

快速排序的基本思想
快速排序算法是一种不稳定的排序算法。其时间复杂度为O(nlogn),最坏复杂度为O(n^2);快排的平均空间复杂度为O(logn),关于空间界的论断来自于《编程珠玑第2版》第113页。但是其最坏空间复杂度为O(n)。
快速排序的基本思想是使用两个指针来遍历待排序的数组,**根据两个指针遍历的方向可以分为两类:第一,两个指针从待排序数组的同一个方向遍历。第二,两个指针分别从带排序数组的两端进行遍历。下列的几种算法都可以归为这两类中的某类。
下图给出的是两个指针从同一方向遍历时的状态。下图的第一个图给出的是循环过程中的状态,在循环中,low指向的是小于枢纽的那部分元素的最右端,high在未排序的部分遍历。循环直到high指针到达right的位置(数组的最右端),如下图第二个图所示。此时数组除了枢纽pivot被划分为两部分:小于pivot的和大于等于pivot的。然后将low和枢纽元素交换就可以得到本次排序的第一趟结果,如下图的第三幅图所示。
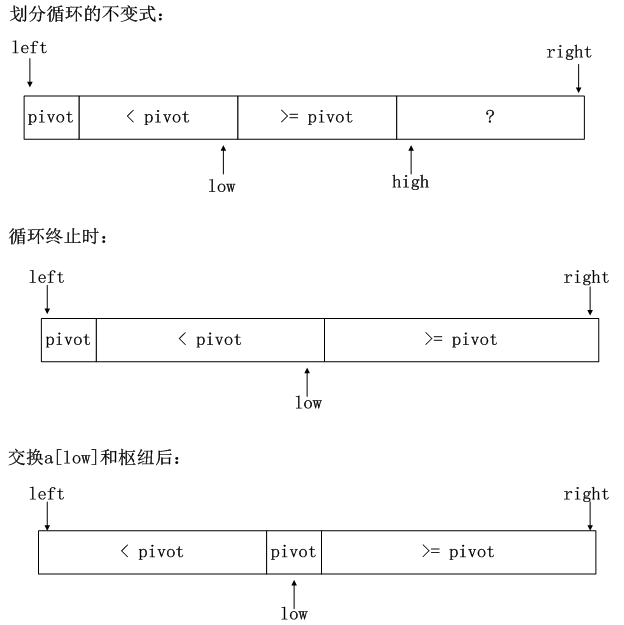
当从两个方向分别遍历数组时,下图是遍历的循环过程状态。循环时,low向右移动,high向左移动。
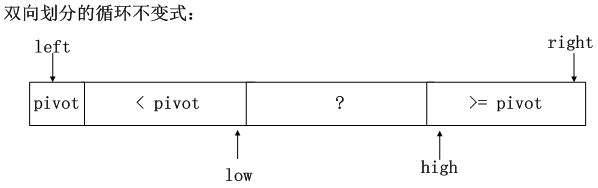
Hoare的变形版本(空穴法)
假设待排序的数组为a[],快速排序算法最常见的做法是将第一个元素设置为枢纽元。设置两个指针low和high,它们分别指向待排序的数组的低和高位:
(1)high向左移动找小于枢纽的元素,找到后(找到的是a[high])将其值存储在a[low]中,那么此时high所指的元素其实没有意义了,因为a[high]已经存储到了a[low]中,那么可以认为high所指的是空穴,该空穴将存储(2)中low指针找到的大于枢纽的元素。
(2)然后low向右移动找大于枢纽元的元素,找到后(a[low])将其存储在a[high]中(high指的是空穴),同样的,此时a[low]存的数没有意义了,因为该数已经存到了a[high]中,那么low所指的是空穴,该空穴存储下次high找到的小于枢纽的数。
(3)当两个指针相遇时,上述循环终止,此时low指向空穴,将枢纽存入空穴。这就是一次递归过程。递归该过程。
例如,对数组5 1 9 3 8 4 7进行排序,给出一次递归的过程:
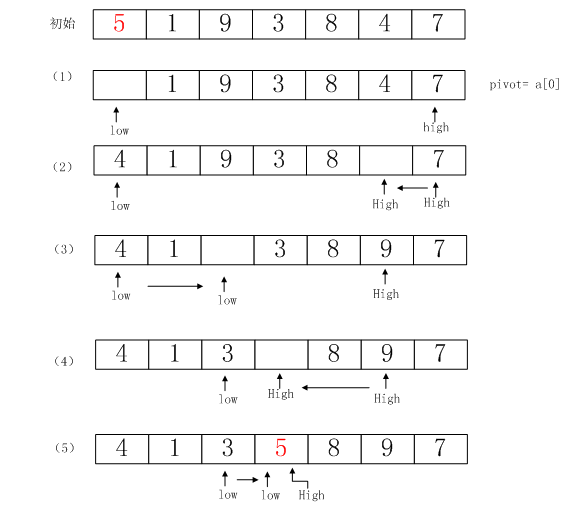
第1步:low指向5,high指向7。选取第一个元素5为枢纽pivot,则可以认为第一个元素处是空穴,即low指向空穴。
第2步:high向左移动,找到了小于枢纽5的元素4,将这个元素存储到low所指的空穴中,此时,high所指的位置成了空穴。
第3步:low向右移动,找到了大于枢纽5的元素9,将这个元素存储到high所指的空穴中,此时,low所指的位置成了空穴。
第4步:重复第2步,high找到的小元素3存到了low所指的空穴中,high所指位置成为空穴。
第5步:low指针此时仍小于high,所以low向右移动一次,此时vec[low]等于枢纽,low == high,那么内层第二个while循环将不再执行第二次。此时,low和high都指向空穴。外层while循环终止,将枢纽元素放入low所指的空穴。可以看到,该算法一趟排序后枢纽被放在了最终的位置上**(这里的枢纽为5)。
递归算法
注意:该算法的内层while循环的判断条件如果没有等于号的话,遇到等于枢纽的元素会死循环,和这个算法的实现对比下。
如下是该思想的代码:
//快速排序版本一,vec[0]为枢纽
template<typename T>
int PartionQuickSort1(vector<T> &vec, int left, int right) {
T pivot = vec[left];//设置枢纽
int low = left;
int high = right;
while (low < high) {//注意两个内层while的顺序不能换
while (low < high && vec[high] >= pivot) //这里是>=不能使>,否则当数组元素等于枢纽时会死循环
high--;
vec[low] = vec[high];//将找到的小于于枢纽的元素存到high所指的空穴
while (low < high && vec[low] <= pivot) //这里是<=不能使<,否则当数组元素等于枢纽时会死循环
low++;
vec[high] = vec[low];//将找到的大于枢纽的元素存到high所指的空穴
}
vec[low] = pivot;
return low; //返回枢纽的位置
}
template<typename T>
void QuickSort1(vector<T> &vec, int left, int right) {
if (left < right) {
int partion = PartionQuickSort1(vec, left, right);
QuickSort1(vec, left, partion - 1);
QuickSort1(vec, partion + 1, right);
}
}
/*
该算法需要注意的是在PartionQuickSort1函数中两个内层while的顺序不能交换,否则会覆盖元素。如果两个内层while循环交换,
例如在上边的演示中,首先low指针右移,找到9,则要将a[low] = 9 存入a[high] = 7的位置,这样7还没被保存,那么该值就丢失了。
算法中之所以可以在循环中赋值是因为枢纽元素值已经保存在了pivot中。
*/
//如果将待排序数组的最右侧元素设为枢纽,那么则内层while循环需要交换,如下程序:
template<typename T>
int PartionQuickSort12(vector<T> &vec, int left, int right) {
T pivot = vec[right]; //设置最右侧元素为枢纽
int low = left;
int high = right;
while (low < high) { //注意下面内层while的顺序
while (low < high && vec[low] <= pivot)
low++;
vec[high] = vec[low];
while (low < high && vec[high] >= pivot)
high--;
vec[low] = vec[high];
}
vec[low] = pivot;
return low;
}
template<typename T>
void QuickSort12(vector<T> &vec, int left, int right) {
if (left < right) {
int partion = PartionQuickSort1(vec, left, right);
QuickSort12(vec, left, partion - 1);
QuickSort12(vec, partion + 1, right);
}
}
非递归算法
以左侧元素为枢纽,非递归算法:利用STL栈适配器stack
//快速排序的非递归算法,以第一个元素为枢纽
//非递归算法用一个stack辅助数据结构,栈存放下一次要排序的两个下标
template<typename T>
void QuickSort1NoRecursion(vector<T>& vec, int left, int right) {
stack<int> st;
//注意每次入栈都将较大的下标先入栈,那么
//每次出栈相反:较大的小标会后出栈
st.push(right);
st.push(left);
int maxsize = 0;
while (!st.empty()) {
if (st.size() > maxsize)
maxsize = st.size();
int low = st.top(); st.pop();
int high = st.top(); st.pop();
//cout << low << " " << high << endl;
int mid = PartionQuickSort1(vec, low, high);
if (mid - 1 > low) {
st.push(mid - 1);
st.push(low);
}
if (mid + 1 < high) {
st.push(high);
st.push(mid + 1);
}
}
//cout << "max stack size: " << maxsize << endl;
return;
}
Hoare版本(直接交换元素)
这里给出Hoare提出的快速排序算法,其思想与上述的类似,也是两个指针low和high分别指向待排序数组的低位和高位,然后low向右遍历找大于枢纽的、high向左遍历找小于枢纽的,只是这里是当找到了就将a[low]和a[high]交换,而不是产生空穴。
代码如下:
//快速排序版本二
template<typename T>
void SwapQuickSort(T &a, T &b) {
T temp = a;
a = b;
b = temp;
}
template<typename T>
int PartionQuickSort2(vector<T> &vec, int left, int right) {
T pivot = vec[left];
int low = left - 1;
int high = right + 1;
for (; ;) {
do {
high--;
}while (vec[high] > pivot); //这里没有等于,见“对比版本二和版本三”的下边分析
do {
low++;
}while (vec[low] < pivot); //这里没有等于,见“对比版本二和版本三”的下边分析
/*这里的循环是错误的,当某元素等于pivot时会死循环
while (vec[high] > pivot)
high--;
while (vec[low] < pivot)
low++;
*/
if (low < high)
SwapQuickSort(vec[low], vec[high]);
else
return high;
}
}
template<typename T>
void QuickSort2(vector<T> &vec, int left, int right) {
if (left < right) {
int partion = PartionQuickSort2(vec, left, right);
QuickSort2(vec, left, partion);
/*
注意上一行与版本一不同,不是QuickSort2(vec, left, partion - 1)
因为版本一中每次排序后会将枢纽pivot放在最终的位置上,但是该算法
只保证每次排序后枢纽位于待排序数组的有半部分,不保证pivot在最终
的位置上,因此要将Partion所指的位置加入下一次排序
*/
QuickSort2(vec, partion + 1, right);
}
}
例如,对数组5 1 9 3 8 4 7进行排序,第一次排序的过程:
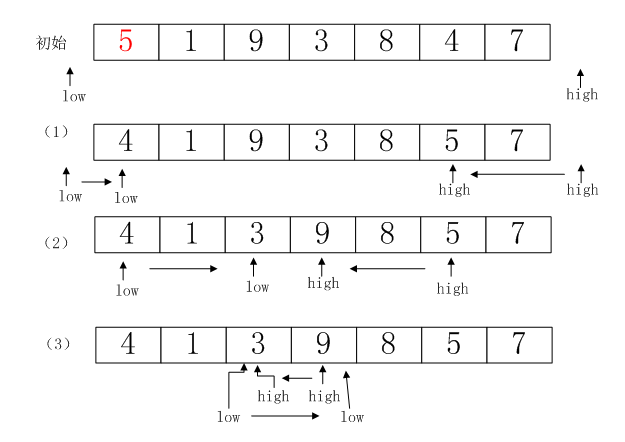
初始状态:low指向数组前一个位置,high指向数组后一个位置。枢纽为第一个元素5。
第1步:high向左移动,找到不大于枢纽的元素4,停止;low向右移动,找到不小于枢纽的元素5,停止;此时low < high所以将它们指向的元素交换。结果如(1)图所示。
第2步:重复第1步,high在3所在位置停下,low在9所在位置停下;此时low < high所以将它们指向的元素交换。结果如(2)图所示。
第3步:由于for循环是无条件循环的,因此与版本一不同的是,这里low 会越过high,如(3)图所示;high指向3,low指向9。此时if检测到low不小于high了,则返回high,一次排序结束。
继续给出第二趟排序时,左侧数组元素的排序过程:

可以看出,Hoare排序,每次排序结束后并不保证枢纽在最终的位置上,只保证枢纽位于数组的右半部分,因此Partion所指的位置要进行下一次排序。
算法导论上方法:单向划分
该算法与上边算法最大的不同是:该算法的low和high元素都是从数组开始向后移动,而不是一前一后,且将枢纽设置为最右端的元素。在排序中,low指向已经排序的、小于枢纽的元素的最右位置(那么low的右侧下一个位置就是大于枢纽的了),high指向待排序的数组,当high找到了一个小于等于枢纽的位置,则将low加1(此时low指向了大于枢纽的第一个位置),然后将low和high所指的位置元素交换;交换后low所指的元素小于枢纽(此时,low的右侧下一个位置就是大于枢纽的了),high所指的值大于枢纽,high继续循环。
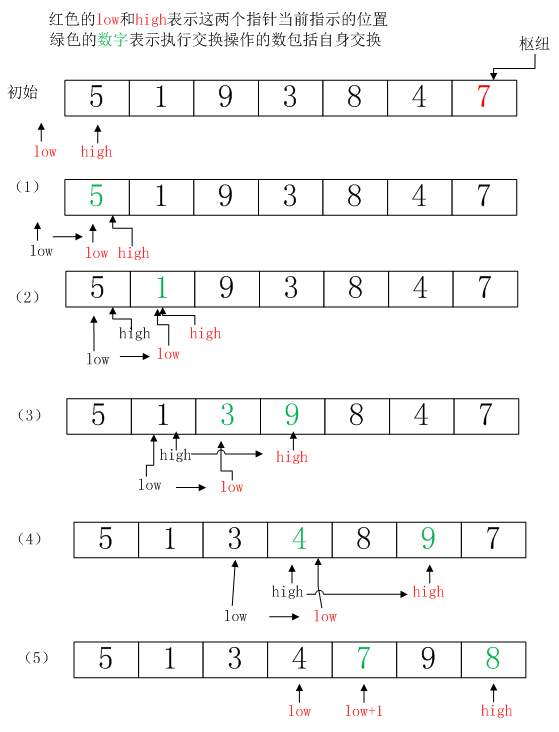
初始状态:low指向数组前一个位置,high指向数组第一个位置,枢纽为最右位置。
第1步:high所指的5小于枢纽7,所以low++,此时high也指向的是5,所以5和5交换,数组不变,如(1)图所示。
第2步:high向右移动到1,1小于枢纽5,所以low++,此时high也指向1,所以1和1交换,数组不变,若(2)图所示。
第3步:high继续右移到3的位置,此时3小于枢纽,所以low++,将low和high所指位置的元素交换,结果如图(3)所示。
第4步:high继续向右移动到4的位置,4小于枢纽,所以low++,将low和high所指位置的元素交换,结果如图(4)所示。
第5步:high在第4步中++后指向了数组最右侧,此时for循环不会再执行,接着执行SwapQuickSort(vec[low + 1], vec[right]),交换low+1和枢纽元素,结果如图(5)所示。
可以看出在每次交换后,low所指的都是已经遍历的、小于枢纽的一系列元素的最右边一个(low的右边下一个元素就大于枢纽了),因此high发现了小于等于枢纽的元素后,交换low和high所指元素,即可将low所指的大元素放到数组右侧,而把high所指的小元素放到数组左侧。该算法和版本一一样,每次排序后都将枢纽元素放在了最终的位置上。
代码如下:
//快速排版本三,算法导论上的方法
template<typename T>
void SwapQuickSort(T &a, T &b) {
T temp = a;
a = b;
b = temp;
}
template<typename T>
int PartionQuickSort3(vector<T> &vec, int left, int right) {
int low = left - 1;
int high;
T pivot = vec[right];
for (high = left; high < right; high++) {
if (vec[high] <= pivot) { //将找到的小于枢纽的元素移到左边
low++;//low++后low指向了数组第一个大于枢纽的位置
//将low所指的、第一个大于枢纽的元素与high所指的小于枢纽的元素交换
SwapQuickSort(vec[low], vec[high]);
}
}
SwapQuickSort(vec[low + 1], vec[right]);
return low + 1;
}
template<typename T>
void QuickSort3(vector<T>& vec, int left, int right) {
if (left < right) {
int partion = PartionQuickSort3(vec, left, right);
QuickSort3(vec, left, partion - 1);
QuickSort3(vec, partion + 1, right);
}
}
这里给出《编程珠玑第2版》第112页的实现方法,与版本三类似,只是这里用的是最左侧的为枢纽元。
template<typename T>
void QuickSort32(vector<T>& vec, int left, int right) {
if (right <= left)
return;
int low = left;
int high;
for (high = left + 1; high <= right; high++) {
if (vec[high] < vec[left])
SwapQuickSort(vec[++low], vec[high]);
}
SwapQuickSort(vec[left], vec[low]);
QuickSort32(vec, left, low - 1);
QuickSort32(vec, low + 1, right);
}
对比版本二和版本三
这里的分析思路来源于《编程珠玑》。
(1)待排序的数都相等
版本三给出的两个指针单向遍历的方法,对于一般待排序序列效果较好,但是如果n个数是相等的话,那么版本三的方法将很糟糕,n-1划分中,每次都需要O(n)才能排序一个元素,总运行时间为O(n^2);而如果使用插入排序,则每次不需要移动元素,总时间为O(n)。而版本二对于相同的待排序序列则可以避免这个问题。
(2)如何处理等于枢纽的元素
注意到版本二中内层的do-while循环,判断条件中没有“等于”,也就是说,对于等于枢纽的元素我们的处理是:遇到等于枢纽的元素时,停止扫描,交换low和high所指的元素。这样做增加了交换的次数,但是这样就将等于枢纽的元素交换到了数组的中间,可以将数组划分为几乎相等的两个数组,总的时间为O(nlogn)。试想,如果遇到等于枢纽元不停止的话,对于所有元素都相等的待排序数组,首先high执行do-while循环,直到待排序数组的最左侧与low相遇,此时一趟排序后返回的high(即下一趟排序的递归分界线)很靠近数组左侧,这样的话,将数组分成了及其不均等的两部分(左侧部分仅为1个元素),那么相当于下趟排序是对n-1个相等元素进行,再下趟排序对相等的n-2个元素进行,这样的话和上边(1)中提到的一样,总时间仍为O(n^2)。而且,如果不停止,还要有相应的程序防止low和high越界。
因此,进行不必要的交换建立两个均等的子数组比蛮干冒险得到不均衡的子数组好。所以,遇到等于枢纽的元素,要让low和high停下来,交换它们。
(3)如果数组排序前已经有序
如果数组排序前已经递增有序,这时,如果以第一个(最小)元素为枢纽的话,划分的仍然是及其不均衡的子数组,总时间仍为O(n^2)。而此时,插入排序,则每次不需要移动元素,总时间为O(n)。因此,固定选择某个元素为枢纽存在不科学的情况,于是有了下面的随机枢纽排序方法。
随机枢纽的快速排序
以上的方法都是固定某个位置为枢纽,该方法是随机选取一个位置为枢纽。
思想为:首先产生随机的枢纽位置i,然后交换i、right或者交换i、left。那么接下来就可以继续使用上述的方法了。下面使用版本一的方法。
代码:
//版本四,随机的枢纽,使用版本一的方法
int Rand(int left, int right) { //产生数组范围内的随机下标
int size = right - left + 1;
return left + rand() % size;
}
template<typename T>
int PartionQuickSort4(vector<T> &vec, int left, int right) {
SwapQuickSort(vec[Rand(left, right)], vec[right]);//将随机的枢纽交换到right位置处
T pivot = vec[right]; //设置枢纽
int low = left;
int high = right;
while (low < high) {//注意两个内层while的顺序不能换
while (low < high && vec[low] <= pivot)
low++;
vec[high] = vec[low];
while (low < high && vec[high] >= pivot)
high--;
vec[low] = vec[high];
}
vec[low] = pivot;
return low;
}
template<typename T>
void QuickSort4(vector<T> &vec, int left, int right) {
if (left < right) {
int partion = PartionQuickSort1(vec, left, right);
QuickSort4(vec, left, partion - 1);
QuickSort4(vec, partion + 1, right);
}
}
枢纽三数中值法
上述的程序均使用了大量的时间排序很小的数组,效率不高,如果利用插入排序等算法来排序很小的子数组,效率会提高很多,该算法就是这么做的。而且,该算法是选取三个数的中间值作为枢纽元,只给出代码,具体分析见《数据结构与算法分析C++描述第3版》。
//版本五,取中间值为枢纽
template <typename T>
const T & median( vector<T> & a, int left, int right )
{
int center = ( left + right ) / 2;
if( a[ center ] < a[ left ] )
swap( a[ left ], a[ center ] );
if( a[ right ] < a[ left ] )
swap( a[ left ], a[ right ] );
if( a[ right ] < a[ center ] )
swap( a[ center ], a[ right ] );
swap( a[ center ], a[ right - 1 ] );
return a[ right - 1 ];
}
template <typename T>
void QuickSort5( vector<T> & a, int left, int right )
{
if (left + 10 <= right) {
T pivot = median( a, left, right );
int i = left, j = right - 1;
for( ; ; )
{
while( a[ ++i ] < pivot ) { }
while( pivot < a[ --j ] ) { }
if( i < j )
swap( a[ i ], a[ j ] );
else
break;
}
swap( a[ i ], a[ right - 1 ] );
QuickSort5( a, left, i - 1 );
QuickSort5( a, i + 1, right );
}
else { //使用插入排序来处理很小的数组(n < 10)提高效率
InsertionSortQuickSort(a, left, right);
}
}
template <typename T>
void InsertionSortQuickSort( vector<T> & a, int left, int right )
{
for( int p = left + 1; p <= right; p++ )
{
T tmp = a[ p ];
int j;
for( j = p; j > left && tmp < a[ j - 1 ]; j-- )
a[ j ] = a[ j - 1 ];
a[ j ] = tmp;
}
}
各个算法版本的性能测试分析
测试环境: VS2010旗舰版。Intel i3处理器(2.94Ghz),2.93G内存,32位操作系统。
一、随机产生的十个数
对以上前四个算法、三种版本有效性测试:
int main() {
int max = 10;
int i = 0;
vector<int> ivec1, ivec12, ivec2, ivec3;
srand((unsigned int)time(0));
while (i < max) {
i++;
int value = rand();
ivec1.push_back(value);
ivec12.push_back(value);
ivec2.push_back(value);
ivec3.push_back(value);
}
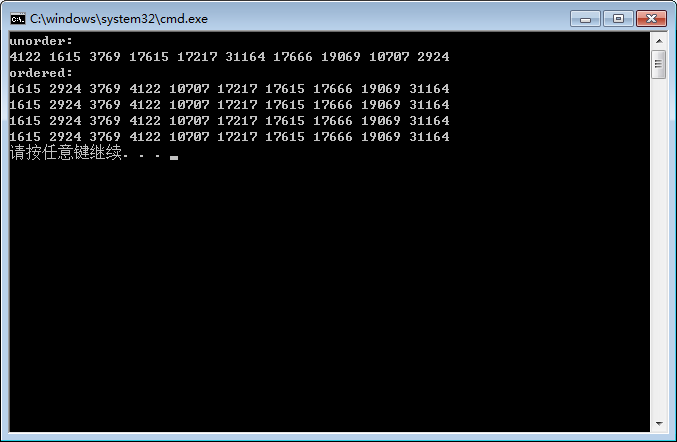
cout << "unorder: " << endl;
PrintValue(ivec1);
cout << "ordered: " << endl;
QuickSort1(ivec1, 0, ivec1.size() - 1);
PrintValue(ivec1);
QuickSort12(ivec12, 0, ivec12.size() - 1);
PrintValue(ivec12);
QuickSort2(ivec2, 0, ivec2.size() - 1);
PrintValue(ivec2);
QuickSort3(ivec3, 0, ivec3.size() - 1);
PrintValue(ivec3);
}
二、大量随机数测试
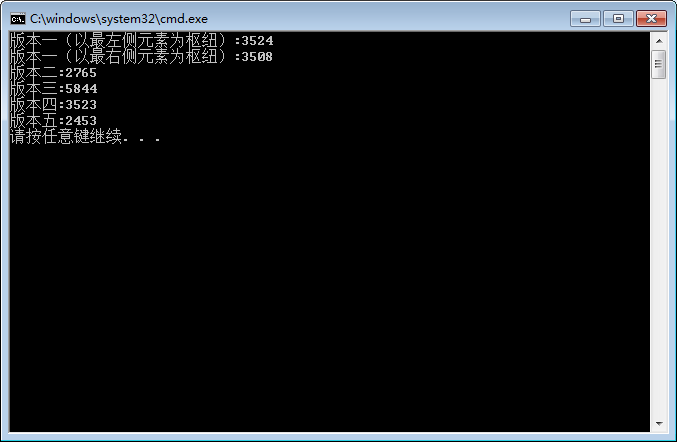
(1)某次随机产生的10,000,000(一千万)个数测试
输出各个算法用时(ms):
int main() {
int max = 10000000;
int i = 0;
vector<int> ivec1, ivec12, ivec2, ivec3, ivec4, ivec5;
srand((unsigned int)time(0));
while (i < max) {
i++;
int value = rand();
ivec1.push_back(value);
ivec12.push_back(value);
ivec2.push_back(value);
ivec3.push_back(value);
ivec4.push_back(value);
ivec5.push_back(value);
}
clock_t time1 = clock();
QuickSort1(ivec1, 0, ivec1.size() - 1);
clock_t time2 = clock();
cout << "版本一(以最左侧元素为枢纽):" << time2 - time1 << endl;
QuickSort12(ivec12, 0, ivec12.size() - 1);
clock_t time3 = clock();
cout << "版本一(以最右侧元素为枢纽):" << time3 - time2 << endl;
QuickSort2(ivec2, 0, ivec2.size() - 1);
clock_t time4 = clock();
cout << "版本二:" << time4 - time3 << endl;
QuickSort3(ivec3, 0, ivec3.size() - 1);
clock_t time5 = clock();
cout << "版本三:" << time5 - time4 << endl;
QuickSort4(ivec4, 0, ivec4.size() - 1);
clock_t time6 = clock();
cout << "版本四:" << time6 - time5 << endl;
QuickSort5(ivec5, 0, ivec5.size() - 1);
clock_t time7 = clock();
cout << "版本五:" << time7 - time6 << endl;
}
(2)随机产生一百万个数,连续测试10次
如下图所示:每一行依次是某个算法10次测试所有时间,最后一列为各个算法耗时的平均值。
//vec_time用于记录所有算法的十次耗时
//每个元素表示一种算法
vector< vector<int> > vec_time(10);
//进行十次测试
for (int a = 0; a < 10; ++a) {
int max = 1000000; //每次测试的都是随机的一百万个数
int i = 0;
vector<int> ivec1, ivec1_none, ivec12, ivec2, ivec3, ivec4, ivec5;
srand((unsigned int)time(0));
while (i < max) {
i++;
int value = rand();
ivec1.push_back(value);
ivec1_none.push_back(value);
ivec12.push_back(value);
ivec2.push_back(value);
ivec3.push_back(value);
ivec4.push_back(value);
ivec5.push_back(value);
}
clock_t time1 = clock();
QuickSort1(ivec1, 0, ivec1.size() - 1);
clock_t time2 = clock();
//cout << "版本一(左侧枢纽):" << time2 - time1 << endl;
vec_time[0].push_back(time2 - time1);
clock_t time_none1 = clock();
QuickSort1NoRecursion(ivec1_none, 0, ivec1_none.size() - 1);
clock_t time_none2 = clock();
//cout << "版本一(非递归法):" << time_none2 - time_none1 << endl;
//PrintValue(ivec1_none);
vec_time[1].push_back(time_none2 - time_none1);
clock_t time31 = clock();
QuickSort12(ivec12, 0, ivec12.size() - 1);
clock_t time3 = clock();
//cout << "版本一(右侧枢纽):" << time3 - time31 << endl;
vec_time[2].push_back(time3 - time31);
clock_t time41 = clock();
QuickSort2(ivec2, 0, ivec2.size() - 1);
clock_t time4 = clock();
//cout << "版本二(直接交换):" << time4 - time41 << endl;
vec_time[3].push_back(time4 - time41);
clock_t time51 = clock();
QuickSort3(ivec3, 0, ivec3.size() - 1);
clock_t time5 = clock();
//cout << "版本三(单向划分):" << time5 - time51 << endl;
vec_time[4].push_back(time5 - time51);
clock_t time61 = clock();
QuickSort4(ivec4, 0, ivec4.size() - 1);
clock_t time6 = clock();
//cout << "版本四(随机枢纽):" << time6 - time61 << endl;
vec_time[5].push_back(time6 - time61);
clock_t time71 = clock();
QuickSort5(ivec5, 0, ivec5.size() - 1);
clock_t time7 = clock();
//cout << "版本五(三数取中):" << time7 - time71 << endl;
vec_time[6].push_back(time7 - time71);
}
//下列输出的各行依次是下列各个算法的函数
cout << "版本一(左侧枢纽) " << "版本一(非递归法) " << "版本一(右侧枢纽) " << endl;
cout << "版本二(直接交换) " << "版本三(单向划分) " << "版本四(随机枢纽) " << "版本五(三数取中)" << endl;
for (int j = 0; j < 7; ++j) {
int sum = 0;
vector<int>::iterator iter = vec_time[j].begin();
while (iter != vec_time[j].end()) {
cout << *iter << " ";
sum += *iter;
++iter;
}
cout << (double)sum / 10;
cout << endl;
}
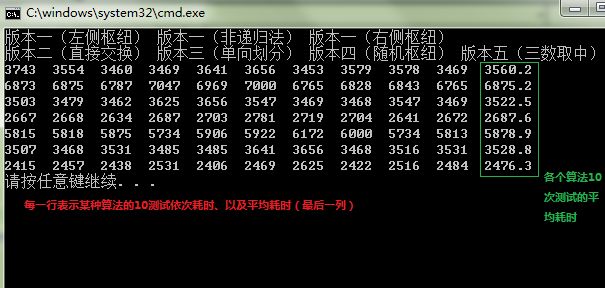
分析:
从上图可以得出如下结论:
(1)版本一以左侧元素或右侧元素作为枢纽时,两种方式的递归算法性能相当;
但是使用STL的栈适配器的非递归算法性能很差,几乎是递归算法时间的二倍。这是所有算法中性能最差的算法;这原因可能是STL实现的栈比较耗时。一百万随机数排序平均时间为6.8秒。
(2)版本二:Hore算法(每次直接交换)性能略微优于版本一(产生空穴)。
(3)版本三:单向划分(两个指针都从待排序数组一侧开始移动)性能较差,仅次于上述的非递归算法。
(4)版本四:随机枢纽算法性能和版本一的非递归算法性能类似。
(5)版本五:三数取中算法是所有算法中性能最好的。一百万随机数平均时间只有2.5秒。
(3)随机产生一千万个数,连续测试10次
采用和上一节同样的方式测试,只是测试数据量提高了一个数量级:由一百万个数提升到一千万个。
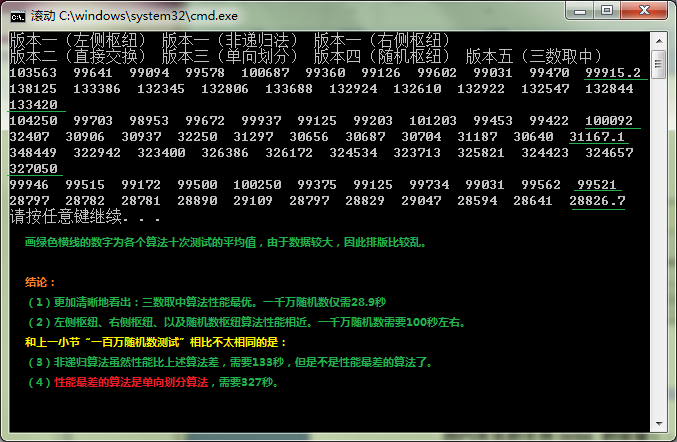
分析:
(1)对比一百万数据测试和一千万数据测试可以看出,同样是快速排序,其性能差距也会很大:
一百万随机数时最慢算法(非递归算法)时间几乎是最快的算法(三数取中)的时间的2.7倍;
一千万随机数测试时,最慢算法(单向划分算法)的时间是最快的算法(三数取中)时间的11倍还多。
(2)一百万个数据时,Hore算法(每次直接交换)性能略微优于版本一(产生空穴);在一千万个数据时,Hore算法(每次直接交换)性能远优于版本一(产生空穴),后者时间是前者的3倍还多。
(2)一百万数据测试的最差算法是非递归,一千万算法测试最差算法是单向划分。其实一百万数据测试时,单向划分的表现就不佳。
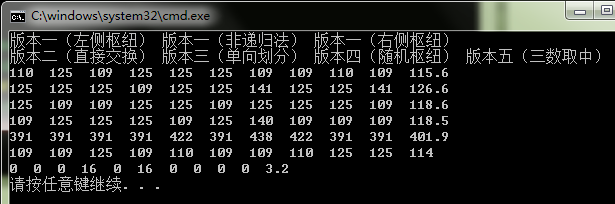
三、已经有序数组排序测试
使用有序的数组测试排序性能,已经知道,在数组有序的情况下,快速排序的性能退化为O(n ^ 2)。因此不能如随机数据测试那样,测试百万、千万级别的数据。
事实上,当已排序数组元素超过5000个(大概数值)时,我的程序就崩溃了(在初始数组有序(或逆序)情况下,栈深度为O(n),栈溢出,所以程序崩溃。参考基础排序算法总结)。
测试程序和随机数的类似,只是初始化是将数组元素初始化为有序的,而不是随机的:
//有序数据测试的代码片段
//将数组初始化为4000个元素的有序数组
for (int a = 0; a < 10; ++a) {
int max = 100; //每次测试的都是随机的一百万个数
int i = 0;
vector<int> ivec1, ivec1_none, ivec12, ivec2, ivec3, ivec4, ivec5;
for (i = 0; i < 4000; i++) {
int value = i;
ivec1.push_back(value);
ivec1_none.push_back(value);
ivec12.push_back(value);
ivec2.push_back(value);
ivec3.push_back(value);
ivec4.push_back(value);
ivec5.push_back(value);
}
(1) 2000个数
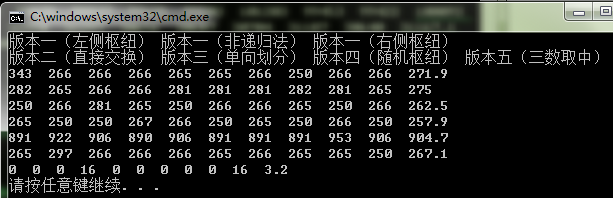
(2)3000个数
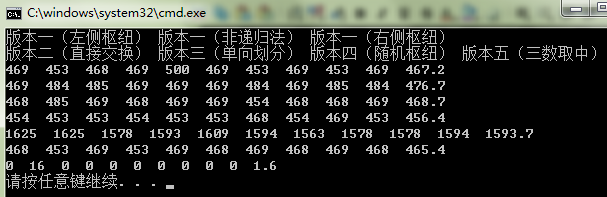
(3) 4000个数
分析:
虽然测试数据比较少,但是仍可以看出:单向划分算法性能较差。三数取中算法性能占绝对优势。
结论:
(1)采用待排序序列第一个或最后一个元素作为枢纽的算法性能:在平均情况下不错,可以从随机数的测试中看出来,但是当待排序的数组序列基本有序或逆序时,请算法性能退化为O(n ^ 2)。其中非递归版本算法性能没有递归版本好,可能是STL栈实现性能不够好。
(2)三数取中枢纽法的性能是最优解法的,它不仅可以避免初始序列基本有序或逆序的最坏情况,相反,在初始序列基本有序或逆序时,该算法达到的是最好的性能:每次枢纽将待排序序列划分为等长的两个子序列,此时栈空间最小,仅为longn,所需时间也最少。
(3)单向划分的性能不佳,采用待排序序列第一个或最后一个元素作为枢纽的非递归版本性能也不佳。