

javaеҫ®еҚҡзҲ¬иҷ«2--еҰӮдҪ•жҠ“еҸ–HTMLйЎөйқў
дёҖгҖҒеҶҷеңЁеүҚйқў
дёҠзҜҮж–Үз« д»ҘзҪ‘жҳ“еҫ®еҚҡзҲ¬иҷ«дёәдҫӢпјҢз»ҷеҮәдәҶдёҖдёӘеҫҲз®ҖеҚ•зҡ„еҫ®еҚҡзҲ¬иҷ«зҡ„зҲ¬еҸ–иҝҮзЁӢпјҢеӨ§жҰӮиҜҙжҳҺдәҶзҪ‘з»ңзҲ¬иҷ«е…¶е®һд№ҹе°ұиҝҷд№ҲеӣһдәӢпјҢжҲ–и®ёеҲқж¬ЎзңӢеҲ°иҝҷдёӘдҫӢеӯҗи§үеҫ—жңүдәӣеӨҚжқӮпјҢдёҚиҝҮжІЎжңүе…ізі»пјҢдёҠзҜҮж–Үз« з»ҷзҡ„дҫӢеӯҗеҸӘжҳҜи®©еӨ§е®¶еҜ№зҲ¬иҷ«иҝҮзЁӢжңүжүҖдәҶи§ЈгҖӮжҺҘдёӢжқҘзҡ„зі»еҲ—йҮҢпјҢе°ҶдёҖжӯҘдёҖжӯҘең°еү–жһҗжҜҸдёӘиҝҮзЁӢгҖӮ
зҲ¬иҷ«жҖ»дҪ“жөҒзЁӢеңЁдёҠзҜҮж–Үз« е·Із»ҸиҜҙеҫ—еҫҲжё…жҘҡдәҶпјҢжІЎжңүзңӢиҝҮзҡ„жңӢеҸӢеҸҜд»ҘеҺ»зңӢдёӢпјҡгҖҗзҪ‘з»ңзҲ¬иҷ«гҖ‘[java]еҫ®еҚҡзҲ¬иҷ«пјҲдёҖпјүпјҡзҪ‘жҳ“еҫ®еҚҡзҲ¬иҷ«пјҲиҮӘе®ҡд№үе…ій”®еӯ—зҲ¬еҸ–еҫ®еҚҡдҝЎжҒҜж•°жҚ®пјү
зҺ°еңЁеҶҚеӣһйЎҫдёӢзҲ¬иҷ«иҝҮзЁӢпјҡ
step1: йҖҡиҝҮиҜ·жұӮurlеҫ—еҲ°htmlзҡ„stringпјҢз”ЁhttpClient-4.3.1е·Ҙе…·пјҢеҗҢж—¶и®ҫзҪ®socketи¶…ж—¶е’ҢиҝһжҺҘи¶…ж—¶connectTimeoutпјҢжң¬ж–Үе°ҶиҜҰи§ЈжӯӨжӯҘйӘӨгҖӮ
step2: еҜ№дәҺдёҠжӯҘеҫ—еҲ°зҡ„htmlпјҢйӘҢиҜҒжҳҜеҗҰдёәеҗҲжі•HTMLпјҢеҲӨж–ӯжҳҜеҗҰдёәжңүж•ҲжҗңзҙўйЎөйқўпјҢеӣ дёәжңүдәӣиҜ·жұӮзҡ„htmlйЎөйқўдёҚеӯҳеңЁгҖӮ
step3: жҠҠhtmlиҝҷдёӘstringеӯҳж”ҫеҲ°жң¬ең°пјҢеҶҷе…Ҙtxtж–Ү件пјӣ
step4: д»Һtxtж–Ү件解жһҗеҫ®еҚҡж•°жҚ®пјҡuseridпјҢtimestampвҖҰвҖҰи§ЈжһҗиҝҮзЁӢжүҚжҳҜйҮҚзӮ№пјҢеҜ№дәҺдёҚеҗҢзҪ‘йЎөз»“жһ„зҡ„еҲҶжһҗеҸҠзү№еҫҒжҸҗеҸ–пјҢе°ҶеңЁзі»еҲ—дёүдёӯиҜҰз»Ҷи®Іи§ЈгҖӮ
step5: и§ЈжһҗеҮәжқҘзҡ„ж•°жҚ®ж”ҫе…Ҙtxtе’ҢxmlдёӯпјҢиҝҷйҮҢдё»иҰҒjsoupи§ЈжһҗhtmlпјҢdom4jе·Ҙе…·иҜ»еҶҷxmlпјҢе°ҶеңЁзі»еҲ—еӣӣдёӯи®Іи§ЈгҖӮ
然еҗҺеңЁзі»еҲ—дә”дёӯдјҡз»ҷеҮәдёҖдәӣйҳІжӯўиў«еўҷзҡ„ж–№жі•пјҢдҪҝз”Ёд»ЈзҗҶIPи®ҝй—®жҲ–и§Јжһҗжң¬ең°IPж•°жҚ®еә“пјҲеүҚжҸҗжҳҜдҪ жңүеӯҳж”ҫзҡ„IPж•°жҚ®еә“пјүпјҢеҗҺйқўеҶҚиҜҙгҖӮ
дәҢгҖҒHttpClientе·Ҙе…·еҢ…
жҗһиҝҮwebејҖеҸ‘зҡ„жңӢеҸӢеҜ№иҝҷдёӘеә”иҜҘеҫҲзҶҹжӮүдәҶпјҢдёҚйңҖиҰҒеҶҚеӨҡиҜҙпјҢиҝҷжҳҜдёӘеҫҲеҹәжң¬зҡ„е·Ҙе…·еҢ…пјҢдёҖдёӘд»Јз Ғзә§Httpе®ўжҲ·з«Ҝе·Ҙе…·пјҢеҸҜд»ҘдҪҝз”Ёе…¶жЁЎжӢҹжөҸи§ҲеҷЁеҗ‘httpжңҚеҠЎеҷЁеҸ‘йҖҒиҜ·жұӮгҖӮHttpClientжҳҜHttpComponents(з®Җз§°hc)йЎ№зӣ®е…¶дёӯзҡ„дёҖйғЁеҲҶпјҢеҸҜд»ҘзӣҙжҺҘдёӢиҪҪ组件гҖӮдҪҝз”ЁHttpClientиҝҳйңҖиҰҒHttpCoreпјҢеҗҺиҖ…еҢ…жӢ¬HttpиҜ·жұӮдёҺHttpе“Қеә”д»Јз Ғе°ҒиЈ…гҖӮе®ғдҪҝе®ўжҲ·з«ҜеҸ‘йҖҒhttpиҜ·жұӮеҸҳеҫ—е®№жҳ“пјҢеҗҢж—¶д№ҹдјҡжӣҙеҠ ж·ұе…ҘзҗҶи§ЈhttpеҚҸи®®гҖӮ
еңЁиҝҷйҮҢеҸҜд»ҘдёӢиҪҪHttpComponents组件пјҡhttp://hc.apache.org/пјҢдёӢиҪҪеҗҺзӣ®еҪ•з»“жһ„пјҡ
йҰ–е…ҲиҰҒжіЁж„Ҹзҡ„жңүд»ҘдёӢеҮ зӮ№пјҡ
1.httpclientй“ҫжҺҘеҗҺйҮҠж”ҫй—®йўҳеҫҲйҮҚиҰҒпјҢе°ұи·ҹз”Ёdatabase connectionиҰҒйҮҠж”ҫиө„жәҗдёҖж ·гҖӮ
2.httpsзҪ‘з«ҷдҪҝз”ЁsslеҠ еҜҶдј иҫ“пјҢиҜҒд№ҰеҜје…ҘиҰҒжіЁж„ҸгҖӮ
3.еҜ№дәҺhttpеҚҸи®®иҰҒжңүеҹәжң¬зҡ„дәҶи§ЈпјҢжҜ”еҰӮhttpзҡ„200,301,302,400,404,500зӯүиҝ”еӣһд»Јз Ғж—¶д»Җд№Ҳж„ҸжҖқпјҲиҝҷдёӘжҳҜжңҖеҹәжң¬зҡ„пјүпјҢиҝҳжңүcookieе’ҢsessionжңәеҲ¶пјҲиҝҷдёӘеңЁд№ӢеҗҺзҡ„pythonзҲ¬иҷ«зі»еҲ—дёүвҖңжЁЎжӢҹзҷ»еҪ•вҖқзҡ„ж–№жі•йңҖиҰҒжҠ“еҸ–ж•°жҚ®еҢ…еҲҶжһҗпјҢдё»иҰҒе°ұжҳҜзңӢcookieиҝҷдәӣдёңиҘҝпјҢиҰҒеӯҰдјҡеҲҶжһҗж•°жҚ®еҢ…пјү
4.httpclientзҡ„redirectпјҲйҮҚе®ҡеҗ‘пјүзҠ¶жҖҒй»ҳи®ӨжҳҜиҮӘеҠЁзҡ„пјҢиҝҷеңЁеҫҲеӨ§зЁӢеәҰдёҠз»ҷејҖеҸ‘иҖ…еҫҲеӨ§зҡ„ж–№дҫҝпјҲеҰӮдёҖдәӣжҺҲжқғиҺ·еҫ—зҡ„cookieпјүпјҢдҪҶжңүж—¶йңҖиҰҒжүӢеҠЁи®ҫзҪ®пјҢжҜ”еҰӮжңүж—¶дјҡйҒҮеҲ°CircularRedictExceptionејӮеёёпјҢеҮәзҺ°иҝҷж ·зҡ„жғ…еҶөжҳҜеӣ дёәиҝ”еӣһзҡ„еӨҙж–Ү件дёӯlocationеҖјжҢҮеҗ‘д№ӢеүҚйҮҚеӨҚең°еқҖпјҲз«ҜеҸЈеҸ·еҸҜд»ҘдёҚеҗҢпјүпјҢеҜјиҮҙеҸҜиғҪдјҡеҮәзҺ°жӯ»еҫӘзҺҜйҖ’еҪ’йҮҚе®ҡеҗ‘пјҢжӯӨж—¶еҸҜд»ҘжүӢеҠЁе…ій—ӯ:method.setFollowRedirects(false)гҖӮ
5.жЁЎжӢҹжөҸи§ҲеҷЁзҷ»еҪ•пјҢиҝҷдёӘеҜ№дәҺзҲ¬иҷ«жқҘиҜҙзӣёеҪ“йҮҚиҰҒпјҢжңүзҡ„зҪ‘з«ҷдјҡе…ҲеҲӨеҲ«з”ЁжҲ·зҡ„иҜ·жұӮжҳҜеҗҰжқҘиҮӘжөҸи§ҲеҷЁпјҢеҰӮжһңдёҚжҳҜзӣҙжҺҘжӢ’з»қи®ҝй—®пјҢиҝҷдёӘзӣҙжҺҘдјӘиЈ…жҲҗжөҸи§ҲеҷЁи®ҝй—®е°ұеҘҪдәҶпјҢеҘҪз”ЁhttpclientжҠ“еҸ–дҝЎжҒҜж—¶еңЁеӨҙйғЁеҠ е…ҘдёҖдәӣдҝЎжҒҜпјҡheader.put(вҖңUser-AgentвҖқ, вҖңMozilla/5.0 (Windows NT 6.1)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36)вҖқ);
6.еҪ“postиҜ·жұӮжҸҗдәӨж•°жҚ®ж—¶иҰҒж”№еҸҳй»ҳи®Өзј–з ҒпјҢдёҚ然жҸҗдәӨдёҠеҺ»зҡ„ж•°жҚ®дјҡеҮәзҺ°д№ұз ҒгҖӮйҮҚеҶҷpostMethodзҡ„setContentCharSet()ж–№жі•е°ұеҸҜд»ҘдәҶгҖӮ
дёӢйқўз»ҷеҮ дёӘдҫӢеӯҗпјҡ
пјҲ1пјүеҸ‘postиҜ·жұӮи®ҝй—®жң¬ең°еә”з”Ёе№¶ж №жҚ®дј йҖ’еҸӮж•°дёҚеҗҢиҝ”еӣһдёҚеҗҢз»“жһң
public void post() {
//еҲӣе»әй»ҳи®ӨhttpClientе®һдҫӢ
CloseableHttpClient httpclient = HttpClients.createDefault();
//еҲӣе»әhttpPost
HttpPost httppost = new HttpPost("http://localhost:8088/weibo/Ajax/service.action");
//еҲӣе»әеҸӮж•°йҳҹеҲ—
List<keyvalue> formparams = new ArrayList<keyvalue>();
formparams.add(new BasicKeyValue("name", "alice"));
UrlEncodeFormEntity uefEntity;
try {
uefEntity = new UrlEncodeFormEntity(formparams, "utf-8");
httppost.setEntity(uefEntity);
System.out.println("executing request " + httppost.getURI());
CloseableHttpResponse response = httpclient.execute(httppost);
try {
HttpEntity entity = response.getEntity();
if(entity != null) {
System.out.println("Response content: " + EntityUtils.toString(entity, "utf-8"));
}
} finally {
response.close();
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//е…ій—ӯиҝһжҺҘ,йҮҠж”ҫиө„жәҗ
try {
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}пјҲ2пјүеҸ‘getиҜ·жұӮ
public void get() {
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
//еҲӣе»әhttpget
HttpGet httpget = new HttpGet("http://www.baidu.com");
System.out.println("executing request " + httpget.getURI());
//жү§иЎҢgetиҜ·жұӮ
CloseableHttpResponse response = httpclient.execute(httpget);
try {
//иҺ·еҸ–е“Қеә”е®һдҪ“
HttpEntity entity = response.getEntity();
//е“Қеә”зҠ¶жҖҒ
System.out.println(response.getStatusLine());
if(entity != null) {
//е“Қеә”еҶ…е®№й•ҝеәҰ
System.out.println("response length: " + entity.getContentLength());
//е“Қеә”еҶ…е®№
System.out.println("response content: " + EntityUtils.toString(entity));
}
} finally {
response.close();
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//е…ій—ӯй“ҫжҺҘ,йҮҠж”ҫиө„жәҗ
try {
httpclient.close();
} catch(IOException e) {
e.printStackTrace();
}
}
}пјҲ3пјүи®ҫзҪ®header
жҜ”еҰӮеңЁзҷҫеәҰжҗңзҙўвҖқhttpclientвҖқе…ій”®еӯ—пјҢзҷҫеәҰдёҖдёӢпјҢеҸ‘йҖҒиҜ·жұӮпјҢchromeйҮҢжҢүF12ејҖеҸ‘иҖ…е·Ҙе…·пјҢеңЁNetworkйҖүйЎ№еҚЎжҹҘзңӢеҲҶжһҗж•°жҚ®еҢ…пјҢеҸҜд»ҘзңӢеҲ°ж•°жҚ®еҢ…зӣёе…ідҝЎжҒҜпјҢжҜ”еҰӮиҝҷйҮҢиҜ·жұӮеӨҙRequest HeaderйҮҢзҡ„дҝЎжҒҜгҖӮ
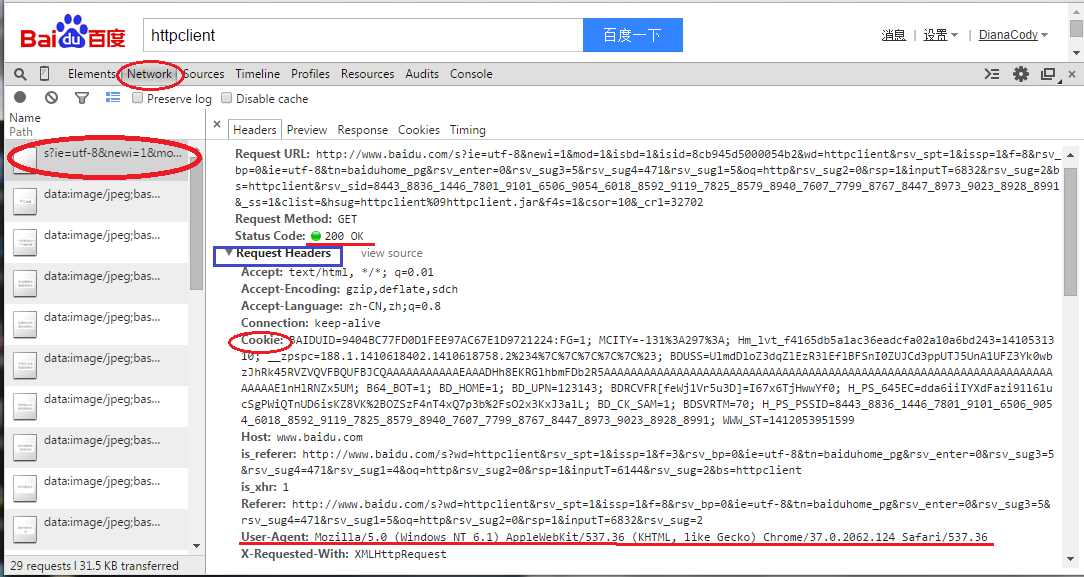
жңүж—¶йңҖиҰҒжЁЎжӢҹжөҸи§ҲеҷЁзҷ»еҪ•пјҢжҠҠheaderи®ҫзҪ®дёҖдёӢе°ұOKпјҢз…§зқҖиҝҷйҮҢж”№еҗ§гҖӮ
public void header() {
HttpClient httpClient = new DefaultHttpClient();
try {
HttpGet httpget = new HttpGet("http://www.baidu.com");
httpget.setHeader("Accept", "text/html, */*; q=0.01");
httpget.setHeader("Accept-Encoding", "gzip, deflate,sdch");
httpget.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
httpget.setHeader("Connection", "keep-alive");
httpget.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36)");
HttpResponse response = httpClient.execute(httpget);
HttpEntity entity = response.getEntity();
System.out.println(response.getStatusLine()); //зҠ¶жҖҒз Ғ
if(entity != null) {
System.out.println(entity.getContentLength());
System.out.println(entity.getContent());
}
} catch (Exception e) {
e.printStackTrace();
}
}дёүгҖҒйҖҡиҝҮurlеҫ—еҲ°htmlйЎөйқў
еүҚйқўиҜҙдәҶиҝҷд№ҲеӨҡпјҢйғҪжҳҜдәӣеҮҶеӨҮе·ҘдҪңдё»иҰҒжҳҜHttpClientзҡ„дёҖдәӣеҹәжң¬дҪҝз”ЁпјҢе…¶е®һиҝҳжңүеҫҲеӨҡпјҢзҪ‘дёҠе…¶д»–иө„ж–ҷжӣҙиҜҰз»ҶпјҢд№ҹдёҚжҳҜиҝҷйҮҢиҰҒи®Ізҡ„йҮҚзӮ№гҖӮдёӢйқўжқҘзңӢеҰӮдҪ•йҖҡиҝҮurlжқҘеҫ—еҲ°htmlйЎөйқўпјҢе…¶е®һж–№жі•е·Із»ҸеңЁдёҠдёҖзҜҮж–Үз« дёӯиҜҙиҝҮдәҶпјҡгҖҗзҪ‘з»ңзҲ¬иҷ«гҖ‘[java]еҫ®еҚҡзҲ¬иҷ«пјҲдёҖпјүпјҡзҪ‘жҳ“еҫ®еҚҡзҲ¬иҷ«пјҲиҮӘе®ҡд№үе…ій”®еӯ—зҲ¬еҸ–еҫ®еҚҡдҝЎжҒҜж•°жҚ®пјү
ж–°жөӘеҫ®еҚҡе’ҢзҪ‘жҳ“еҫ®еҚҡпјҡпјҲиҝҷйҮҢе°Өе…¶иҰҒжіЁж„Ҹең°еқҖеҸҠеҸӮж•°пјҒпјү
ж–°жөӘеҫ®еҚҡжҗңзҙўиҜқйўҳең°еқҖпјҡhttp://s.weibo.com/weibo/иӢ№жһңжүӢжңә&nodup=1&page=50
зҪ‘жҳ“еҫ®еҚҡжҗңзҙўиҜқйўҳең°еқҖпјҡhttp://t.163.com/tag/иӢ№жһңжүӢжңә
иҝҷйҮҢеҸӮж•°&nodupе’ҢеҸӮж•°&page=50пјҢиЎЁзӨәд»Һжҗңзҙўз»“жһңиҝ”еӣһзҡ„еүҚ50дёӘhtmlйЎөйқўпјҢд»Һ第50дёӘйЎөйқўејҖе§ӢзҲ¬еҸ–гҖӮд№ҹеҸҜд»Ҙдҝ®ж”№еҸӮж•°зҡ„еҖјпјҢзҲ¬еҸ–зҡ„йЎөйқўдёӘж•°дёҚеҗҢгҖӮ
еңЁиҝҷйҮҢеҶҷдәҶдёүдёӘж–№жі•пјҢеҲҶеҲ«и®ҫзҪ®з”ЁжҲ·cookieгҖҒй»ҳи®ӨдёҖиҲ¬зҡ„ж–№жі•гҖҒд»ЈзҗҶIPж–№жі•пјҢеҹәжң¬жҖқи·Ҝе·®дёҚеӨҡпјҢдё»иҰҒжҳҜеңЁRequestConfigе’ҢCloseableHttpClientзҡ„custom()еҸҜд»ҘиҮӘе®ҡд№үй…ҚзҪ®гҖӮ
/**
* @note дёүз§ҚиҝһжҺҘurl并иҺ·еҸ–htmlзҡ„ж–№жі•(жңүдёҖиҲ¬ж–№жі•,иҮӘе®ҡд№үcookieж–№жі•,д»ЈзҗҶIPж–№жі•)
* @author DianaCody
* @since 2014-09-26 16:03
*
*/
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.net.URISyntaxException;
import java.text.ParseException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.config.CookieSpecs;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.config.Registry;
import org.apache.http.config.RegistryBuilder;
import org.apache.http.cookie.Cookie;
import org.apache.http.cookie.CookieOrigin;
import org.apache.http.cookie.CookieSpec;
import org.apache.http.cookie.CookieSpecProvider;
import org.apache.http.cookie.MalformedCookieException;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.DefaultProxyRoutePlanner;
import org.apache.http.impl.cookie.BestMatchSpecFactory;
import org.apache.http.impl.cookie.BrowserCompatSpec;
import org.apache.http.impl.cookie.BrowserCompatSpecFactory;
import org.apache.http.protocol.HttpContext;
import org.apache.http.util.EntityUtils;
public class HTML {
/**й»ҳи®Өж–№жі• */
public String[] getHTML(String url) throws ClientProtocolException, IOException {
String[] html = new String[2];
html[1] = "null";
RequestConfig requestConfig = RequestConfig.custom()
.setSocketTimeout(5000) //socket超时
.setConnectTimeout(5000) //connect超时
.build();
CloseableHttpClient httpClient = HttpClients.custom()
.setDefaultRequestConfig(requestConfig)
.build();
HttpGet httpGet = new HttpGet(url);
try {
CloseableHttpResponse response = httpClient.execute(httpGet);
html[0] = String.valueOf(response.getStatusLine().getStatusCode());
html[1] = EntityUtils.toString(response.getEntity(), "utf-8");
//System.out.println(html);
} catch (IOException e) {
System.out.println("----------Connection timeout--------");
}
return html;
}
/**cookieж–№жі•зҡ„getHTMl() и®ҫзҪ®cookieзӯ–з•Ҙ,йҳІжӯўcookie rejectedй—®йўҳ,жӢ’з»қеҶҷе…Ҙcookie --йҮҚиҪҪ,3еҸӮж•°:url, hostName, port */
public String getHTML(String url, String hostName, int port) throws URISyntaxException, ClientProtocolException, IOException {
//йҮҮз”Ёз”ЁжҲ·иҮӘе®ҡд№үзҡ„cookieзӯ–з•Ҙ
HttpHost proxy = new HttpHost(hostName, port);
DefaultProxyRoutePlanner routePlanner = new DefaultProxyRoutePlanner(proxy);
CookieSpecProvider cookieSpecProvider = new CookieSpecProvider() {
public CookieSpec create(HttpContext context) {
return new BrowserCompatSpec() {
@Override
public void validate(Cookie cookie, CookieOrigin origin) throws MalformedCookieException {
//Oh, I am easy...
}
};
}
};
Registry<CookieSpecProvider> r = RegistryBuilder
.<CookieSpecProvider> create()
.register(CookieSpecs.BEST_MATCH, new BestMatchSpecFactory())
.register(CookieSpecs.BROWSER_COMPATIBILITY, new BrowserCompatSpecFactory())
.register("easy", cookieSpecProvider)
.build();
RequestConfig requestConfig = RequestConfig.custom()
.setCookieSpec("easy")
.setSocketTimeout(5000) //socket超时
.setConnectTimeout(5000) //connect超时
.build();
CloseableHttpClient httpClient = HttpClients.custom()
.setDefaultCookieSpecRegistry(r)
.setRoutePlanner(routePlanner)
.build();
HttpGet httpGet = new HttpGet(url);
httpGet.setConfig(requestConfig);
String html = "null"; //з”ЁдәҺйӘҢиҜҒжҳҜеҗҰжӯЈеёёеҸ–еҲ°html
try {
CloseableHttpResponse response = httpClient.execute(httpGet);
html = EntityUtils.toString(response.getEntity(), "utf-8");
} catch (IOException e) {
System.out.println("----Connection timeout----");
}
return html;
}
/**proxyд»ЈзҗҶIPж–№жі• */
public String getHTMLbyProxy(String targetUrl, String hostName, int port) throws ClientProtocolException, IOException {
HttpHost proxy = new HttpHost(hostName, port);
String html = "null";
DefaultProxyRoutePlanner routePlanner = new DefaultProxyRoutePlanner(proxy);
RequestConfig requestConfig = RequestConfig.custom()
.setSocketTimeout(5000) //socket超时
.setConnectTimeout(5000) //connect超时
.build();
CloseableHttpClient httpClient = HttpClients.custom()
.setRoutePlanner(routePlanner)
.setDefaultRequestConfig(requestConfig)
.build();
HttpGet httpGet = new HttpGet(targetUrl);
try {
CloseableHttpResponse response = httpClient.execute(httpGet);
int statusCode = response.getStatusLine().getStatusCode();
if(statusCode == HttpStatus.SC_OK) { //зҠ¶жҖҒз Ғ200: OK
html = EntityUtils.toString(response.getEntity(), "gb2312");
}
response.close();
//System.out.println(html); //жү“еҚ°иҝ”еӣһзҡ„html
} catch (IOException e) {
System.out.println("----Connection timeout----");
}
return html;
}
}еӣӣгҖҒйӘҢиҜҒжҳҜеҗҰеӯҳеңЁHTMLйЎөйқў
жңүж—¶иҜ·жұӮзҡ„htmlдёҚеӯҳеңЁпјҢжҜ”еҰӮеңЁдёҠзҜҮж–Үз« дёӯжҸҗеҲ°зҡ„жғ…еҶөдёҖж ·пјҢиҝҷйҮҢеҠ дёӘеҲӨж–ӯеҮҪж•°гҖӮ
private boolean isExistHTML(String html) throws InterruptedException {
boolean isExist = false;
Pattern pNoResult = Pattern.compile("u6ca1u6709u627eu5230u76f8"
+ "u5173u7684u5faeu535au5462uff0cu6362u4e2a"
+ "u5173u952eu8bcdu8bd5u5427uff01"); //жІЎжңүжүҫеҲ°зӣёе…ізҡ„еҫ®еҚҡе‘ўпјҢжҚўдёӘе…ій”®иҜҚиҜ•иҜ•еҗ§пјҒпјҲhtmlйЎөйқўдёҠзҡ„дҝЎжҒҜпјү
Matcher mNoResult = pNoResult.matcher(html);
if(!mNoResult.find()) {
isExist = true;
}
return isExist;
}дә”гҖҒзҲ¬еҸ–еҫ®еҚҡиҝ”еӣһзҡ„HTMLеӯ—з¬ҰдёІ
жҠҠжүҖжңүhtmlеҶҷеҲ°жң¬ең°txtж–Ү件йҮҢгҖӮ
/**жҠҠжүҖжңүhtmlеҶҷеҲ°жң¬ең°txtж–Ү件еӯҳеӮЁ */
public static void writeHTML2txt(String html, int num) throws IOException {
String savePath = "e:/weibo/weibohtml/" + num + ".txt";
File f = new File(savePath);
FileWriter fw = new FileWriter(f);
BufferedWriter bw = new BufferedWriter(fw);
bw.write(html);
bw.close();
}зҲ¬дёӢжқҘзҡ„htmlпјҡ
жқҘзңӢдёӢжҜҸдёӘhtmlйЎөйқўпјҢеӨҙйғЁдёҖдәӣж•°жҚ®пјҡ

еҫ®еҚҡжӯЈж–Үж•°жҚ®дҝЎжҒҜпјҢжҳҜдёӘjsonж јејҸпјҢеҢ…еҗ«дёҖдәӣдҝЎжҒҜпјҡ

иҮідәҺеҰӮдҪ•и§ЈжһҗжҸҗеҸ–е…ій”®ж•°жҚ®пјҢеңЁдёӢзҜҮж–Үз« дёӯеҶҚеҶҷгҖӮ
еҺҹеҲӣж–Үз« пјҢиҪ¬иҪҪиҜ·жіЁжҳҺеҮәеӨ„пјҡhttp://blog.csdn.net/dianacody/article/details/39695285