

第 30В з« В иҝӣзЁӢ
зӣ®еҪ•
1.В еј•иЁҖ
жҲ‘们зҹҘйҒ“пјҢжҜҸдёӘиҝӣзЁӢеңЁеҶ…ж ёдёӯйғҪжңүдёҖдёӘиҝӣзЁӢжҺ§еҲ¶еқ—пјҲPCBпјүжқҘз»ҙжҠӨиҝӣзЁӢзӣёе…ізҡ„дҝЎжҒҜпјҢLinuxеҶ…ж ёзҡ„иҝӣзЁӢжҺ§еҲ¶еқ—жҳҜtask_structз»“жһ„дҪ“гҖӮзҺ°еңЁжҲ‘们全йқўдәҶи§ЈдёҖдёӢе…¶дёӯйғҪжңүе“ӘдәӣдҝЎжҒҜгҖӮ
иҝӣзЁӢidгҖӮзі»з»ҹдёӯжҜҸдёӘиҝӣзЁӢжңүе”ҜдёҖзҡ„idпјҢеңЁCиҜӯиЁҖдёӯз”Ё
pid_tзұ»еһӢиЎЁзӨәпјҢе…¶е®һе°ұжҳҜдёҖдёӘйқһиҙҹж•ҙж•°гҖӮиҝӣзЁӢзҡ„зҠ¶жҖҒпјҢжңүиҝҗиЎҢгҖҒжҢӮиө·гҖҒеҒңжӯўгҖҒеғөе°ёзӯүзҠ¶жҖҒгҖӮ
иҝӣзЁӢеҲҮжҚўж—¶йңҖиҰҒдҝқеӯҳе’ҢжҒўеӨҚзҡ„дёҖдәӣCPUеҜ„еӯҳеҷЁгҖӮ
жҸҸиҝ°иҷҡжӢҹең°еқҖз©әй—ҙзҡ„дҝЎжҒҜгҖӮ
жҸҸиҝ°жҺ§еҲ¶з»Ҳз«Ҝзҡ„дҝЎжҒҜгҖӮ
еҪ“еүҚе·ҘдҪңзӣ®еҪ•пјҲCurrent Working DirectoryпјүгҖӮ
umaskжҺ©з ҒгҖӮж–Ү件жҸҸиҝ°з¬ҰиЎЁпјҢеҢ…еҗ«еҫҲеӨҡжҢҮеҗ‘
fileз»“жһ„дҪ“зҡ„жҢҮй’ҲгҖӮе’ҢдҝЎеҸ·зӣёе…ізҡ„дҝЎжҒҜгҖӮ
з”ЁжҲ·idе’Ңз»„idгҖӮ
жҺ§еҲ¶з»Ҳз«ҜгҖҒSessionе’ҢиҝӣзЁӢз»„гҖӮ
иҝӣзЁӢеҸҜд»ҘдҪҝз”Ёзҡ„иө„жәҗдёҠйҷҗпјҲResource LimitпјүгҖӮ
зӣ®еүҚиҜ»иҖ…并дёҚйңҖиҰҒзҗҶи§ЈиҝҷдәӣдҝЎжҒҜзҡ„з»ҶиҠӮпјҢеңЁйҡҸеҗҺеҮ з« дёӯи®ІеҲ°жҹҗдёҖйЎ№ж—¶дјҡеҶҚж¬ЎжҸҗйҶ’иҜ»иҖ…е®ғжҳҜдҝқеӯҳеңЁPCBдёӯзҡ„гҖӮ
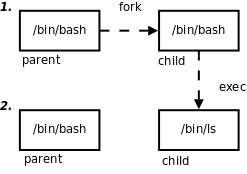
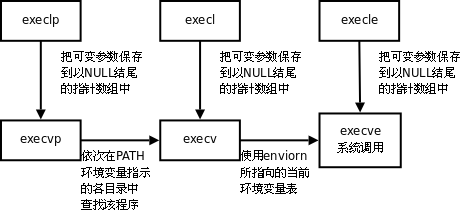
forkе’ҢexecжҳҜжң¬з« иҰҒд»Ӣз»Қзҡ„дёӨдёӘйҮҚиҰҒзҡ„зі»з»ҹи°ғз”ЁгҖӮforkзҡ„дҪңз”ЁжҳҜж №жҚ®дёҖдёӘзҺ°жңүзҡ„иҝӣзЁӢеӨҚеҲ¶еҮәдёҖдёӘж–°иҝӣзЁӢпјҢеҺҹжқҘзҡ„иҝӣзЁӢз§°дёәзҲ¶иҝӣзЁӢпјҲParent ProcessпјүпјҢж–°иҝӣзЁӢз§°дёәеӯҗиҝӣзЁӢпјҲChild ProcessпјүгҖӮзі»з»ҹдёӯеҗҢж—¶иҝҗиЎҢзқҖеҫҲеӨҡиҝӣзЁӢпјҢиҝҷдәӣиҝӣзЁӢйғҪжҳҜд»ҺжңҖеҲқеҸӘжңүдёҖдёӘиҝӣзЁӢејҖе§ӢдёҖдёӘдёҖдёӘеӨҚеҲ¶еҮәжқҘзҡ„гҖӮеңЁShellдёӢиҫ“е…Ҙе‘Ҫд»ӨеҸҜд»ҘиҝҗиЎҢдёҖдёӘзЁӢеәҸпјҢжҳҜеӣ дёәShellиҝӣзЁӢеңЁиҜ»еҸ–з”ЁжҲ·иҫ“е…Ҙзҡ„е‘Ҫд»Өд№ӢеҗҺдјҡи°ғз”ЁforkеӨҚеҲ¶еҮәдёҖдёӘж–°зҡ„ShellиҝӣзЁӢпјҢ然еҗҺж–°зҡ„ShellиҝӣзЁӢи°ғз”Ёexecжү§иЎҢж–°зҡ„зЁӢеәҸгҖӮ
жҲ‘们зҹҘйҒ“дёҖдёӘзЁӢеәҸеҸҜд»ҘеӨҡж¬ЎеҠ иҪҪеҲ°еҶ…еӯҳпјҢжҲҗдёәеҗҢж—¶иҝҗиЎҢзҡ„еӨҡдёӘиҝӣзЁӢпјҢдҫӢеҰӮеҸҜд»ҘеҗҢж—¶ејҖеӨҡдёӘз»Ҳз«ҜзӘ—еҸЈиҝҗиЎҢ/bin/bashпјҢеҸҰдёҖж–№йқўпјҢдёҖдёӘиҝӣзЁӢеңЁи°ғз”ЁexecеүҚеҗҺд№ҹеҸҜд»ҘеҲҶеҲ«жү§иЎҢдёӨдёӘдёҚеҗҢзҡ„зЁӢеәҸпјҢдҫӢеҰӮеңЁShellжҸҗзӨәз¬ҰдёӢиҫ“е…Ҙе‘Ҫд»ӨlsпјҢйҰ–е…ҲforkеҲӣе»әеӯҗиҝӣзЁӢпјҢиҝҷж—¶еӯҗиҝӣзЁӢд»ҚеңЁжү§иЎҢ/bin/bashзЁӢеәҸпјҢ然еҗҺеӯҗиҝӣзЁӢи°ғз”Ёexecжү§иЎҢж–°зҡ„зЁӢеәҸ/bin/lsпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
еӣҫВ 30.1.В fork/exec
еңЁз¬¬В 3В иҠӮ вҖңopen/closeвҖқдёӯжҲ‘们еҒҡиҝҮдёҖдёӘе®һйӘҢпјҡз”Ёumaskе‘Ҫд»Өи®ҫзҪ®ShellиҝӣзЁӢзҡ„umaskжҺ©з ҒпјҢ然еҗҺиҝҗиЎҢзЁӢеәҸa.outпјҢз»“жһңa.outиҝӣзЁӢзҡ„umaskжҺ©з Ғд№ҹе’ҢShellиҝӣзЁӢдёҖж ·гҖӮзҺ°еңЁеҸҜд»Ҙи§ЈйҮҠдәҶпјҢеӣ дёәa.outиҝӣзЁӢжҳҜShellиҝӣзЁӢзҡ„еӯҗиҝӣзЁӢпјҢеӯҗиҝӣзЁӢзҡ„PCBжҳҜж №жҚ®зҲ¶иҝӣзЁӢеӨҚеҲ¶иҖҢжқҘзҡ„пјҢжүҖд»Ҙе…¶дёӯзҡ„umaskжҺ©з Ғд№ҹе’ҢзҲ¶иҝӣзЁӢдёҖж ·гҖӮеҗҢж ·йҒ“зҗҶпјҢеӯҗиҝӣзЁӢзҡ„еҪ“еүҚе·ҘдҪңзӣ®еҪ•д№ҹе’ҢзҲ¶иҝӣзЁӢдёҖж ·пјҢжүҖд»ҘжҲ‘们еҸҜд»Ҙз”Ёcdе‘Ҫд»Өж”№еҸҳShellиҝӣзЁӢзҡ„еҪ“еүҚзӣ®еҪ•пјҢ然еҗҺз”Ёlsе‘Ҫд»ӨеҲ—еҮәйӮЈдёӘзӣ®еҪ•дёӢзҡ„ж–Ү件пјҢlsиҝӣзЁӢе…¶е®һжҳҜеңЁеҲ—иҮӘе·ұзҡ„еҪ“еүҚзӣ®еҪ•пјҢиҖҢдёҚжҳҜShellиҝӣзЁӢзҡ„еҪ“еүҚзӣ®еҪ•пјҢеҸӘдёҚиҝҮlsиҝӣзЁӢзҡ„еҪ“еүҚзӣ®еҪ•жӯЈеҘҪе’ҢShellиҝӣзЁӢзӣёеҗҢгҖӮжңүдёҖдёӘдҫӢеӨ–пјҢеӯҗиҝӣзЁӢPCBдёӯзҡ„иҝӣзЁӢidе’ҢзҲ¶иҝӣзЁӢжҳҜдёҚеҗҢзҡ„гҖӮ
2.В зҺҜеўғеҸҳйҮҸ
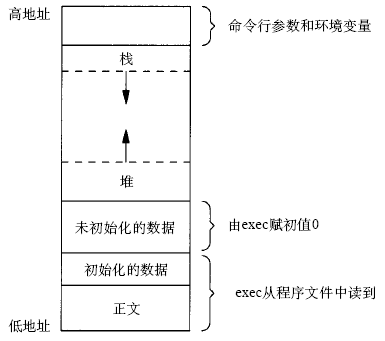
е…ҲеүҚи®ІиҝҮпјҢexecзі»з»ҹи°ғз”Ёжү§иЎҢж–°зЁӢеәҸж—¶дјҡжҠҠе‘Ҫд»ӨиЎҢеҸӮж•°е’ҢзҺҜеўғеҸҳйҮҸиЎЁдј йҖ’з»ҷmainеҮҪж•°пјҢе®ғ们еңЁж•ҙдёӘиҝӣзЁӢең°еқҖз©әй—ҙдёӯзҡ„дҪҚзҪ®еҰӮдёӢеӣҫжүҖзӨәгҖӮ
еӣҫВ 30.2.В иҝӣзЁӢең°еқҖз©әй—ҙ
е’Ңе‘Ҫд»ӨиЎҢеҸӮж•°argvзұ»дјјпјҢзҺҜеўғеҸҳйҮҸиЎЁд№ҹжҳҜдёҖз»„еӯ—з¬ҰдёІпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
еӣҫВ 30.3.В зҺҜеўғеҸҳйҮҸ
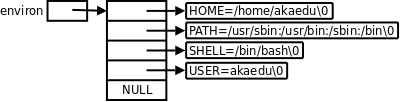
libcдёӯе®ҡд№үзҡ„е…ЁеұҖеҸҳйҮҸenvironжҢҮеҗ‘зҺҜеўғеҸҳйҮҸиЎЁпјҢenvironжІЎжңүеҢ…еҗ«еңЁд»»дҪ•еӨҙж–Ү件дёӯпјҢжүҖд»ҘеңЁдҪҝз”Ёж—¶иҰҒз”ЁexternеЈ°жҳҺгҖӮдҫӢеҰӮпјҡ
дҫӢВ 30.1.В жү“еҚ°зҺҜеўғеҸҳйҮҸ
#include <stdio.h>
int main(void)
{
extern char **environ;
int i;
for(i=0; environ[i]!=NULL; i++)
printf("%s
", environ[i]);
return 0;
}
жү§иЎҢз»“жһңдёә
$ ./a.out
SSH_AGENT_PID=5717
SHELL=/bin/bash
DESKTOP_STARTUP_ID=
TERM=xterm
...
з”ұдәҺзҲ¶иҝӣзЁӢеңЁи°ғз”ЁforkеҲӣе»әеӯҗиҝӣзЁӢж—¶дјҡжҠҠиҮӘе·ұзҡ„зҺҜеўғеҸҳйҮҸиЎЁд№ҹеӨҚеҲ¶з»ҷеӯҗиҝӣзЁӢпјҢжүҖд»Ҙa.outжү“еҚ°зҡ„зҺҜеўғеҸҳйҮҸе’ҢShellиҝӣзЁӢзҡ„зҺҜеўғеҸҳйҮҸжҳҜзӣёеҗҢзҡ„гҖӮ
жҢүз…§жғҜдҫӢпјҢзҺҜеўғеҸҳйҮҸеӯ—з¬ҰдёІйғҪжҳҜname=valueиҝҷж ·зҡ„еҪўејҸпјҢеӨ§еӨҡж•°nameз”ұеӨ§еҶҷеӯ—жҜҚеҠ дёӢеҲ’зәҝз»„жҲҗпјҢдёҖиҲ¬жҠҠnameзҡ„йғЁеҲҶеҸ«еҒҡзҺҜеўғеҸҳйҮҸпјҢvalueзҡ„йғЁеҲҶеҲҷжҳҜзҺҜеўғеҸҳйҮҸзҡ„еҖјгҖӮзҺҜеўғеҸҳйҮҸе®ҡд№үдәҶиҝӣзЁӢзҡ„иҝҗиЎҢзҺҜеўғпјҢдёҖдәӣжҜ”иҫғйҮҚиҰҒзҡ„зҺҜеўғеҸҳйҮҸзҡ„еҗ«д№үеҰӮдёӢпјҡ
PATH
еҸҜжү§иЎҢж–Ү件зҡ„жҗңзҙўи·Ҝеҫ„гҖӮlsе‘Ҫд»Өд№ҹжҳҜдёҖдёӘзЁӢеәҸпјҢжү§иЎҢе®ғдёҚйңҖиҰҒжҸҗдҫӣе®Ңж•ҙзҡ„и·Ҝеҫ„еҗҚ/bin/lsпјҢ然иҖҢйҖҡеёёжҲ‘们жү§иЎҢеҪ“еүҚзӣ®еҪ•дёӢзҡ„зЁӢеәҸa.outеҚҙйңҖиҰҒжҸҗдҫӣе®Ңж•ҙзҡ„и·Ҝеҫ„еҗҚ./a.outпјҢиҝҷжҳҜеӣ дёәPATHзҺҜеўғеҸҳйҮҸзҡ„еҖјйҮҢйқўеҢ…еҗ«дәҶlsе‘Ҫд»ӨжүҖеңЁзҡ„зӣ®еҪ•/binпјҢеҚҙдёҚеҢ…еҗ«a.outжүҖеңЁзҡ„зӣ®еҪ•гҖӮPATHзҺҜеўғеҸҳйҮҸзҡ„еҖјеҸҜд»ҘеҢ…еҗ«еӨҡдёӘзӣ®еҪ•пјҢз”Ё:еҸ·йҡ”ејҖгҖӮеңЁShellдёӯз”Ёechoе‘Ҫд»ӨеҸҜд»ҘжҹҘзңӢиҝҷдёӘзҺҜеўғеҸҳйҮҸзҡ„еҖјпјҡ
$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games
SHELL
еҪ“еүҚShellпјҢе®ғзҡ„еҖјйҖҡеёёжҳҜ/bin/bashгҖӮ
TERM
еҪ“еүҚз»Ҳз«Ҝзұ»еһӢпјҢеңЁеӣҫеҪўз•Ңйқўз»Ҳз«ҜдёӢе®ғзҡ„еҖјйҖҡеёёжҳҜxtermпјҢз»Ҳз«Ҝзұ»еһӢеҶіе®ҡдәҶдёҖдәӣзЁӢеәҸзҡ„иҫ“еҮәжҳҫзӨәж–№ејҸпјҢжҜ”еҰӮеӣҫеҪўз•Ңйқўз»Ҳз«ҜеҸҜд»ҘжҳҫзӨәжұүеӯ—пјҢиҖҢеӯ—з¬Ұз»Ҳз«ҜдёҖиҲ¬дёҚиЎҢгҖӮ
LANG
иҜӯиЁҖе’ҢlocaleпјҢеҶіе®ҡдәҶеӯ—з¬Ұзј–з Ғд»ҘеҸҠж—¶й—ҙгҖҒиҙ§еёҒзӯүдҝЎжҒҜзҡ„жҳҫзӨәж јејҸгҖӮ
HOME
еҪ“еүҚз”ЁжҲ·дё»зӣ®еҪ•зҡ„и·Ҝеҫ„пјҢеҫҲеӨҡзЁӢеәҸйңҖиҰҒеңЁдё»зӣ®еҪ•дёӢдҝқеӯҳй…ҚзҪ®ж–Ү件пјҢдҪҝеҫ—жҜҸдёӘз”ЁжҲ·еңЁиҝҗиЎҢиҜҘзЁӢеәҸж—¶йғҪжңүиҮӘе·ұзҡ„дёҖеҘ—й…ҚзҪ®гҖӮ
з”ЁenvironжҢҮй’ҲеҸҜд»ҘжҹҘзңӢжүҖжңүзҺҜеўғеҸҳйҮҸеӯ—з¬ҰдёІпјҢдҪҶжҳҜдёҚеӨҹж–№дҫҝпјҢеҰӮжһңз»ҷеҮәnameиҰҒеңЁзҺҜеўғеҸҳйҮҸиЎЁдёӯжҹҘжүҫе®ғеҜ№еә”зҡ„valueпјҢеҸҜд»Ҙз”ЁgetenvеҮҪж•°гҖӮ
#include <stdlib.h>
char *getenv(const char *name);
getenvзҡ„иҝ”еӣһеҖјжҳҜжҢҮеҗ‘valueзҡ„жҢҮй’ҲпјҢиӢҘжңӘжүҫеҲ°еҲҷдёәNULLгҖӮ
дҝ®ж”№зҺҜеўғеҸҳйҮҸеҸҜд»Ҙз”Ёд»ҘдёӢеҮҪж•°
#include <stdlib.h>
int setenv(const char *name, const char *value, int rewrite);
void unsetenv(const char *name);
putenvе’ҢsetenvеҮҪж•°иӢҘжҲҗеҠҹеҲҷиҝ”еӣһдёә0пјҢиӢҘеҮәй”ҷеҲҷиҝ”еӣһйқһ0гҖӮ
setenvе°ҶзҺҜеўғеҸҳйҮҸnameзҡ„еҖји®ҫзҪ®дёәvalueгҖӮеҰӮжһңе·ІеӯҳеңЁзҺҜеўғеҸҳйҮҸnameпјҢйӮЈд№Ҳ
иӢҘrewriteйқһ0пјҢеҲҷиҰҶзӣ–еҺҹжқҘзҡ„е®ҡд№үпјӣ
иӢҘrewriteдёә0пјҢеҲҷдёҚиҰҶзӣ–еҺҹжқҘзҡ„е®ҡд№үпјҢд№ҹдёҚиҝ”еӣһй”ҷиҜҜгҖӮ
unsetenvеҲ йҷӨnameзҡ„е®ҡд№үгҖӮеҚідҪҝnameжІЎжңүе®ҡд№үд№ҹдёҚиҝ”еӣһй”ҷиҜҜгҖӮ
дҫӢВ 30.2.В дҝ®ж”№зҺҜеўғеҸҳйҮҸ
#include <stdlib.h>
#include <stdio.h>
int main(void)
{
printf("PATH=%s
", getenv("PATH"));
setenv("PATH", "hello", 1);
printf("PATH=%s
", getenv("PATH"));
return 0;
}
$ ./a.out
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games
PATH=hello
$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games
еҸҜд»ҘзңӢеҮәпјҢShellиҝӣзЁӢзҡ„зҺҜеўғеҸҳйҮҸPATHдј з»ҷдәҶa.outпјҢ然еҗҺa.outдҝ®ж”№дәҶPATHзҡ„еҖјпјҢеңЁa.outдёӯиғҪжү“еҚ°еҮәдҝ®ж”№еҗҺзҡ„еҖјпјҢдҪҶеңЁShellиҝӣзЁӢдёӯPATHзҡ„еҖјжІЎеҸҳгҖӮзҲ¶иҝӣзЁӢеңЁеҲӣе»әеӯҗиҝӣзЁӢж—¶дјҡеӨҚеҲ¶дёҖд»ҪзҺҜеўғеҸҳйҮҸз»ҷеӯҗиҝӣзЁӢпјҢдҪҶжӯӨеҗҺдәҢиҖ…зҡ„зҺҜеўғеҸҳйҮҸдә’дёҚеҪұе“ҚгҖӮ
3.В иҝӣзЁӢжҺ§еҲ¶
3.1.В forkеҮҪж•°
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
forkи°ғз”ЁеӨұиҙҘеҲҷиҝ”еӣһ-1пјҢи°ғз”ЁжҲҗеҠҹзҡ„иҝ”еӣһеҖји§ҒдёӢйқўзҡ„и§ЈйҮҠгҖӮжҲ‘们йҖҡиҝҮдёҖдёӘдҫӢеӯҗжқҘзҗҶи§ЈforkжҳҜжҖҺж ·еҲӣе»әж–°иҝӣзЁӢзҡ„гҖӮ
дҫӢВ 30.3.В fork
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
pid_t pid;
char *message;
int n;
pid = fork();
if (pid < 0) {
perror("fork failed");
exit(1);
}
if (pid == 0) {
message = "This is the child
";
n = 6;
} else {
message = "This is the parent
";
n = 3;
}
for(; n > 0; n--) {
printf(message);
sleep(1);
}
return 0;
}
$ ./a.out
This is the child
This is the parent
This is the child
This is the parent
This is the child
This is the parent
This is the child
$ This is the child
This is the child
иҝҷдёӘзЁӢеәҸзҡ„иҝҗиЎҢиҝҮзЁӢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
еӣҫВ 30.4.В fork
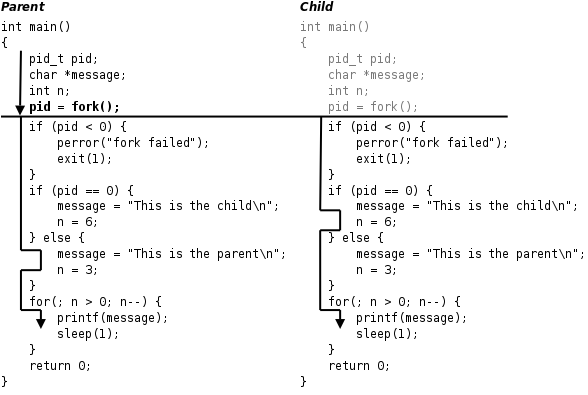
зҲ¶иҝӣзЁӢеҲқе§ӢеҢ–гҖӮ
зҲ¶иҝӣзЁӢи°ғз”Ё
forkпјҢиҝҷжҳҜдёҖдёӘзі»з»ҹи°ғз”ЁпјҢеӣ жӯӨиҝӣе…ҘеҶ…ж ёгҖӮеҶ…ж ёж №жҚ®зҲ¶иҝӣзЁӢеӨҚеҲ¶еҮәдёҖдёӘеӯҗиҝӣзЁӢпјҢзҲ¶иҝӣзЁӢе’ҢеӯҗиҝӣзЁӢзҡ„PCBдҝЎжҒҜзӣёеҗҢпјҢз”ЁжҲ·жҖҒд»Јз Ғе’Ңж•°жҚ®д№ҹзӣёеҗҢгҖӮеӣ жӯӨпјҢеӯҗиҝӣзЁӢзҺ°еңЁзҡ„зҠ¶жҖҒзңӢиө·жқҘе’ҢзҲ¶иҝӣзЁӢдёҖж ·пјҢеҒҡе®ҢдәҶеҲқе§ӢеҢ–пјҢеҲҡи°ғз”ЁдәҶ
forkиҝӣе…ҘеҶ…ж ёпјҢиҝҳжІЎжңүд»ҺеҶ…ж ёиҝ”еӣһгҖӮзҺ°еңЁжңүдёӨдёӘдёҖжЁЎдёҖж ·зҡ„иҝӣзЁӢзңӢиө·жқҘйғҪи°ғз”ЁдәҶ
forkиҝӣе…ҘеҶ…ж ёзӯүеҫ…д»ҺеҶ…ж ёиҝ”еӣһпјҲе®һйҷ…дёҠforkеҸӘи°ғз”ЁдәҶдёҖж¬ЎпјүпјҢжӯӨеӨ–зі»з»ҹдёӯиҝҳжңүеҫҲеӨҡеҲ«зҡ„иҝӣзЁӢд№ҹзӯүеҫ…д»ҺеҶ…ж ёиҝ”еӣһгҖӮжҳҜзҲ¶иҝӣзЁӢе…Ҳиҝ”еӣһиҝҳжҳҜеӯҗиҝӣзЁӢе…Ҳиҝ”еӣһпјҢиҝҳжҳҜиҝҷдёӨдёӘиҝӣзЁӢйғҪзӯүеҫ…пјҢе…ҲеҺ»и°ғеәҰжү§иЎҢеҲ«зҡ„иҝӣзЁӢпјҢиҝҷйғҪдёҚдёҖе®ҡпјҢеҸ–еҶідәҺеҶ…ж ёзҡ„и°ғеәҰз®—жі•гҖӮеҰӮжһңжҹҗдёӘж—¶еҲ»зҲ¶иҝӣзЁӢиў«и°ғеәҰжү§иЎҢдәҶпјҢд»ҺеҶ…ж ёиҝ”еӣһеҗҺе°ұд»Һ
forkеҮҪж•°иҝ”еӣһпјҢдҝқеӯҳеңЁеҸҳйҮҸpidдёӯзҡ„иҝ”еӣһеҖјжҳҜеӯҗиҝӣзЁӢзҡ„idпјҢжҳҜдёҖдёӘеӨ§дәҺ0зҡ„ж•ҙж•°пјҢеӣ жӯӨжү§дёӢйқўзҡ„elseеҲҶж”ҜпјҢ然еҗҺжү§иЎҢforеҫӘзҺҜпјҢжү“еҚ°"This is the parent "дёүж¬Ўд№ӢеҗҺз»ҲжӯўгҖӮеҰӮжһңжҹҗдёӘж—¶еҲ»еӯҗиҝӣзЁӢиў«и°ғеәҰжү§иЎҢдәҶпјҢд»ҺеҶ…ж ёиҝ”еӣһеҗҺе°ұд»Һ
forkеҮҪж•°иҝ”еӣһпјҢдҝқеӯҳеңЁеҸҳйҮҸpidдёӯзҡ„иҝ”еӣһеҖјжҳҜ0пјҢеӣ жӯӨжү§иЎҢдёӢйқўзҡ„if (pid == 0)еҲҶж”ҜпјҢ然еҗҺжү§иЎҢforеҫӘзҺҜпјҢжү“еҚ°"This is the child "е…ӯж¬Ўд№ӢеҗҺз»ҲжӯўгҖӮforkи°ғз”ЁжҠҠзҲ¶иҝӣзЁӢзҡ„ж•°жҚ®еӨҚеҲ¶дёҖд»Ҫз»ҷеӯҗиҝӣзЁӢпјҢдҪҶжӯӨеҗҺдәҢиҖ…дә’дёҚеҪұе“ҚпјҢеңЁиҝҷдёӘдҫӢеӯҗдёӯпјҢforkи°ғз”Ёд№ӢеҗҺзҲ¶иҝӣзЁӢе’ҢеӯҗиҝӣзЁӢзҡ„еҸҳйҮҸmessageе’Ңnиў«иөӢдәҲдёҚеҗҢзҡ„еҖјпјҢдә’дёҚеҪұе“ҚгҖӮзҲ¶иҝӣзЁӢжҜҸжү“еҚ°дёҖжқЎж¶ҲжҒҜе°ұзқЎзң 1з§’пјҢиҝҷж—¶еҶ…ж ёи°ғеәҰеҲ«зҡ„иҝӣзЁӢжү§иЎҢпјҢеңЁ1з§’иҝҷд№Ҳй•ҝзҡ„й—ҙйҡҷйҮҢпјҲеҜ№дәҺи®Ўз®—жңәжқҘиҜҙ1з§’еҫҲй•ҝдәҶпјүеӯҗиҝӣзЁӢеҫҲжңүеҸҜиғҪиў«и°ғеәҰеҲ°гҖӮеҗҢж ·ең°пјҢеӯҗиҝӣзЁӢжҜҸжү“еҚ°дёҖжқЎж¶ҲжҒҜе°ұзқЎзң 1з§’пјҢеңЁиҝҷ1з§’жңҹй—ҙзҲ¶иҝӣзЁӢд№ҹеҫҲжңүеҸҜиғҪиў«и°ғеәҰеҲ°гҖӮжүҖд»ҘзЁӢеәҸиҝҗиЎҢзҡ„з»“жһңеҹәжң¬дёҠжҳҜзҲ¶еӯҗиҝӣзЁӢдәӨжӣҝжү“еҚ°пјҢдҪҶиҝҷд№ҹдёҚжҳҜдёҖе®ҡзҡ„пјҢеҸ–еҶідәҺзі»з»ҹдёӯе…¶е®ғиҝӣзЁӢзҡ„иҝҗиЎҢжғ…еҶөе’ҢеҶ…ж ёзҡ„и°ғеәҰз®—жі•пјҢеҰӮжһңзі»з»ҹдёӯе…¶е®ғиҝӣзЁӢйқһеёёз№ҒеҝҷеҲҷжңүеҸҜиғҪи§ӮеҜҹеҲ°дёҚеҗҢзҡ„з»“жһңгҖӮеҸҰеӨ–пјҢиҜ»иҖ…д№ҹеҸҜд»ҘжҠҠ
sleep(1);еҺ»жҺүзңӢзЁӢеәҸзҡ„иҝҗиЎҢз»“жһңеҰӮдҪ•гҖӮиҝҷдёӘзЁӢеәҸжҳҜеңЁShellдёӢиҝҗиЎҢзҡ„пјҢеӣ жӯӨShellиҝӣзЁӢжҳҜзҲ¶иҝӣзЁӢзҡ„зҲ¶иҝӣзЁӢгҖӮзҲ¶иҝӣзЁӢиҝҗиЎҢж—¶ShellиҝӣзЁӢеӨ„дәҺзӯүеҫ…зҠ¶жҖҒпјҲ第 3.3В иҠӮ вҖңwaitе’ҢwaitpidеҮҪж•°вҖқдјҡи®ІеҲ°иҝҷз§Қзӯүеҫ…жҳҜжҖҺд№Ҳе®һзҺ°зҡ„пјүпјҢеҪ“зҲ¶иҝӣзЁӢз»Ҳжӯўж—¶ShellиҝӣзЁӢи®Өдёәе‘Ҫд»Өжү§иЎҢз»“жқҹдәҶпјҢдәҺжҳҜжү“еҚ°ShellжҸҗзӨәз¬ҰпјҢиҖҢдәӢе®һдёҠеӯҗиҝӣзЁӢиҝҷж—¶иҝҳжІЎз»“жқҹпјҢжүҖд»ҘеӯҗиҝӣзЁӢзҡ„ж¶ҲжҒҜжү“еҚ°еҲ°дәҶShellжҸҗзӨәз¬ҰеҗҺйқўгҖӮжңҖеҗҺе…үж ҮеҒңеңЁ
This is the childзҡ„дёӢдёҖиЎҢпјҢиҝҷж—¶з”ЁжҲ·д»Қ然еҸҜд»Ҙж•Іе‘Ҫд»ӨпјҢеҚідҪҝе‘Ҫд»ӨдёҚжҳҜзҙ§и·ҹеңЁжҸҗзӨәз¬ҰеҗҺйқўпјҢShellд№ҹиғҪжӯЈзЎ®иҜ»еҸ–гҖӮ
forkеҮҪж•°зҡ„зү№зӮ№жҰӮжӢ¬иө·жқҘе°ұжҳҜвҖңи°ғз”ЁдёҖж¬ЎпјҢиҝ”еӣһдёӨж¬ЎвҖқпјҢеңЁзҲ¶иҝӣзЁӢдёӯи°ғз”ЁдёҖж¬ЎпјҢеңЁзҲ¶иҝӣзЁӢе’ҢеӯҗиҝӣзЁӢдёӯеҗ„иҝ”еӣһдёҖж¬ЎгҖӮд»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮәпјҢдёҖејҖе§ӢжҳҜдёҖдёӘжҺ§еҲ¶жөҒзЁӢпјҢи°ғз”Ёforkд№ӢеҗҺеҸ‘з”ҹдәҶеҲҶеҸүпјҢеҸҳжҲҗдёӨдёӘжҺ§еҲ¶жөҒзЁӢпјҢиҝҷд№ҹе°ұжҳҜвҖңforkвҖқпјҲеҲҶеҸүпјүиҝҷдёӘеҗҚеӯ—зҡ„з”ұжқҘдәҶгҖӮеӯҗиҝӣзЁӢдёӯforkзҡ„иҝ”еӣһеҖјжҳҜ0пјҢиҖҢзҲ¶иҝӣзЁӢдёӯforkзҡ„иҝ”еӣһеҖјеҲҷжҳҜеӯҗиҝӣзЁӢзҡ„idпјҲд»Һж №жң¬дёҠиҜҙforkжҳҜд»ҺеҶ…ж ёиҝ”еӣһзҡ„пјҢеҶ…ж ёиҮӘжңүеҠһжі•и®©зҲ¶иҝӣзЁӢе’ҢеӯҗиҝӣзЁӢиҝ”еӣһдёҚеҗҢзҡ„еҖјпјүпјҢиҝҷж ·еҪ“forkеҮҪж•°иҝ”еӣһеҗҺпјҢзЁӢеәҸе‘ҳеҸҜд»Ҙж №жҚ®иҝ”еӣһеҖјзҡ„дёҚеҗҢи®©зҲ¶иҝӣзЁӢе’ҢеӯҗиҝӣзЁӢжү§иЎҢдёҚеҗҢзҡ„д»Јз ҒгҖӮ
forkзҡ„иҝ”еӣһеҖјиҝҷж ·и§„е®ҡжҳҜжңүйҒ“зҗҶзҡ„гҖӮforkеңЁеӯҗиҝӣзЁӢдёӯиҝ”еӣһ0пјҢеӯҗиҝӣзЁӢд»ҚеҸҜд»Ҙи°ғз”ЁgetpidеҮҪж•°еҫ—еҲ°иҮӘе·ұзҡ„иҝӣзЁӢidпјҢд№ҹеҸҜд»Ҙи°ғз”ЁgetppidеҮҪж•°еҫ—еҲ°зҲ¶иҝӣзЁӢзҡ„idгҖӮеңЁзҲ¶иҝӣзЁӢдёӯз”ЁgetpidеҸҜд»Ҙеҫ—еҲ°иҮӘе·ұзҡ„иҝӣзЁӢidпјҢ然иҖҢиҰҒжғіеҫ—еҲ°еӯҗиҝӣзЁӢзҡ„idпјҢеҸӘжңүе°Ҷforkзҡ„иҝ”еӣһеҖји®°еҪ•дёӢжқҘпјҢеҲ«ж— е®ғжі•гҖӮ
forkзҡ„еҸҰдёҖдёӘзү№жҖ§жҳҜжүҖжңүз”ұзҲ¶иҝӣзЁӢжү“ејҖзҡ„жҸҸиҝ°з¬ҰйғҪиў«еӨҚеҲ¶еҲ°еӯҗиҝӣзЁӢдёӯгҖӮзҲ¶гҖҒеӯҗиҝӣзЁӢдёӯзӣёеҗҢзј–еҸ·зҡ„ж–Ү件жҸҸиҝ°з¬ҰеңЁеҶ…ж ёдёӯжҢҮеҗ‘еҗҢдёҖдёӘfileз»“жһ„дҪ“пјҢд№ҹе°ұжҳҜиҜҙпјҢfileз»“жһ„дҪ“зҡ„еј•з”Ёи®Ўж•°иҰҒеўһеҠ гҖӮ
з”Ёgdbи°ғиҜ•еӨҡиҝӣзЁӢзҡ„зЁӢеәҸдјҡйҒҮеҲ°еӣ°йҡҫпјҢgdbеҸӘиғҪи·ҹиёӘдёҖдёӘиҝӣзЁӢпјҲй»ҳи®ӨжҳҜи·ҹиёӘзҲ¶иҝӣзЁӢпјүпјҢиҖҢдёҚиғҪеҗҢж—¶и·ҹиёӘеӨҡдёӘиҝӣзЁӢпјҢдҪҶеҸҜд»Ҙи®ҫзҪ®gdbеңЁforkд№ӢеҗҺи·ҹиёӘзҲ¶иҝӣзЁӢиҝҳжҳҜеӯҗиҝӣзЁӢгҖӮд»ҘдёҠйқўзҡ„зЁӢеәҸдёәдҫӢпјҡ
$ gcc main.c -g
$ gdb a.out
GNU gdb 6.8-debian
Copyright (C) 2008 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "i486-linux-gnu"...
(gdb) l
2 #include <unistd.h>
3 #include <stdio.h>
4 #include <stdlib.h>
5
6 int main(void)
7 {
8 pid_t pid;
9 char *message;
10 int n;
11 pid = fork();
(gdb)
12 if(pid<0) {
13 perror("fork failed");
14 exit(1);
15 }
16 if(pid==0) {
17 message = "This is the child
";
18 n = 6;
19 } else {
20 message = "This is the parent
";
21 n = 3;
(gdb) b 17
Breakpoint 1 at 0x8048481: file main.c, line 17.
(gdb) set follow-fork-mode child
(gdb) r
Starting program: /home/akaedu/a.out
This is the parent
[Switching to process 30725]
Breakpoint 1, main () at main.c:17
17 message = "This is the child
";
(gdb) This is the parent
This is the parent
set follow-fork-mode childе‘Ҫд»Өи®ҫзҪ®gdbеңЁforkд№ӢеҗҺи·ҹиёӘеӯҗиҝӣзЁӢпјҲset follow-fork-mode parentеҲҷжҳҜи·ҹиёӘзҲ¶иҝӣзЁӢпјүпјҢ然еҗҺз”Ёrunе‘Ҫд»ӨпјҢзңӢеҲ°зҡ„зҺ°иұЎжҳҜзҲ¶иҝӣзЁӢдёҖзӣҙеңЁиҝҗиЎҢпјҢеңЁ(gdb)жҸҗзӨәз¬ҰдёӢжү“еҚ°ж¶ҲжҒҜпјҢиҖҢеӯҗиҝӣзЁӢиў«е…ҲеүҚи®ҫзҡ„ж–ӯзӮ№жү“ж–ӯдәҶгҖӮ
3.2.В execеҮҪж•°
з”ЁforkеҲӣе»әеӯҗиҝӣзЁӢеҗҺжү§иЎҢзҡ„жҳҜе’ҢзҲ¶иҝӣзЁӢзӣёеҗҢзҡ„зЁӢеәҸпјҲдҪҶжңүеҸҜиғҪжү§иЎҢдёҚеҗҢзҡ„д»Јз ҒеҲҶж”ҜпјүпјҢеӯҗиҝӣзЁӢеҫҖеҫҖиҰҒи°ғз”ЁдёҖз§ҚexecеҮҪж•°д»Ҙжү§иЎҢеҸҰдёҖдёӘзЁӢеәҸгҖӮеҪ“иҝӣзЁӢи°ғз”ЁдёҖз§ҚexecеҮҪж•°ж—¶пјҢиҜҘиҝӣзЁӢзҡ„з”ЁжҲ·з©әй—ҙд»Јз Ғе’Ңж•°жҚ®е®Ңе…Ёиў«ж–°зЁӢеәҸжӣҝжҚўпјҢд»Һж–°зЁӢеәҸзҡ„еҗҜеҠЁдҫӢзЁӢејҖе§Ӣжү§иЎҢгҖӮи°ғз”Ёexec并дёҚеҲӣе»әж–°иҝӣзЁӢпјҢжүҖд»Ҙи°ғз”ЁexecеүҚеҗҺиҜҘиҝӣзЁӢзҡ„id并жңӘж”№еҸҳгҖӮ
е…¶е®һжңүе…ӯз§Қд»ҘexecејҖеӨҙзҡ„еҮҪж•°пјҢз»ҹз§°execеҮҪж•°пјҡ
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
иҝҷдәӣеҮҪж•°еҰӮжһңи°ғз”ЁжҲҗеҠҹеҲҷеҠ иҪҪж–°зҡ„зЁӢеәҸд»ҺеҗҜеҠЁд»Јз ҒејҖе§Ӣжү§иЎҢпјҢдёҚеҶҚиҝ”еӣһпјҢеҰӮжһңи°ғз”ЁеҮәй”ҷеҲҷиҝ”еӣһ-1пјҢжүҖд»ҘexecеҮҪж•°еҸӘжңүеҮәй”ҷзҡ„иҝ”еӣһеҖјиҖҢжІЎжңүжҲҗеҠҹзҡ„иҝ”еӣһеҖјгҖӮ
иҝҷдәӣеҮҪж•°еҺҹеһӢзңӢиө·жқҘеҫҲе®№жҳ“ж··пјҢдҪҶеҸӘиҰҒжҺҢжҸЎдәҶ规еҫӢе°ұеҫҲеҘҪи®°гҖӮдёҚеёҰеӯ—жҜҚpпјҲиЎЁзӨәpathпјүзҡ„execеҮҪ数第дёҖдёӘеҸӮж•°еҝ…йЎ»жҳҜзЁӢеәҸзҡ„зӣёеҜ№и·Ҝеҫ„жҲ–з»қеҜ№и·Ҝеҫ„пјҢдҫӢеҰӮ"/bin/ls"жҲ–"./a.out"пјҢиҖҢдёҚиғҪжҳҜ"ls"жҲ–"a.out"гҖӮеҜ№дәҺеёҰеӯ—жҜҚpзҡ„еҮҪж•°пјҡ
еҰӮжһңеҸӮж•°дёӯеҢ…еҗ«/пјҢеҲҷе°Ҷе…¶и§Ҷдёәи·Ҝеҫ„еҗҚгҖӮ
еҗҰеҲҷи§ҶдёәдёҚеёҰи·Ҝеҫ„зҡ„зЁӢеәҸеҗҚпјҢеңЁ
PATHзҺҜеўғеҸҳйҮҸзҡ„зӣ®еҪ•еҲ—иЎЁдёӯжҗңзҙўиҝҷдёӘзЁӢеәҸгҖӮ
еёҰжңүеӯ—жҜҚlпјҲиЎЁзӨәlistпјүзҡ„execеҮҪж•°иҰҒжұӮе°Ҷж–°зЁӢеәҸзҡ„жҜҸдёӘе‘Ҫд»ӨиЎҢеҸӮж•°йғҪеҪ“дҪңдёҖдёӘеҸӮж•°дј з»ҷе®ғпјҢе‘Ҫд»ӨиЎҢеҸӮж•°зҡ„дёӘж•°жҳҜеҸҜеҸҳзҡ„пјҢеӣ жӯӨеҮҪж•°еҺҹеһӢдёӯжңү...пјҢ...дёӯзҡ„жңҖеҗҺдёҖдёӘеҸҜеҸҳеҸӮж•°еә”иҜҘжҳҜNULLпјҢиө·sentinelзҡ„дҪңз”ЁгҖӮеҜ№дәҺеёҰжңүеӯ—жҜҚvпјҲиЎЁзӨәvectorпјүзҡ„еҮҪж•°пјҢеҲҷеә”иҜҘе…Ҳжһ„йҖ дёҖдёӘжҢҮеҗ‘еҗ„еҸӮж•°зҡ„жҢҮй’Ҳж•°з»„пјҢ然еҗҺе°ҶиҜҘж•°з»„зҡ„йҰ–ең°еқҖеҪ“дҪңеҸӮж•°дј з»ҷе®ғпјҢж•°з»„дёӯзҡ„жңҖеҗҺдёҖдёӘжҢҮй’Ҳд№ҹеә”иҜҘжҳҜNULLпјҢе°ұеғҸmainеҮҪж•°зҡ„argvеҸӮж•°жҲ–иҖ…зҺҜеўғеҸҳйҮҸиЎЁдёҖж ·гҖӮ
еҜ№дәҺд»ҘeпјҲиЎЁзӨәenvironmentпјүз»“е°ҫзҡ„execеҮҪж•°пјҢеҸҜд»ҘжҠҠдёҖд»Ҫж–°зҡ„зҺҜеўғеҸҳйҮҸиЎЁдј з»ҷе®ғпјҢе…¶д»–execеҮҪж•°д»ҚдҪҝз”ЁеҪ“еүҚзҡ„зҺҜеўғеҸҳйҮҸиЎЁжү§иЎҢж–°зЁӢеәҸгҖӮ
execи°ғз”ЁдёҫдҫӢеҰӮдёӢпјҡ
char *const ps_argv[] ={"ps", "-o", "pid,ppid,pgrp,session,tpgid,comm", NULL};
char *const ps_envp[] ={"PATH=/bin:/usr/bin", "TERM=console", NULL};
execl("/bin/ps", "ps", "-o", "pid,ppid,pgrp,session,tpgid,comm", NULL);
execv("/bin/ps", ps_argv);
execle("/bin/ps", "ps", "-o", "pid,ppid,pgrp,session,tpgid,comm", NULL, ps_envp);
execve("/bin/ps", ps_argv, ps_envp);
execlp("ps", "ps", "-o", "pid,ppid,pgrp,session,tpgid,comm", NULL);
execvp("ps", ps_argv);
дәӢе®һдёҠпјҢеҸӘжңүexecveжҳҜзңҹжӯЈзҡ„зі»з»ҹи°ғз”ЁпјҢе…¶е®ғдә”дёӘеҮҪж•°жңҖз»ҲйғҪи°ғз”ЁexecveпјҢжүҖд»ҘexecveеңЁmanжүӢеҶҢ第2иҠӮпјҢе…¶е®ғеҮҪж•°еңЁmanжүӢеҶҢ第3иҠӮгҖӮиҝҷдәӣеҮҪж•°д№Ӣй—ҙзҡ„е…ізі»еҰӮдёӢеӣҫжүҖзӨәгҖӮ
еӣҫВ 30.5.В execеҮҪж•°ж—Ҹ
дёҖдёӘе®Ңж•ҙзҡ„дҫӢеӯҗпјҡ
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
execlp("ps", "ps", "-o", "pid,ppid,pgrp,session,tpgid,comm", NULL);
perror("exec ps");
exit(1);
}
жү§иЎҢжӯӨзЁӢеәҸеҲҷеҫ—еҲ°пјҡ
$ ./a.out
PID PPID PGRP SESS TPGID COMMAND
6614 6608 6614 6614 7199 bash
7199 6614 7199 6614 7199 ps
з”ұдәҺexecеҮҪж•°еҸӘжңүй”ҷиҜҜиҝ”еӣһеҖјпјҢеҸӘиҰҒиҝ”еӣһдәҶдёҖе®ҡжҳҜеҮәй”ҷдәҶпјҢжүҖд»ҘдёҚйңҖиҰҒеҲӨж–ӯе®ғзҡ„иҝ”еӣһеҖјпјҢзӣҙжҺҘеңЁеҗҺйқўи°ғз”ЁperrorеҚіеҸҜгҖӮжіЁж„ҸеңЁи°ғз”Ёexeclpж—¶дј дәҶдёӨдёӘ"ps"еҸӮж•°пјҢ第дёҖдёӘ"ps"жҳҜзЁӢеәҸеҗҚпјҢexeclpеҮҪж•°иҰҒеңЁPATHзҺҜеўғеҸҳйҮҸдёӯжүҫеҲ°иҝҷдёӘзЁӢеәҸ并жү§иЎҢе®ғпјҢиҖҢ第дәҢдёӘ"ps"жҳҜ第дёҖдёӘе‘Ҫд»ӨиЎҢеҸӮж•°пјҢexeclpеҮҪ数并дёҚе…іеҝғе®ғзҡ„еҖјпјҢеҸӘжҳҜз®ҖеҚ•ең°жҠҠе®ғдј з»ҷpsзЁӢеәҸпјҢpsзЁӢеәҸеҸҜд»ҘйҖҡиҝҮmainеҮҪж•°зҡ„argv[0]еҸ–еҲ°иҝҷдёӘеҸӮж•°гҖӮ
и°ғз”ЁexecеҗҺпјҢеҺҹжқҘжү“ејҖзҡ„ж–Ү件жҸҸиҝ°з¬Ұд»Қ然жҳҜжү“ејҖзҡ„[[37](#ftn.id2867112)]гҖӮеҲ©з”ЁиҝҷдёҖзӮ№еҸҜд»Ҙе®һзҺ°I/OйҮҚе®ҡеҗ‘гҖӮе…ҲзңӢдёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗпјҢжҠҠж ҮеҮҶиҫ“е…ҘиҪ¬жҲҗеӨ§еҶҷ然еҗҺжү“еҚ°еҲ°ж ҮеҮҶиҫ“еҮәпјҡ
дҫӢВ 30.4.В upper
/* upper.c */
#include <stdio.h>
int main(void)
{
int ch;
while((ch = getchar()) != EOF) {
putchar(toupper(ch));
}
return 0;
}
иҝҗиЎҢз»“жһңеҰӮдёӢпјҡ
$ ./upper
hello THERE
HELLO THERE
пјҲжҢүCtrl-DиЎЁзӨәEOFпјү
$
дҪҝз”ЁShellйҮҚе®ҡеҗ‘пјҡ
$ cat file.txt
this is the file, file.txt, it is all lower case.
$ ./upper < file.txt
THIS IS THE FILE, FILE.TXT, IT IS ALL LOWER CASE.
еҰӮжһңеёҢжңӣжҠҠеҫ…иҪ¬жҚўзҡ„ж–Ү件еҗҚж”ҫеңЁе‘Ҫд»ӨиЎҢеҸӮж•°дёӯпјҢиҖҢдёҚжҳҜеҖҹеҠ©дәҺиҫ“е…ҘйҮҚе®ҡеҗ‘пјҢжҲ‘们еҸҜд»ҘеҲ©з”ЁupperзЁӢеәҸзҡ„зҺ°жңүеҠҹиғҪпјҢеҶҚеҶҷдёҖдёӘеҢ…иЈ…зЁӢеәҸwrapperгҖӮ
дҫӢВ 30.5.В wrapper
/* wrapper.c */
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <fcntl.h>
int main(int argc, char *argv[])
{
int fd;
if (argc != 2) {
fputs("usage: wrapper file
", stderr);
exit(1);
}
fd = open(argv[1], O_RDONLY);
if(fd<0) {
perror("open");
exit(1);
}
dup2(fd, STDIN_FILENO);
close(fd);
execl("./upper", "upper", NULL);
perror("exec ./upper");
exit(1);
}
wrapperзЁӢеәҸе°Ҷе‘Ҫд»ӨиЎҢеҸӮж•°еҪ“дҪңж–Ү件еҗҚжү“ејҖпјҢе°Ҷж ҮеҮҶиҫ“е…ҘйҮҚе®ҡеҗ‘еҲ°иҝҷдёӘж–Ү件пјҢ然еҗҺи°ғз”Ёexecжү§иЎҢupperзЁӢеәҸпјҢиҝҷж—¶еҺҹжқҘжү“ејҖзҡ„ж–Ү件жҸҸиҝ°з¬Ұд»Қ然жҳҜжү“ејҖзҡ„пјҢupperзЁӢеәҸеҸӘиҙҹиҙЈд»Һж ҮеҮҶиҫ“е…ҘиҜ»е…Ҙеӯ—з¬ҰиҪ¬жҲҗеӨ§еҶҷпјҢ并дёҚе…іеҝғж ҮеҮҶиҫ“е…ҘеҜ№еә”зҡ„жҳҜж–Ү件иҝҳжҳҜз»Ҳз«ҜгҖӮиҝҗиЎҢз»“жһңеҰӮдёӢпјҡ
$ ./wrapper file.txt
THIS IS THE FILE, FILE.TXT, IT IS ALL LOWER CASE.
3.3.В waitе’ҢwaitpidеҮҪж•°
дёҖдёӘиҝӣзЁӢеңЁз»Ҳжӯўж—¶дјҡе…ій—ӯжүҖжңүж–Ү件жҸҸиҝ°з¬ҰпјҢйҮҠж”ҫеңЁз”ЁжҲ·з©әй—ҙеҲҶй…Қзҡ„еҶ…еӯҳпјҢдҪҶе®ғзҡ„PCBиҝҳдҝқз•ҷзқҖпјҢеҶ…ж ёеңЁе…¶дёӯдҝқеӯҳдәҶдёҖдәӣдҝЎжҒҜпјҡеҰӮжһңжҳҜжӯЈеёёз»ҲжӯўеҲҷдҝқеӯҳзқҖйҖҖеҮәзҠ¶жҖҒпјҢеҰӮжһңжҳҜејӮеёёз»ҲжӯўеҲҷдҝқеӯҳзқҖеҜјиҮҙиҜҘиҝӣзЁӢз»Ҳжӯўзҡ„дҝЎеҸ·жҳҜе“ӘдёӘгҖӮиҝҷдёӘиҝӣзЁӢзҡ„зҲ¶иҝӣзЁӢеҸҜд»Ҙи°ғз”ЁwaitжҲ–waitpidиҺ·еҸ–иҝҷдәӣдҝЎжҒҜпјҢ然еҗҺеҪ»еә•жё…йҷӨжҺүиҝҷдёӘиҝӣзЁӢгҖӮжҲ‘们зҹҘйҒ“дёҖдёӘиҝӣзЁӢзҡ„йҖҖеҮәзҠ¶жҖҒеҸҜд»ҘеңЁShellдёӯз”Ёзү№ж®ҠеҸҳйҮҸ$?жҹҘзңӢпјҢеӣ дёәShellжҳҜе®ғзҡ„зҲ¶иҝӣзЁӢпјҢеҪ“е®ғз»Ҳжӯўж—¶Shellи°ғз”ЁwaitжҲ–waitpidеҫ—еҲ°е®ғзҡ„йҖҖеҮәзҠ¶жҖҒеҗҢж—¶еҪ»еә•жё…йҷӨжҺүиҝҷдёӘиҝӣзЁӢгҖӮ
еҰӮжһңдёҖдёӘиҝӣзЁӢе·Із»Ҹз»ҲжӯўпјҢдҪҶжҳҜе®ғзҡ„зҲ¶иҝӣзЁӢе°ҡжңӘи°ғз”ЁwaitжҲ–waitpidеҜ№е®ғиҝӣиЎҢжё…зҗҶпјҢиҝҷж—¶зҡ„иҝӣзЁӢзҠ¶жҖҒз§°дёәеғөе°ёпјҲZombieпјүиҝӣзЁӢгҖӮд»»дҪ•иҝӣзЁӢеңЁеҲҡз»Ҳжӯўж—¶йғҪжҳҜеғөе°ёиҝӣзЁӢпјҢжӯЈеёёжғ…еҶөдёӢпјҢеғөе°ёиҝӣзЁӢйғҪз«ӢеҲ»иў«зҲ¶иҝӣзЁӢжё…зҗҶдәҶпјҢдёәдәҶи§ӮеҜҹеҲ°еғөе°ёиҝӣзЁӢпјҢжҲ‘们иҮӘе·ұеҶҷдёҖдёӘдёҚжӯЈеёёзҡ„зЁӢеәҸпјҢзҲ¶иҝӣзЁӢforkеҮәеӯҗиҝӣзЁӢпјҢеӯҗиҝӣзЁӢз»ҲжӯўпјҢиҖҢзҲ¶иҝӣзЁӢж—ўдёҚз»Ҳжӯўд№ҹдёҚи°ғз”Ёwaitжё…зҗҶеӯҗиҝӣзЁӢпјҡ
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid=fork();
if(pid<0) {
perror("fork");
exit(1);
}
if(pid>0) { /* parent */
while(1);
}
/* child */
return 0;
}
еңЁеҗҺеҸ°иҝҗиЎҢиҝҷдёӘзЁӢеәҸпјҢ然еҗҺз”Ёpsе‘Ҫд»ӨжҹҘзңӢпјҡ
$ ./a.out &
[1] 6130
$ ps u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
akaedu 6016 0.0 0.3 5724 3140 pts/0 Ss 08:41 0:00 bash
akaedu 6130 97.2 0.0 1536 284 pts/0 R 08:44 14:33 ./a.out
akaedu 6131 0.0 0.0 0 0 pts/0 Z 08:44 0:00 [a.out] <defunct>
akaedu 6163 0.0 0.0 2620 1000 pts/0 R+ 08:59 0:00 ps u
еңЁ./a.outе‘Ҫд»ӨеҗҺйқўеҠ дёӘ&иЎЁзӨәеҗҺеҸ°иҝҗиЎҢпјҢShellдёҚзӯүеҫ…иҝҷдёӘиҝӣзЁӢз»Ҳжӯўе°ұз«ӢеҲ»жү“еҚ°жҸҗзӨәз¬Ұ并зӯүеҫ…з”ЁжҲ·иҫ“е‘Ҫд»ӨгҖӮзҺ°еңЁShellжҳҜдҪҚдәҺеүҚеҸ°зҡ„пјҢз”ЁжҲ·еңЁз»Ҳз«Ҝзҡ„иҫ“е…Ҙдјҡиў«ShellиҜ»еҸ–пјҢеҗҺеҸ°иҝӣзЁӢжҳҜиҜ»дёҚеҲ°з»Ҳз«Ҝиҫ“е…Ҙзҡ„гҖӮ第дәҢжқЎе‘Ҫд»Өps uжҳҜеңЁеүҚеҸ°иҝҗиЎҢзҡ„пјҢеңЁжӯӨжңҹй—ҙShellиҝӣзЁӢе’Ң./a.outиҝӣзЁӢйғҪеңЁеҗҺеҸ°иҝҗиЎҢпјҢзӯүеҲ°ps uе‘Ҫд»Өз»“жқҹж—¶ShellиҝӣзЁӢеҸҲйҮҚж–°еӣһеҲ°еүҚеҸ°гҖӮеңЁз¬¬В 33В з« дҝЎеҸ·е’Ң第 34В з« з»Ҳз«ҜгҖҒдҪңдёҡжҺ§еҲ¶дёҺе®ҲжҠӨиҝӣзЁӢе°ҶдјҡиҝӣдёҖжӯҘи§ЈйҮҠеүҚеҸ°пјҲForegroundпјүе’ҢеҗҺеҸ°пјҲBackgroudпјүзҡ„жҰӮеҝөгҖӮ
зҲ¶иҝӣзЁӢзҡ„pidжҳҜ6130пјҢеӯҗиҝӣзЁӢжҳҜеғөе°ёиҝӣзЁӢпјҢpidжҳҜ6131пјҢpsе‘Ҫд»ӨжҳҫзӨәеғөе°ёиҝӣзЁӢзҡ„зҠ¶жҖҒдёәZпјҢеңЁе‘Ҫд»ӨиЎҢдёҖж ҸиҝҳжҳҫзӨә<defunct>гҖӮ
еҰӮжһңдёҖдёӘзҲ¶иҝӣзЁӢз»ҲжӯўпјҢиҖҢе®ғзҡ„еӯҗиҝӣзЁӢиҝҳеӯҳеңЁпјҲиҝҷдәӣеӯҗиҝӣзЁӢжҲ–иҖ…д»ҚеңЁиҝҗиЎҢпјҢжҲ–иҖ…е·Із»ҸжҳҜеғөе°ёиҝӣзЁӢдәҶпјүпјҢеҲҷиҝҷдәӣеӯҗиҝӣзЁӢзҡ„зҲ¶иҝӣзЁӢж”№дёәinitиҝӣзЁӢгҖӮinitжҳҜзі»з»ҹдёӯзҡ„дёҖдёӘзү№ж®ҠиҝӣзЁӢпјҢйҖҡеёёзЁӢеәҸж–Ү件жҳҜ/sbin/initпјҢиҝӣзЁӢidжҳҜ1пјҢеңЁзі»з»ҹеҗҜеҠЁж—¶иҙҹиҙЈеҗҜеҠЁеҗ„з§Қзі»з»ҹжңҚеҠЎпјҢд№ӢеҗҺе°ұиҙҹиҙЈжё…зҗҶеӯҗиҝӣзЁӢпјҢеҸӘиҰҒжңүеӯҗиҝӣзЁӢз»ҲжӯўпјҢinitе°ұдјҡи°ғз”ЁwaitеҮҪж•°жё…зҗҶе®ғгҖӮ
еғөе°ёиҝӣзЁӢжҳҜдёҚиғҪз”Ёkillе‘Ҫд»Өжё…йҷӨжҺүзҡ„пјҢеӣ дёәkillе‘Ҫд»ӨеҸӘжҳҜз”ЁжқҘз»ҲжӯўиҝӣзЁӢзҡ„пјҢиҖҢеғөе°ёиҝӣзЁӢе·Із»Ҹз»ҲжӯўдәҶгҖӮжҖқиҖғдёҖдёӢпјҢз”Ёд»Җд№ҲеҠһжі•еҸҜд»Ҙжё…йҷӨжҺүеғөе°ёиҝӣзЁӢпјҹ
waitе’ҢwaitpidеҮҪж•°зҡ„еҺҹеһӢжҳҜпјҡ
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, int options);
иӢҘи°ғз”ЁжҲҗеҠҹеҲҷиҝ”еӣһжё…зҗҶжҺүзҡ„еӯҗиҝӣзЁӢidпјҢиӢҘи°ғз”ЁеҮәй”ҷеҲҷиҝ”еӣһ-1гҖӮзҲ¶иҝӣзЁӢи°ғз”ЁwaitжҲ–waitpidж—¶еҸҜиғҪдјҡпјҡ
йҳ»еЎһпјҲеҰӮжһңе®ғзҡ„жүҖжңүеӯҗиҝӣзЁӢйғҪиҝҳеңЁиҝҗиЎҢпјүгҖӮ
еёҰеӯҗиҝӣзЁӢзҡ„з»ҲжӯўдҝЎжҒҜз«ӢеҚіиҝ”еӣһпјҲеҰӮжһңдёҖдёӘеӯҗиҝӣзЁӢе·Із»ҲжӯўпјҢжӯЈзӯүеҫ…зҲ¶иҝӣзЁӢиҜ»еҸ–е…¶з»ҲжӯўдҝЎжҒҜпјүгҖӮ
еҮәй”ҷз«ӢеҚіиҝ”еӣһпјҲеҰӮжһңе®ғжІЎжңүд»»дҪ•еӯҗиҝӣзЁӢпјүгҖӮ
иҝҷдёӨдёӘеҮҪж•°зҡ„еҢәеҲ«жҳҜпјҡ
еҰӮжһңзҲ¶иҝӣзЁӢзҡ„жүҖжңүеӯҗиҝӣзЁӢйғҪиҝҳеңЁиҝҗиЎҢпјҢи°ғз”Ё
waitе°ҶдҪҝзҲ¶иҝӣзЁӢйҳ»еЎһпјҢиҖҢи°ғз”Ёwaitpidж—¶еҰӮжһңеңЁoptionsеҸӮж•°дёӯжҢҮе®ҡWNOHANGеҸҜд»ҘдҪҝзҲ¶иҝӣзЁӢдёҚйҳ»еЎһиҖҢз«ӢеҚіиҝ”еӣһ0гҖӮwaitзӯүеҫ…第дёҖдёӘз»Ҳжӯўзҡ„еӯҗиҝӣзЁӢпјҢиҖҢwaitpidеҸҜд»ҘйҖҡиҝҮpidеҸӮж•°жҢҮе®ҡзӯүеҫ…е“ӘдёҖдёӘеӯҗиҝӣзЁӢгҖӮ
еҸҜи§ҒпјҢи°ғз”Ёwaitе’ҢwaitpidдёҚд»…еҸҜд»ҘиҺ·еҫ—еӯҗиҝӣзЁӢзҡ„з»ҲжӯўдҝЎжҒҜпјҢиҝҳеҸҜд»ҘдҪҝзҲ¶иҝӣзЁӢйҳ»еЎһзӯүеҫ…еӯҗиҝӣзЁӢз»ҲжӯўпјҢиө·еҲ°иҝӣзЁӢй—ҙеҗҢжӯҘзҡ„дҪңз”ЁгҖӮеҰӮжһңеҸӮж•°statusдёҚжҳҜз©әжҢҮй’ҲпјҢеҲҷеӯҗиҝӣзЁӢзҡ„з»ҲжӯўдҝЎжҒҜйҖҡиҝҮиҝҷдёӘеҸӮж•°дј еҮәпјҢеҰӮжһңеҸӘжҳҜдёәдәҶеҗҢжӯҘиҖҢдёҚе…іеҝғеӯҗиҝӣзЁӢзҡ„з»ҲжӯўдҝЎжҒҜпјҢеҸҜд»Ҙе°ҶstatusеҸӮж•°жҢҮе®ҡдёәNULLгҖӮ
дҫӢВ 30.6.В waitpid
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
pid_t pid;
pid = fork();
if (pid < 0) {
perror("fork failed");
exit(1);
}
if (pid == 0) {
int i;
for (i = 3; i > 0; i--) {
printf("This is the child
");
sleep(1);
}
exit(3);
} else {
int stat_val;
waitpid(pid, &stat_val, 0);
if (WIFEXITED(stat_val))
printf("Child exited with code %d
", WEXITSTATUS(stat_val));
else if (WIFSIGNALED(stat_val))
printf("Child terminated abnormally, signal %d
", WTERMSIG(stat_val));
}
return 0;
}
еӯҗиҝӣзЁӢзҡ„з»ҲжӯўдҝЎжҒҜеңЁдёҖдёӘintдёӯеҢ…еҗ«дәҶеӨҡдёӘеӯ—ж®өпјҢз”Ёе®Ҹе®ҡд№үеҸҜд»ҘеҸ–еҮәе…¶дёӯзҡ„жҜҸдёӘеӯ—ж®өпјҡеҰӮжһңеӯҗиҝӣзЁӢжҳҜжӯЈеёёз»Ҳжӯўзҡ„пјҢWIFEXITEDеҸ–еҮәзҡ„еӯ—ж®өеҖјйқһйӣ¶пјҢWEXITSTATUSеҸ–еҮәзҡ„еӯ—ж®өеҖје°ұжҳҜеӯҗиҝӣзЁӢзҡ„йҖҖеҮәзҠ¶жҖҒпјӣеҰӮжһңеӯҗиҝӣзЁӢжҳҜ收еҲ°дҝЎеҸ·иҖҢејӮеёёз»Ҳжӯўзҡ„пјҢWIFSIGNALEDеҸ–еҮәзҡ„еӯ—ж®өеҖјйқһйӣ¶пјҢWTERMSIGеҸ–еҮәзҡ„еӯ—ж®өеҖје°ұжҳҜдҝЎеҸ·зҡ„зј–еҸ·гҖӮдҪңдёәз»ғд№ пјҢиҜ·иҜ»иҖ…д»ҺеӨҙж–Ү件йҮҢжҹҘдёҖдёӢиҝҷдәӣе®ҸеҒҡдәҶд»Җд№Ҳиҝҗз®—пјҢжҳҜеҰӮдҪ•еҸ–еҮәеӯ—ж®өеҖјзҡ„гҖӮ
д№ йўҳ
1гҖҒиҜ·иҜ»иҖ…дҝ®ж”№дҫӢВ 30.6 вҖңwaitpidвҖқзҡ„д»Јз Ғе’Ңе®һйӘҢжқЎд»¶пјҢдҪҝе®ғдә§з”ҹвҖңChild terminated abnormallyвҖқзҡ„иҫ“еҮәгҖӮ
[[37](#id2867112)] дәӢе®һдёҠпјҢеңЁжҜҸдёӘж–Ү件жҸҸиҝ°з¬ҰдёӯжңүдёҖдёӘclose-on-execж Үеҝ—пјҢеҰӮжһңиҜҘж Үеҝ—дёә1пјҢеҲҷи°ғз”Ёexecж—¶е…ій—ӯиҝҷдёӘж–Ү件жҸҸиҝ°з¬ҰгҖӮиҜҘж Үеҝ—й»ҳи®Өдёә0пјҢеҸҜд»Ҙз”ЁfcntlеҮҪж•°е°Ҷе®ғзҪ®1пјҢжң¬д№ҰдёҚи®Ёи®әиҜҘж Үеҝ—дёә1зҡ„жғ…еҶөгҖӮ
4.В иҝӣзЁӢй—ҙйҖҡдҝЎ
жҜҸдёӘиҝӣзЁӢеҗ„иҮӘжңүдёҚеҗҢзҡ„з”ЁжҲ·ең°еқҖз©әй—ҙпјҢд»»дҪ•дёҖдёӘиҝӣзЁӢзҡ„е…ЁеұҖеҸҳйҮҸеңЁеҸҰдёҖдёӘиҝӣзЁӢдёӯйғҪзңӢдёҚеҲ°пјҢжүҖд»ҘиҝӣзЁӢд№Ӣй—ҙиҰҒдәӨжҚўж•°жҚ®еҝ…йЎ»йҖҡиҝҮеҶ…ж ёпјҢеңЁеҶ…ж ёдёӯејҖиҫҹдёҖеқ—зј“еҶІеҢәпјҢиҝӣзЁӢ1жҠҠж•°жҚ®д»Һз”ЁжҲ·з©әй—ҙжӢ·еҲ°еҶ…ж ёзј“еҶІеҢәпјҢиҝӣзЁӢ2еҶҚд»ҺеҶ…ж ёзј“еҶІеҢәжҠҠж•°жҚ®иҜ»иө°пјҢеҶ…ж ёжҸҗдҫӣзҡ„иҝҷз§ҚжңәеҲ¶з§°дёәиҝӣзЁӢй—ҙйҖҡдҝЎпјҲIPCпјҢInterProcess CommunicationпјүгҖӮеҰӮдёӢеӣҫжүҖзӨәгҖӮ
еӣҫВ 30.6.В иҝӣзЁӢй—ҙйҖҡдҝЎ
4.1.В з®ЎйҒ“
з®ЎйҒ“жҳҜдёҖз§ҚжңҖеҹәжң¬зҡ„IPCжңәеҲ¶пјҢз”ұpipeеҮҪж•°еҲӣе»әпјҡ
#include <unistd.h>
int pipe(int filedes[2]);
и°ғз”ЁpipeеҮҪж•°ж—¶еңЁеҶ…ж ёдёӯејҖиҫҹдёҖеқ—зј“еҶІеҢәпјҲз§°дёәз®ЎйҒ“пјүз”ЁдәҺйҖҡдҝЎпјҢе®ғжңүдёҖдёӘиҜ»з«ҜдёҖдёӘеҶҷз«ҜпјҢ然еҗҺйҖҡиҝҮfiledesеҸӮж•°дј еҮәз»ҷз”ЁжҲ·зЁӢеәҸдёӨдёӘж–Ү件жҸҸиҝ°з¬ҰпјҢfiledes[0]жҢҮеҗ‘з®ЎйҒ“зҡ„иҜ»з«ҜпјҢfiledes[1]жҢҮеҗ‘з®ЎйҒ“зҡ„еҶҷз«ҜпјҲеҫҲеҘҪи®°пјҢе°ұеғҸ0жҳҜж ҮеҮҶиҫ“е…Ҙ1жҳҜж ҮеҮҶиҫ“еҮәдёҖж ·пјүгҖӮжүҖд»Ҙз®ЎйҒ“еңЁз”ЁжҲ·зЁӢеәҸзңӢиө·жқҘе°ұеғҸдёҖдёӘжү“ејҖзҡ„ж–Ү件пјҢйҖҡиҝҮread(filedes[0]);жҲ–иҖ…write(filedes[1]);еҗ‘иҝҷдёӘж–Ү件иҜ»еҶҷж•°жҚ®е…¶е®һжҳҜеңЁиҜ»еҶҷеҶ…ж ёзј“еҶІеҢәгҖӮpipeеҮҪж•°и°ғз”ЁжҲҗеҠҹиҝ”еӣһ0пјҢи°ғз”ЁеӨұиҙҘиҝ”еӣһ-1гҖӮ
ејҖиҫҹдәҶз®ЎйҒ“д№ӢеҗҺеҰӮдҪ•е®һзҺ°дёӨдёӘиҝӣзЁӢй—ҙзҡ„йҖҡдҝЎе‘ўпјҹжҜ”еҰӮеҸҜд»ҘжҢүдёӢйқўзҡ„жӯҘйӘӨйҖҡдҝЎгҖӮ
еӣҫВ 30.7.В з®ЎйҒ“
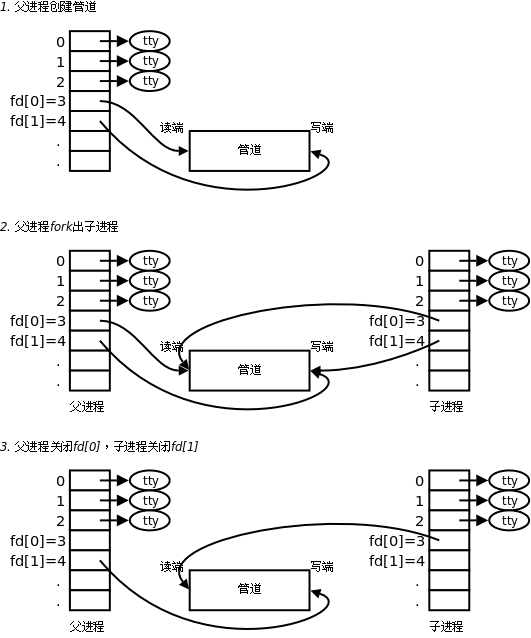
зҲ¶иҝӣзЁӢи°ғз”Ё
pipeејҖиҫҹз®ЎйҒ“пјҢеҫ—еҲ°дёӨдёӘж–Ү件жҸҸиҝ°з¬ҰжҢҮеҗ‘з®ЎйҒ“зҡ„дёӨз«ҜгҖӮзҲ¶иҝӣзЁӢи°ғз”Ё
forkеҲӣе»әеӯҗиҝӣзЁӢпјҢйӮЈд№ҲеӯҗиҝӣзЁӢд№ҹжңүдёӨдёӘж–Ү件жҸҸиҝ°з¬ҰжҢҮеҗ‘еҗҢдёҖз®ЎйҒ“гҖӮзҲ¶иҝӣзЁӢе…ій—ӯз®ЎйҒ“иҜ»з«ҜпјҢеӯҗиҝӣзЁӢе…ій—ӯз®ЎйҒ“еҶҷз«ҜгҖӮзҲ¶иҝӣзЁӢеҸҜд»ҘеҫҖз®ЎйҒ“йҮҢеҶҷпјҢеӯҗиҝӣзЁӢеҸҜд»Ҙд»Һз®ЎйҒ“йҮҢиҜ»пјҢз®ЎйҒ“жҳҜз”ЁзҺҜеҪўйҳҹеҲ—е®һзҺ°зҡ„пјҢж•°жҚ®д»ҺеҶҷз«ҜжөҒе…Ҙд»ҺиҜ»з«ҜжөҒеҮәпјҢиҝҷж ·е°ұе®һзҺ°дәҶиҝӣзЁӢй—ҙйҖҡдҝЎгҖӮ
дҫӢВ 30.7.В з®ЎйҒ“
#include <stdlib.h>
#include <unistd.h>
#define MAXLINE 80
int main(void)
{
int n;
int fd[2];
pid_t pid;
char line[MAXLINE];
if (pipe(fd) < 0) {
perror("pipe");
exit(1);
}
if ((pid = fork()) < 0) {
perror("fork");
exit(1);
}
if (pid > 0) { /* parent */
close(fd[0]);
write(fd[1], "hello world
", 12);
wait(NULL);
} else { /* child */
close(fd[1]);
n = read(fd[0], line, MAXLINE);
write(STDOUT_FILENO, line, n);
}
return 0;
}
дҪҝз”Ёз®ЎйҒ“жңүдёҖдәӣйҷҗеҲ¶пјҡ
дёӨдёӘиҝӣзЁӢйҖҡиҝҮдёҖдёӘз®ЎйҒ“еҸӘиғҪе®һзҺ°еҚ•еҗ‘йҖҡдҝЎпјҢжҜ”еҰӮдёҠйқўзҡ„дҫӢеӯҗпјҢзҲ¶иҝӣзЁӢеҶҷеӯҗиҝӣзЁӢиҜ»пјҢеҰӮжһңжңүж—¶еҖҷд№ҹйңҖиҰҒеӯҗиҝӣзЁӢеҶҷзҲ¶иҝӣзЁӢиҜ»пјҢе°ұеҝ…йЎ»еҸҰејҖдёҖдёӘз®ЎйҒ“гҖӮиҜ·иҜ»иҖ…жҖқиҖғпјҢеҰӮжһңеҸӘејҖдёҖдёӘз®ЎйҒ“пјҢдҪҶжҳҜзҲ¶иҝӣзЁӢдёҚе…ій—ӯиҜ»з«ҜпјҢеӯҗиҝӣзЁӢд№ҹдёҚе…ій—ӯеҶҷз«ҜпјҢеҸҢж–№йғҪжңүиҜ»з«Ҝе’ҢеҶҷз«ҜпјҢдёәд»Җд№ҲдёҚиғҪе®һзҺ°еҸҢеҗ‘йҖҡдҝЎпјҹ
з®ЎйҒ“зҡ„иҜ»еҶҷз«ҜйҖҡиҝҮжү“ејҖзҡ„ж–Ү件жҸҸиҝ°з¬ҰжқҘдј йҖ’пјҢеӣ жӯӨиҰҒйҖҡдҝЎзҡ„дёӨдёӘиҝӣзЁӢеҝ…йЎ»д»Һе®ғ们зҡ„е…¬е…ұзҘ–е…ҲйӮЈйҮҢ继жүҝз®ЎйҒ“ж–Ү件жҸҸиҝ°з¬ҰгҖӮдёҠйқўзҡ„дҫӢеӯҗжҳҜзҲ¶иҝӣзЁӢжҠҠж–Ү件жҸҸиҝ°з¬Ұдј з»ҷеӯҗиҝӣзЁӢд№ӢеҗҺзҲ¶еӯҗиҝӣзЁӢд№Ӣй—ҙйҖҡдҝЎпјҢд№ҹеҸҜд»ҘзҲ¶иҝӣзЁӢ
forkдёӨж¬ЎпјҢжҠҠж–Ү件жҸҸиҝ°з¬Ұдј з»ҷдёӨдёӘеӯҗиҝӣзЁӢпјҢ然еҗҺдёӨдёӘеӯҗиҝӣзЁӢд№Ӣй—ҙйҖҡдҝЎпјҢжҖ»д№ӢйңҖиҰҒйҖҡиҝҮforkдј йҖ’ж–Ү件жҸҸиҝ°з¬ҰдҪҝдёӨдёӘиҝӣзЁӢйғҪиғҪи®ҝй—®еҗҢдёҖз®ЎйҒ“пјҢе®ғ们жүҚиғҪйҖҡдҝЎгҖӮ
дҪҝз”Ёз®ЎйҒ“йңҖиҰҒжіЁж„Ҹд»ҘдёӢ4з§Қзү№ж®Ҡжғ…еҶөпјҲеҒҮи®ҫйғҪжҳҜйҳ»еЎһI/Oж“ҚдҪңпјҢжІЎжңүи®ҫзҪ®O_NONBLOCKж Үеҝ—пјүпјҡ
еҰӮжһңжүҖжңүжҢҮеҗ‘з®ЎйҒ“еҶҷз«Ҝзҡ„ж–Ү件жҸҸиҝ°з¬ҰйғҪе…ій—ӯдәҶпјҲз®ЎйҒ“еҶҷз«Ҝзҡ„еј•з”Ёи®Ўж•°зӯүдәҺ0пјүпјҢиҖҢд»Қ然жңүиҝӣзЁӢд»Һз®ЎйҒ“зҡ„иҜ»з«ҜиҜ»ж•°жҚ®пјҢйӮЈд№Ҳз®ЎйҒ“дёӯеү©дҪҷзҡ„ж•°жҚ®йғҪиў«иҜ»еҸ–еҗҺпјҢеҶҚж¬Ў
readдјҡиҝ”еӣһ0пјҢе°ұеғҸиҜ»еҲ°ж–Ү件жң«е°ҫдёҖж ·гҖӮеҰӮжһңжңүжҢҮеҗ‘з®ЎйҒ“еҶҷз«Ҝзҡ„ж–Ү件жҸҸиҝ°з¬ҰжІЎе…ій—ӯпјҲз®ЎйҒ“еҶҷз«Ҝзҡ„еј•з”Ёи®Ўж•°еӨ§дәҺ0пјүпјҢиҖҢжҢҒжңүз®ЎйҒ“еҶҷз«Ҝзҡ„иҝӣзЁӢд№ҹжІЎжңүеҗ‘з®ЎйҒ“дёӯеҶҷж•°жҚ®пјҢиҝҷж—¶жңүиҝӣзЁӢд»Һз®ЎйҒ“иҜ»з«ҜиҜ»ж•°жҚ®пјҢйӮЈд№Ҳз®ЎйҒ“дёӯеү©дҪҷзҡ„ж•°жҚ®йғҪиў«иҜ»еҸ–еҗҺпјҢеҶҚж¬Ў
readдјҡйҳ»еЎһпјҢзӣҙеҲ°з®ЎйҒ“дёӯжңүж•°жҚ®еҸҜиҜ»дәҶжүҚиҜ»еҸ–ж•°жҚ®е№¶иҝ”еӣһгҖӮеҰӮжһңжүҖжңүжҢҮеҗ‘з®ЎйҒ“иҜ»з«Ҝзҡ„ж–Ү件жҸҸиҝ°з¬ҰйғҪе…ій—ӯдәҶпјҲз®ЎйҒ“иҜ»з«Ҝзҡ„еј•з”Ёи®Ўж•°зӯүдәҺ0пјүпјҢиҝҷж—¶жңүиҝӣзЁӢеҗ‘з®ЎйҒ“зҡ„еҶҷз«Ҝ
writeпјҢйӮЈд№ҲиҜҘиҝӣзЁӢдјҡ收еҲ°дҝЎеҸ·SIGPIPEпјҢйҖҡеёёдјҡеҜјиҮҙиҝӣзЁӢејӮеёёз»ҲжӯўгҖӮеңЁз¬¬В 33В з« дҝЎеҸ·дјҡи®ІеҲ°жҖҺж ·дҪҝSIGPIPEдҝЎеҸ·дёҚз»ҲжӯўиҝӣзЁӢгҖӮеҰӮжһңжңүжҢҮеҗ‘з®ЎйҒ“иҜ»з«Ҝзҡ„ж–Ү件жҸҸиҝ°з¬ҰжІЎе…ій—ӯпјҲз®ЎйҒ“иҜ»з«Ҝзҡ„еј•з”Ёи®Ўж•°еӨ§дәҺ0пјүпјҢиҖҢжҢҒжңүз®ЎйҒ“иҜ»з«Ҝзҡ„иҝӣзЁӢд№ҹжІЎжңүд»Һз®ЎйҒ“дёӯиҜ»ж•°жҚ®пјҢиҝҷж—¶жңүиҝӣзЁӢеҗ‘з®ЎйҒ“еҶҷз«ҜеҶҷж•°жҚ®пјҢйӮЈд№ҲеңЁз®ЎйҒ“иў«еҶҷж»Ўж—¶еҶҚж¬Ў
writeдјҡйҳ»еЎһпјҢзӣҙеҲ°з®ЎйҒ“дёӯжңүз©әдҪҚзҪ®дәҶжүҚеҶҷе…Ҙж•°жҚ®е№¶иҝ”еӣһгҖӮ
з®ЎйҒ“зҡ„иҝҷеӣӣз§Қзү№ж®Ҡжғ…еҶөе…·жңүжҷ®йҒҚж„Ҹд№үгҖӮеңЁз¬¬В 37В з« socketзј–зЁӢиҰҒи®Ізҡ„TCP socketд№ҹе…·жңүз®ЎйҒ“зҡ„иҝҷдәӣзү№жҖ§гҖӮ
д№ йўҳ
1гҖҒеңЁдҫӢВ 30.7 вҖңз®ЎйҒ“вҖқдёӯпјҢзҲ¶иҝӣзЁӢеҸӘз”ЁеҲ°еҶҷз«ҜпјҢеӣ иҖҢжҠҠиҜ»з«Ҝе…ій—ӯпјҢеӯҗиҝӣзЁӢеҸӘз”ЁеҲ°иҜ»з«ҜпјҢеӣ иҖҢжҠҠеҶҷз«Ҝе…ій—ӯпјҢ然еҗҺдә’зӣёйҖҡдҝЎпјҢдёҚдҪҝз”Ёзҡ„иҜ»з«ҜжҲ–еҶҷз«Ҝеҝ…йЎ»е…ій—ӯпјҢиҜ·иҜ»иҖ…жғідёҖжғіеҰӮжһңдёҚе…ій—ӯдјҡжңүд»Җд№Ҳй—®йўҳгҖӮ
2гҖҒиҜ·иҜ»иҖ…дҝ®ж”№дҫӢВ 30.7 вҖңз®ЎйҒ“вҖқзҡ„д»Јз Ғе’Ңе®һйӘҢжқЎд»¶пјҢйӘҢиҜҒжҲ‘дёҠйқўжүҖиҜҙзҡ„еӣӣз§Қзү№ж®Ҡжғ…еҶөгҖӮ
4.2.В е…¶е®ғIPCжңәеҲ¶
иҝӣзЁӢй—ҙйҖҡдҝЎеҝ…йЎ»йҖҡиҝҮеҶ…ж ёжҸҗдҫӣзҡ„йҖҡйҒ“пјҢиҖҢдё”еҝ…йЎ»жңүдёҖз§ҚеҠһжі•еңЁиҝӣзЁӢдёӯж ҮиҜҶеҶ…ж ёжҸҗдҫӣзҡ„жҹҗдёӘйҖҡйҒ“пјҢдёҠдёҖиҠӮи®Ізҡ„з®ЎйҒ“жҳҜз”Ёжү“ејҖзҡ„ж–Ү件жҸҸиҝ°з¬ҰжқҘж ҮиҜҶзҡ„гҖӮеҰӮжһңиҰҒдә’зӣёйҖҡдҝЎзҡ„еҮ дёӘиҝӣзЁӢжІЎжңүд»Һе…¬е…ұзҘ–е…ҲйӮЈйҮҢ继жүҝж–Ү件жҸҸиҝ°з¬ҰпјҢе®ғ们жҖҺд№ҲйҖҡдҝЎе‘ўпјҹеҶ…ж ёжҸҗдҫӣдёҖжқЎйҖҡйҒ“дёҚжҲҗй—®йўҳпјҢй—®йўҳжҳҜеҰӮдҪ•ж ҮиҜҶиҝҷжқЎйҖҡйҒ“жүҚиғҪдҪҝеҗ„иҝӣзЁӢйғҪеҸҜд»Ҙи®ҝй—®е®ғпјҹж–Ү件系з»ҹдёӯзҡ„и·Ҝеҫ„еҗҚжҳҜе…ЁеұҖзҡ„пјҢеҗ„иҝӣзЁӢйғҪеҸҜд»Ҙи®ҝй—®пјҢеӣ жӯӨеҸҜд»Ҙз”Ёж–Ү件系з»ҹдёӯзҡ„и·Ҝеҫ„еҗҚжқҘж ҮиҜҶдёҖдёӘIPCйҖҡйҒ“гҖӮ
FIFOе’ҢUNIX Domain SocketиҝҷдёӨз§ҚIPCжңәеҲ¶йғҪжҳҜеҲ©з”Ёж–Ү件系з»ҹдёӯзҡ„зү№ж®Ҡж–Ү件жқҘж ҮиҜҶзҡ„гҖӮеҸҜд»Ҙз”Ёmkfifoе‘Ҫд»ӨеҲӣе»әдёҖдёӘFIFOж–Ү件пјҡ
$ mkfifo hello
$ ls -l hello
prw-r--r-- 1 akaedu akaedu 0 2008-10-30 10:44 hello
FIFOж–Ү件еңЁзЈҒзӣҳдёҠжІЎжңүж•°жҚ®еқ—пјҢд»…з”ЁжқҘж ҮиҜҶеҶ…ж ёдёӯзҡ„дёҖжқЎйҖҡйҒ“пјҢеҗ„иҝӣзЁӢеҸҜд»Ҙжү“ејҖиҝҷдёӘж–Ү件иҝӣиЎҢread/writeпјҢе®һйҷ…дёҠжҳҜеңЁиҜ»еҶҷеҶ…ж ёйҖҡйҒ“пјҲж №жң¬еҺҹеӣ еңЁдәҺиҝҷдёӘfileз»“жһ„дҪ“жүҖжҢҮеҗ‘зҡ„readгҖҒwriteеҮҪж•°е’Ң常规ж–Ү件дёҚдёҖж ·пјүпјҢиҝҷж ·е°ұе®һзҺ°дәҶиҝӣзЁӢй—ҙйҖҡдҝЎгҖӮUNIX Domain Socketе’ҢFIFOзҡ„еҺҹзҗҶзұ»дјјпјҢд№ҹйңҖиҰҒдёҖдёӘзү№ж®Ҡзҡ„socketж–Ү件жқҘж ҮиҜҶеҶ…ж ёдёӯзҡ„йҖҡйҒ“пјҢдҫӢеҰӮ/var/runзӣ®еҪ•дёӢжңүеҫҲеӨҡзі»з»ҹжңҚеҠЎзҡ„socketж–Ү件пјҡ
$ ls -l /var/run/
total 52
srw-rw-rw- 1 root root 0 2008-10-30 00:24 acpid.socket
...
srw-rw-rw- 1 root root 0 2008-10-30 00:25 gdm_socket
...
srw-rw-rw- 1 root root 0 2008-10-30 00:24 sdp
...
srwxr-xr-x 1 root root 0 2008-10-30 00:42 synaptic.socket
ж–Ү件зұ»еһӢsиЎЁзӨәsocketпјҢиҝҷдәӣж–Ү件еңЁзЈҒзӣҳдёҠд№ҹжІЎжңүж•°жҚ®еқ—гҖӮUNIX Domain SocketжҳҜзӣ®еүҚжңҖе№ҝжіӣдҪҝз”Ёзҡ„IPCжңәеҲ¶пјҢеҲ°еҗҺйқўи®Іsocketзј–зЁӢж—¶еҶҚиҜҰз»Ҷд»Ӣз»ҚгҖӮ
зҺ°еңЁжҠҠиҝӣзЁӢд№Ӣй—ҙдј йҖ’дҝЎжҒҜзҡ„еҗ„з§ҚйҖ”еҫ„пјҲеҢ…жӢ¬еҗ„з§ҚIPCжңәеҲ¶пјүжҖ»з»“еҰӮдёӢпјҡ
зҲ¶иҝӣзЁӢйҖҡиҝҮ
forkеҸҜд»Ҙе°Ҷжү“ејҖж–Ү件зҡ„жҸҸиҝ°з¬Ұдј йҖ’з»ҷеӯҗиҝӣзЁӢеӯҗиҝӣзЁӢз»“жқҹж—¶пјҢзҲ¶иҝӣзЁӢи°ғз”Ё
waitеҸҜд»Ҙеҫ—еҲ°еӯҗиҝӣзЁӢзҡ„з»ҲжӯўдҝЎжҒҜеҮ дёӘиҝӣзЁӢеҸҜд»ҘеңЁж–Ү件系з»ҹдёӯиҜ»еҶҷжҹҗдёӘе…ұдә«ж–Ү件пјҢд№ҹеҸҜд»ҘйҖҡиҝҮз»ҷж–Ү件еҠ й”ҒжқҘе®һзҺ°иҝӣзЁӢй—ҙеҗҢжӯҘ
иҝӣзЁӢд№Ӣй—ҙдә’еҸ‘дҝЎеҸ·пјҢдёҖиҲ¬дҪҝз”Ё
SIGUSR1е’ҢSIGUSR2е®һзҺ°з”ЁжҲ·иҮӘе®ҡд№үеҠҹиғҪз®ЎйҒ“
FIFO
mmapеҮҪж•°пјҢеҮ дёӘиҝӣзЁӢеҸҜд»Ҙжҳ е°„еҗҢдёҖеҶ…еӯҳеҢә
SYS V IPCпјҢд»ҘеүҚзҡ„SYS V UNIXзі»з»ҹе®һзҺ°зҡ„IPCжңәеҲ¶пјҢеҢ…жӢ¬ж¶ҲжҒҜйҳҹеҲ—гҖҒдҝЎеҸ·йҮҸе’Ңе…ұдә«еҶ…еӯҳпјҢзҺ°еңЁе·Із»Ҹеҹәжң¬еәҹејғ
UNIX Domain SocketпјҢзӣ®еүҚжңҖе№ҝжіӣдҪҝз”Ёзҡ„IPCжңәеҲ¶
5.В з»ғд№ пјҡе®һзҺ°з®ҖеҚ•зҡ„Shell
з”Ёи®ІиҝҮзҡ„еҗ„з§ҚCеҮҪж•°е®һзҺ°дёҖдёӘз®ҖеҚ•зҡ„дәӨдә’ејҸShellпјҢиҰҒжұӮпјҡ
1гҖҒз»ҷеҮәжҸҗзӨәз¬ҰпјҢи®©з”ЁжҲ·иҫ“е…ҘдёҖиЎҢе‘Ҫд»ӨпјҢиҜҶеҲ«зЁӢеәҸеҗҚе’ҢеҸӮ数并и°ғз”ЁйҖӮеҪ“зҡ„execеҮҪж•°жү§иЎҢзЁӢеәҸпјҢеҫ…жү§иЎҢе®ҢжҲҗеҗҺеҶҚж¬Ўз»ҷеҮәжҸҗзӨәз¬ҰгҖӮ
2гҖҒиҜҶеҲ«е’ҢеӨ„зҗҶд»ҘдёӢз¬ҰеҸ·пјҡ
з®ҖеҚ•зҡ„ж ҮеҮҶиҫ“е…Ҙиҫ“еҮәйҮҚе®ҡеҗ‘пјҲ<е’Ң>пјүпјҡд»ҝз…§дҫӢВ 30.5 вҖңwrapperвҖқпјҢе…Ҳ
dup2然еҗҺexecгҖӮз®ЎйҒ“пјҲ|пјүпјҡShellиҝӣзЁӢе…Ҳи°ғз”Ё
pipeеҲӣе»әдёҖеҜ№з®ЎйҒ“жҸҸиҝ°з¬ҰпјҢ然еҗҺforkеҮәдёӨдёӘеӯҗиҝӣзЁӢпјҢдёҖдёӘеӯҗиҝӣзЁӢе…ій—ӯиҜ»з«ҜпјҢи°ғз”Ёdup2жҠҠеҶҷз«ҜиөӢз»ҷж ҮеҮҶиҫ“еҮәпјҢеҸҰдёҖдёӘеӯҗиҝӣзЁӢе…ій—ӯеҶҷз«ҜпјҢи°ғз”Ёdup2жҠҠиҜ»з«ҜиөӢз»ҷж ҮеҮҶиҫ“е…ҘпјҢдёӨдёӘеӯҗиҝӣзЁӢеҲҶеҲ«и°ғз”Ёexecжү§иЎҢзЁӢеәҸпјҢиҖҢShellиҝӣзЁӢжҠҠз®ЎйҒ“зҡ„дёӨз«ҜйғҪе…ій—ӯпјҢи°ғз”Ёwaitзӯүеҫ…дёӨдёӘеӯҗиҝӣзЁӢз»ҲжӯўгҖӮ
дҪ зҡ„зЁӢеәҸеә”иҜҘеҸҜд»ҘеӨ„зҗҶд»ҘдёӢе‘Ҫд»Өпјҡ
в—Ӣlsв–і-lв–і-Rв—Ӣ>в—Ӣfile1в—Ӣ
в—Ӣcatв—Ӣ<в—Ӣfile1в—Ӣ|в—Ӣwcв–і-cв—Ӣ>в—Ӣfile1в—Ӣ
в—ӢиЎЁзӨәйӣ¶дёӘжҲ–еӨҡдёӘз©әж јпјҢв–іиЎЁзӨәдёҖдёӘжҲ–еӨҡдёӘз©әж ј