

[Pythonе≠¶дє†] зЃАеНХзИђеПЦCSDNдЄЛиљљиµДжЇРдњ°жБѓ
ињЩжШѓдЄАзѓЗPythonзИђеПЦCSDNдЄЛиљљиµДжЇРдњ°жБѓзЪДдЊЛе≠РпЉМдЄїи¶БжШѓйАЪињЗurllib2иОЈеПЦCSDNжЯРдЄ™дЇЇжЙАжЬЙиµДжЇРзЪДиµДжЇРURLгАБиµДжЇРеРНзІ∞гАБдЄЛиљљжђ°жХ∞гАБеИЖжХ∞з≠Йдњ°жБѓпЉЫеЖЩињЩзѓЗжЦЗзЂ†зЪДеОЯеЫ†жШѓжИСжГ≥иОЈеПЦиЗ™еЈ±зЪДиµДжЇРжЙАжЬЙзЪДиѓДиЃЇдњ°жБѓпЉМдљЖжШѓзФ±дЇОиѓДиЃЇйЗЗзФ®JSдЄіжЧґеК†иљљпЉМжЙАдї•ињЩзѓЗжЦЗзЂ†еЕИзЃАеНХдїЛзїНе¶ВдљХдЇЇеЈ•еИЖжЮРHTMLй°µйЭҐзИђеПЦдњ°жБѓгАВ
жЇРдї£з†Б
# coding=utf-8
import urllib
import time
import re
import os
#**************************
#зђђдЄАж≠• йБНеОЖиОЈеПЦжѓПй°µеѓєеЇФдЄїйҐШзЪДURL
#http://download.csdn.net/user/eastmount/uploads/1
#http://download.csdn.net/user/eastmount/uploads/8
#**************************
num=1 #иЃ∞ељХиµДжЇРжАїжХ∞ еЕ±46дЄ™иµДжЇР
number=1 #иЃ∞ељХеИЧи°®жАїжХ∞1-8
fileurl=open("csdn_url.txt","w+")
fileurl.write("********иОЈеПЦиµДжЇРURL*******
")
while number<9:
url="http://download.csdn.net/user/eastmount/uploads/" + str(number)
fileurl.write("дЄЛиљљеИЧи°®URL:"+url+"
")
print unicode("дЄЛиљљеИЧи°®URL:"+url,"utf-8")
content=urllib.urlopen(url).read()
open("csdn.html","w+").write(content)
#иОЈеПЦеМЕеРЂURLеЭЧеЖЕеЃє еМєйЕНйЬАи¶БиЃ°зЃЧ</div>дЄ™жХ∞
start=content.find(r"<div class="list-container mb-bg">")
end=content.find(r"<div class="page_nav">")
cutcontent=content[start:end]
#print cutcontent
#иОЈеПЦеЭЧеЖЕеЃєдЄ≠URL
#嚥е¶В<dt><div><img еЫЊж†З></div><h3><a href>ж†ЗйҐШ</a></h3></dt>
res_dt = r"<dt>(.*?)</dt>"
m_dt = re.findall(res_dt,cutcontent,re.S|re.M)
for obj in m_dt:
#иЃ∞ељХURLжХ∞йЗП
print "**********************"
print "зђђ"+str(num)+"дЄ™иµДжЇР"
fileurl.write("**********************
")
fileurl.write("зђђ"+str(num)+"дЄ™иµДжЇР
")
num = num +1
#иОЈеПЦеЕЈдљУURL
url_list = re.findall(r"(?<=href=").+?(?=")|(?<=href=").+?(?=")", obj)
for url in url_list:
url_load="http://download.csdn.net"+url
print "URLпЉЪ "+url_load
fileurl.write("URLпЉЪ http://download.csdn.net"+url+"
")
#иОЈеПЦиµДжЇРж†ЗйҐШ
#<a href="/detail/eastmount/8757243">MFCжШЊз§ЇBMPеЫЊзЙЗ</a>
res_title = r"<a href=.*?>(.*?)</a>"
title = re.findall(res_title,obj,re.S|re.M)
for t in title:
print unicode("Title: " + t,"utf-8")
fileurl.write("TitleпЉЪ " + t +"
")
#**************************
#зђђдЇМж≠• йБНеОЖеЕЈдљУиµДжЇРзЪДеЖЕеЃєеПКиѓДиЃЇ
#http://download.csdn.net/detail/eastmount/8785591
#**************************
#еЃЪдљНжМЗеЃЪзїУжЮДеМЦдњ°жБѓзЫТInfobox
resources = urllib.urlopen(url_load).read()
open("resource.html","w+").write(resources)
start_res=resources.find(r"<div class="wraper-info">")
end_res=resources.find(r"<div class="enter-link">")
infobox=resources[start_res:end_res]
#иОЈеПЦиµДжЇРзІѓеИЖгАБдЄЛиљљжђ°жХ∞гАБиµДжЇРз±їеЮЛгАБиµДжЇРе§Іе∞П(еЙН4дЄ™<span></span>)
res_span = r"<span>(.*?)</span>"
m_span = re.findall(res_span,infobox,re.S|re.M)
print "иµДжЇРзІѓеИЖпЉЪ "+m_span[0]
fileurl.write("иµДжЇРзІѓеИЖ: " + m_span[0] +"
")
print "дЄЛиљљжђ°жХ∞пЉЪ "+m_span[1]
fileurl.write("дЄЛиљљжђ°жХ∞: " + m_span[1] +"
")
print "иµДжЇРз±їеЮЛпЉЪ "+m_span[2]
fileurl.write("иµДжЇРз±їеЮЛ: " + m_span[2] +"
")
print "иµДжЇРе§Іе∞ПпЉЪ "+m_span[3]
fileurl.write("иµДжЇРе§Іе∞П: " + m_span[3] +"
")
#**************************
#зђђдЄЙж≠• е¶ВдљХиОЈеПЦиѓДиЃЇ
#http://jeanphix.me/Ghost.py/
#http://segmentfault.com/q/1010000000143340
#http://casperjs.org/
#**************************
else:
fileurl.write("**********************
")
print "**********************
"
print "Load Next List
"
number = number+1 #еИЧи°®еК†1
#йААеЗЇжЙАжЬЙеЊ™зОѓ
else:
fileurl.close()
жШЊз§ЇзїУжЮЬ
жШЊз§ЇеЖЕеЃєеМЕжЛђиµДжЇРURLгАБиµДжЇРж†ЗйҐШгАБиµДжЇРзІѓеИЖгАБдЄЛиљљжђ°жХ∞гАБиµДжЇРз±їеЮЛеТМиµДжЇРе§Іе∞ПпЉЪ
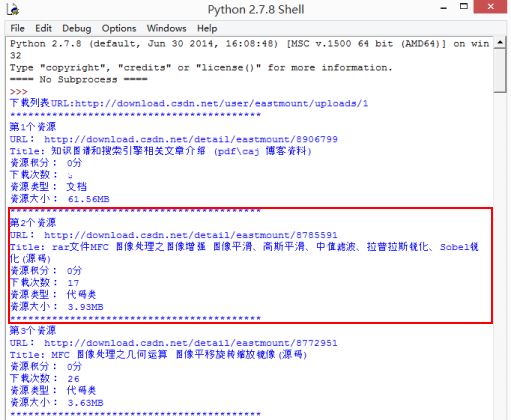
жѓФе¶ВзО∞еЬ®зИђеПЦйГ≠йЬЦе§Із•ЮзЪДиµДжЇРдњ°жБѓпЉМеЕґдЄ≠й°µйЭҐйУЊжО•е¶ВдЄЛпЉЪ(еЕ±7й°µ)
http://download.csdn.net/user/sinyu890807/uploads/1
http://download.csdn.net/user/sinyu890807/uploads/7
зЃАеНХдњЃжФєPythonжЇРдї£з†БURLеРОпЉМдЄЛиљљй°µйЭҐе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ
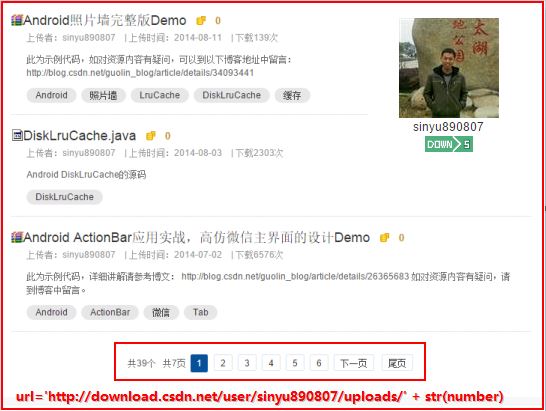
ињРи°МзїУжЮЬе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ

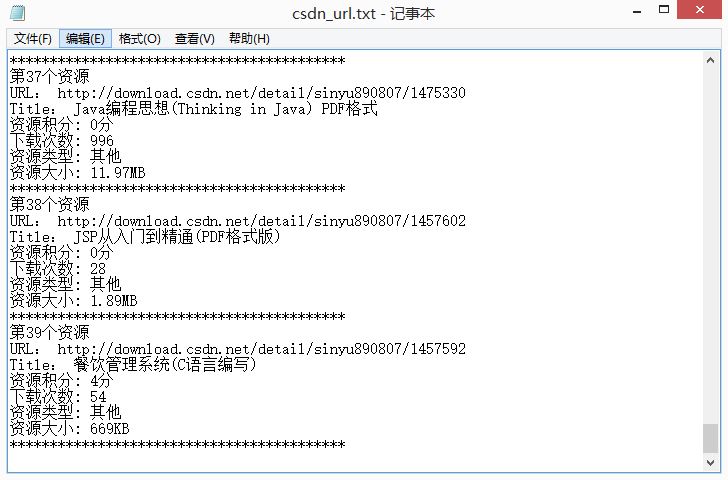
HTMLеИЖжЮР
й¶ЦеЕИпЉМиОЈеПЦжѓПеИЧдЄ≠зЪДжЙАжЬЙиµДжЇРзЪДURLеТМж†ЗйҐШпЉМйАЪињЗеИЖжЮРжЇРдї£з†БгАВ
<dt>
<div class="icon"><img src="/images/minetype/rar.gif" title="rarжЦЗдїґ"></div>
<div class="btns"></div>
<h3><a href="/detail/eastmount/8772951">
MFC еЫЊеГПе§ДзРЖдєЛеЗ†дљХињРзЃЧ еЫЊеГПеє≥зІїжЧЛиљђзЉ©жФЊйХЬеГП(жЇРз†Б)</a>
<span class="points">0</span>
</h3>
</dt>
<dd class="meta">дЄКдЉ†иАЕпЉЪ
<a class="user_name" href="/user/eastmount">eastmount</a>
¬†¬†¬†¬†| дЄКдЉ†жЧґйЧіпЉЪ2015-06-04
¬†¬†¬†¬†| дЄЛиљљ26жђ°
</dd>
<dd class="intro">
иѓ•иµДжЇРдЄїи¶БеПВиАГжИСзЪДеНЪеЃҐгАРжХ∞е≠ЧеЫЊеГПе§ДзРЖгАСеЕ≠.MFCз©ЇйЧіеЗ†дљХеПШжНҐдєЛеЫЊеГПеє≥зІїгАБйХЬеГПгАБжЧЛиљђ
зЉ©жФЊиѓ¶иІ£пЉМдЄїи¶БиЃ≤ињ∞еЯЇдЇОVC++6.0 MFCеЫЊеГПе§ДзРЖзЪДеЇФзФ®зЯ•иѓЖпЉМи¶БйАЪињЗMFCеНХжЦЗж°£иІЖеЫЊеЃЮзО∞жШЊ
з§ЇBMPеЫЊзЙЗгАВ
</dd>
<dd class="tag">
<a href="/tag/MFC">MFC</a>
<a href="/tag/%E5%9B%BE%E5%83%8F%E5%A4%84%E7%90%86">еЫЊеГПе§ДзРЖ</a><
</dd>
еѓєеЇФзЪДHTMLжШЊз§Їе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ
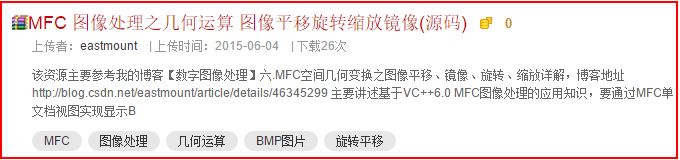
зДґеРОйАЪињЗURLеОїеИ∞еЕЈдљУзЪДиµДжЇРиОЈеПЦжИСиЗ™еЈ±зІ∞дЄЇеГПжґИжБѓзЫТзЪДдњ°жБѓпЉЪ
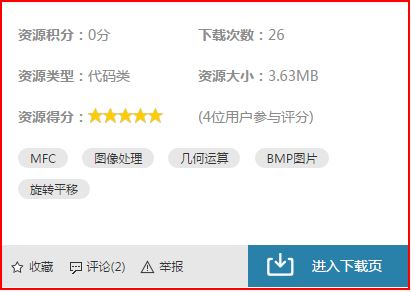
еѓєеЇФеЃ°жЯ•еЕГзі†зЪДдњ°жБѓе¶ВдЄЛжЙАз§ЇпЉМиОЈеПЦ0еИЖеН≥еПѓпЉЪ

жЬАеРОжИСжГ≥еБЪзЪДдЇЛиОЈеПЦиѓДиЃЇдњ°жБѓпЉМдљЖжШѓеЃГжШѓйАЪињЗJSеЃЮзО∞зЪДпЉЪ
<div class="section-list panel panel-default">
<div class="panel-heading">
<h3 class="panel-title">иµДжЇРиѓДиЃЇ</h3>
</div>
<!-- recommand -->
<script language="JavaScript" defer type="text/javascript"
src="/js/comment.js"></script>
<div class="recommand download_comment panel-body" sourceid="8772951"></div>
</div>
жШЊз§ЇзЪДJSй°µйЭҐйГ®еИЖе¶ВдЄЛпЉЪ
var base_url= (window.location.host.substring(0,5)=="local") ? "http://local.downloadv3.csdn.net" : "http://download.csdn.net";
base_url = "";
$(document).ready(function(){
CC_Comment.initConfig();
CC_Comment.getContent(1);
});
var CC_Comment =
{
sourceid:0,
initConfig:function()
{
var sid = parseInt($(".download_comment").attr("sourceid"));
if(isNaN(sid) || sid<=0)
{
this.sourceid = 0;
}else
{
this.sourceid = sid;
}
}
....
}
жЬАеРОеЄМжЬЫжЦЗзЂ†еѓєдљ†жЬЙжЙАеЄЃеК©еРІпЉБдЄЛдЄАзѓЗеЗЖе§ЗеИЖжЮРдЄЛPythonе¶ВдљХиОЈеПЦJSзЪДиѓДиЃЇдњ°жБѓпЉМеРМжЧґиѓ•зѓЗжЦЗзЂ†еПѓдї•зїЩдљ†жПРдЊЫдЄАзІНзЃАеНХзЪДдЇЇеЈ•еИЖжЮРй°µйЭҐзЪДдЊЛе≠РпЉЫдєЯеПѓдї•иОЈеПЦжЯРдЄ™дЇЇCSDNиµДжЇРдЄЛиљље§ЪгАБеИЖжХ∞йЂШзЪДзїЩдљ†жМСйАЙгАВеЯЇз°АзЯ•иѓЖпЉМдїЕдЊЫеПВиАГ~
пЉИBy:Eastmount 2015-7-21 дЄЛеНИ5зВє http://blog.csdn.net/eastmount/пЉЙ