

зђђ¬†19¬†зЂ†¬†ж±ЗзЉЦдЄОCдєЛйЧізЪДеЕ≥з≥ї
зЫЃељХ
- 1. еЗљжХ∞и∞ГзФ®
- 2.
mainеЗљжХ∞еТМеРѓеК®дЊЛз®Л - 3. еПШйЗПзЪДе≠ШеВ®еЄГе±А
- 4. зїУжЮДдљУеТМиБФеРИдљУ
- 5. CеЖЕиБФж±ЗзЉЦ
- 6. volatileйЩРеЃЪзђ¶
дЄКдЄАзЂ†жИСдїђе≠¶дє†дЇЖж±ЗзЉЦзЪДдЄАдЇЫеЯЇз°АзЯ•иѓЖпЉМжЬђзЂ†жИСдїђињЫдЄАж≠•з†Фз©ґCз®ЛеЇПзЉЦиѓСдєЛеРОзЪДж±ЗзЉЦжШѓдїАдєИж†ЈзЪДпЉМCиѓ≠и®АзЪДеРДзІНиѓ≠ж≥ХеИЖеИЂеѓєеЇФдїАдєИж†ЈзЪДжМЗдї§пЉМдїОиАМжЫіжЈ±еЕ•еЬ∞зРЖиІ£Cиѓ≠и®АгАВgccињШжПРдЊЫдЇЖдЄАзІНжЙ©е±Хиѓ≠ж≥ХеПѓдї•еЬ®Cз®ЛеЇПдЄ≠еЖЕеµМж±ЗзЉЦжМЗдї§пЉМињЩеЬ®еЖЕж†Єдї£з†БдЄ≠еЊИеЄЄиІБпЉМжЬђзЂ†дєЯдЉЪзЃАи¶БдїЛзїНињЩзІНзФ®ж≥ХгАВ
1.¬†еЗљжХ∞и∞ГзФ®
жИСдїђзФ®дЄЛйЭҐзЪДдї£з†БжЭ•з†Фз©ґеЗљжХ∞и∞ГзФ®зЪДињЗз®ЛгАВ
дЊЛ¬†19.1.¬†з†Фз©ґеЗљжХ∞зЪДи∞ГзФ®ињЗз®Л
int bar(int c, int d)
{
int e = c + d;
return e;
}
int foo(int a, int b)
{
return bar(a, b);
}
int main(void)
{
foo(2, 3);
return 0;
}
е¶ВжЮЬеЬ®зЉЦиѓСжЧґеК†дЄК-gйАЙй°єпЉИеЬ®зђђ¬†10¬†зЂ† gdbиЃ≤ињЗ-gйАЙй°єпЉЙпЉМйВ£дєИзФ®objdumpеПНж±ЗзЉЦжЧґеПѓдї•жККCдї£з†БеТМж±ЗзЉЦдї£з†Бз©њжПТиµЈжЭ•жШЊз§ЇпЉМињЩж†ЈCдї£з†БеТМж±ЗзЉЦдї£з†БзЪДеѓєеЇФеЕ≥з≥їзЬЛеЊЧжЫіжЄЕж•ЪгАВеПНж±ЗзЉЦзЪДзїУжЮЬеЊИйХњпЉМдї•дЄЛеП™еИЧеЗЇжИСдїђеЕ≥ењГзЪДйГ®еИЖгАВ
$ gcc main.c -g
$ objdump -dS a.out
...
08048394 <bar>:
int bar(int c, int d)
{
8048394: 55 push %ebp
8048395: 89 e5 mov %esp,%ebp
8048397: 83 ec 10 sub $0x10,%esp
int e = c + d;
804839a: 8b 55 0c mov 0xc(%ebp),%edx
804839d: 8b 45 08 mov 0x8(%ebp),%eax
80483a0: 01 d0 add %edx,%eax
80483a2: 89 45 fc mov %eax,-0x4(%ebp)
return e;
80483a5: 8b 45 fc mov -0x4(%ebp),%eax
}
80483a8: c9 leave
80483a9: c3 ret
080483aa <foo>:
int foo(int a, int b)
{
80483aa: 55 push %ebp
80483ab: 89 e5 mov %esp,%ebp
80483ad: 83 ec 08 sub $0x8,%esp
return bar(a, b);
80483b0: 8b 45 0c mov 0xc(%ebp),%eax
80483b3: 89 44 24 04 mov %eax,0x4(%esp)
80483b7: 8b 45 08 mov 0x8(%ebp),%eax
80483ba: 89 04 24 mov %eax,(%esp)
80483bd: e8 d2 ff ff ff call 8048394 <bar>
}
80483c2: c9 leave
80483c3: c3 ret
080483c4 <main>:
int main(void)
{
80483c4: 8d 4c 24 04 lea 0x4(%esp),%ecx
80483c8: 83 e4 f0 and $0xfffffff0,%esp
80483cb: ff 71 fc pushl -0x4(%ecx)
80483ce: 55 push %ebp
80483cf: 89 e5 mov %esp,%ebp
80483d1: 51 push %ecx
80483d2: 83 ec 08 sub $0x8,%esp
foo(2, 3);
80483d5: c7 44 24 04 03 00 00 movl $0x3,0x4(%esp)
80483dc: 00
80483dd: c7 04 24 02 00 00 00 movl $0x2,(%esp)
80483e4: e8 c1 ff ff ff call 80483aa <foo>
return 0;
80483e9: b8 00 00 00 00 mov $0x0,%eax
}
80483ee: 83 c4 08 add $0x8,%esp
80483f1: 59 pop %ecx
80483f2: 5d pop %ebp
80483f3: 8d 61 fc lea -0x4(%ecx),%esp
80483f6: c3 ret
...
и¶БжЯ•зЬЛзЉЦиѓСеРОзЪДж±ЗзЉЦдї£з†БпЉМеЕґеЃЮињШжЬЙдЄАзІНеКЮж≥ХжШѓgcc -S main.cпЉМињЩж†ЈеП™зФЯжИРж±ЗзЉЦдї£з†Бmain.sпЉМиАМдЄНзФЯжИРдЇМињЫеИґзЪДзЫЃж†ЗжЦЗдїґгАВ
жХідЄ™з®ЛеЇПзЪДжЙІи°МињЗз®ЛжШѓmainи∞ГзФ®fooпЉМfooи∞ГзФ®barпЉМжИСдїђзФ®gdbиЈЯиЄ™з®ЛеЇПзЪДжЙІи°МпЉМзЫіеИ∞barеЗљжХ∞дЄ≠зЪДint e = c + d;иѓ≠еП•жЙІи°МеЃМжѓХеЗЖе§ЗињФеЫЮжЧґпЉМињЩжЧґеЬ®gdbдЄ≠жЙУеН∞еЗљжХ∞ж†ИеЄІгАВ
(gdb) start
...
main () at main.c:14
14 foo(2, 3);
(gdb) s
foo (a=2, b=3) at main.c:9
9 return bar(a, b);
(gdb) s
bar (c=2, d=3) at main.c:3
3 int e = c + d;
(gdb) disassemble
Dump of assembler code for function bar:
0x08048394 <bar+0>: push %ebp
0x08048395 <bar+1>: mov %esp,%ebp
0x08048397 <bar+3>: sub $0x10,%esp
0x0804839a <bar+6>: mov 0xc(%ebp),%edx
0x0804839d <bar+9>: mov 0x8(%ebp),%eax
0x080483a0 <bar+12>: add %edx,%eax
0x080483a2 <bar+14>: mov %eax,-0x4(%ebp)
0x080483a5 <bar+17>: mov -0x4(%ebp),%eax
0x080483a8 <bar+20>: leave
0x080483a9 <bar+21>: ret
End of assembler dump.
(gdb) si
0x0804839d 3 int e = c + d;
(gdb) si
0x080483a0 3 int e = c + d;
(gdb) si
0x080483a2 3 int e = c + d;
(gdb) si
4 return e;
(gdb) si
5 }
(gdb) bt
#0 bar (c=2, d=3) at main.c:5
#1 0x080483c2 in foo (a=2, b=3) at main.c:9
#2 0x080483e9 in main () at main.c:14
(gdb) info registers
eax 0x5 5
ecx 0xbff1c440 -1074674624
edx 0x3 3
ebx 0xb7fe6ff4 -1208061964
esp 0xbff1c3f4 0xbff1c3f4
ebp 0xbff1c404 0xbff1c404
esi 0x8048410 134513680
edi 0x80482e0 134513376
eip 0x80483a8 0x80483a8 <bar+20>
eflags 0x200206 [ PF IF ID ]
cs 0x73 115
ss 0x7b 123
ds 0x7b 123
es 0x7b 123
fs 0x0 0
gs 0x33 51
(gdb) x/20 $esp
0xbff1c3f4: 0x00000000 0xbff1c6f7 0xb7efbdae 0x00000005
0xbff1c404: 0xbff1c414 0x080483c2 0x00000002 0x00000003
0xbff1c414: 0xbff1c428 0x080483e9 0x00000002 0x00000003
0xbff1c424: 0xbff1c440 0xbff1c498 0xb7ea3685 0x08048410
0xbff1c434: 0x080482e0 0xbff1c498 0xb7ea3685 0x00000001
(gdb)
ињЩйЗМеПИзФ®еИ∞еЗ†дЄ™жЦ∞зЪДgdbеСљдї§гАВdisassembleеПѓдї•еПНж±ЗзЉЦељУеЙНеЗљжХ∞жИЦиАЕжМЗеЃЪзЪДеЗљжХ∞пЉМеНХзЛђзФ®disassembleеСљдї§жШѓеПНж±ЗзЉЦељУеЙНеЗљжХ∞пЉМе¶ВжЮЬdisassembleеСљдї§еРОйЭҐиЈЯеЗљжХ∞еРНжИЦеЬ∞еЭАеИЩеПНж±ЗзЉЦжМЗеЃЪзЪДеЗљжХ∞гАВдї•еЙНжИСдїђиЃ≤ињЗstepеСљдї§еПѓдї•дЄАи°Мдї£з†БдЄАи°Мдї£з†БеЬ∞еНХж≠•и∞ГиѓХпЉМиАМињЩйЗМзФ®еИ∞зЪДsiеСљдї§еПѓдї•дЄАжЭ°жМЗдї§дЄАжЭ°жМЗдї§еЬ∞еНХж≠•и∞ГиѓХгАВinfo registersеПѓдї•жШЊз§ЇжЙАжЬЙеѓДе≠ШеЩ®зЪДељУеЙНеАЉгАВеЬ®gdbдЄ≠и°®з§ЇеѓДе≠ШеЩ®еРНжЧґеЙНйЭҐи¶БеК†дЄ™$пЉМдЊЛе¶Вp $espеПѓдї•жЙУеН∞espеѓДе≠ШеЩ®зЪДеАЉпЉМеЬ®дЄКдЊЛдЄ≠espеѓДе≠ШеЩ®зЪДеАЉжШѓ0xbff1c3f4пЉМжЙАдї•x/20 $espеСљдї§жЯ•зЬЛеЖЕе≠ШдЄ≠дїО0xbff1c3f4еЬ∞еЭАеЉАеІЛзЪД20дЄ™32дљНжХ∞гАВеЬ®жЙІи°Мз®ЛеЇПжЧґпЉМжУНдљЬз≥їзїЯдЄЇињЫз®ЛеИЖйЕНдЄАеЭЧж†Из©ЇйЧіжЭ•дњЭе≠ШеЗљжХ∞ж†ИеЄІпЉМespеѓДе≠ШеЩ®жАїжШѓжМЗеРСж†Ий°ґпЉМеЬ®x86еє≥еП∞дЄКињЩдЄ™ж†ИжШѓдїОйЂШеЬ∞еЭАеРСдљОеЬ∞еЭАеҐЮйХњзЪДпЉМжИСдїђзЯ•йБУжѓПжђ°и∞ГзФ®дЄАдЄ™еЗљжХ∞йГљи¶БеИЖйЕНдЄАдЄ™ж†ИеЄІжЭ•дњЭе≠ШеПВжХ∞еТМе±АйГ®еПШйЗПпЉМзО∞еЬ®жИСдїђиѓ¶зїЖеИЖжЮРињЩдЇЫжХ∞жНЃеЬ®ж†Из©ЇйЧізЪДеЄГе±АпЉМж†єжНЃgdbзЪДиЊУеЗЇзїУжЮЬеЫЊз§Їе¶ВдЄЛ[[29](#ftn.id2775282)]пЉЪ
еЫЊ¬†19.1.¬†еЗљжХ∞ж†ИеЄІ
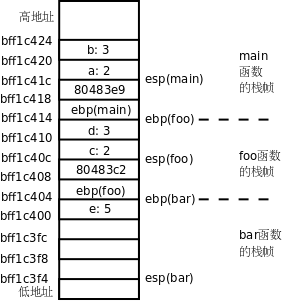
еЫЊдЄ≠жѓПдЄ™е∞ПжЦєж†Љи°®з§Ї4дЄ™е≠ЧиКВзЪДеЖЕе≠ШеНХеЕГпЉМдЊЛе¶Вb: 3ињЩдЄ™е∞ПжЦєж†ЉеН†зЪДеЖЕе≠ШеЬ∞еЭАжШѓ0xbf822d20~0xbf822d23пЉМжИСжККеЬ∞еЭАеЖЩеЬ®жѓПдЄ™е∞ПжЦєж†ЉзЪДдЄЛиЊєзХМзЇњдЄКпЉМжШѓдЄЇдЇЖеЉЇи∞Гиѓ•еЬ∞еЭАжШѓеЖЕе≠ШеНХеЕГзЪДиµЈеІЛеЬ∞еЭАгАВжИСдїђдїОmainеЗљжХ∞зЪДињЩйЗМеЉАеІЛзЬЛиµЈпЉЪ
foo(2, 3);
80483d5: c7 44 24 04 03 00 00 movl $0x3,0x4(%esp)
80483dc: 00
80483dd: c7 04 24 02 00 00 00 movl $0x2,(%esp)
80483e4: e8 c1 ff ff ff call 80483aa <foo>
return 0;
80483e9: b8 00 00 00 00 mov $0x0,%eax
и¶Би∞ГзФ®еЗљжХ∞fooеЕИи¶БжККеПВжХ∞еЗЖе§Зе•љпЉМзђђдЇМдЄ™еПВжХ∞дњЭе≠ШеЬ®esp+4жМЗеРСзЪДеЖЕе≠ШдљНзљЃпЉМзђђдЄАдЄ™еПВжХ∞дњЭе≠ШеЬ®espжМЗеРСзЪДеЖЕе≠ШдљНзљЃпЉМеПѓиІБеПВжХ∞жШѓдїОеП≥еРСеЈ¶дЊЭжђ°еОЛж†ИзЪДгАВзДґеРОжЙІи°МcallжМЗдї§пЉМињЩдЄ™жМЗдї§жЬЙдЄ§дЄ™дљЬзФ®пЉЪ
fooеЗљжХ∞и∞ГзФ®еЃМдєЛеРОи¶БињФеЫЮеИ∞callзЪДдЄЛдЄАжЭ°жМЗдї§зїІзї≠жЙІи°МпЉМжЙАдї•жККcallзЪДдЄЛдЄАжЭ°жМЗдї§зЪДеЬ∞еЭА0x80483e9еОЛж†ИпЉМеРМжЧґжККespзЪДеАЉеЗП4пЉМespзЪДеАЉзО∞еЬ®жШѓ0xbf822d18гАВдњЃжФєз®ЛеЇПиЃ°жХ∞еЩ®
eipпЉМиЈ≥иљђеИ∞fooеЗљжХ∞зЪДеЉАе§іжЙІи°МгАВ
зО∞еЬ®зЬЛfooеЗљжХ∞зЪДж±ЗзЉЦдї£з†БпЉЪ
int foo(int a, int b)
{
80483aa: 55 push %ebp
80483ab: 89 e5 mov %esp,%ebp
80483ad: 83 ec 08 sub $0x8,%esp
push %ebpжМЗдї§жККebpеѓДе≠ШеЩ®зЪДеАЉеОЛж†ИпЉМеРМжЧґжККespзЪДеАЉеЗП4гАВespзЪДеАЉзО∞еЬ®жШѓ0xbf822d14пЉМдЄЛдЄАжЭ°жМЗдї§жККињЩдЄ™еАЉдЉ†йАБзїЩebpеѓДе≠ШеЩ®гАВињЩдЄ§жЭ°жМЗдї§еРИиµЈжЭ•жШѓжККеОЯжЭ•ebpзЪДеАЉдњЭе≠ШеЬ®ж†ИдЄКпЉМзДґеРОеПИзїЩebpиµЛдЇЖжЦ∞еАЉгАВеЬ®жѓПдЄ™еЗљжХ∞зЪДж†ИеЄІдЄ≠пЉМebpжМЗеРСж†ИеЇХпЉМиАМespжМЗеРСж†Ий°ґпЉМеЬ®еЗљжХ∞жЙІи°МињЗз®ЛдЄ≠espйЪПзЭАеОЛж†ИеТМеЗЇж†ИжУНдљЬйЪПжЧґеПШеМЦпЉМиАМebpжШѓдЄНеК®зЪДпЉМеЗљжХ∞зЪДеПВжХ∞еТМе±АйГ®еПШйЗПйГљжШѓйАЪињЗebpзЪДеАЉеК†дЄКдЄАдЄ™еБПзІїйЗПжЭ•иЃњйЧЃпЉМдЊЛе¶ВfooеЗљжХ∞зЪДеПВжХ∞aеТМbеИЖеИЂйАЪињЗebp+8еТМebp+12жЭ•иЃњйЧЃгАВжЙАдї•дЄЛйЭҐзЪДжМЗдї§жККеПВжХ∞aеТМbеЖНжђ°еОЛж†ИпЉМдЄЇи∞ГзФ®barеЗљжХ∞еБЪеЗЖе§ЗпЉМзДґеРОжККињФеЫЮеЬ∞еЭАеОЛж†ИпЉМи∞ГзФ®barеЗљжХ∞пЉЪ
return bar(a, b);
80483b0: 8b 45 0c mov 0xc(%ebp),%eax
80483b3: 89 44 24 04 mov %eax,0x4(%esp)
80483b7: 8b 45 08 mov 0x8(%ebp),%eax
80483ba: 89 04 24 mov %eax,(%esp)
80483bd: e8 d2 ff ff ff call 8048394 <bar>
зО∞еЬ®зЬЛbarеЗљжХ∞зЪДжМЗдї§пЉЪ
int bar(int c, int d)
{
8048394: 55 push %ebp
8048395: 89 e5 mov %esp,%ebp
8048397: 83 ec 10 sub $0x10,%esp
int e = c + d;
804839a: 8b 55 0c mov 0xc(%ebp),%edx
804839d: 8b 45 08 mov 0x8(%ebp),%eax
80483a0: 01 d0 add %edx,%eax
80483a2: 89 45 fc mov %eax,-0x4(%ebp)
ињЩжђ°еПИжККfooеЗљжХ∞зЪДebpеОЛж†ИдњЭе≠ШпЉМзДґеРОзїЩebpиµЛдЇЖжЦ∞еАЉпЉМжМЗеРСbarеЗљжХ∞ж†ИеЄІзЪДж†ИеЇХпЉМйАЪињЗebp+8еТМebp+12еИЖеИЂеПѓдї•иЃњйЧЃеПВжХ∞cеТМdгАВbarеЗљжХ∞ињШжЬЙдЄАдЄ™е±АйГ®еПШйЗПeпЉМеПѓдї•йАЪињЗebp-4жЭ•иЃњйЧЃгАВжЙАдї•еРОйЭҐеЗ†жЭ°жМЗдї§зЪДжДПжАЭжШѓжККеПВжХ∞cеТМdеПЦеЗЇжЭ•е≠ШеЬ®еѓДе≠ШеЩ®дЄ≠еБЪеК†ж≥ХпЉМиЃ°зЃЧзїУжЮЬдњЭе≠ШеЬ®eaxеѓДе≠ШеЩ®дЄ≠пЉМеЖНжККeaxеѓДе≠ШеЩ®е≠ШеЫЮе±АйГ®еПШйЗПeзЪДеЖЕе≠ШеНХеЕГгАВ
еЬ®gdbдЄ≠еПѓдї•зФ®btеСљдї§еТМframeеСљдї§жЯ•зЬЛжѓПе±Вж†ИеЄІдЄКзЪДеПВжХ∞еТМе±АйГ®еПШйЗПпЉМзО∞еЬ®еПѓдї•иІ£йЗКеЃГзЪДеЈ•дљЬеОЯзРЖдЇЖпЉЪе¶ВжЮЬжИСељУеЙНеЬ®barеЗљжХ∞дЄ≠пЉМжИСеПѓдї•йАЪињЗebpжЙЊеИ∞barеЗљжХ∞зЪДеПВжХ∞еТМе±АйГ®еПШйЗПпЉМдєЯеПѓдї•жЙЊеИ∞fooеЗљжХ∞зЪДebpдњЭе≠ШеЬ®ж†ИдЄКзЪДеАЉпЉМжЬЙдЇЖfooеЗљжХ∞зЪДebpпЉМеПИеПѓдї•жЙЊеИ∞еЃГзЪДеПВжХ∞еТМе±АйГ®еПШйЗПпЉМдєЯеПѓдї•жЙЊеИ∞mainеЗљжХ∞зЪДebpдњЭе≠ШеЬ®ж†ИдЄКзЪДеАЉпЉМеЫ†ж≠§еРДе±ВеЗљжХ∞ж†ИеЄІйАЪињЗдњЭе≠ШеЬ®ж†ИдЄКзЪДebpзЪДеАЉдЄ≤иµЈжЭ•дЇЖгАВ
зО∞еЬ®зЬЛbarеЗљжХ∞зЪДињФеЫЮжМЗдї§пЉЪ
return e;
80483a5: 8b 45 fc mov -0x4(%ebp),%eax
}
80483a8: c9 leave
80483a9: c3 ret
barеЗљжХ∞жЬЙдЄАдЄ™intеЮЛзЪДињФеЫЮеАЉпЉМињЩдЄ™ињФеЫЮеАЉжШѓйАЪињЗeaxеѓДе≠ШеЩ®дЉ†йАТзЪДпЉМжЙАдї•й¶ЦеЕИжККeзЪДеАЉиѓїеИ∞eaxеѓДе≠ШеЩ®дЄ≠гАВзДґеРОжЙІи°МleaveжМЗдї§пЉМињЩдЄ™жМЗдї§жШѓеЗљжХ∞еЉАе§ізЪДpush %ebpеТМmov %esp,%ebpзЪДйАЖжУНдљЬпЉЪ
жКК
ebpзЪДеАЉиµЛзїЩespпЉМзО∞еЬ®espзЪДеАЉжШѓ0xbf822d04гАВзО∞еЬ®
espжЙАжМЗеРСзЪДж†Ий°ґдњЭе≠ШзЭАfooеЗљжХ∞ж†ИеЄІзЪДebpпЉМжККињЩдЄ™еАЉжБҐе§НзїЩebpпЉМеРМжЧґespеҐЮеК†4пЉМespзЪДеАЉеПШжИР0xbf822d08гАВ
жЬАеРОжШѓretжМЗдї§пЉМеЃГжШѓcallжМЗдї§зЪДйАЖжУНдљЬпЉЪ
зО∞еЬ®
espжЙАжМЗеРСзЪДж†Ий°ґдњЭе≠ШзЭАињФеЫЮеЬ∞еЭАпЉМжККињЩдЄ™еАЉжБҐе§НзїЩeipпЉМеРМжЧґespеҐЮеК†4пЉМespзЪДеАЉеПШжИР0xbf822d0cгАВдњЃжФєдЇЖз®ЛеЇПиЃ°жХ∞еЩ®
eipпЉМеЫ†ж≠§иЈ≥иљђеИ∞ињФеЫЮеЬ∞еЭА0x80483c2зїІзї≠жЙІи°МгАВ
еЬ∞еЭА0x80483c2е§ДжШѓfooеЗљжХ∞зЪДињФеЫЮжМЗдї§пЉЪ
80483c2: c9 leave
80483c3: c3 ret
йЗНе§НеРМж†ЈзЪДињЗз®ЛпЉМеПИињФеЫЮеИ∞дЇЖmainеЗљжХ∞гАВж≥®жДПеЗљжХ∞и∞ГзФ®еТМињФеЫЮињЗз®ЛдЄ≠зЪДињЩдЇЫиІДеИЩпЉЪ
еПВжХ∞еОЛж†ИдЉ†йАТпЉМеєґдЄФжШѓдїОеП≥еРСеЈ¶дЊЭжђ°еОЛж†ИгАВ
ebpжАїжШѓжМЗеРСељУеЙНж†ИеЄІзЪДж†ИеЇХгАВињФеЫЮеАЉйАЪињЗ
eaxеѓДе≠ШеЩ®дЉ†йАТгАВ
ињЩдЇЫиІДеИЩеєґдЄНжШѓдљУз≥їзїУжЮДжЙАеЉЇеК†зЪДпЉМebpеѓДе≠ШеЩ®еєґдЄНжШѓењЕй°їињЩдєИзФ®пЉМеЗљжХ∞зЪДеПВжХ∞еТМињФеЫЮеАЉдєЯдЄНжШѓењЕй°їињЩдєИдЉ†пЉМеП™жШѓжУНдљЬз≥їзїЯеТМзЉЦиѓСеЩ®йАЙжЛ©дЇЖдї•ињЩж†ЈзЪДжЦєеЉПеЃЮзО∞Cдї£з†БдЄ≠зЪДеЗљжХ∞и∞ГзФ®пЉМињЩзІ∞дЄЇCalling ConventionпЉМCalling ConventionжШѓжУНдљЬз≥їзїЯдЇМињЫеИґжО•еП£иІДиМГпЉИABIпЉМApplication Binary InterfaceпЉЙзЪДдЄАйГ®еИЖгАВ
дє†йҐШ
1гАБеЬ®зђђ¬†2¬†иКВ вАЬиЗ™еЃЪдєЙеЗљжХ∞вАЭиЃ≤ињЗпЉМOld Style Cй£Ож†ЉзЪДеЗљжХ∞е£∞жШОеПѓдї•дЄНжМЗеЃЪеПВжХ∞дЄ™жХ∞еТМз±їеЮЛпЉМињЩж†ЈзЉЦиѓСеЩ®дЄНдЉЪеѓєеЗљжХ∞и∞ГзФ®еБЪж£АжЯ•пЉМйВ£дєИе¶ВжЮЬи∞ГзФ®жЧґзЪДеПВжХ∞з±їеЮЛдЄНеѓєжИЦиАЕеПВжХ∞дЄ™жХ∞дЄНеѓєдЉЪжАОдєИж†ЈеСҐпЉЯжѓФе¶ВжККжЬђиКВзЪДдЊЛе≠РжФєжИРињЩж†ЈпЉЪ
int foo();
int bar();
int main(void)
{
foo(2, 3, 4);
return 0;
}
int foo(int a, int b)
{
return bar(a);
}
int bar(int c, int d)
{
int e = c + d;
return e;
}
mainеЗљжХ∞и∞ГзФ®fooжЧґе§ЪдЉ†дЇЖдЄАдЄ™еПВжХ∞пЉМйВ£дєИеПВжХ∞aеТМbеИЖеИЂеПЦдїАдєИеАЉпЉЯе§ЪзЪДеПВжХ∞жАОдєИеКЮпЉЯfooи∞ГзФ®barжЧґе∞СдЉ†дЇЖдЄАдЄ™еПВжХ∞пЉМйВ£дєИеПВжХ∞dзЪДеАЉдїОеУ™йЗМеПЦеЊЧпЉЯиѓЈиѓїиАЕеИ©зФ®еПНж±ЗзЉЦеТМgdbиЗ™еЈ±еИЖжЮРдЄАдЄЛгАВжИСдїђеЖНзЬЛдЄАдЄ™еПВжХ∞з±їеЮЛдЄНзђ¶зЪДдЊЛе≠РпЉЪ
#include <stdio.h>
int main(void)
{
void foo();
char c = 60;
foo(c);
return 0;
}
void foo(double d)
{
printf("%f
", d);
}
жЙУеН∞зїУжЮЬжШѓе§Ъе∞СпЉЯе¶ВжЮЬжККе£∞жШОvoid foo();жФєжИРvoid foo(double);пЉМжЙУеН∞зїУжЮЬеПИжШѓе§Ъе∞СпЉЯ
[[29](#id2775282)] LinuxеЖЕж†ЄдЄЇжѓПдЄ™жЦ∞ињЫз®ЛжМЗеЃЪзЪДж†Из©ЇйЧізЪДиµЈеІЛеЬ∞еЭАйГљдЉЪжЬЙдЇЫдЄНеРМпЉМжЙАдї•жѓПжђ°ињРи°МињЩдЄ™з®ЛеЇПеЊЧеИ∞зЪДеЬ∞еЭАйГљдЄНдЄАж†ЈпЉМдљЖйАЪеЄЄйГљжШѓ0xbf??????ињЩж†ЈдЄАдЄ™еЬ∞еЭАгАВ
2.¬†mainеЗљжХ∞еТМеРѓеК®дЊЛз®Л
дЄЇдїАдєИж±ЗзЉЦз®ЛеЇПзЪДеЕ•еП£жШѓ_startпЉМиАМCз®ЛеЇПзЪДеЕ•еП£жШѓmainеЗљжХ∞еСҐпЉЯжЬђиКВе∞±жЭ•иІ£йЗКињЩдЄ™йЧЃйҐШгАВеЬ®иЃ≤дЊЛ¬†18.1 вАЬжЬАзЃАеНХзЪДж±ЗзЉЦз®ЛеЇПвАЭжЧґпЉМжИСдїђзЪДж±ЗзЉЦеТМйУЊжО•ж≠•й™§жШѓпЉЪ
$ as hello.s -o hello.o
$ ld hello.o -o hello
дї•еЙНжИСдїђеЄЄзФ®gcc main.c -o mainеСљдї§зЉЦиѓСдЄАдЄ™з®ЛеЇПпЉМеЕґеЃЮдєЯеПѓдї•еИЖдЄЙж≠•еБЪпЉМзђђдЄАж≠•зФЯжИРж±ЗзЉЦдї£з†БпЉМзђђдЇМж≠•зФЯжИРзЫЃж†ЗжЦЗдїґпЉМзђђдЄЙж≠•зФЯжИРеПѓжЙІи°МжЦЗдїґпЉЪ
$ gcc -S main.c
$ gcc -c main.s
$ gcc main.o
-SйАЙй°єзФЯжИРж±ЗзЉЦдї£з†БпЉМ-cйАЙй°єзФЯжИРзЫЃж†ЗжЦЗдїґпЉМж≠§е§ЦеЬ®зђђ¬†2¬†иКВ вАЬжХ∞зїДеЇФзФ®еЃЮдЊЛпЉЪзїЯиЃ°йЪПжЬЇжХ∞вАЭињШиЃ≤ињЗ-EйАЙй°єеП™еБЪйҐДе§ДзРЖиАМдЄНзЉЦиѓСпЉМе¶ВжЮЬдЄНеК†ињЩдЇЫйАЙй°єеИЩgccжЙІи°МеЃМжХізЪДзЉЦиѓСж≠•й™§пЉМзЫіеИ∞жЬАеРОйУЊжО•зФЯжИРеПѓжЙІи°МжЦЗдїґдЄЇж≠ҐгАВе¶ВдЄЛеЫЊжЙАз§ЇгАВ
еЫЊ¬†19.2.¬†gccеСљдї§зЪДйАЙй°є
ињЩдЇЫйАЙй°єйГљеПѓдї•еТМ-oжР≠йЕНдљњзФ®пЉМзїЩиЊУеЗЇзЪДжЦЗдїґйЗНжЦ∞еСљеРНиАМдЄНдљњзФ®gccйїШиЃ§зЪДжЦЗдїґеРНпЉИxxx.cгАБxxx.sгАБxxx.oеТМa.outпЉЙпЉМдЊЛе¶Вgcc main.o -o mainе∞Жmain.oйУЊжО•жИРеПѓжЙІи°МжЦЗдїґmainгАВеЕИеЙНзФ±ж±ЗзЉЦдї£з†БдЊЛ¬†18.1 вАЬжЬАзЃАеНХзЪДж±ЗзЉЦз®ЛеЇПвАЭзФЯжИРзЪДзЫЃж†ЗжЦЗдїґhello.oжИСдїђжШѓзФ®ldжЭ•йУЊжО•зЪДпЉМеПѓдЄНеПѓдї•зФ®gccйУЊжО•еСҐпЉЯиѓХиѓХзЬЛгАВ
$ gcc hello.o -o hello
hello.o: In function `_start":
(.text+0x0): multiple definition of `_start"
/usr/lib/gcc/i486-linux-gnu/4.3.2/../../../../lib/crt1.o:(.text+0x0): first defined here
/usr/lib/gcc/i486-linux-gnu/4.3.2/../../../../lib/crt1.o: In function `_start":
(.text+0x18): undefined reference to `main"
collect2: ld returned 1 exit status
жПРз§ЇдЄ§дЄ™йФЩиѓѓпЉЪдЄАжШѓ_startжЬЙе§ЪдЄ™еЃЪдєЙпЉМдЄАдЄ™еЃЪдєЙжШѓзФ±жИСдїђзЪДж±ЗзЉЦдї£з†БжПРдЊЫзЪДпЉМеП¶дЄАдЄ™еЃЪдєЙжЭ•иЗ™/usr/lib/crt1.oпЉЫдЇМжШѓcrt1.oзЪД_startеЗљжХ∞и¶Би∞ГзФ®mainеЗљжХ∞пЉМиАМжИСдїђзЪДж±ЗзЉЦдї£з†БдЄ≠ж≤°жЬЙжПРдЊЫmainеЗљжХ∞зЪДеЃЪдєЙгАВдїОжЬАеРОдЄАи°МињШеПѓдї•зЬЛеЗЇињЩдЇЫйФЩиѓѓжПРз§ЇжШѓзФ±ldзїЩеЗЇзЪДгАВзФ±ж≠§еПѓиІБпЉМе¶ВжЮЬжИСдїђзФ®gccеБЪйУЊжО•пЉМgccеЕґеЃЮжШѓи∞ГзФ®ldе∞ЖзЫЃж†ЗжЦЗдїґcrt1.oеТМжИСдїђзЪДhello.oйУЊжО•еЬ®дЄАиµЈгАВcrt1.oйЗМйЭҐеЈ≤зїПжПРдЊЫдЇЖ_startеЕ•еП£зВєпЉМжИСдїђзЪДж±ЗзЉЦз®ЛеЇПдЄ≠еЖНеЃЮзО∞дЄАдЄ™_startе∞±жШѓе§ЪйЗНеЃЪдєЙдЇЖпЉМйУЊжО•еЩ®дЄНзЯ•йБУиѓ•зФ®еУ™дЄ™пЉМеП™е•љжК•йФЩгАВеП¶е§ЦпЉМcrt1.oжПРдЊЫзЪД_startйЬАи¶Би∞ГзФ®mainеЗљжХ∞пЉМиАМжИСдїђзЪДж±ЗзЉЦз®ЛеЇПдЄ≠ж≤°жЬЙеЃЮзО∞mainеЗљжХ∞пЉМжЙАдї•жК•йФЩгАВ
е¶ВжЮЬзЫЃж†ЗжЦЗдїґжШѓзФ±Cдї£з†БзЉЦиѓСзФЯжИРзЪДпЉМзФ®gccеБЪйУЊжО•е∞±ж≤°йФЩдЇЖпЉМжХідЄ™з®ЛеЇПзЪДеЕ•еП£зВєжШѓcrt1.oдЄ≠жПРдЊЫзЪД_startпЉМеЃГй¶ЦеЕИеБЪдЄАдЇЫеИЭеІЛеМЦеЈ•дљЬпЉИдї•дЄЛзІ∞дЄЇеРѓеК®дЊЛз®ЛпЉМStartup RoutineпЉЙпЉМзДґеРОи∞ГзФ®Cдї£з†БдЄ≠жПРдЊЫзЪДmainеЗљжХ∞гАВжЙАдї•пЉМдї•еЙНжИСдїђиѓіmainеЗљжХ∞жШѓз®ЛеЇПзЪДеЕ•еП£зВєеЕґеЃЮдЄНеЗЖз°ЃпЉМ_startжЙНжШѓзЬЯж≠£зЪДеЕ•еП£зВєпЉМиАМmainеЗљжХ∞ж؃襀_startи∞ГзФ®зЪДгАВ
жИСдїђзїІзї≠з†Фз©ґдЄКдЄАиКВзЪДдЊЛ¬†19.1 вАЬз†Фз©ґеЗљжХ∞зЪДи∞ГзФ®ињЗз®ЛвАЭгАВе¶ВжЮЬеИЖдЄ§ж≠•зЉЦиѓСпЉМзђђдЇМж≠•gcc main.o -o mainеЕґеЃЮжШѓи∞ГзФ®ldеБЪйУЊжО•зЪДпЉМзЫЄељУдЇОињЩж†ЈзЪДеСљдї§пЉЪ
$ ld /usr/lib/crt1.o /usr/lib/crti.o main.o -o main -lc -dynamic-linker /lib/ld-linux.so.2
дєЯе∞±жШѓиѓіпЉМйЩ§дЇЖcrt1.oдєЛе§ЦеЕґеЃЮињШжЬЙcrti.oпЉМињЩдЄ§дЄ™зЫЃж†ЗжЦЗдїґеТМжИСдїђзЪДmain.oйУЊжО•еЬ®дЄАиµЈзФЯжИРеПѓжЙІи°МжЦЗдїґmainгАВ-lcи°®з§ЇйЬАи¶БйУЊжО•libcеЇУпЉМеЬ®зђђ¬†1¬†иКВ вАЬжХ∞е≠¶еЗљжХ∞вАЭиЃ≤ињЗ-lcйАЙй°єжШѓgccйїШиЃ§зЪДпЉМдЄНзФ®еЖЩпЉМиАМеѓєдЇОldеИЩдЄНжШѓйїШиЃ§йАЙй°єпЉМжЙАдї•и¶БеЖЩдЄКгАВ-dynamic-linker /lib/ld-linux.so.2жМЗеЃЪеК®жАБйУЊжО•еЩ®жШѓ/lib/ld-linux.so.2пЉМз®НеРОдЉЪиІ£йЗКдїАдєИжШѓеК®жАБйУЊжО•гАВ
йВ£дєИcrt1.oеТМcrti.oйЗМйЭҐйГљжЬЙдїАдєИеСҐпЉЯжИСдїђеПѓдї•зФ®readelfеСљдї§жЯ•зЬЛгАВеЬ®ињЩйЗМжИСдїђеП™еЕ≥ењГзђ¶еПЈи°®пЉМе¶ВжЮЬеП™зЬЛзђ¶еПЈи°®пЉМеПѓдї•зФ®readelfеСљдї§зЪД-sйАЙй°єпЉМдєЯеПѓдї•зФ®nmеСљдї§гАВ
$ nm /usr/lib/crt1.o
00000000 R _IO_stdin_used
00000000 D __data_start
U __libc_csu_fini
U __libc_csu_init
U __libc_start_main
00000000 R _fp_hw
00000000 T _start
00000000 W data_start
U main
$ nm /usr/lib/crti.o
U _GLOBAL_OFFSET_TABLE_
w __gmon_start__
00000000 T _fini
00000000 T _init
U mainињЩдЄАи°Ми°®з§ЇmainињЩдЄ™зђ¶еПЈеЬ®crt1.oдЄ≠зФ®еИ∞дЇЖпЉМдљЖжШѓж≤°жЬЙеЃЪдєЙпЉИUи°®з§ЇUndefinedпЉЙпЉМеЫ†ж≠§йЬАи¶БеИЂзЪДзЫЃж†ЗжЦЗдїґжПРдЊЫдЄАдЄ™еЃЪдєЙеєґдЄФеТМcrt1.oйУЊжО•еЬ®дЄАиµЈгАВеЕЈдљУжЭ•иѓіпЉМеЬ®crt1.oдЄ≠и¶БзФ®еИ∞mainињЩдЄ™зђ¶еПЈжЙАдї£и°®зЪДеЬ∞еЭАпЉМдЊЛе¶ВжЬЙдЄАжЭ°жМЗдї§жШѓpush $зђ¶еПЈmainжЙАдї£и°®зЪДеЬ∞еЭАпЉМдљЖдЄНзЯ•йБУињЩдЄ™еЬ∞еЭАжШѓе§Ъе∞СпЉМжЙАдї•еЬ®crt1.oдЄ≠ињЩжЭ°жМЗдї§жЪВжЧґеЖЩжИРpush $0x0пЉМз≠ЙеИ∞еТМmain.oйУЊжО•жИРеПѓжЙІи°МжЦЗдїґжЧґе∞±зЯ•йБУињЩдЄ™еЬ∞еЭАжШѓе§Ъе∞СдЇЖпЉМжѓФе¶ВжШѓ0x80483c4пЉМйВ£дєИеПѓжЙІи°МжЦЗдїґmainдЄ≠зЪДињЩжЭ°жМЗдї§е∞±иҐЂйУЊжО•еЩ®жФєжИРдЇЖpush $0x80483c4гАВйУЊжО•еЩ®еЬ®ињЩйЗМиµЈеИ∞зђ¶еПЈиІ£жЮРпЉИSymbol ResolutionпЉЙзЪДдљЬзФ®пЉМеЬ®зђђ¬†5.2¬†иКВ вАЬеПѓжЙІи°МжЦЗдїґвАЭжИСдїђзЬЛеИ∞йУЊжО•еЩ®иµЈеИ∞йЗНеЃЪдљНзЪДдљЬзФ®пЉМињЩдЄ§зІНдљЬзФ®йГљжШѓйАЪињЗдњЃжФєжМЗдї§дЄ≠зЪДеЬ∞еЭАеЃЮзО∞зЪДпЉМйУЊжО•еЩ®дєЯжШѓдЄАзІНзЉЦиЊСеЩ®пЉМviеТМemacsзЉЦиЊСзЪДжШѓжЇРжЦЗдїґпЉМиАМйУЊжО•еЩ®зЉЦиЊСзЪДжШѓзЫЃж†ЗжЦЗдїґпЉМжЙАдї•йУЊжО•еЩ®дєЯеПЂLink EditorгАВT _startињЩдЄАи°Ми°®з§Ї_startињЩдЄ™зђ¶еПЈеЬ®crt1.oдЄ≠жПРдЊЫдЇЖеЃЪдєЙпЉМињЩдЄ™зђ¶еПЈзЪДз±їеЮЛжШѓдї£з†БпЉИTи°®з§ЇTextпЉЙгАВжИСдїђдїОдЄКйЭҐзЪДиЊУеЗЇзїУжЮЬдЄ≠йАЙеПЦеЗ†дЄ™зђ¶еПЈзФ®еЫЊз§ЇиѓіжШОеЃГдїђдєЛйЧізЪДеЕ≥з≥їпЉЪ
еЫЊ¬†19.3.¬†Cз®ЛеЇПзЪДйУЊжО•ињЗз®Л
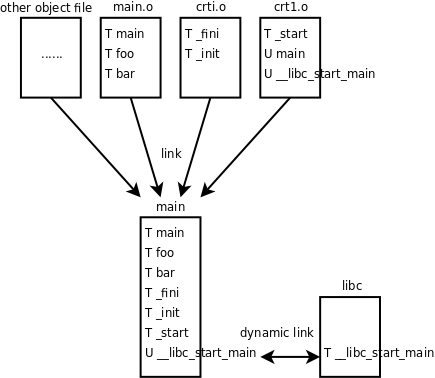
еЕґеЃЮдЄКйЭҐжИСдїђеЖЩзЪДldеСљдї§еБЪдЇЖеЊИе§ЪзЃАеМЦпЉМgccеЬ®йУЊжО•жЧґињШзФ®еИ∞дЇЖеП¶е§ЦеЗ†дЄ™зЫЃж†ЗжЦЗдїґпЉМжЙАдї•дЄКеЫЊе§ЪзФїдЇЖдЄАдЄ™ж°ЖпЉМи°®з§ЇзїДжИРеПѓжЙІи°МжЦЗдїґmainзЪДйЩ§дЇЖmain.oгАБcrt1.oеТМcrti.oдєЛе§ЦињШжЬЙеЕґеЃГзЫЃж†ЗжЦЗдїґпЉМжЬђдє¶дЄНеБЪжЈ±еЕ•иЃ®иЃЇпЉМзФ®gccзЪД-vйАЙй°єеПѓдї•дЇЖиІ£иѓ¶зїЖзЪДзЉЦиѓСињЗз®ЛпЉЪ
$ gcc -v main.c -o main
Using built-in specs.
Target: i486-linux-gnu
...
/usr/lib/gcc/i486-linux-gnu/4.3.2/cc1 -quiet -v main.c -D_FORTIFY_SOURCE=2 -quiet -dumpbase main.c -mtune=generic -auxbase main -version -fstack-protector -o /tmp/ccRGDpua.s
...
as -V -Qy -o /tmp/ccidnZ1d.o /tmp/ccRGDpua.s
...
/usr/lib/gcc/i486-linux-gnu/4.3.2/collect2 --eh-frame-hdr -m elf_i386 --hash-style=both -dynamic-linker /lib/ld-linux.so.2 -o main -z relro /usr/lib/gcc/i486-linux-gnu/4.3.2/../../../../lib/crt1.o /usr/lib/gcc/i486-linux-gnu/4.3.2/../../../../lib/crti.o /usr/lib/gcc/i486-linux-gnu/4.3.2/crtbegin.o -L/usr/lib/gcc/i486-linux-gnu/4.3.2 -L/usr/lib/gcc/i486-linux-gnu/4.3.2 -L/usr/lib/gcc/i486-linux-gnu/4.3.2/../../../../lib -L/lib/../lib -L/usr/lib/../lib -L/usr/lib/gcc/i486-linux-gnu/4.3.2/../../.. /tmp/ccidnZ1d.o -lgcc --as-needed -lgcc_s --no-as-needed -lc -lgcc --as-needed -lgcc_s --no-as-needed /usr/lib/gcc/i486-linux-gnu/4.3.2/crtend.o /usr/lib/gcc/i486-linux-gnu/4.3.2/../../../../lib/crtn.o
йУЊжО•зФЯжИРзЪДеПѓжЙІи°МжЦЗдїґmainдЄ≠еМЕеРЂдЇЖеРДзЫЃж†ЗжЦЗдїґжЙАеЃЪдєЙзЪДзђ¶еПЈпЉМйАЪињЗеПНж±ЗзЉЦеПѓдї•зЬЛеИ∞ињЩдЇЫзђ¶еПЈзЪДеЃЪдєЙпЉЪ
$ objdump -d main
main: file format elf32-i386
Disassembly of section .init:
08048274 <_init>:
8048274: 55 push %ebp
8048275: 89 e5 mov %esp,%ebp
8048277: 53 push %ebx
...
Disassembly of section .text:
080482e0 <_start>:
80482e0: 31 ed xor %ebp,%ebp
80482e2: 5e pop %esi
80482e3: 89 e1 mov %esp,%ecx
...
08048394 <bar>:
8048394: 55 push %ebp
8048395: 89 e5 mov %esp,%ebp
8048397: 83 ec 10 sub $0x10,%esp
...
080483aa <foo>:
80483aa: 55 push %ebp
80483ab: 89 e5 mov %esp,%ebp
80483ad: 83 ec 08 sub $0x8,%esp
...
080483c4 <main>:
80483c4: 8d 4c 24 04 lea 0x4(%esp),%ecx
80483c8: 83 e4 f0 and $0xfffffff0,%esp
80483cb: ff 71 fc pushl -0x4(%ecx)
...
Disassembly of section .fini:
0804849c <_fini>:
804849c: 55 push %ebp
804849d: 89 e5 mov %esp,%ebp
804849f: 53 push %ebx
crt1.oдЄ≠зЪДжЬ™еЃЪдєЙзђ¶еПЈmainеЬ®main.oдЄ≠еЃЪдєЙдЇЖпЉМжЙАдї•йУЊжО•еЬ®дЄАиµЈе∞±ж≤°йЧЃйҐШдЇЖгАВcrt1.oињШжЬЙдЄАдЄ™жЬ™еЃЪдєЙзђ¶еПЈ__libc_start_mainеЬ®еЕґеЃГеЗ†дЄ™зЫЃж†ЗжЦЗдїґдЄ≠дєЯж≤°жЬЙеЃЪдєЙпЉМжЙАдї•еЬ®еПѓжЙІи°МжЦЗдїґmainдЄ≠дїНзДґжШѓдЄ™жЬ™еЃЪдєЙзђ¶еПЈгАВињЩдЄ™зђ¶еПЈжШѓеЬ®libcдЄ≠еЃЪдєЙзЪДпЉМlibcеєґдЄНеГПеЕґеЃГзЫЃж†ЗжЦЗдїґдЄАж†ЈйУЊжО•еИ∞еПѓжЙІи°МжЦЗдїґmainдЄ≠пЉМиАМжШѓеЬ®ињРи°МжЧґеБЪеК®жАБйУЊжО•пЉЪ
жУНдљЬз≥їзїЯеЬ®еК†иљљжЙІи°М
mainињЩдЄ™з®ЛеЇПжЧґпЉМй¶ЦеЕИжЯ•зЬЛеЃГжЬЙж≤°жЬЙйЬАи¶БеК®жАБйУЊжО•зЪДжЬ™еЃЪдєЙзђ¶еПЈгАВе¶ВжЮЬйЬАи¶БеБЪеК®жАБйУЊжО•пЉМе∞±жЯ•зЬЛињЩдЄ™з®ЛеЇПжМЗеЃЪдЇЖеУ™дЇЫеЕ±дЇЂеЇУпЉИжИСдїђзФ®
-lcжМЗеЃЪдЇЖlibcпЉЙдї•еПКзФ®дїАдєИеК®жАБйУЊжО•еЩ®жЭ•еБЪеК®жАБйУЊжО•пЉИжИСдїђзФ®-dynamic-linker /lib/ld-linux.so.2жМЗеЃЪдЇЖеК®жАБйУЊжО•еЩ®пЉЙгАВеК®жАБйУЊжО•еЩ®еЬ®еЕ±дЇЂеЇУдЄ≠жЯ•жЙЊињЩдЇЫзђ¶еПЈзЪДеЃЪдєЙпЉМеЃМжИРйУЊжО•ињЗз®ЛгАВ
дЇЖиІ£дЇЖињЩдЇЫеОЯзРЖдєЛеРОпЉМзО∞еЬ®жИСдїђжЭ•зЬЛ_startзЪДеПНж±ЗзЉЦпЉЪ
...
Disassembly of section .text:
080482e0 <_start>:
80482e0: 31 ed xor %ebp,%ebp
80482e2: 5e pop %esi
80482e3: 89 e1 mov %esp,%ecx
80482e5: 83 e4 f0 and $0xfffffff0,%esp
80482e8: 50 push %eax
80482e9: 54 push %esp
80482ea: 52 push %edx
80482eb: 68 00 84 04 08 push $0x8048400
80482f0: 68 10 84 04 08 push $0x8048410
80482f5: 51 push %ecx
80482f6: 56 push %esi
80482f7: 68 c4 83 04 08 push $0x80483c4
80482fc: e8 c3 ff ff ff call 80482c4 <__libc_start_main@plt>
...
й¶ЦеЕИе∞ЖдЄАз≥їеИЧеПВжХ∞еОЛж†ИпЉМзДґеРОи∞ГзФ®libcзЪДеЇУеЗљжХ∞__libc_start_mainеБЪеИЭеІЛеМЦеЈ•дљЬпЉМеЕґдЄ≠жЬАеРОдЄАдЄ™еОЛж†ИзЪДеПВжХ∞push $0x80483c4жШѓmainеЗљжХ∞зЪДеЬ∞еЭАпЉМ__libc_start_mainеЬ®еЃМжИРеИЭеІЛеМЦеЈ•дљЬдєЛеРОдЉЪи∞ГзФ®mainеЗљжХ∞гАВзФ±дЇО__libc_start_mainйЬАи¶БеК®жАБйУЊжО•пЉМжЙАдї•ињЩдЄ™еЇУеЗљжХ∞зЪДжМЗдї§еЬ®еПѓжЙІи°МжЦЗдїґmainзЪДеПНж±ЗзЉЦдЄ≠иВѓеЃЪжШѓжЙЊдЄНеИ∞зЪДпЉМзДґиАМжИСдїђжЙЊеИ∞дЇЖињЩдЄ™пЉЪ
Disassembly of section .plt:
...
080482c4 <__libc_start_main@plt>:
80482c4: ff 25 04 a0 04 08 jmp *0x804a004
80482ca: 68 08 00 00 00 push $0x8
80482cf: e9 d0 ff ff ff jmp 80482a4 <_init+0x30>
ињЩдЄЙжЭ°жМЗдї§дљНдЇО.pltжЃµиАМдЄНжШѓ.textжЃµпЉМ.pltжЃµеНПеК©еЃМжИРеК®жАБйУЊжО•зЪДињЗз®ЛгАВжИСдїђе∞ЖеЬ®дЄЛдЄАзЂ†иѓ¶зїЖиЃ≤иІ£еК®жАБйУЊжО•зЪДињЗз®ЛгАВ
mainеЗљжХ∞жЬАж†ЗеЗЖзЪДеОЯеЮЛеЇФиѓ•жШѓint main(int argc, char *argv[])пЉМдєЯе∞±жШѓиѓіеРѓеК®дЊЛз®ЛдЉЪдЉ†дЄ§дЄ™еПВжХ∞зїЩmainеЗљжХ∞пЉМињЩдЄ§дЄ™еПВжХ∞зЪДеРЂдєЙжИСдїђе≠¶дЇЖжМЗйТИдї•еРОеЖНиІ£йЗКгАВжИСдїђеИ∞зЫЃеЙНдЄЇж≠ҐйГљжККmainеЗљжХ∞зЪДеОЯеЮЛеЖЩжИРint main(void)пЉМињЩдєЯжШѓCж†ЗеЗЖеЕБиЃЄзЪДпЉМе¶ВжЮЬдљ†иЃ§зЬЯеИЖжЮРдЇЖдЄКдЄАиКВзЪДдє†йҐШпЉМдљ†е∞±еЇФиѓ•зЯ•йБУпЉМе§ЪдЉ†дЇЖеПВжХ∞иАМдЄНзФ®жШѓж≤°жЬЙйЧЃйҐШзЪДпЉМе∞СдЉ†дЇЖеПВжХ∞еНізФ®дЇЖеИЩдЉЪеЗЇйЧЃйҐШгАВ
зФ±дЇОmainеЗљжХ∞ж؃襀еРѓеК®дЊЛз®Ли∞ГзФ®зЪДпЉМжЙАдї•дїОmainеЗљжХ∞returnжЧґдїНињФеЫЮеИ∞еРѓеК®дЊЛз®ЛдЄ≠пЉМmainеЗљжХ∞зЪДињФеЫЮеАЉиҐЂеРѓеК®дЊЛз®ЛеЊЧеИ∞пЉМе¶ВжЮЬе∞ЖеРѓеК®дЊЛз®Ли°®з§ЇжИРз≠ЙдїЈзЪДCдї£з†БпЉИеЃЮйЩЕдЄКеРѓеК®дЊЛз®ЛдЄАиИђжШѓзЫіжО•зФ®ж±ЗзЉЦеЖЩзЪДпЉЙпЉМеИЩеЃГи∞ГзФ®mainеЗљжХ∞зЪД嚥еЉПжШѓпЉЪ
exit(main(argc, argv));
дєЯе∞±жШѓиѓіпЉМеРѓеК®дЊЛз®ЛеЊЧеИ∞mainеЗљжХ∞зЪДињФеЫЮеАЉеРОпЉМдЉЪзЂЛеИїзФ®еЃГеБЪеПВжХ∞и∞ГзФ®exitеЗљжХ∞гАВexitдєЯжШѓlibcдЄ≠зЪДеЗљжХ∞пЉМеЃГй¶ЦеЕИеБЪдЄАдЇЫжЄЕзРЖеЈ•дљЬпЉМзДґеРОи∞ГзФ®дЄКдЄАзЂ†иЃ≤ињЗзЪД_exitз≥їзїЯи∞ГзФ®зїИж≠ҐињЫз®ЛпЉМmainеЗљжХ∞зЪДињФеЫЮеАЉжЬАзїИ襀䊆зїЩ_exitз≥їзїЯи∞ГзФ®пЉМжИРдЄЇињЫз®ЛзЪДйААеЗЇзКґжАБгАВжИСдїђдєЯеПѓдї•еЬ®mainеЗљжХ∞дЄ≠зЫіжО•и∞ГзФ®exitеЗљжХ∞зїИж≠ҐињЫз®ЛиАМдЄНињФеЫЮеИ∞еРѓеК®дЊЛз®ЛпЉМдЊЛе¶ВпЉЪ
#include <stdlib.h>
int main(void)
{
exit(4);
}
ињЩж†ЈеТМint main(void) { return 4; }зЪДжХИжЮЬжШѓдЄАж†ЈзЪДгАВеЬ®ShellдЄ≠ињРи°МињЩдЄ™з®ЛеЇПеєґжЯ•зЬЛеЃГзЪДйААеЗЇзКґжАБпЉЪ
$ ./a.out
$ echo $?
4
жМЙзЕІжГѓдЊЛпЉМйААеЗЇзКґжАБдЄЇ0и°®з§Їз®ЛеЇПжЙІи°МжИРеКЯпЉМйААеЗЇзКґжАБйЭЮ0и°®з§ЇеЗЇйФЩгАВж≥®жДПпЉМйААеЗЇзКґжАБеП™жЬЙ8дљНпЉМиАМдЄФ襀ShellиІ£йЗКжИРжЧ†зђ¶еПЈжХ∞пЉМе¶ВжЮЬе∞ЖдЄКйЭҐзЪДдї£з†БжФєдЄЇexit(-1);жИЦreturn -1;пЉМеИЩињРи°МзїУжЮЬдЄЇ
$ ./a.out
$ echo $?
255
ж≥®жДПпЉМе¶ВжЮЬе£∞жШОдЄАдЄ™еЗљжХ∞зЪДињФеЫЮеАЉз±їеЮЛжШѓintпЉМеЗљжХ∞дЄ≠жѓПдЄ™еИЖжФѓжОІеИґжµБз®ЛењЕй°їеЖЩreturnиѓ≠еП•жМЗеЃЪињФеЫЮеАЉпЉМе¶ВжЮЬзЉЇдЇЖreturnеИЩињФеЫЮеАЉдЄНз°ЃеЃЪпЉИжГ≥жГ≥ињЩжШѓдЄЇдїАдєИпЉЙпЉМзЉЦиѓСеЩ®йАЪеЄЄжШѓдЉЪжК•и≠¶еСКзЪДпЉМдљЖе¶ВжЮЬжЯРдЄ™еИЖжФѓжОІеИґжµБз®Ли∞ГзФ®дЇЖexitжИЦ_exitиАМдЄНеЖЩreturnпЉМзЉЦиѓСеЩ®жШѓеЕБиЃЄзЪДпЉМеЫ†дЄЇеЃГйГљж≤°жЬЙжЬЇдЉЪињФеЫЮдЇЖпЉМжМЗдЄНжМЗеЃЪињФеЫЮеАЉдєЯе∞±жЧ†жЙАи∞УдЇЖгАВдљњзФ®exitеЗљжХ∞йЬАи¶БеМЕеРЂе§іжЦЗдїґstdlib.hпЉМиАМдљњзФ®_exitеЗљжХ∞йЬАи¶БеМЕеРЂе§іжЦЗдїґunistd.hпЉМдї•еРОињШи¶Биѓ¶зїЖиІ£йЗКињЩдЄ§дЄ™еЗљжХ∞гАВ
3.¬†еПШйЗПзЪДе≠ШеВ®еЄГе±А
й¶ЦеЕИзЬЛдЄЛйЭҐзЪДдЊЛе≠РпЉЪ
дЊЛ¬†19.2.¬†з†Фз©ґеПШйЗПзЪДе≠ШеВ®еЄГе±А
#include <stdio.h>
const int A = 10;
int a = 20;
static int b = 30;
int c;
int main(void)
{
static int a = 40;
char b[] = "Hello world";
register int c = 50;
printf("Hello world %d
", c);
return 0;
}
жИСдїђеЬ®еЕ®е±АдљЬзФ®еЯЯеТМmainеЗљжХ∞зЪДе±АйГ®дљЬзФ®еЯЯеРДеЃЪдєЙдЇЖдЄАдЇЫеПШйЗПпЉМеєґдЄФеЉХеЕ•дЄАдЇЫжЦ∞зЪДеЕ≥йФЃе≠ЧconstгАБstaticгАБregisterжЭ•дњЃй•∞еПШйЗПпЉМйВ£дєИињЩдЇЫеПШйЗПзЪДе≠ШеВ®з©ЇйЧіжШѓжАОдєИеИЖйЕНзЪДеСҐпЉЯжИСдїђзЉЦиѓСдєЛеРОзФ®readelfеСљдї§зЬЛеЃГзЪДзђ¶еПЈи°®пЉМдЇЖиІ£еРДеПШйЗПзЪДеЬ∞еЭАеИЖеЄГгАВж≥®жДПеЬ®дЄЛйЭҐзЪДжЄЕеНХдЄ≠жИСжККзђ¶еПЈи°®жМЙеЬ∞еЭАдїОдљОеИ∞йЂШзЪДй°ЇеЇПйЗНжЦ∞жОТеИЧдЇЖпЉМеєґдЄФеП™жИ™еПЦжИСдїђеЕ≥ењГзЪДйВ£еЗ†и°МгАВ
$ gcc main.c -g
$ readelf -a a.out
...
68: 08048540 4 OBJECT GLOBAL DEFAULT 15 A
69: 0804a018 4 OBJECT GLOBAL DEFAULT 23 a
52: 0804a01c 4 OBJECT LOCAL DEFAULT 23 b
53: 0804a020 4 OBJECT LOCAL DEFAULT 23 a.1589
81: 0804a02c 4 OBJECT GLOBAL DEFAULT 24 c
...
еПШйЗПAзФ®constдњЃй•∞пЉМи°®з§ЇAжШѓеП™иѓїзЪДпЉМдЄНеПѓдњЃжФєпЉМеЃГ襀еИЖйЕНзЪДеЬ∞еЭАжШѓ0x8048540пЉМдїОreadelfзЪДиЊУеЗЇеПѓдї•зЬЛеИ∞ињЩдЄ™еЬ∞еЭАдљНдЇО.rodataжЃµпЉЪ
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
...
[13] .text PROGBITS 08048360 000360 0001bc 00 AX 0 0 16
...
[15] .rodata PROGBITS 08048538 000538 00001c 00 A 0 0 4
...
[23] .data PROGBITS 0804a010 001010 000014 00 WA 0 0 4
[24] .bss NOBITS 0804a024 001024 00000c 00 WA 0 0 4
...
еЃГеЬ®жЦЗдїґдЄ≠зЪДеЬ∞еЭАжШѓ0x538~0x554пЉМжИСдїђзФ®hexdumpеСљдї§зЬЛзЬЛињЩдЄ™жЃµзЪДеЖЕеЃєпЉЪ
$ hexdump -C a.out
...
00000530 5c fe ff ff 59 5b c9 c3 03 00 00 00 01 00 02 00 |...Y[..........|
00000540 0a 00 00 00 48 65 6c 6c 6f 20 77 6f 72 6c 64 20 |....Hello world |
00000550 25 64 0a 00 00 00 00 00 00 00 00 00 00 00 00 00 |%d..............|
...
еЕґдЄ≠0x540еЬ∞еЭАе§ДзЪД0a 00 00 00е∞±жШѓеПШйЗПAгАВжИСдїђињШзЬЛеИ∞з®ЛеЇПдЄ≠зЪДе≠Чзђ¶дЄ≤е≠ЧйЭҐеАЉ"Hello world %d
"еИЖйЕНеЬ®.rodataжЃµзЪДжЬЂе∞ЊпЉМеЬ®зђђ¬†4¬†иКВ вАЬе≠Чзђ¶дЄ≤вАЭиѓіињЗе≠Чзђ¶дЄ≤е≠ЧйЭҐеАЉжШѓеП™иѓїзЪДпЉМзЫЄељУдЇОеЬ®еЕ®е±АдљЬзФ®еЯЯеЃЪдєЙдЇЖдЄАдЄ™constжХ∞зїДпЉЪ
const char helloworld[] = {"H", "e", "l", "l", "o", " ",
"w", "o", "r", "l", "d", " ", "%", "d", "
", "�"};
з®ЛеЇПеК†иљљињРи°МжЧґпЉМ.rodataжЃµеТМ.textжЃµйАЪеЄЄеРИеєґеИ∞дЄАдЄ™SegmentдЄ≠пЉМжУНдљЬз≥їзїЯе∞ЖињЩдЄ™SegmentзЪДй°µйЭҐеП™иѓїдњЭжК§иµЈжЭ•пЉМйШ≤ж≠ҐжДПе§ЦзЪДжФєеЖЩгАВињЩдЄАзВєдїОreadelfзЪДиЊУеЗЇдєЯеПѓдї•зЬЛеЗЇжЭ•пЉЪ
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .hash .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rel.dyn .rel.plt .init .plt .text .fini .rodata .eh_frame
03 .ctors .dtors .jcr .dynamic .got .got.plt .data .bss
04 .dynamic
05 .note.ABI-tag
06
07 .ctors .dtors .jcr .dynamic .got
ж≥®жДПпЉМеГПAињЩзІНconstеПШйЗПеЬ®еЃЪдєЙжЧґењЕй°їеИЭеІЛеМЦгАВеЫ†дЄЇеП™жЬЙеИЭеІЛеМЦжЧґжЙНжЬЙжЬЇдЉЪзїЩеЃГдЄАдЄ™еАЉпЉМдЄАжЧ¶еЃЪдєЙдєЛеРОе∞±дЄНиГљеЖНжФєеЖЩдЇЖпЉМдєЯе∞±жШѓдЄНиГљеЖНиµЛеАЉдЇЖгАВ
дїОдЄКйЭҐreadelfзЪДиЊУеЗЇеПѓдї•зЬЛеИ∞.dataжЃµдїОеЬ∞еЭА0x804a010еЉАеІЛпЉМйХњеЇ¶жШѓ0x14пЉМдєЯе∞±жШѓеИ∞еЬ∞еЭА0x804a024зїУжЭЯгАВеЬ®.dataжЃµдЄ≠жЬЙдЄЙдЄ™еПШйЗПпЉМaпЉМbеТМa.1589гАВ
aжШѓдЄАдЄ™GLOBALзЪДзђ¶еПЈпЉМиАМb襀staticеЕ≥йФЃе≠ЧдњЃй•∞дЇЖпЉМеѓЉиЗіеЃГжИРдЄЇдЄАдЄ™LOCALзЪДзђ¶еПЈпЉМжЙАдї•staticеЬ®ињЩйЗМзЪДдљЬзФ®жШѓе£∞жШОbињЩдЄ™зђ¶еПЈдЄЇLOCALзЪДпЉМдЄН襀йУЊжО•еЩ®е§ДзРЖпЉМеЬ®дЄЛдЄАзЂ†жИСдїђдЉЪзЬЛеИ∞пЉМе¶ВжЮЬжККе§ЪдЄ™зЫЃж†ЗжЦЗдїґйУЊжО•еЬ®дЄАиµЈпЉМLOCALзЪДзђ¶еПЈеП™иГљеЬ®жЯРдЄАдЄ™зЫЃж†ЗжЦЗдїґдЄ≠еЃЪдєЙеТМдљњзФ®пЉМиАМдЄНиГљеЃЪдєЙеЬ®дЄАдЄ™зЫЃж†ЗжЦЗдїґдЄ≠еНіеЬ®еП¶дЄАдЄ™зЫЃж†ЗжЦЗдїґдЄ≠дљњзФ®гАВдЄАдЄ™еЗљжХ∞еЃЪдєЙеЙНйЭҐдєЯеПѓдї•зФ®staticдњЃй•∞пЉМи°®з§ЇињЩдЄ™еЗљжХ∞еРНзђ¶еПЈжШѓLOCALзЪДгАВ
ињШжЬЙдЄАдЄ™a.1589жШѓдїАдєИеСҐпЉЯеЃГе∞±жШѓmainеЗљжХ∞дЄ≠зЪДstatic int aгАВеЗљжХ∞дЄ≠зЪДstaticеПШйЗПдЄНеРМдЇОдї•еЙНжИСдїђиЃ≤зЪДе±АйГ®еПШйЗПпЉМеЃГеєґдЄНжШѓеЬ®и∞ГзФ®еЗљжХ∞жЧґеИЖйЕНпЉМеЬ®еЗљжХ∞ињФеЫЮжЧґйЗКжФЊпЉМиАМжШѓеГПеЕ®е±АеПШйЗПдЄАж†ЈйЭЩжАБеИЖйЕНпЉМжЙАдї•зФ®вАЬstaticвАЭпЉИйЭЩжАБпЉЙињЩдЄ™иѓНгАВеП¶дЄАжЦєйЭҐпЉМеЗљжХ∞дЄ≠зЪДstaticеПШйЗПзЪДдљЬзФ®еЯЯеТМдї•еЙНиЃ≤зЪДе±АйГ®еПШйЗПдЄАж†ЈпЉМеП™еЬ®еЗљжХ∞дЄ≠иµЈдљЬзФ®пЉМжѓФе¶ВmainеЗљжХ∞дЄ≠зЪДaињЩдЄ™еПШйЗПеРНеП™еЬ®mainеЗљжХ∞дЄ≠иµЈдљЬзФ®пЉМеЬ®еИЂзЪДеЗљжХ∞дЄ≠иѓіеПШйЗПaе∞±дЄНжШѓжМЗеЃГдЇЖпЉМжЙАдї•зЉЦиѓСеЩ®зїЩеЃГзЪДзђ¶еПЈеРНеК†дЇЖдЄАдЄ™еРОзЉАпЉМеПШжИРa.1589пЉМдї•дЊњеТМеЕ®е±АеПШйЗПaдї•еПКеЕґеЃГеЗљжХ∞зЪДеПШйЗПaеМЇеИЖеЉАгАВ
.bssжЃµдїОеЬ∞еЭА0x804a024еЉАеІЛпЉИзіІжМ®зЭА.dataжЃµпЉЙпЉМйХњеЇ¶дЄЇ0xcпЉМдєЯе∞±жШѓеИ∞еЬ∞еЭА0x804a030зїУжЭЯгАВеПШйЗПcдљНдЇОињЩдЄ™жЃµгАВдїОдЄКйЭҐзЪДreadelfиЊУеЗЇеПѓдї•зЬЛеИ∞пЉМ.dataеТМ.bssеЬ®еК†иљљжЧґеРИеєґеИ∞дЄАдЄ™SegmentдЄ≠пЉМињЩдЄ™SegmentжШѓеПѓиѓїеПѓеЖЩзЪДгАВ.bssжЃµеТМ.dataжЃµзЪДдЄНеРМдєЛе§ДеЬ®дЇОпЉМ.bssжЃµеЬ®жЦЗдїґдЄ≠дЄНеН†е≠ШеВ®з©ЇйЧіпЉМеЬ®еК†иљљжЧґињЩдЄ™жЃµзФ®0е°ЂеЕЕгАВжЙАдї•жИСдїђеЬ®зђђ¬†4¬†иКВ вАЬеЕ®е±АеПШйЗПгАБе±АйГ®еПШйЗПеТМдљЬзФ®еЯЯвАЭиЃ≤ињЗпЉМеЕ®е±АеПШйЗПе¶ВжЮЬдЄНеИЭеІЛеМЦеИЩеИЭеАЉдЄЇ0пЉМеРМзРЖеПѓдї•жО®жЦ≠пЉМstaticеПШйЗПпЉИдЄНзЃ°жШѓеЗљжХ∞йЗМзЪДињШжШѓеЗљжХ∞е§ЦзЪДпЉЙе¶ВжЮЬдЄНеИЭеІЛеМЦеИЩеИЭеАЉдєЯжШѓ0пЉМдєЯеИЖйЕНеЬ®.bssжЃµгАВ
зО∞еЬ®ињШеЙ©дЄЛеЗљжХ∞дЄ≠зЪДbеТМcињЩдЄ§дЄ™еПШйЗПж≤°жЬЙеИЖжЮРгАВдЄКдЄАиКВжИСдїђиЃ≤ињЗеЗљжХ∞зЪДеПВжХ∞еТМе±АйГ®еПШйЗПжШѓеИЖйЕНеЬ®ж†ИдЄКзЪДпЉМbжШѓжХ∞зїДдєЯдЄАж†ЈпЉМдєЯжШѓеИЖйЕНеЬ®ж†ИдЄКзЪДпЉМжИСдїђзЬЛmainеЗљжХ∞зЪДеПНж±ЗзЉЦдї£з†БпЉЪ
$ objdump -dS a.out
...
char b[]="Hello world";
8048430: c7 45 ec 48 65 6c 6c movl $0x6c6c6548,-0x14(%ebp)
8048437: c7 45 f0 6f 20 77 6f movl $0x6f77206f,-0x10(%ebp)
804843e: c7 45 f4 72 6c 64 00 movl $0x646c72,-0xc(%ebp)
register int c = 50;
8048445: b8 32 00 00 00 mov $0x32,%eax
printf("Hello world %d
", c);
804844a: 89 44 24 04 mov %eax,0x4(%esp)
804844e: c7 04 24 44 85 04 08 movl $0x8048544,(%esp)
8048455: e8 e6 fe ff ff call 8048340 <printf@plt>
...
еПѓиІБпЉМзїЩbеИЭеІЛеМЦзФ®зЪДињЩдЄ™е≠Чзђ¶дЄ≤"Hello world"еєґж≤°жЬЙеИЖйЕНеЬ®.rodataжЃµпЉМиАМжШѓзЫіжО•еЖЩеЬ®жМЗдї§йЗМдЇЖпЉМйАЪињЗдЄЙжЭ°movlжМЗдї§жКК12дЄ™е≠ЧиКВеЖЩеИ∞ж†ИдЄКпЉМињЩе∞±жШѓbзЪДе≠ШеВ®з©ЇйЧіпЉМе¶ВдЄЛеЫЊжЙАз§ЇгАВ
еЫЊ¬†19.4.¬†жХ∞зїДзЪДе≠ШеВ®еЄГе±А
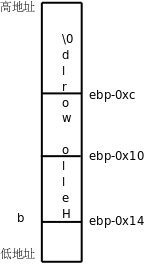
ж≥®жДПпЉМиЩљзДґж†ИжШѓдїОйЂШеЬ∞еЭАеРСдљОеЬ∞еЭАеҐЮйХњзЪДпЉМдљЖжХ∞зїДжАїжШѓдїОдљОеЬ∞еЭАеРСйЂШеЬ∞еЭАжОТеИЧзЪДпЉМжМЙдїОдљОеЬ∞еЭАеИ∞йЂШеЬ∞еЭАзЪДй°ЇеЇПдЊЭжђ°жШѓb[0]гАБb[1]гАБb[2]вА¶вА¶ињЩж†ЈпЉМ
жХ∞зїДеЕГзі†b[n]зЪДеЬ∞еЭА¬†=¬†жХ∞зїДзЪДеЯЇеЬ∞еЭАпЉИbеБЪеП≥еАЉе∞±и°®з§ЇињЩдЄ™еЯЇеЬ∞еЭАпЉЙ¬†+¬†n¬†√Ч¬†жѓПдЄ™еЕГзі†зЪДе≠ЧиКВжХ∞
ељУn=0жЧґпЉМеЕГзі†b[0]зЪДеЬ∞еЭАе∞±жШѓжХ∞зїДзЪДеЯЇеЬ∞еЭАпЉМеЫ†ж≠§жХ∞зїДдЄЛж†Зи¶БдїО0еЉАеІЛиАМдЄНжШѓдїО1еЉАеІЛгАВ
еПШйЗПcеєґж≤°жЬЙеЬ®ж†ИдЄКеИЖйЕНе≠ШеВ®з©ЇйЧіпЉМиАМжШѓзЫіжО•е≠ШеЬ®eaxеѓДе≠ШеЩ®йЗМпЉМеРОйЭҐи∞ГзФ®printfдєЯжШѓзЫіжО•дїОeaxеѓДе≠ШеЩ®йЗМеПЦеЗЇcзЪДеАЉељУеПВжХ∞еОЛж†ИпЉМињЩе∞±жШѓregisterеЕ≥йФЃе≠ЧзЪДдљЬзФ®пЉМжМЗз§ЇзЉЦиѓСеЩ®е∞љеПѓиГљеИЖйЕНдЄАдЄ™еѓДе≠ШеЩ®жЭ•е≠ШеВ®ињЩдЄ™еПШйЗПгАВжИСдїђињШзЬЛеИ∞и∞ГзФ®printfжЧґеѓєдЇО"Hello world %d
"ињЩдЄ™еПВжХ∞еОЛж†ИзЪДжШѓеЃГеЬ®.rodataжЃµдЄ≠зЪДй¶ЦеЬ∞еЭАпЉМиАМдЄНжШѓжККжХідЄ™е≠Чзђ¶дЄ≤еОЛж†ИпЉМжЙАдї•еЬ®зђђ¬†4¬†иКВ вАЬе≠Чзђ¶дЄ≤вАЭдЄ≠иѓіињЗпЉМе≠Чзђ¶дЄ≤еЬ®дљњзФ®жЧґеПѓдї•зЬЛдљЬжХ∞зїДеРНпЉМе¶ВжЮЬеБЪеП≥еАЉеИЩи°®з§ЇжХ∞зїДй¶ЦеЕГзі†зЪДеЬ∞еЭАпЉИжИЦиАЕиѓіжМЗеРСжХ∞зїДй¶ЦеЕГзі†зЪДжМЗйТИпЉЙпЉМжИСдїђдї•еРОиЃ≤жМЗйТИињШи¶БзїІзї≠иЃ®иЃЇињЩдЄ™йЧЃйҐШгАВ
дї•еЙНжИСдїђзФ®вАЬеЕ®е±АеПШйЗПвАЭеТМвАЬе±АйГ®еПШйЗПвАЭињЩдЄ§дЄ™ж¶ВењµпЉМдЄїи¶БжШѓдїОдљЬзФ®еЯЯдЄКеМЇеИЖзЪДпЉМзО∞еЬ®зЬЛжЭ•зФ®ињЩдЄ§дЄ™ж¶ВењµзїЩеПШйЗПеИЖ籿姙琊зїЯдЇЖпЉМйЬАи¶БињЫдЄАж≠•зїЖеИЖгАВжИСдїђжАїзїУдЄАдЄЛзЫЄеЕ≥зЪДCиѓ≠ж≥ХгАВ
дљЬзФ®еЯЯпЉИScopeпЉЙињЩдЄ™ж¶ВењµйАВзФ®дЇОжЙАжЬЙж†ЗиѓЖзђ¶пЉМиАМдЄНдїЕдїЕжШѓеПШйЗПпЉМCиѓ≠и®АзЪДдљЬзФ®еЯЯеИЖдЄЇдї•дЄЛеЗ†з±їпЉЪ
еЗљжХ∞дљЬзФ®еЯЯпЉИFunction ScopeпЉЙпЉМж†ЗиѓЖзђ¶еЬ®жХідЄ™еЗљжХ∞дЄ≠йГљжЬЙжХИгАВеП™жЬЙиѓ≠еП•ж†ЗеПЈе±ЮдЇОеЗљжХ∞дљЬзФ®еЯЯгАВж†ЗеПЈеЬ®еЗљжХ∞дЄ≠дЄНйЬАи¶БеЕИе£∞жШОеРОдљњзФ®пЉМеЬ®еЙНйЭҐзФ®дЄАдЄ™
gotoиѓ≠еП•дєЯеПѓдї•иЈ≥иљђеИ∞еРОйЭҐзЪДжЯРдЄ™ж†ЗеПЈпЉМдљЖдїЕйЩРдЇОеРМдЄАдЄ™еЗљжХ∞дєЛдЄ≠гАВжЦЗдїґдљЬзФ®еЯЯпЉИFile ScopeпЉЙпЉМж†ЗиѓЖзђ¶дїОеЃГе£∞жШОзЪДдљНзљЃеЉАеІЛзЫіеИ∞ињЩдЄ™з®ЛеЇПжЦЗдїґ[[30](#ftn.id2778429)]зЪДжЬЂе∞ЊйГљжЬЙжХИгАВдЊЛе¶ВдЄКдЊЛдЄ≠
mainеЗљжХ∞е§ЦйЭҐзЪДAгАБaгАБbгАБcпЉМињШжЬЙmainдєЯзЃЧпЉМprintfеЕґеЃЮжШѓеЬ®stdio.hдЄ≠е£∞жШОзЪДпЉМ襀еМЕеРЂеИ∞ињЩдЄ™з®ЛеЇПжЦЗдїґдЄ≠дЇЖпЉМжЙАдї•дєЯзЃЧжЦЗдїґдљЬзФ®еЯЯзЪДгАВеЭЧдљЬзФ®еЯЯпЉИBlock ScopeпЉЙпЉМж†ЗиѓЖзђ¶дљНдЇОдЄАеѓє{}жЛђеПЈдЄ≠пЉИеЗљжХ∞дљУжИЦиѓ≠еП•еЭЧпЉЙпЉМдїОеЃГе£∞жШОзЪДдљНзљЃеЉАеІЛеИ∞еП≥}жЛђеПЈдєЛйЧіжЬЙжХИгАВдЊЛе¶ВдЄКдЊЛдЄ≠
mainеЗљжХ∞йЗМзЪДaгАБbгАБcгАВж≠§е§ЦпЉМеЗљжХ∞еЃЪдєЙдЄ≠зЪД嚥еПВдєЯзЃЧеЭЧдљЬзФ®еЯЯзЪДпЉМдїОе£∞жШОзЪДдљНзљЃеЉАеІЛеИ∞еЗљжХ∞жЬЂе∞ЊдєЛйЧіжЬЙжХИгАВеЗљжХ∞еОЯеЮЛдљЬзФ®еЯЯпЉИFunction Prototype ScopeпЉЙпЉМж†ЗиѓЖзђ¶еЗЇзО∞еЬ®еЗљжХ∞еОЯеЮЛдЄ≠пЉМињЩдЄ™еЗљжХ∞еОЯеЮЛеП™жШѓдЄАдЄ™е£∞жШОиАМдЄНжШѓеЃЪдєЙпЉИж≤°жЬЙеЗљжХ∞дљУпЉЙпЉМйВ£дєИж†ЗиѓЖзђ¶дїОе£∞жШОзЪДдљНзљЃеЉАеІЛеИ∞еЬ®ињЩдЄ™еОЯеЮЛжЬЂе∞ЊдєЛйЧіжЬЙжХИгАВдЊЛе¶В
int foo(int a, int b);дЄ≠зЪДaеТМbгАВ
еѓєе±ЮдЇОеРМдЄАеСљеРНз©ЇйЧіпЉИName SpaceпЉЙзЪДйЗНеРНж†ЗиѓЖзђ¶пЉМеЖЕе±ВдљЬзФ®еЯЯзЪДж†ЗиѓЖзђ¶е∞Жи¶ЖзЫЦе§Це±ВдљЬзФ®еЯЯзЪДж†ЗиѓЖзђ¶пЉМдЊЛе¶Ве±АйГ®еПШйЗПеРНеЬ®еЃГзЪДеЗљжХ∞дЄ≠е∞Жи¶ЖзЫЦйЗНеРНзЪДеЕ®е±АеПШйЗПгАВеСљеРНз©ЇйЧіеПѓеИЖдЄЇдї•дЄЛеЗ†з±їпЉЪ
иѓ≠еП•ж†ЗеПЈеНХзЛђе±ЮдЇОдЄАдЄ™еСљеРНз©ЇйЧігАВдЊЛе¶ВеЬ®еЗљжХ∞дЄ≠е±АйГ®еПШйЗПеТМиѓ≠еП•ж†ЗеПЈеПѓдї•йЗНеРНпЉМдЇТдЄНељ±еУНгАВзФ±дЇОдљњзФ®ж†ЗеПЈзЪДиѓ≠ж≥ХеТМдљњзФ®еЕґеЃГж†ЗиѓЖзђ¶зЪДиѓ≠ж≥ХйГљдЄНдЄАж†ЈпЉМзЉЦиѓСеЩ®дЄНдЉЪжККеЃГеТМеИЂзЪДж†ЗиѓЖзђ¶еЉДжЈЈгАВ
structпЉМenumеТМunionпЉИдЄЛдЄАиКВдїЛзїНunionпЉЙзЪДз±їеЮЛTagе±ЮдЇОдЄАдЄ™еСљеРНз©ЇйЧігАВзФ±дЇОTagеЙНйЭҐжАїжШѓеЄ¶structпЉМenumжИЦunionеЕ≥йФЃе≠ЧпЉМжЙАдї•зЉЦиѓСеЩ®дЄНдЉЪжККеЃГеТМеИЂзЪДж†ЗиѓЖзђ¶еЉДжЈЈгАВstructеТМunionзЪДжИРеСШеРНе±ЮдЇОдЄАдЄ™еСљеРНз©ЇйЧігАВзФ±дЇОжИРеСШеРНжАїжШѓйАЪињЗ.жИЦ->ињРзЃЧзђ¶жЭ•иЃњйЧЃиАМдЄНдЉЪеНХзЛђдљњзФ®пЉМжЙАдї•зЉЦиѓСеЩ®дЄНдЉЪжККеЃГеТМеИЂзЪДж†ЗиѓЖзђ¶еЉДжЈЈгАВжЙАжЬЙеЕґеЃГж†ЗиѓЖзђ¶пЉМдЊЛе¶ВеПШйЗПеРНгАБеЗљжХ∞еРНгАБеЃПеЃЪдєЙгАБ
typedefзЪДз±їеЮЛеРНгАБenumжИРеСШз≠Йз≠ЙйГље±ЮдЇОеРМдЄАдЄ™еСљеРНз©ЇйЧігАВе¶ВжЮЬжЬЙйЗНеРНзЪДиѓЭпЉМеЃПеЃЪдєЙи¶ЖзЫЦжЙАжЬЙеЕґеЃГж†ЗиѓЖзђ¶пЉМеЫ†дЄЇеЃГеЬ®йҐДе§ДзРЖйШґжЃµиАМдЄНжШѓзЉЦиѓСйШґжЃµе§ДзРЖпЉМйЩ§дЇЖеЃПеЃЪдєЙдєЛе§ЦеЕґеЃГеЗ†з±їж†ЗиѓЖзђ¶жМЙдЄКйЭҐжЙАиѓізЪДиІДеИЩе§ДзРЖпЉМеЖЕе±ВдљЬзФ®еЯЯи¶ЖзЫЦе§Це±ВдљЬзФ®еЯЯгАВ
ж†ЗиѓЖзђ¶зЪДйУЊжО•е±ЮжАІпЉИLinkageпЉЙжЬЙдЄЙзІНпЉЪ
е§ЦйГ®йУЊжО•пЉИExternal LinkageпЉЙпЉМе¶ВжЮЬжЬАзїИзЪДеПѓжЙІи°МжЦЗдїґзФ±е§ЪдЄ™з®ЛеЇПжЦЗдїґйУЊжО•иАМжИРпЉМдЄАдЄ™ж†ЗиѓЖзђ¶еЬ®дїїжДПз®ЛеЇПжЦЗдїґдЄ≠еН≥дљње£∞жШОе§Ъжђ°дєЯйГљдї£и°®еРМдЄАдЄ™еПШйЗПжИЦеЗљжХ∞пЉМеИЩињЩдЄ™ж†ЗиѓЖзђ¶еЕЈжЬЙExternal LinkageгАВеЕЈжЬЙExternal LinkageзЪДж†ЗиѓЖзђ¶зЉЦиѓСеРОеЬ®зђ¶еПЈи°®дЄ≠жШѓ
GLOBALзЪДзђ¶еПЈгАВдЊЛе¶ВдЄКдЊЛдЄ≠mainеЗљжХ∞е§ЦйЭҐзЪДaеТМcпЉМmainеТМprintfдєЯзЃЧгАВеЖЕйГ®йУЊжО•пЉИInternal LinkageпЉЙпЉМе¶ВжЮЬдЄАдЄ™ж†ЗиѓЖзђ¶еЬ®жЯРдЄ™з®ЛеЇПжЦЗдїґдЄ≠еН≥дљње£∞жШОе§Ъжђ°дєЯйГљдї£и°®еРМдЄАдЄ™еПШйЗПжИЦеЗљжХ∞пЉМеИЩињЩдЄ™ж†ЗиѓЖзђ¶еЕЈжЬЙInternal LinkageгАВдЊЛе¶ВдЄКдЊЛдЄ≠
mainеЗљжХ∞е§ЦйЭҐзЪДbгАВе¶ВжЮЬжЬЙеП¶дЄАдЄ™foo.cз®ЛеЇПеТМmain.cйУЊжО•еЬ®дЄАиµЈпЉМеЬ®foo.cдЄ≠дєЯе£∞жШОдЄАдЄ™static int b;пЉМеИЩйВ£дЄ™bеТМињЩдЄ™bдЄНдї£и°®еРМдЄАдЄ™еПШйЗПгАВеЕЈжЬЙInternal LinkageзЪДж†ЗиѓЖзђ¶зЉЦиѓСеРОеЬ®зђ¶еПЈи°®дЄ≠жШѓLOCALзЪДзђ¶еПЈпЉМдљЖmainеЗљжХ∞йЗМйЭҐйВ£дЄ™aдЄНиГљзЃЧInternal LinkageзЪДпЉМеЫ†дЄЇеН≥дљњеЬ®еРМдЄАдЄ™з®ЛеЇПжЦЗдїґдЄ≠пЉМеЬ®дЄНеРМзЪДеЗљжХ∞дЄ≠е£∞жШОе§Ъжђ°пЉМдєЯдЄНдї£и°®еРМдЄАдЄ™еПШйЗПгАВжЧ†йУЊжО•пЉИNo LinkageпЉЙгАВйЩ§дї•дЄКжГЕеЖµдєЛе§ЦзЪДж†ЗиѓЖзђ¶йГље±ЮдЇОNo LinkageзЪДпЉМдЊЛе¶ВеЗљжХ∞зЪДе±АйГ®еПШйЗПпЉМдї•еПКдЄНи°®з§ЇеПШйЗПеТМеЗљжХ∞зЪДеЕґеЃГж†ЗиѓЖзђ¶гАВ
е≠ШеВ®з±їдњЃй•∞зђ¶пЉИStorage Class SpecifierпЉЙжЬЙдї•дЄЛеЗ†зІНеЕ≥йФЃе≠ЧпЉМеПѓдї•дњЃй•∞еПШйЗПжИЦеЗљжХ∞е£∞жШОпЉЪ
staticпЉМзФ®еЃГдњЃй•∞зЪДеПШйЗПзЪДе≠ШеВ®з©ЇйЧіжШѓйЭЩжАБеИЖйЕНзЪДпЉМзФ®еЃГдњЃй•∞зЪДжЦЗдїґдљЬзФ®еЯЯзЪДеПШйЗПжИЦеЗљжХ∞еЕЈжЬЙInternal LinkageгАВautoпЉМзФ®еЃГдњЃй•∞зЪДеПШйЗПеЬ®еЗљжХ∞и∞ГзФ®жЧґиЗ™еК®еЬ®ж†ИдЄКеИЖйЕНе≠ШеВ®з©ЇйЧіпЉМеЗљжХ∞ињФеЫЮжЧґиЗ™еК®йЗКжФЊпЉМдЊЛе¶ВдЄКдЊЛдЄ≠mainеЗљжХ∞йЗМзЪДbеЕґеЃЮе∞±жШѓзФ®autoдњЃй•∞зЪДпЉМеП™дЄНињЗautoеПѓдї•зЬБзХ•дЄНеЖЩпЉМautoдЄНиГљдњЃй•∞жЦЗдїґдљЬзФ®еЯЯзЪДеПШйЗПгАВregisterпЉМзЉЦиѓСеЩ®еѓєдЇОзФ®registerдњЃй•∞зЪДеПШйЗПдЉЪе∞љеПѓиГљеИЖйЕНдЄАдЄ™дЄУйЧ®зЪДеѓДе≠ШеЩ®жЭ•е≠ШеВ®пЉМдљЖе¶ВжЮЬеЃЮеЬ®еИЖйЕНдЄНеЉАеѓДе≠ШеЩ®пЉМзЉЦиѓСеЩ®е∞±жККеЃГељУautoеПШйЗПе§ДзРЖдЇЖпЉМregisterдЄНиГљдњЃй•∞жЦЗдїґдљЬзФ®еЯЯзЪДеПШйЗПгАВзО∞еЬ®дЄАиИђзЉЦиѓСеЩ®зЪДдЉШеМЦйГљеБЪеЊЧеЊИе•љдЇЖпЉМеЃГиЗ™еЈ±дЉЪжГ≥еКЮж≥ХжЬЙжХИеЬ∞еИ©зФ®CPUзЪДеѓДе≠ШеЩ®пЉМжЙАдї•зО∞еЬ®registerеЕ≥йФЃе≠ЧдєЯзФ®еЊЧжѓФиЊГе∞СдЇЖгАВexternпЉМдЄКйЭҐиЃ≤ињЗпЉМйУЊжО•е±ЮжАІжШѓж†єжНЃдЄАдЄ™ж†ЗиѓЖзђ¶е§Ъжђ°е£∞жШОжЧґжШѓдЄНжШѓдї£и°®еРМдЄАдЄ™еПШйЗПжИЦеЗљжХ∞жЭ•еИЖз±їзЪДпЉМexternеЕ≥йФЃе≠Че∞±зФ®дЇОе§Ъжђ°е£∞жШОеРМдЄАдЄ™ж†ЗиѓЖзђ¶пЉМдЄЛдЄАзЂ†еЖНиѓ¶зїЖдїЛзїНеЃГзЪДзФ®ж≥ХгАВtypedefпЉМеЬ®зђђ¬†2.4¬†иКВ вАЬsizeofињРзЃЧзђ¶дЄОtypedefз±їеЮЛе£∞жШОвАЭиЃ≤ињЗињЩдЄ™еЕ≥йФЃе≠ЧпЉМеЃГеєґдЄНжШѓзФ®жЭ•дњЃй•∞еПШйЗПзЪДпЉМиАМжШѓеЃЪдєЙдЄАдЄ™з±їеЮЛеРНгАВеЬ®йВ£дЄАиКВдєЯиЃ≤ињЗпЉМзЬЛtypedefе£∞жШОжАОдєИзЬЛеСҐпЉМй¶ЦеЕИеОїжОЙtypedefжККеЃГзЬЛжИРеПШйЗПе£∞жШОпЉМзЬЛињЩдЄ™еПШйЗПжШѓдїАдєИз±їеЮЛзЪДпЉМйВ£дєИtypedefе∞±еЃЪдєЙдЇЖдЄАдЄ™дїАдєИз±їеЮЛпЉМдєЯе∞±жШѓиѓіпЉМtypedefеЬ®иѓ≠ж≥ХзїУжЮДдЄ≠еЗЇзО∞зЪДдљНзљЃеТМеЙНйЭҐеЗ†дЄ™еЕ≥йФЃе≠ЧдЄАж†ЈпЉМдєЯжШѓдњЃй•∞еПШйЗПе£∞жШОзЪДпЉМжЙАдї•дїОиѓ≠ж≥ХпЉИиАМдЄНжШѓиѓ≠дєЙпЉЙзЪДиІТеЇ¶жККеЃГеТМеЙНйЭҐеЗ†дЄ™еЕ≥йФЃе≠ЧељТз±їеИ∞дЄАиµЈгАВ
ж≥®жДПпЉМдЄКйЭҐдїЛзїНзЪДconstеЕ≥йФЃе≠ЧдЄНжШѓдЄАдЄ™Storage Class SpecifierпЉМиЩљзДґзЬЛиµЈжЭ•еЃГдєЯдњЃй•∞дЄАдЄ™еПШйЗПе£∞жШОпЉМдљЖжШѓеЬ®дї•еРОдїЛзїНзЪДжЫіе§НжЭВзЪДе£∞жШОдЄ≠constеЬ®иѓ≠ж≥ХзїУжЮДдЄ≠еЕБиЃЄеЗЇзО∞зЪДдљНзљЃеТМStorage Class SpecifierжШѓдЄНеЃМеЕ®зЫЄеРМзЪДгАВconstеТМдї•еРОи¶БдїЛзїНзЪДrestrictеТМvolatileеЕ≥йФЃе≠Че±ЮдЇОеРМдЄАз±їиѓ≠ж≥ХеЕГзі†пЉМзІ∞дЄЇз±їеЮЛйЩРеЃЪзђ¶пЉИType QualifierпЉЙгАВ
еПШйЗПзЪДзФЯе≠ШжЬЯпЉИStorage DurationпЉМжИЦиАЕLifetimeпЉЙеИЖдЄЇдї•дЄЛеЗ†з±їпЉЪ
йЭЩжАБзФЯе≠ШжЬЯпЉИStatic Storage DurationпЉЙпЉМеЕЈжЬЙе§ЦйГ®жИЦеЖЕйГ®йУЊжО•е±ЮжАІпЉМжИЦиАЕ襀
staticдњЃй•∞зЪДеПШйЗПпЉМеЬ®з®ЛеЇПеЉАеІЛжЙІи°МжЧґеИЖйЕНеТМеИЭеІЛеМЦдЄАжђ°пЉМж≠§еРОдЊњдЄАзЫіе≠ШеЬ®зЫіеИ∞з®ЛеЇПзїУжЭЯгАВињЩзІНеПШйЗПйАЪеЄЄдљНдЇО.rodataпЉМ.dataжИЦ.bssжЃµпЉМдЊЛе¶ВдЄКдЊЛдЄ≠mainеЗљжХ∞е§ЦзЪДAпЉМaпЉМbпЉМcпЉМдї•еПКmainеЗљжХ∞йЗМзЪДaгАВиЗ™еК®зФЯе≠ШжЬЯпЉИAutomatic Storage DurationпЉЙпЉМйУЊжО•е±ЮжАІдЄЇжЧ†йУЊжО•еєґдЄФж≤°жЬЙ襀
staticдњЃй•∞зЪДеПШйЗПпЉМињЩзІНеПШйЗПеЬ®ињЫеЕ•еЭЧдљЬзФ®еЯЯжЧґеЬ®ж†ИдЄКжИЦеѓДе≠ШеЩ®дЄ≠еИЖйЕНпЉМеЬ®йААеЗЇеЭЧдљЬзФ®еЯЯжЧґйЗКжФЊгАВдЊЛе¶ВдЄКдЊЛдЄ≠mainеЗљжХ∞йЗМзЪДbеТМcгАВеК®жАБеИЖйЕНзФЯе≠ШжЬЯпЉИAllocated Storage DurationпЉЙпЉМдї•еРОдЉЪиЃ≤еИ∞и∞ГзФ®
mallocеЗљжХ∞еЬ®ињЫз®ЛзЪДе†Жз©ЇйЧідЄ≠еИЖйЕНеЖЕе≠ШпЉМи∞ГзФ®freeеЗљжХ∞еПѓдї•йЗКжФЊињЩзІНе≠ШеВ®з©ЇйЧігАВ- *
[[30](#id2778429)] дЄЇдЇЖеЃєжШУйШЕиѓїпЉМињЩйЗМжИСзФ®дЇЖвАЬз®ЛеЇПжЦЗдїґвАЭињЩдЄ™дЄНдЄ•ж†ЉзЪДеПЂж≥ХгАВе¶ВжЮЬжЬЙжЦЗдїґa.cеМЕеРЂдЇЖb.hеТМc.hпЉМйВ£дєИжИСжЙАиѓізЪДвАЬз®ЛеЇПжЦЗдїґвАЭжМЗзЪДжШѓзїПињЗйҐДе§ДзРЖжККb.hеТМc.hеЬ®a.cдЄ≠е±ХеЉАдєЛеРОзФЯжИРзЪДдї£з†БпЉМеЬ®Cж†ЗеЗЖдЄ≠зІ∞дЄЇзЉЦиѓСеНХеЕГпЉИTranslation UnitпЉЙгАВжѓПдЄ™зЉЦиѓСеНХеЕГеПѓдї•еИЖеИЂзЉЦиѓСжИРдЄАдЄ™.oзЫЃж†ЗжЦЗдїґпЉМжЬАеРОињЩдЇЫзЫЃж†ЗжЦЗдїґзФ®йУЊжО•еЩ®йУЊжО•еИ∞дЄАиµЈпЉМжИРдЄЇдЄАдЄ™еПѓжЙІи°МжЦЗдїґгАВCж†ЗеЗЖдЄ≠е§ІйЗПдљњзФ®дЄАдЇЫйЭЮеЄЄдЄНйАЪдњЧзЪДеРНиѓНпЉМйЩ§дЇЖзЉЦиѓСеНХеЕГдєЛе§ЦпЉМињШжЬЙзЉЦиѓСеЩ®еПЂTranslatorпЉМеПШйЗПеПЂObjectпЉМжЬђдє¶дЄНдЉЪйЗЗзФ®ињЩдЇЫеРНиѓНпЉМеЫ†дЄЇжИСдЄНжШѓеЬ®еЖЩCж†ЗеЗЖгАВ
4.¬†зїУжЮДдљУеТМиБФеРИдљУ
жИСдїђзїІзї≠зФ®еПНж±ЗзЉЦзЪДжЦєж≥Хз†Фз©ґдЄАдЄЛCиѓ≠и®АзЪДзїУжЮДдљУпЉЪ
дЊЛ¬†19.3.¬†з†Фз©ґзїУжЮДдљУ
#include <stdio.h>
int main(int argc, char** argv)
{
struct {
char a;
short b;
int c;
char d;
} s;
s.a = 1;
s.b = 2;
s.c = 3;
s.d = 4;
printf("%u
", sizeof(s));
return 0;
}
mainеЗљжХ∞дЄ≠еЗ†жЭ°иѓ≠еП•зЪДеПНж±ЗзЉЦзїУжЮЬе¶ВдЄЛпЉЪ
s.a = 1;
80483d5: c6 45 f0 01 movb $0x1,-0x10(%ebp)
s.b = 2;
80483d9: 66 c7 45 f2 02 00 movw $0x2,-0xe(%ebp)
s.c = 3;
80483df: c7 45 f4 03 00 00 00 movl $0x3,-0xc(%ebp)
s.d = 4;
80483e6: c6 45 f8 04 movb $0x4,-0x8(%ebp)
дїОиЃњйЧЃзїУжЮДдљУжИРеСШзЪДжМЗдї§еПѓдї•зЬЛеЗЇпЉМзїУжЮДдљУзЪДеЫЫдЄ™жИРеСШеЬ®ж†ИдЄКжШѓињЩж†ЈжОТеИЧзЪДпЉЪ
еЫЊ¬†19.5.¬†зїУжЮДдљУзЪДе≠ШеВ®еЄГе±А
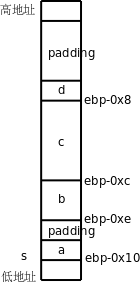
иЩљзДґж†ИжШѓдїОйЂШеЬ∞еЭАеРСдљОеЬ∞еЭАеҐЮйХњзЪДпЉМдљЖзїУжЮДдљУжИРеСШдєЯжШѓдїОдљОеЬ∞еЭАеРСйЂШеЬ∞еЭАжОТеИЧзЪДпЉМињЩдЄАзВєеТМжХ∞зїДз±їдЉЉгАВдљЖжЬЙдЄАзВєеТМжХ∞зїДдЄНеРМпЉМзїУжЮДдљУзЪДеРДжИРеСШеєґдЄНжШѓдЄАдЄ™зіІжМ®дЄАдЄ™жОТеИЧзЪДпЉМдЄ≠йЧіжЬЙз©ЇйЪЩпЉМзІ∞дЄЇе°ЂеЕЕпЉИPaddingпЉЙпЉМдЄНдїЕе¶Вж≠§пЉМеЬ®ињЩдЄ™зїУжЮДдљУзЪДжЬЂе∞ЊдєЯжЬЙдЄЙдЄ™е≠ЧиКВзЪДе°ЂеЕЕпЉМжЙАдї•sizeof(s)зЪДеАЉжШѓ12гАВж≥®жДПпЉМprintfзЪД%uиљђжНҐиѓіжШОи°®з§ЇжЧ†зђ¶еПЈжХ∞пЉМsizeofзЪДеАЉжШѓsize_tз±їеЮЛзЪДпЉМжШѓжЯРзІНжЧ†зђ¶еПЈжХіеЮЛгАВ
дЄЇдїАдєИзЉЦиѓСеЩ®и¶БињЩж†Је§ДзРЖеСҐпЉЯжЬЙдЄАдЄ™зЯ•иѓЖзВєжИСж≠§еЙНдЄАзЫіеЫЮйБњж≤°иЃ≤пЉМйВ£е∞±жШѓе§Іе§ЪжХ∞иЃ°зЃЧжЬЇдљУз≥їзїЯзїУжЮДеѓєдЇОиЃњйЧЃеЖЕе≠ШзЪДжМЗдї§жШѓжЬЙйЩРеИґзЪДпЉМеЬ®32дљНеє≥еП∞дЄКпЉМиЃњйЧЃ4е≠ЧиКВзЪДжМЗдї§пЉИжѓФе¶ВдЄКйЭҐзЪДmovlпЉЙжЙАиЃњйЧЃзЪДеЖЕе≠ШеЬ∞еЭАеЇФиѓ•жШѓ4зЪДжХіжХ∞еАНпЉМиЃњйЧЃдЄ§е≠ЧиКВзЪДжМЗдї§пЉИжѓФе¶ВдЄКйЭҐзЪДmovwпЉЙжЙАиЃњйЧЃзЪДеЖЕе≠ШеЬ∞еЭАеЇФиѓ•жШѓдЄ§е≠ЧиКВзЪДжХіжХ∞еАНпЉМињЩзІ∞дЄЇеѓєйљРпЉИAlignmentпЉЙгАВдї•еЙНдЄЊзЪДжЙАжЬЙдЊЛе≠РдЄ≠зЪДеЖЕе≠ШиЃњйЧЃжМЗдї§йГљжї°иґ≥ињЩдЄ™йЩРеИґжЭ°дїґпЉМиѓїиАЕеПѓдї•еЫЮе§іж£Ай™МдЄАдЄЛгАВе¶ВжЮЬжМЗдї§жЙАиЃњйЧЃзЪДеЖЕе≠ШеЬ∞еЭАж≤°жЬЙж≠£з°ЃеѓєйљРдЉЪжАОдєИж†ЈеСҐпЉЯеЬ®жЬЙдЇЫеє≥еП∞дЄКе∞ЖдЄНиГљиЃњйЧЃеЖЕе≠ШпЉМиАМжШѓеЉХеПСдЄАдЄ™еЉВеЄЄпЉМеЬ®x86еє≥еП∞дЄКеАТжШѓдїНзДґиГљиЃњйЧЃеЖЕе≠ШпЉМдљЖжШѓдЄНеѓєйљРзЪДжМЗдї§жЙІи°МжХИзОЗжѓФеѓєйљРзЪДжМЗдї§и¶БдљОпЉМжЙАдї•зЉЦиѓСеЩ®еЬ®еЃЙжОТеРДзІНеПШйЗПзЪДеЬ∞еЭАжЧґйГљдЉЪиАГиЩСеИ∞еѓєйљРзЪДйЧЃйҐШгАВеѓєдЇОжЬђдЊЛдЄ≠зЪДзїУжЮДдљУпЉМзЉЦиѓСеЩ®дЉЪжККеЃГзЪДеЯЇеЬ∞еЭАеѓєйљРеИ∞4е≠ЧиКВиЊєзХМпЉМдєЯе∞±жШѓиѓіпЉМebp-0x10ињЩдЄ™еЬ∞еЭАдЄАеЃЪжШѓ4зЪДжХіжХ∞еАНгАВs.aеН†дЄАдЄ™е≠ЧиКВпЉМж≤°жЬЙеѓєйљРзЪДйЧЃйҐШгАВs.bеН†дЄ§дЄ™е≠ЧиКВпЉМе¶ВжЮЬs.bзіІжМ®еЬ®s.aеРОйЭҐпЉМеЃГзЪДеЬ∞еЭАе∞±дЄНиГљжШѓдЄ§е≠ЧиКВзЪДжХіжХ∞еАНдЇЖпЉМжЙАдї•зЉЦиѓСеЩ®дЉЪеЬ®зїУжЮДдљУдЄ≠жПТеЕ•дЄАдЄ™е°ЂеЕЕе≠ЧиКВпЉМдљњs.bзЪДеЬ∞еЭАдєЯжШѓдЄ§е≠ЧиКВзЪДжХіжХ∞еАНгАВs.cеН†4е≠ЧиКВпЉМзіІжМ®еЬ®s.bзЪДеРОйЭҐе∞±еПѓдї•дЇЖпЉМеЫ†дЄЇebp-0xcињЩдЄ™еЬ∞еЭАдєЯжШѓ4зЪДжХіжХ∞еАНгАВйВ£дєИдЄЇдїАдєИs.dзЪДеРОйЭҐдєЯи¶БжЬЙе°ЂеЕЕдљНе°ЂеЕЕеИ∞4е≠ЧиКВиЊєзХМеСҐпЉЯињЩжШѓдЄЇдЇЖдЊњдЇОеЃЙжОТињЩдЄ™зїУжЮДдљУеРОйЭҐзЪДеПШйЗПзЪДеЬ∞еЭАпЉМеБЗе¶ВзФ®ињЩзІНзїУжЮДдљУз±їеЮЛзїДжИРдЄАдЄ™жХ∞зїДпЉМйВ£дєИеРОдЄАдЄ™зїУжЮДдљУеП™йЬАеТМеЙНдЄАдЄ™зїУжЮДдљУзіІжМ®зЭАжОТеИЧе∞±еПѓдї•дњЭиѓБеЃГзЪДеЯЇеЬ∞еЭАдїНзДґеѓєйљРеИ∞4е≠ЧиКВиЊєзХМдЇЖпЉМеЫ†дЄЇеЬ®еЙНдЄАдЄ™зїУжЮДдљУзЪДжЬЂе∞ЊеЈ≤зїПжЬЙдЇЖе°ЂеЕЕе≠ЧиКВгАВдЇЛеЃЮдЄКпЉМCж†ЗеЗЖиІДеЃЪжХ∞зїДеЕГзі†ењЕй°їзіІжМ®зЭАжОТеИЧпЉМдЄНиГљжЬЙз©ЇйЪЩпЉМињЩж†ЈжЙНиГљдњЭиѓБжѓПдЄ™еЕГзі†зЪДеЬ∞еЭАеПѓдї•жМЙвАЬеЯЇеЬ∞еЭА+n√ЧеЕГзі†е§Іе∞ПвАЭзЃАеНХиЃ°зЃЧеЗЇжЭ•гАВ
еРИзРЖиЃЊиЃ°зїУжЮДдљУеРДжИРеСШзЪДжОТеИЧй°ЇеЇПеПѓдї•иКВзЬБе≠ШеВ®з©ЇйЧіпЉМдЊЛе¶ВдЄКдЊЛдЄ≠зЪДзїУжЮДдљУжФєжИРињЩж†Је∞±еПѓдї•йБњеЕНдЇІзФЯе°ЂеЕЕе≠ЧиКВпЉЪ
struct {
char a;
char d;
short b;
int c;
} s;
ж≠§е§ЦпЉМgccжПРдЊЫдЇЖдЄАзІНжЙ©е±Хиѓ≠ж≥ХеПѓдї•жґИйЩ§зїУжЮДдљУдЄ≠зЪДе°ЂеЕЕе≠ЧиКВпЉЪ
struct {
char a;
short b;
int c;
char d;
} __attribute__((packed)) s;
ињЩж†Је∞±дЄНиГљдњЭиѓБзїУжЮДдљУжИРеСШзЪДеѓєйљРдЇЖпЉМеЬ®иЃњйЧЃbеТМcзЪДжЧґеАЩеПѓиГљдЉЪжЬЙжХИзОЗйЧЃйҐШпЉМжЙАдї•йЩ§йЭЮжЬЙзЙєеИЂзЪДзРЖзФ±пЉМдЄАиИђдЄНи¶БдљњзФ®ињЩзІНиѓ≠ж≥ХгАВ
дї•еЙНжИСдїђдљњзФ®зЪДжХ∞жНЃз±їеЮЛйГљжШѓеН†еЗ†дЄ™е≠ЧиКВпЉМжЬАе∞ПзЪДз±їеЮЛдєЯи¶БеН†дЄАдЄ™е≠ЧиКВпЉМиАМеЬ®зїУжЮДдљУдЄ≠ињШеПѓдї•дљњзФ®Bit-fieldиѓ≠ж≥ХеЃЪдєЙеП™еН†еЗ†дЄ™bitзЪДжИРеСШгАВдЄЛйЭҐињЩдЄ™дЊЛе≠РеЗЇиЗ™зОЛиБ™зЪДзљСзЂЩпЉИwww.wangcong.orgпЉЙпЉЪ
дЊЛ¬†19.4.¬†Bit-field
#include <stdio.h>
typedef struct {
unsigned int one:1;
unsigned int two:3;
unsigned int three:10;
unsigned int four:5;
unsigned int :2;
unsigned int five:8;
unsigned int six:8;
} demo_type;
int main(void)
{
demo_type s = { 1, 5, 513, 17, 129, 0x81 };
printf("sizeof demo_type = %u
", sizeof(demo_type));
printf("values: s=%u,%u,%u,%u,%u,%u
",
s.one, s.two, s.three, s.four, s.five, s.six);
return 0;
}
sињЩдЄ™зїУжЮДдљУзЪДеЄГе±Ае¶ВдЄЛеЫЊжЙАз§ЇпЉЪ
еЫЊ¬†19.6.¬†Bit-fieldзЪДе≠ШеВ®еЄГе±А
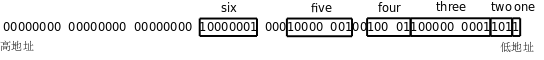
Bit-fieldжИРеСШзЪДз±їеЮЛеПѓдї•жШѓintжИЦunsigned intпЉМи°®з§ЇжЬЙзђ¶еПЈжХ∞жИЦжЧ†зђ¶еПЈжХ∞пЉМдљЖдЄНи°®з§ЇеЃГеГПжЩЃйАЪзЪДintеЮЛдЄАж†ЈеН†4дЄ™е≠ЧиКВпЉМеЃГеРОйЭҐзЪДжХ∞е≠ЧжШѓеЗ†е∞±и°®з§ЇеЃГеН†е§Ъе∞СдЄ™bitпЉМдєЯеПѓдї•еГПunsigned int :2;ињЩж†ЈеЃЪдєЙдЄАдЄ™жЬ™еСљеРНзЪДBit-fieldпЉМеН≥дљњдЄНеЖЩжЬ™еСљеРНзЪДBit-fieldпЉМзЉЦиѓСеЩ®дєЯжЬЙеПѓиГљеЬ®дЄ§дЄ™жИРеСШдєЛйЧіжПТеЕ•е°ЂеЕЕдљНпЉМе¶ВдЄКеЫЊзЪДfiveеТМsixдєЛйЧіпЉМињЩж†ЈsixињЩдЄ™жИРеСШе∞±еИЪе•љеНХзЛђеН†дЄАдЄ™е≠ЧиКВдЇЖпЉМиЃњйЧЃжХИзОЗдЉЪжѓФиЊГйЂШпЉМињЩдЄ™зїУжЮДдљУзЪДжЬЂе∞ЊињШе°ЂеЕЕдЇЖ3дЄ™е≠ЧиКВпЉМдї•дЊњеѓєйљРеИ∞4е≠ЧиКВиЊєзХМгАВдї•еЙНжИСдїђиѓіињЗx86зЪДByte OrderжШѓе∞ПзЂѓзЪДпЉМдїОдЄКеЫЊдЄ≠oneеТМtwoзЪДжОТеИЧй°ЇеЇПеПѓдї•зЬЛеЗЇпЉМе¶ВжЮЬеѓєдЄАдЄ™е≠ЧиКВеЖНзїЖеИЖпЉМеИЩе≠ЧиКВдЄ≠зЪДBit OrderдєЯжШѓе∞ПзЂѓзЪДпЉМеЫ†дЄЇжОТеЬ®зїУжЮДдљУеЙНйЭҐзЪДжИРеСШпЉИйЭ†ињСдљОеЬ∞еЭАдЄАиЊєзЪДжИРеСШпЉЙеПЦе≠ЧиКВдЄ≠зЪДдљОдљНгАВеЕ≥дЇОе¶ВдљХжОТеИЧBit-fieldеЬ®Cж†ЗеЗЖдЄ≠ж≤°жЬЙиѓ¶зїЖзЪДиІДеЃЪпЉМињЩиЈЯByte OrderгАБBit OrderгАБеѓєйљРз≠ЙйЧЃйҐШйГљжЬЙеЕ≥пЉМдЄНеРМзЪДеє≥еП∞еТМзЉЦиѓСеЩ®еПѓиГљдЉЪжОТеИЧеЊЧеЊИдЄНдЄАж†ЈпЉМи¶БзЉЦеЖЩеПѓзІїж§НзЪДдї£з†Бе∞±дЄНиГљеБЗеЃЪBit-fieldжШѓжМЙжЯРдЄАзІНеЫЇеЃЪжЦєеЉПжОТеИЧзЪДгАВBit-fieldеЬ®й©±еК®з®ЛеЇПдЄ≠жШѓеЊИжЬЙзФ®зЪДпЉМеЫ†дЄЇзїПеЄЄйЬАи¶БеНХзЛђжУНдљЬиЃЊе§ЗеѓДе≠ШеЩ®дЄ≠зЪДдЄАдЄ™жИЦеЗ†дЄ™bitпЉМдљЖдЄАеЃЪи¶Бе∞ПењГдљњзФ®пЉМй¶ЦеЕИеЉДжЄЕж•ЪжѓПдЄ™Bit-fieldеТМеЃЮйЩЕbitзЪДеѓєеЇФеЕ≥з≥їгАВ
еТМеЙНйЭҐеЗ†дЄ™дЊЛе≠РдЄНдЄАж†ЈпЉМеЬ®дЄКдЊЛдЄ≠жИСж≤°жЬЙзїЩеЗЇеПНж±ЗзЉЦзїУжЮЬпЉМзЫіжО•зФїдЇЖдЄ™еЫЊиѓіињЩдЄ™зїУжЮДдљУзЪДеЄГе±АжШѓињЩж†ЈзЪДпЉМйВ£жИСжЬЙдїАдєИиѓБжНЃињЩдєИиѓіеСҐпЉЯдЄКдЊЛзЪДеПНж±ЗзЉЦзїУжЮЬжѓФиЊГзєБзРРпЉМжИСдїђеПѓдї•йАЪињЗеП¶дЄАзІНжЙЛжЃµеЊЧеИ∞ињЩдЄ™зїУжЮДдљУзЪДеЖЕе≠ШеЄГе±АгАВCиѓ≠и®АињШжЬЙдЄАзІНз±їеЮЛеПЂиБФеРИдљУпЉМзФ®еЕ≥йФЃе≠ЧunionеЃЪдєЙпЉМеЕґиѓ≠ж≥Хз±їдЉЉдЇОзїУжЮДдљУпЉМдЊЛе¶ВпЉЪ
дЊЛ¬†19.5.¬†иБФеРИдљУ
#include <stdio.h>
typedef union {
struct {
unsigned int one:1;
unsigned int two:3;
unsigned int three:10;
unsigned int four:5;
unsigned int :2;
unsigned int five:8;
unsigned int six:8;
} bitfield;
unsigned char byte[8];
} demo_type;
int main(void)
{
demo_type u = {{ 1, 5, 513, 17, 129, 0x81 }};
printf("sizeof demo_type = %u
", sizeof(demo_type));
printf("values: u=%u,%u,%u,%u,%u,%u
",
u.bitfield.one, u.bitfield.two, u.bitfield.three,
u.bitfield.four, u.bitfield.five, u.bitfield.six);
printf("hex dump of u: %x %x %x %x %x %x %x %x
",
u.byte[0], u.byte[1], u.byte[2], u.byte[3],
u.byte[4], u.byte[5], u.byte[6], u.byte[7]);
return 0;
}
дЄАдЄ™иБФеРИдљУзЪДеРДдЄ™жИРеСШеН†зФ®зЫЄеРМзЪДеЖЕе≠Шз©ЇйЧіпЉМиБФеРИдљУзЪДйХњеЇ¶з≠ЙдЇОеЕґдЄ≠жЬАйХњжИРеСШзЪДйХњеЇ¶гАВжѓФе¶ВuињЩдЄ™иБФеРИдљУеН†8дЄ™е≠ЧиКВпЉМе¶ВжЮЬиЃњйЧЃжИРеСШu.bitfieldпЉМеИЩжККињЩ8дЄ™е≠ЧиКВзЬЛжИРдЄАдЄ™зФ±Bit-fieldзїДжИРзЪДзїУжЮДдљУпЉМе¶ВжЮЬиЃњйЧЃжИРеСШu.byteпЉМеИЩжККињЩ8дЄ™е≠ЧиКВзЬЛжИРдЄАдЄ™жХ∞зїДгАВиБФеРИдљУе¶ВжЮЬзФ®InitializerеИЭеІЛеМЦпЉМеИЩеП™еИЭеІЛеМЦеЃГзЪДзђђдЄАдЄ™жИРеСШпЉМдЊЛе¶Вdemo_type u = {{ 1, 5, 513, 17, 129, 0x81 }};еИЭеІЛеМЦзЪДжШѓu.bitfieldпЉМдљЖжШѓйАЪињЗu.bitfieldзЪДжИРеСШзЬЛдЄНеЗЇињЩ8дЄ™е≠ЧиКВзЪДеЖЕе≠ШеЄГе±АпЉМиАМйАЪињЗu.byteжХ∞зїДе∞±еПѓдї•зЬЛеЗЇжѓПдЄ™е≠ЧиКВеИЖеИЂжШѓе§Ъе∞СдЇЖгАВ
дє†йҐШ
1гАБзЉЦеЖЩдЄАдЄ™з®ЛеЇПпЉМжµЛиѓХињРи°МеЃГзЪДеє≥еП∞жШѓе§ІзЂѓињШжШѓе∞ПзЂѓе≠ЧиКВеЇПгАВ
5.¬†CеЖЕиБФж±ЗзЉЦ
зФ®CеЖЩз®ЛеЇПжѓФзЫіжО•зФ®ж±ЗзЉЦеЖЩз®ЛеЇПжЫізЃАжіБпЉМеПѓиѓїжАІжЫіе•љпЉМдљЖжХИзОЗеПѓиГљдЄНе¶Вж±ЗзЉЦз®ЛеЇПпЉМеЫ†дЄЇCз®ЛеЇПжѓХзЂЯи¶БзїПзФ±зЉЦиѓСеЩ®зФЯжИРж±ЗзЉЦдї£з†БпЉМе∞љзЃ°зО∞дї£зЉЦиѓСеЩ®зЪДдЉШеМЦеЈ≤зїПеБЪеЊЧеЊИе•љдЇЖпЉМдљЖињШжШѓдЄНе¶ВжЙЛеЖЩзЪДж±ЗзЉЦдї£з†БгАВеП¶е§ЦпЉМжЬЙдЇЫеє≥еП∞зЫЄеЕ≥зЪДжМЗдї§ењЕй°їжЙЛеЖЩпЉМеЬ®Cиѓ≠и®АдЄ≠ж≤°жЬЙз≠ЙдїЈзЪДиѓ≠ж≥ХпЉМеЫ†дЄЇCиѓ≠и®АзЪДиѓ≠ж≥ХеТМж¶ВењµжШѓеѓєеРДзІНеє≥еП∞зЪДжКљи±°пЉМиАМеРДзІНеє≥еП∞зЙєжЬЙзЪДдЄАдЇЫдЄЬи•ње∞±дЄНдЉЪеЬ®Cиѓ≠и®АдЄ≠еЗЇзО∞дЇЖпЉМдЊЛе¶Вx86жШѓзЂѓеП£I/OпЉМиАМCиѓ≠и®Ае∞±ж≤°жЬЙињЩдЄ™ж¶ВењµпЉМжЙАдї•in/outжМЗдї§ењЕй°їзФ®ж±ЗзЉЦжЭ•еЖЩгАВ
Cиѓ≠и®АзЃАжіБжШУиѓїпЉМеЃєжШУзїДзїЗиІДж®°иЊГе§ІзЪДдї£з†БпЉМиАМж±ЗзЉЦжХИзОЗйЂШпЉМиАМдЄФеЖЩдЄАдЇЫзЙєжЃКжМЗдї§ењЕй°їзФ®ж±ЗзЉЦпЉМдЄЇдЇЖжККињЩдЄ§жЦєйЭҐзЪДе•ље§ДйГљеН†еЕ®дЇЖпЉМgccжПРдЊЫдЇЖдЄАзІНжЙ©е±Хиѓ≠ж≥ХеПѓдї•еЬ®Cдї£з†БдЄ≠дљњзФ®еЖЕиБФж±ЗзЉЦпЉИInline AssemblyпЉЙгАВжЬАзЃАеНХзЪДж†ЉеЉПжШѓ__asm__("assembly code");пЉМдЊЛе¶В__asm__("nop"); пЉМnop ињЩжЭ°жМЗдї§дїАдєИйГљдЄНеБЪпЉМеП™жШѓиЃ©CPUз©ЇиљђдЄАдЄ™жМЗдї§жЙІи°МеС®жЬЯгАВе¶ВжЮЬйЬАи¶БжЙІи°Ме§ЪжЭ°ж±ЗзЉЦжМЗдї§пЉМеИЩеЇФиѓ•зФ®
е∞ЖеРДжЭ°жМЗдї§еИЖйЪФеЉАпЉМдЊЛе¶ВпЉЪ
__asm__("movl $1, %eax
"
"movl $4, %ebx
"
"int $0x80");
йАЪеЄЄ C дї£з†БдЄ≠зЪДеЖЕиБФж±ЗзЉЦйЬАи¶БеТМCзЪДеПШйЗПеїЇзЂЛеЕ≥иБФпЉМйЬАи¶БзФ®еИ∞еЃМжХізЪДеЖЕиБФж±ЗзЉЦж†ЉеЉПпЉЪ
__asm__(assembler template
: output operands /* optional */
: input operands /* optional */
: list of clobbered registers /* optional */
);
ињЩзІНж†ЉеЉПзФ±еЫЫйГ®еИЖзїДжИРпЉМзђђдЄАйГ®еИЖжШѓж±ЗзЉЦжМЗдї§пЉМеТМдЄКйЭҐзЪДдЊЛе≠РдЄАж†ЈпЉМзђђдЇМйГ®еИЖеТМзђђдЄЙйГ®еИЖжШѓзЇ¶жЭЯжЭ°дїґпЉМзђђдЇМйГ®еИЖжМЗз§Їж±ЗзЉЦжМЗдї§зЪДињРзЃЧзїУжЮЬи¶БиЊУеЗЇеИ∞еУ™дЇЫCжУНдљЬжХ∞дЄ≠пЉМCжУНдљЬжХ∞еЇФиѓ•жШѓеЈ¶еАЉи°®иЊЊеЉПпЉМзђђдЄЙйГ®еИЖжМЗз§Їж±ЗзЉЦжМЗдї§йЬАи¶БдїОеУ™дЇЫCжУНдљЬжХ∞иОЈеЊЧиЊУеЕ•пЉМзђђеЫЫйГ®еИЖжШѓеЬ®ж±ЗзЉЦжМЗдї§дЄ≠襀䜁жФєињЗзЪДеѓДе≠ШеЩ®еИЧи°®пЉМжМЗз§ЇзЉЦиѓСеЩ®еУ™дЇЫеѓДе≠ШеЩ®зЪДеАЉеЬ®жЙІи°МињЩжЭ°__asm__иѓ≠еП•жЧґдЉЪжФєеПШгАВеРОдЄЙдЄ™йГ®еИЖйГљжШѓеПѓйАЙзЪДпЉМе¶ВжЮЬжЬЙе∞±е°ЂеЖЩпЉМж≤°жЬЙе∞±з©ЇзЭАеП™еЖЩдЄ™:еПЈгАВдЊЛе¶ВпЉЪ
дЊЛ¬†19.6.¬†еЖЕиБФж±ЗзЉЦ
#include <stdio.h>
int main()
{
int a = 10, b;
__asm__("movl %1, %%eax
"
"movl %%eax, %0
"
:"=r"(b) /* output */
:"r"(a) /* input */
:"%eax" /* clobbered register */
);
printf("Result: %d, %d
", a, b);
return 0;
}
ињЩдЄ™з®ЛеЇПе∞ЖеПШйЗПaзЪДеАЉиµЛзїЩbгАВ"r"(a)жМЗз§ЇзЉЦиѓСеЩ®еИЖйЕНдЄАдЄ™еѓДе≠ШеЩ®дњЭе≠ШеПШйЗПaзЪДеАЉпЉМдљЬдЄЇж±ЗзЉЦжМЗдї§зЪДиЊУеЕ•пЉМдєЯе∞±жШѓжМЗдї§дЄ≠зЪД%1пЉИжМЙзЕІзЇ¶жЭЯжЭ°дїґзЪДй°ЇеЇПпЉМbеѓєеЇФ%0пЉМaеѓєеЇФ1%пЉЙпЉМиЗ≥дЇО%1з©ґзЂЯдї£и°®еУ™дЄ™еѓДе≠ШеЩ®еИЩзФ±зЉЦиѓСеЩ®иЗ™еЈ±еЖ≥еЃЪгАВж±ЗзЉЦжМЗдї§й¶ЦеЕИжКК%1жЙАдї£и°®зЪДеѓДе≠ШеЩ®зЪДеАЉдЉ†зїЩeaxпЉИдЄЇдЇЖеТМ%1ињЩзІНеН†дљНзђ¶еМЇеИЖпЉМeaxеЙНйЭҐи¶Бж±ВеК†дЄ§дЄ™%еПЈпЉЙпЉМзДґеРОжККeaxзЪДеАЉеЖНдЉ†зїЩ%0жЙАдї£и°®зЪДеѓДе≠ШеЩ®гАВ"=r"(b)е∞±и°®з§ЇжКК%0жЙАдї£и°®зЪДеѓДе≠ШеЩ®зЪДеАЉиЊУеЗЇзїЩеПШйЗПbгАВеЬ®жЙІи°МињЩдЄ§жЭ°жМЗдї§зЪДињЗз®ЛдЄ≠пЉМеѓДе≠ШеЩ®eaxзЪДеАЉиҐЂжФєеПШдЇЖпЉМжЙАдї•жКК"%eax"еЖЩеЬ®зђђеЫЫйГ®еИЖпЉМеСКиѓЙзЉЦиѓСеЩ®еЬ®жЙІи°МињЩжЭ°__asm__иѓ≠еП•жЧґeaxи¶Б襀жФєеЖЩпЉМжЙАдї•еЬ®ж≠§жЬЯйЧідЄНи¶БзФ®eaxдњЭе≠ШеЕґеЃГеАЉгАВ
жИСдїђзЬЛдЄАдЄЛињЩдЄ™з®ЛеЇПзЪДеПНж±ЗзЉЦзїУжЮЬпЉЪ
__asm__("movl %1, %%eax
"
80483dc: 8b 55 f8 mov -0x8(%ebp),%edx
80483df: 89 d0 mov %edx,%eax
80483e1: 89 c2 mov %eax,%edx
80483e3: 89 55 f4 mov %edx,-0xc(%ebp)
"movl %%eax, %0
"
:"=r"(b) /* output */
:"r"(a) /* input */
:"%eax" /* clobbered register */
);
еПѓиІБ%0еТМ%1йГљдї£и°®edxеѓДе≠ШеЩ®пЉМй¶ЦеЕИжККеПШйЗПaпЉИдљНдЇОebp-8зЪДдљНзљЃпЉЙзЪДеАЉдЉ†зїЩedxзДґеРОжЙІи°МеЖЕиБФж±ЗзЉЦзЪДдЄ§жЭ°жМЗдї§пЉМзДґеРОжККedxзЪДеАЉдЉ†зїЩbпЉИдљНдЇОebp-12зЪДдљНзљЃпЉЙгАВ
еЕ≥дЇОеЖЕиБФж±ЗзЉЦе∞±дїЛзїНињЩдєИе§ЪпЉМжЬђдє¶дЄНеБЪжЈ±еЕ•иЃ®иЃЇгАВ
6.¬†volatileйЩРеЃЪзђ¶
зО∞еЬ®жОҐиЃ®дЄАдЄЛзЉЦиѓСеЩ®дЉШеМЦдЉЪеѓєзФЯжИРзЪДжМЗдї§дЇІзФЯдїАдєИељ±еУНпЉМеЬ®ж≠§еЯЇз°АдЄКдїЛзїНCиѓ≠и®АзЪДvolatileйЩРеЃЪзђ¶гАВзЬЛдЄЛйЭҐзЪДдЊЛе≠РгАВ
дЊЛ¬†19.7.¬†volatileйЩРеЃЪзђ¶
/* artificial device registers */
unsigned char recv;
unsigned char send;
/* memory buffer */
unsigned char buf[3];
int main(void)
{
buf[0] = recv;
buf[1] = recv;
buf[2] = recv;
send = ~buf[0];
send = ~buf[1];
send = ~buf[2];
return 0;
}
жИСдїђзФ®recvеТМsendињЩдЄ§дЄ™еЕ®е±АеПШйЗПжЭ•ж®°жЛЯиЃЊе§ЗеѓДе≠ШеЩ®гАВеБЗиЃЊжЯРзІНеє≥еП∞йЗЗзФ®еЖЕе≠ШжШ†е∞ДI/OпЉМдЄ≤еП£еПСйАБеѓДе≠ШеЩ®еТМдЄ≤еП£жО•жФґеѓДе≠ШеЩ®дљНдЇОеЫЇеЃЪзЪДеЖЕе≠ШеЬ∞еЭАпЉМиАМrecvеТМsendињЩдЄ§дЄ™еЕ®е±АеПШйЗПдєЯжЬЙеЫЇеЃЪзЪДеЖЕе≠ШеЬ∞еЭАпЉМжЙАдї•еЬ®ињЩдЄ™дЊЛе≠РдЄ≠жККеЃГдїђеБЗжГ≥жИРдЄ≤еП£жО•жФґеѓДе≠ШеЩ®еТМдЄ≤еП£еПСйАБеѓДе≠ШеЩ®гАВеЬ®mainеЗљжХ∞дЄ≠пЉМй¶ЦеЕИдїОдЄ≤еП£жО•жФґдЄЙдЄ™е≠ЧиКВе≠ШеИ∞bufдЄ≠пЉМзДґеРОжККињЩдЄЙдЄ™е≠ЧиКВеПЦеПНпЉМдЊЭжђ°дїОдЄ≤еП£еПСйАБеЗЇеОї[[31](#ftn.id2780312)]гАВжИСдїђжЯ•зЬЛињЩжЃµдї£з†БзЪДеПНж±ЗзЉЦзїУжЮЬпЉЪ
buf[0] = recv;
80483a2: 0f b6 05 19 a0 04 08 movzbl 0x804a019,%eax
80483a9: a2 1a a0 04 08 mov %al,0x804a01a
buf[1] = recv;
80483ae: 0f b6 05 19 a0 04 08 movzbl 0x804a019,%eax
80483b5: a2 1b a0 04 08 mov %al,0x804a01b
buf[2] = recv;
80483ba: 0f b6 05 19 a0 04 08 movzbl 0x804a019,%eax
80483c1: a2 1c a0 04 08 mov %al,0x804a01c
send = ~buf[0];
80483c6: 0f b6 05 1a a0 04 08 movzbl 0x804a01a,%eax
80483cd: f7 d0 not %eax
80483cf: a2 18 a0 04 08 mov %al,0x804a018
send = ~buf[1];
80483d4: 0f b6 05 1b a0 04 08 movzbl 0x804a01b,%eax
80483db: f7 d0 not %eax
80483dd: a2 18 a0 04 08 mov %al,0x804a018
send = ~buf[2];
80483e2: 0f b6 05 1c a0 04 08 movzbl 0x804a01c,%eax
80483e9: f7 d0 not %eax
80483eb: a2 18 a0 04 08 mov %al,0x804a018
movzжМЗдї§жККе≠ЧйХњиЊГзЯ≠зЪДеАЉе≠ШеИ∞е≠ЧйХњиЊГйХњзЪДе≠ШеВ®еНХеЕГдЄ≠пЉМе≠ШеВ®еНХеЕГзЪДйЂШдљНзФ®0е°ЂеЕЕгАВиѓ•жМЗдї§еПѓдї•жЬЙbпЉИbyteпЉЙгАБwпЉИwordпЉЙгАБlпЉИlongпЉЙдЄЙзІНеРОзЉАпЉМеИЖеИЂи°®з§ЇеНХе≠ЧиКВгАБдЄ§е≠ЧиКВеТМеЫЫе≠ЧиКВгАВжѓФе¶Вmovzbl 0x804a019,%eaxи°®з§ЇжККеЬ∞еЭА0x804a019е§ДзЪДдЄАдЄ™е≠ЧиКВе≠ШеИ∞eaxеѓДе≠ШеЩ®дЄ≠пЉМиАМeaxеѓДе≠ШеЩ®жШѓеЫЫе≠ЧиКВзЪДпЉМйЂШдЄЙе≠ЧиКВзФ®0е°ЂеЕЕпЉМиАМдЄЛдЄАжЭ°жМЗдї§mov %al,0x804a01aдЄ≠зЪДalеѓДе≠ШеЩ®ж≠£жШѓeaxеѓДе≠ШеЩ®зЪДдљОе≠ЧиКВпЉМжККињЩдЄ™е≠ЧиКВе≠ШеИ∞еЬ∞еЭА0x804a01aе§ДзЪДдЄАдЄ™е≠ЧиКВдЄ≠гАВеПѓдї•зФ®дЄНеРМзЪДеРНе≠ЧеНХзЛђиЃњйЧЃx86еѓДе≠ШеЩ®зЪДдљО8