

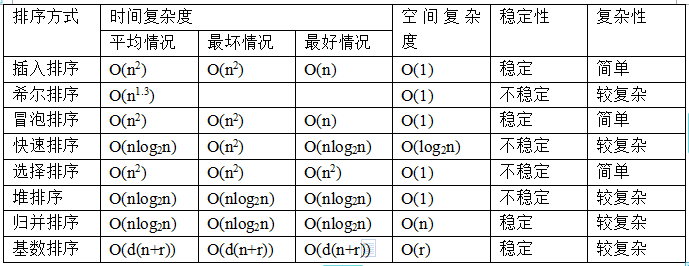
з®≥еЃЪжАІж¶Вењµ
¬†¬†¬†¬†¬†¬† еБЗеЃЪеЬ®еЊЕжОТеЇПзЪДиЃ∞ељХеЇПеИЧдЄ≠пЉМе≠ШеЬ®е§ЪдЄ™еЕЈжЬЙзЫЄеРМзЪДеЕ≥йФЃе≠ЧзЪДиЃ∞ељХпЉМиЛ•зїПињЗжОТеЇПпЉМињЩдЇЫиЃ∞ељХзЪДзЫЄеѓєжђ°еЇПдњЭжМБдЄНеПШпЉМеН≥еЬ®еОЯеЇПеИЧдЄ≠пЉМri=rjпЉМдЄФriеЬ®rjдєЛеЙНпЉМиАМеЬ®жОТеЇПеРОзЪДеЇПеИЧдЄ≠пЉМriдїНеЬ®rjдєЛеЙНпЉМеИЩзІ∞ињЩзІНжОТеЇПзЃЧж≥ХжШѓз®≥еЃЪзЪДпЉЫеР¶еИЩзІ∞дЄЇдЄНз®≥еЃЪзЪДгАВ
йАЙжЛ©жОТеЇПгАБењЂйАЯжОТеЇПгАБеЄМе∞ФжОТеЇПгАБе†ЖжОТеЇПдЄНжШѓз®≥еЃЪзЪДжОТеЇПзЃЧж≥ХпЉМ
еЖТж≥°жОТеЇПгАБжПТеЕ•жОТеЇПгАБељТеєґжОТеЇПеТМеЯЇжХ∞жОТеЇПжШѓз®≥еЃЪзЪДжОТеЇПзЃЧж≥ХгАВ
дЄАгАБеЖТж≥°жОТеЇП
еЖТж≥°жОТеЇПзЪДжЩЃйАЪжАЭиЈѓпЉЪ
¬†¬†¬†¬†¬†¬†¬† жѓФиЊГзЫЄйВїзЪДдЄ§дЄ™еЕГзі†пЉМдЇ§жНҐеЕГзі†дљњеЊЧе∞ПеЕГзі†еЬ®еЙНгАБе§ІеЕГзі†еЬ®еРОгАВ
¬†¬†¬†¬†¬†¬†¬† зђђдЄАжђ°жОТеЇПе∞ЖеѓєnдЄ™еЕГзі†ињЫи°Мn-1жђ°жѓФиЊГпЉМе∞ЖжЬАе§ІзЪДеЕГзі†жФЊеИ∞дЇЖжХ∞зїДзЪДжЬАеРОиЊєпЉЫ
¬†¬†¬†¬†¬†¬†¬† зђђдЇМжђ°жОТеЇПе∞ЖеЙ©дЄЛзЪДn-1дЄ™еЕГзі†ињЫи°Мn-2жђ°жѓФиЊГпЉМе∞ЖзђђдЇМе§ІзЪДжХ∞жФЊеЬ®жХ∞зїДзЪДеАТжХ∞зђђдЇМдЄ™дљНзљЃпЉЫ
¬†¬† ¬† ¬†¬† дЊЭжђ°ињЫи°Миѓ•ињЗз®ЛпЉЫ
¬†¬†¬†¬†¬†¬†¬† зђђn-1иґЯеИЩжЙАжЬЙеЕГзі†йГљжШѓжЬЙеЇПзЪДпЉМеН≥еЃМжИРдЇЖжОТеЇПгАВ
жФєињЫзЪДеЖТж≥°жОТеЇПпЉЪ
¬†¬†¬†¬†¬†¬† иЃЊзљЃдЄАдЄ™ж†ЗењЧзФ®жЭ•иЃ∞ељХжЯРжђ°йБНеОЖжХ∞зїДдЄ≠пЉМжЬЙж≤°жЬЙеПСзФЯеЕГзі†зЪДдЇ§жНҐпЉЫе¶ВжЮЬеПСзФЯдЇЖеЕГзі†зЪДдЇ§жНҐпЉМиѓіжШОжХ∞зїДињШж≤°жЬЙеЃМеЕ®жЬЙеЇПпЉЫе¶ВжЮЬж≤°еПСзФЯеЕГзі†дЇ§жНҐпЉМиѓіжШОжХідЄ™жХ∞зїДеЈ≤зїПжЬЙеЇПпЉМеИЩжОТеЇПзїУжЭЯгАВ
¬†¬†¬†¬†¬† йАЪињЗиЃЊзљЃињЩдЄ™ж†ЗењЧеПѓдї•еЗПе∞СеЕГзі†зЪДжѓФиЊГжђ°жХ∞гАВ
дЇМгАБжПТеЕ•жОТеЇП
жАЭиЈѓпЉЪ
¬†¬†¬†¬†¬†¬† жѓПжђ°е∞ЖжХ∞зїДеП≥иЊєдЄАдЄ™еЊЕжОТеЇПзЪДжХ∞жНЃжПТеЕ•еИ∞жХ∞зїДеЈ¶иЊєеЈ≤зїПжОТеЇПзЪДеЇПеИЧдЄ≠пЉМзЫіеИ∞жХідЄ™жХ∞зїДйГљжШѓжЬЙеЇПзЪДгАВ
¬†¬†¬†¬†¬†¬† жЯРжђ°жОТеЇПпЉМе∞ЖжХ∞зїДеИЖдЄЇеЈ≤жОТеЇПеЇПеИЧAпЉИжХ∞зїДеЈ¶иЊєйГ®еИЖпЉЙеТМжЬ™жОТеЇПеЇПеИЧBпЉИжХ∞зїДеП≥иЊєйГ®еИЖпЉЙпЉЫжѓПжђ°жОТеЇПдЊЭжђ°дїОBеЇПеИЧдЄ≠еПЦдЄАдЄ™еЕГзі†bпЉМиЃ©еЕґдЊЭжђ°дЄОAеЇПеИЧзЪДеЕГзі†жѓФиЊГпЉИдЊЭжђ°дїОAеЇПеИЧзЪДжЬАеП≥дЄАдЄ™еЕГзі†еРСеЈ¶еЉАеІЛжѓФиЊГпЉЙпЉМдЄЇжХ∞bеЬ®AеЇПеИЧдЄ≠еѓїжЙЊдЄАдЄ™еРИйАВзЪДжПТеЕ•дљНзљЃпЉМе∞ЖbжПТеЕ•AгАВ
¬†¬†¬†¬†¬†¬† зФ±дЇОжѓПжђ°йГљжШѓе∞Же§ІдЇОbзЪДеЕГзі†еП≥зІїеК®пЉМзДґеРОе∞ЖbжФЊеЬ®иѓ•дљНзљЃпЉМеЫ†ж≠§дЄНдЉЪеПСзФЯзЫЄеРМеЕГзі†зЪДдЇ§жНҐпЉМеЫ†ж≠§жШѓз®≥еЃЪзЪДгАВ
дЄЙгАБеЄМе∞ФжОТеЇП
жАЭиЈѓпЉЪ
¬†¬†¬†¬†¬†¬† е∞ЖжХ∞зїДеИЖеЙ≤дЄЇиЛ•еє≤дЄ™е≠РеЇПеИЧпЉМжѓПдЄ™еЇПеИЧдЄ≠зЪДеЕГзі†йГљжШѓзФ±зЫЄйЪФжЯРдЄ™еҐЮйЗПзЪДеЕГзі†зїДжИРгАВ
¬†¬†¬†¬†¬†¬† еѓєжѓПдЄ™е≠РеЇПеИЧеИЖеИЂињЫи°МжПТеЕ•жОТеЇПпЉЫзДґеРОдЊЭжђ°зЉ©еЗПеҐЮйЗПпЉМеЖНжђ°йЗНе§НдЄКињ∞жОТеЇПгАВ
¬†¬†¬†¬†¬†¬† зЫіеИ∞еҐЮйЗПдЄЇ1еРОпЉМињЫи°МдЊЭжђ°жОТеЇПпЉМињЩжЧґжХідЄ™жХ∞зїДе∞±жШѓжЬЙеЇПзЪДпЉМжОТеЇПзїУжЭЯгАВ
еЄМе∞ФжОТеЇПжШѓеѓєзЫЄйЪФиЛ•еє≤иЈЭз¶їзЪДжХ∞жНЃињЫи°МзЫіжО•жПТеЕ•жОТеЇПзЪДгАВ
¬†¬†¬†¬†¬†¬† дЄАжђ°жПТеЕ•жОТеЇПжШѓз®≥еЃЪзЪДпЉМдЄНдЉЪжФєеПШзЫЄеРМеЕГ зі†зЪДзЫЄеѓєй°ЇеЇПпЉМдљЖеЬ®дЄНеРМзЪДжПТеЕ•жОТеЇПињЗз®ЛдЄ≠пЉМзЫЄеРМзЪДеЕГзі†еПѓиГљеЬ®еРДиЗ™зЪДжПТеЕ•жОТеЇПдЄ≠зІїеК®пЉМжЬАеРОеЕґз®≥еЃЪжАІе∞±дЉЪ襀жЙУдє±пЉМжЙАдї•shellжОТеЇПжШѓ**дЄНз®≥еЃЪзЪДгАВ
еЫЫгАБйАЙжЛ©жОТеЇП
жАЭиЈѓпЉИеБЗиЃЊйЭЮйАТеЗПжОТеЇПпЉЙпЉЪ
¬†¬†¬†¬†¬†¬† з±їдЉЉдЇОжПТеЕ•жОТеЇПпЉМе∞ЖеЇПеИЧеИЖдЄЇдЇЖжЬЙеЇПзЪДеТМжЧ†еЇПзЪДе≠РеЇПеИЧпЉМдЄНињЗињЩйЗМдЄНжШѓдЊЭжђ°йАЙжЛ©дЄАдЄ™жЬ™жОТеЇПзЪДеЕГзі†жПТеЕ•еЈ≤жОТеЇПеЇПеИЧпЉЫиАМжШѓжЙЊеЗЇжЬ™жОТеЇПеЇПеИЧдЄ≠жЬАе∞ПзЪДеЕГзі†пЉМе∞ЖеЕґдЄОеЈ≤зїПжОТеЇПзЪДеЇПеИЧзіІйВїзЪДйВ£дЄ™еЕГзі†дЇ§жНҐпЉИеИЭеІЛеЈ≤жОТеЇПеЇПеИЧдЄЇ0пЉЙгАВ
дЊЛе¶В5пЉМ8пЉМ5пЉМ2пЉМ9еЇПеИЧзЪДзђђдЄАиґЯжОТеЇПжШѓе∞ЖзђђдЄАдЄ™5дЄО2дЇ§жНҐпЉМйВ£дєИпЉМдЄ§дЄ™5зЪДжђ°еЇПе∞±дЇ§жНҐдЇЖпЉМжЙАдї•йАЙжЛ©жОТеЇПдЄНз®≥еЃЪгАВ
дЇФгАБељТеєґжОТеЇП
жАЭиЈѓпЉЪ
¬†¬†¬†¬†¬†¬†¬† ељУдЄАдЄ™жХ∞зїДзЪДеЈ¶йГ®еИЖжЬЙеЇПгАБеП≥йГ®еИЖдєЯжЬЙеЇПжЧґпЉМеП™и¶Бе∞ЖињЩдЄ§йГ®еИЖеРИеєґеН≥еПѓеЃМжИРжОТеЇПгАВиАМе¶ВдљХдљњеЊЧеЈ¶гАБеП≥йГ®еИЖеИЖеИЂжЬЙеЇПеСҐпЉЯйАТељТдљњзФ®ељТеєґжОТеЇПеН≥еПѓгАВ
¬†¬†¬†¬†¬†¬† еЬ®ељТеєґзЪДињЗз®ЛдЄ≠пЉМдЄїи¶БзЪДжУНдљЬжШѓеРИеєґдЄ§дЄ™жЬЙеЇПзЪДеЇПеИЧпЉМеЬ®еРИеєґдЄ≠пЉМе¶ВжЮЬдЄ§дЄ™еЕГзі†зЫЄз≠ЙпЉМдЄНдЉЪеѓєеЃГдїђдЇ§жНҐпЉМеЫ†ж≠§з®≥еЃЪгАВ
еЕ≠гАБењЂйАЯжОТеЇП
¬†¬†¬†¬†¬†¬†¬† дЄКињ∞йУЊжО•зЪДжЦЗзЂ†дЄ≠зїЩеЗЇдЇЖиѓ¶зїЖзЪДжАЭиЈѓеТМињЗз®ЛгАВ
¬†¬†¬†¬†¬†¬†¬† ењЂйАЯжОТеЇП襀聧䪯жШѓжЙАжЬЙеРМжХ∞йЗПзЇІ(O(nlogn))жОТеЇПжЦєж≥ХдЄ≠пЉМеє≥еЭЗжАІиГљжЬАе•љзЪДгАВ
жЧґйЧіе§НжЭВеЇ¶пЉЪ
¬†¬†¬†¬†¬†¬† дљЖжШѓпЉМе¶ВжЮЬеИЭеІЛиЃ∞ељХеЇПеИЧжЬЙеЇПжЧґпЉМдї•еЈ¶дЊІеЕГзі†дЄЇжЮҐзЇљзЪДењЂйАЯжОТеЇПзЃЧж≥Хе∞ЖйААеМЦдЄЇеЖТж≥°жОТеЇПпЉМеЕґжЧґйЧіе§НжЭВеЇ¶дЄЇO(n ^ 2)пЉЫеЬ®еИЭеІЛеЇПеИЧжЬЙеЇПжИЦйАЖеЇПжГЕеЖµдЄЛпЉМжѓПжђ°жОТеЇПйЬАи¶Бn * nжђ°жѓФиЊГпЉМеЫ†ж≠§зЃЧж≥Хе§НжЭВеЇ¶дЄЇO(n ^ 2)гАВ
з©ЇйЧіе§НжЭВеЇ¶пЉЪ
¬†¬†¬†¬†¬† ењЂйАЯжОТеЇПйЬАи¶БдЄАдЄ™ж†Из©ЇйЧіжЭ•еЃЮзО∞йАТељТпЉИеН≥дљњжШѓйЭЮйАТељТзЃЧж≥ХпЉМеЃГдєЯйЬАи¶БдЄАдЄ™иЊЕеК©ж†ИжЭ•дњЭе≠ШдЄЛжђ°еЄ¶жОТеЇПжХ∞зїДзЪДдЄЛж†ЗиМГеЫіпЉЙгАВиЛ•жѓПдЄАиґЯжОТеЇПйГље∞ЖиЃ∞ељХеЇПеИЧеЭЗеМАеИЖеЙ≤дЄЇйХњеЇ¶жО•ињСзЫЄз≠ЙзЪДдЄ§дЄ™е≠РеЇПеИЧпЉМеИЩеє≥еЭЗжГЕеЖµдЄЛж†ИзЪДжЬАе§ІжЈ±еЇ¶дЄЇlogn + 1пЉИеМЕжЛђжЬАе§Це±ВеПВжХ∞ињЫж†ИпЉЙпЉМдљЖжШѓиЛ•жѓПиґЯжОТеЇПеРОпЉМжЮҐзЇљдљНзљЃеЭЗеБПеРСе≠РеЇПеИЧзЪДдЄАзЂѓпЉИеИЭеІЛеЇПеИЧжЬЙеЇПжИЦйАЖеЇПпЉЙпЉМеИЩдЄЇжЬАеЭПжГЕеЖµпЉМж†ИзЪДжЬАе§ІжЈ±еЇ¶дЄЇnгАВ
дЄГгАБе†ЖжОТеЇП
¬† ¬† ¬†¬† е¶ВжЮЬи¶БжМЙзЕІйЭЮйАТеЗПй°ЇеЇПжОТеЇПпЉМйВ£дєИи¶БдљњзФ®е§Іж†єе†ЖпЉЫжМЙзЕІйЭЮйАТеҐЮй°ЇеЇПжОТеЇПпЉМи¶БдљњзФ®е∞Пж†єе†ЖгАВ
еБЗиЃЊжМЙзЕІйЭЮйАТеЗПй°ЇеЇПжОТеИЧпЉМйВ£дєИжОТеЇПзЪДжАЭиЈѓжШѓпЉЪ
¬†¬†¬†¬†¬†¬†¬† й¶ЦеЕИеїЇзЂЛдЄАдЄ™е§Іж†єе†ЖпЉЫ
¬†¬†¬†¬†¬†¬†¬† еИ†йЩ§е§Іж†єе†ЖзЪДж†єеЕГзі†пЉИиѓіжШѓеИ†йЩ§пЉМеЕґеЃЮжШѓеИ©зФ®дЇЖе†ЖжЬАеРОзЪДйВ£дЄ™з©ЇйЧіжЭ•е≠ШеВ®иѓ•еЕГзі†пЉМеН≥е∞Жж†єеЕГзі†дЄОе†Же∞ЊйГ®еЕГзі†дЇ§жНҐпЉМињЩж†ЈељУе†ЖеИ†йЩ§еЃМеРОпЉМйВ£дєИе≠ШеВ®з©ЇйЧіе∞±жШѓжЬЙеЇПзЪДдЇЖпЉЙпЉЫ
¬†¬†¬†¬†¬† ¬† жѓПжђ°дЇ§жНҐзЪДж†єеЕГзі†еТМе∞ЊеЕГзі†еРОи¶БињЫи°МдЄЛжї§жУНдљЬпЉМдљњеЊЧжї°иґ≥е§Іж†єе†ЖгАВ
¬†¬†¬†¬†¬†¬†¬† жОТеЇПињЗз®Ле∞±жШѓеИ†йЩ§ж†єеЕГзі†еєґдЄКжї§зЪДињЗз®ЛпЉМдЄКжї§дЄ≠еПѓиГљдЉЪиЃ©зЫЄз≠ЙеЕГзі†дљНзљЃжФєеПШпЉМеЫ†ж≠§дЄНз®≥еЃЪгАВ
еЕЂгАБзЇњжАІжЧґйЧіжОТеЇП
дї•дЄКе∞ЖзЪДйГљжШѓеЯЇдЇОжѓФиЊГзЪДжОТеЇПпЉМжЧґйЧіе§НжЭВеЇ¶дЄКзХМдЄЇO(n ^ 2)пЉМ дЄЛзХМдЄЇO(nlogn)гАВдЄЛйЭҐдїЛзїНеЗ†зІНзЇњжАІжОТеЇПпЉЪ
1гАБеЯЇжХ∞жОТеЇП
¬†¬†¬†¬†¬†¬† еЯЇжХ∞жОТеЇПжШѓжМЙзЕІдљОдљНеЕИжОТеЇПпЉМзДґеРОжФґйЫЖпЉЫеЖНжМЙзЕІжђ°дљОдљНжОТеЇПпЉМзДґеРОеЖНжФґйЫЖпЉЫдЊЭжђ°з±їжО®пЉМзЫіеИ∞жЬАйЂШдљНгАВжЬЙжЧґеАЩжЬЙдЇЫе±ЮжАІжШѓжЬЙдЉШеЕИзЇІй°ЇеЇПзЪДпЉМеЕИжМЙдљОдЉШеЕИзЇІжОТеЇПпЉМеЖНжМЙйЂШдЉШ еЕИзЇІжОТеЇПпЉМжЬАеРОзЪДжђ°еЇПе∞±жШѓйЂШдЉШеЕИзЇІйЂШзЪДеЬ®еЙНпЉМйЂШдЉШеЕИзЇІзЫЄеРМзЪДдљОдЉШеЕИзЇІйЂШзЪДеЬ®еЙНгАВеЯЇжХ∞жОТеЇПеЯЇдЇОеИЖеИЂжОТеЇПпЉМеИЖеИЂжФґйЫЖпЉМеЃГеЬ®жѓПдЄАдљНжОТеЇПдЄ≠дЊЭиµЦдЇОдЄАдЄ™з®≥еЃЪзЪДжОТеЇПзЃЧж≥ХпЉМжЙАдї•еЯЇжХ∞жОТеЇПжШѓз®≥еЃЪзЪДжОТеЇПзЃЧж≥ХгАВ
¬†¬†¬†¬†¬†¬† зїЩеЃЪnдЄ™dдљНжХ∞пЉМеЕґдЄ≠жѓПдЄ™жХ∞дљНжЬЙkдЄ™еПѓиГљзЪДеПЦеАЉгАВйВ£дєИйЬАи¶БdиљЃжОТеЇПпЉМжЙАдї•еЯЇжХ∞жОТеЇПиАЧжЧґдЄЇd(n + k)пЉМиАМdдЄЇеЄЄжХ∞пЉМжЙАдї•еЯЇжХ∞жОТеЇПе§НжЭВеЇ¶дЄЇO(n + k)гАВ
2гАБиЃ°жХ∞жОТеЇП
еБЗиЃЊnдЄ™иЊУеЕ•еЕГзі†дЄ≠жѓПдЄ™йГљжШѓеЬ®0еИ∞kеМЇйЧізЪДжХіжХ∞(kжШѓжЯРдЄ™жХіжХ∞)гАВељУk = O(n)жЧґпЉМжОТеЇПзЪДињРи°МжЧґйЧідЄЇO(n)гАВ
3гАБж°ґжОТеЇП
¬†¬†¬†¬†¬†¬† еБЗиЃЊиЊУеЕ•жХ∞жНЃжЬНдїОеЭЗеМАеИЖеЄГпЉМеє≥еЭЗжГЕеЖµдЄЛеЕґжЧґйЧідї£дїЈдЄЇO(n)гАВеТМиЃ°жХ∞жОТеЇПз±їдЉЉпЉМиЃ°жХ∞жОТеЇПеБЗиЃЊжХ∞жНЃйГљжШѓдЄАдЄ™е∞ПеМЇйЧіеЖЕзЪДжХіжХ∞пЉМж°ґжОТеЇПеИЩеБЗеЃЪиЊУеЕ•зФ±дЄАдЄ™йЪПжЬЇињЗз®ЛдЇІзФЯпЉМиѓ•ињЗз®Ле∞ЖеЕГзі†еЭЗеМАгАБзЛђзЂЛеЬ∞еИЖеЄГеЬ®[0,1)еМЇйЧіеЖЕгАВ
¬†¬†¬†¬†¬†¬† ж°ґжОТеЇПе∞Ж[0,1)еМЇйЧіеИТеИЖдЄЇnдЄ™зЫЄеРМе§Іе∞ПзЪДе≠РеМЇйЧіпЉМзІ∞дЄЇж°ґпЉЫзДґеРОпЉМе∞ЖnдЄ™жХ∞еИЖеИЂжФЊеЕ•еИ∞еРДдЄ™ж°ґдЄ≠пЉМеЫ†дЄЇиЊУеЕ•жХ∞жНЃжШѓеЭЗеМАеИЖеЄГзЪДпЉМжЙАдї•дЄНдЉЪеЗЇзО∞еЊИе§ЪжХ∞иРљеЬ®дЄАдЄ™ж°ґеЖЕзЪДжГЕеЖµгАВдЄЇдЇЖеЊЧеИ∞иЊУеЗЇзїУжЮЬпЉМеЕИеѓєжѓПдЄ™ж°ґдЄ≠жХ∞ињЫи°МжОТеЇПпЉИдЊЛе¶ВпЉМеИ©зФ®жПТеЕ•жОТеЇПпЉЙпЉМзДґеРОйБНеОЖжѓПдЄ™ж°ґпЉМжМЙзЕІжђ°еЇПжККеРДдЄ™ж°ґеЖЕзЪДеЕГзі†еИЧеЗЇжЭ•еН≥еПѓгАВ