没有理由来堆积等待队列, 并且系统简单地不做它. poll_table 指针还被立刻设置为 NULL 在任何被轮询的驱动指示可以 I/O 之后. 因为内核在那一点知道不会发生等待, 它不建立等待队列链表.
当 poll 调用完成, poll_table 结构被去分配, 并且所有的之前加入到 poll 表的等待队列入口被从表和它们的等待队列中移出.
我们试图在图poll 背后的数据结构中展示包含在轮询中的数据结构; 这个图是真实数据结构的简化地表示, 因为它忽略了一个 poll 表地多页性质并且忽略了每个 poll_table_entry 的文件指针.
图 6.1. poll 背后的数据结构
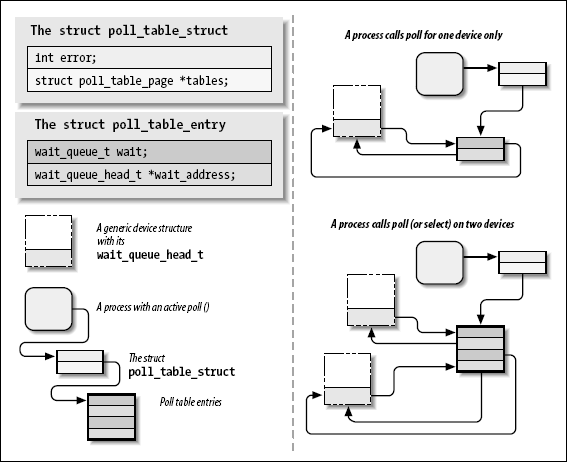
在此, 可能理解在新的系统调用 epoll 后面的动机. 在一个典型的情况中, 一个对 poll 或者 select 的调用只包括一组文件描述符, 所以设置数据结构的开销是小的. 但是, 有应用程序在那里, 它们使用几千个文件描述符. 在这时, 在每次 I/O 操作之间设置和销毁这个数据结构变得非常昂贵. epoll 系统调用家族允许这类应用程序建立内部的内核数据结构只一次, 并且多次使用它们.
[[23](#)] 实际上, epoll 是一组 3 个调用, 都可用来获得查询功能. 但是, 由于我们的目的, 我们可认为它是一个调用.
[[24](#)] 这是建立内部数据结构为将来调用 epoll_wait 的函数.