

激动人心!在网页上通过语音输入文字 - HTML5 Web
很久前我曾经提到过Web Speech API,现在Chrome刚刚发布的25版本已经为桌面和Android提供了对此API的支持,这对Web开发者来说无疑是一个具有里程碑意义的事件,因为我们可以直接在Web App中原生使用语音识别技术,Web应用的新时代将会由此开启。
控制不住激动的心情,下面我会通过示例马上给大家介绍此API的详细信息。
Google专门提供了一个原生示例,来演示Web Speech API。
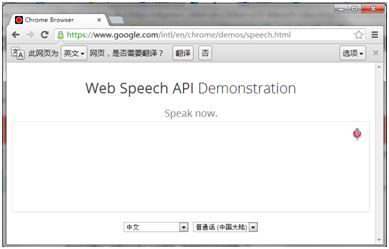
我们来看看实现代码。首先需要判断浏览器是否支持Web Speech API,我们通过window下是否存在webkitSpeechRecognition对象来判断。如果支持,我们创建webkitSpeechRecognition对象,并设置相关属性和事件。
if (!("webkitSpeechRecognition" in window)) {
upgrade();
} else {
var recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.onstart = function() { ... }
recognition.onresult = function(event) { ... }
recognition.onerror = function(event) { ... }
recognition.onend = function() { ... }
...
continuous属性的默认值是false,代表当用户停止说话时,语音识别将结束。在这个演示中 ,我们将它设置为true,这样即便用户暂时停止讲话,语音识别也将会继续。
interimResults属性的默认值也是false,代表语音识别器的返回值不会改变。在这个演示中,我们把它设置为true,这样随着我们的输入,识别结果有可能会改变。仔细观看演示,灰色的文字是临时性的,有时会改变,而黑色文本是最终结果,不会改变。
当我们点击麦克风按钮时,会触发如下代码:
function startButton(event) {
...
final_transcript = "";
recognition.lang = select_dialect.value;
recognition.start();
我们用recognition.lang来设置语音识别的语言,在这个示例中默认为HTML页面的语言,通过下拉列表用户可以进行更换,例如“cmn-Hans-CN”代表普通话,而“en-us”代表美式英语。Chrome浏览器的语音识别支持众多的语言,非常强大。
设置语言后,我们调用recognition.start()来激活语音识别。一旦开始捕获音频,它调用onstart方法,然后为每一个新的结果集调用onresult方法进行处理。
recognition.onresult = function(event) {
var interim_transcript = "";
for (var i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
final_transcript += event.results[i][0].transcript;
} else {
interim_transcript += event.results[i][0].transcript;
}
}
final_transcript = capitalize(final_transcript);
final_span.innerHTML = linebreak(final_transcript);
interim_span.innerHTML = linebreak(interim_transcript);
};
}
这个handler把结果分成两个字符串:final_transcript和interim_transcript。这里调用Linebreak方法来进行分段。最后,它会将final_transcript设置为final_span的innerHTML,显示为黑色;而将interim_transcript设置为interim_span的innerHTML,显示为灰色。
以上就是功能核心代码。当recognition.start()被调用时,麦克风识别动画开始显示,同时Chrome需要获得用户对麦克风的授权。有一点非常重要的是,HTTPS网页不需要反复获取授权,而HTTP网页需要**。
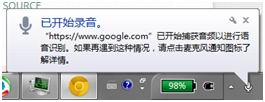
当开始语音输入、捕获和识别时,我们还会在桌面右下角看到相关提示。

从现在开始,Web App的开发者们可以好好考虑考虑,利用Web Speech API能够开发出什么样有趣的产品,或者为自己的产品添加什么有趣的功能?
提示:如果要体验文中的Demo,请使用Chrome 25以上的版本或者Chrome Canary。
相关文章:《对HTML5 Device API相关规范的解惑》
参考文章:VOICE DRIVEN WEB APPS: INTRODUCTION TO THE WEB SPEECH API
转载请标明出处:蒋宇捷的专栏