

[Python] дЄУйҐШдЇФ.еИЧи°®еЯЇз°АзЯ•иѓЖ дЇМзїіlistжОТеЇПгАБиОЈ
йАЪеЄЄжµЛиѓХдЇЇеСШжИЦеЕђеПЄеЃЮдє†дЇЇеСШйЬАи¶Бе§ДзРЖдЄАдЇЫtxtжЦЗжЬђеЖЕеЃєпЉМиАМж≠§жЧґдљњзФ®PythonжШѓжѓФиЊГжЦєдЊњзЪДиѓ≠и®АгАВеЃГдЄНеЕЙеЬ®зИђеПЦзљСдЄКиµДжЦЩдЄКжЦєдЊњпЉМињШеЬ®NLPиЗ™зДґиѓ≠и®Ае§ДзРЖжЦєйЭҐжЛ•жЬЙзЛђеИ∞зЪДдЉШеКњгАВињЩзѓЗжЦЗзЂ†дЄїи¶БзЃАеНХзЪДдїЛзїНдљњзФ®Pythonе§ДзРЖtxtж±Йе≠ЧжЦЗе≠ЧгАБдЇМзїіеИЧи°®жОТеЇПеТМиОЈеПЦlistдЄЛж†ЗгАВеЄМжЬЫжЦЗзЂ†еѓєдљ†жЬЙжЙАеЄЃеК©жИЦжПРдЊЫдЄАдЇЫиІБиІ£~
дЄА. listдЇМзїіжХ∞зїДжОТеЇП
еКЯиГљпЉЪеЈ≤зїПйАЪињЗPythonдїОзїіеЯЇзЩЊзІСдЄ≠иОЈеПЦдЇЖеЫљеЃґзЪДеЫљеЬЯйЭҐзІѓеТМжОТеРНдњ°жБѓпЉМж≠§жЧґйЬАи¶БиОЈеПЦеЫљеЬЯйЭҐзІѓеєґињЫи°МжОТеЇПеИ§жЦ≠дЄЦзХМжОТеРНжШѓеР¶ж≠£з°ЃгАВ
еИЧи°®еЯЇз°АзЯ•иѓЖ
еИЧи°®з±їеЮЛеРМе≠Чзђ¶дЄ≤дЄАж†ЈдєЯжШѓеЇПеИЧеЉПзЪДжХ∞жНЃз±їеЮЛпЉМеПѓдї•йАЪињЗдЄЛж†ЗжИЦеИЗзЙЗжУНдљЬжЭ•иЃњйЧЃжЯРдЄАдЄ™жИЦжЯРдЄАеЭЧињЮзї≠зЪДеЕГзі†гАВеЃГеТМе≠Чзђ¶дЄ≤дЄНеРМдєЛе§ДеЬ®дЇОпЉЪе≠Чзђ¶дЄ≤еП™иГљзФ±е≠Чзђ¶зїДжИРиАМдЄФдЄНеПѓеПШзЪДпЉИдЄНиГљеНХзЛђжФєеПШеЃГзЪДжЯРдЄ™еАЉпЉЙпЉМиАМеИЧи°®жШѓиГљдњЭзХЩдїїжДПжХ∞зЫЃзЪДPythonеѓєи±°зБµжіїеЃєеЩ®гАВ
жАїдєЛпЉМеИЧи°®еПѓдї•еМЕеРЂдЄНеРМз±їеЮЛзЪДеѓєи±°пЉИеМЕжЛђзФ®жИЈиЗ™еЃЪдєЙзЪДеѓєи±°пЉЙдљЬдЄЇеЕГзі†пЉМеИЧи°®еПѓдї•жЈїеК†жИЦеИ†йЩ§еЕГзі†пЉМдєЯеПѓдї•еРИеєґжИЦжЛЖеИЖеИЧи°®пЉМеМЕжЛђinsertгАБupdateгАБremoveгАБsprtгАБreverseз≠ЙжУНдљЬгАВ
еИЧи°®жОТеЇПдїЛзїН
еЄЄзФ®еИЧи°®жОТеЇПжЦєж≥ХеМЕжЛђдљњзФ®ListеЖЕеїЇеЗљжХ∞list.sort()жИЦеЇПеИЧз±їеЮЛеЗљжХ∞sorted(list)жОТеЇП
#list.sort(func=None, key=None, reverse=False)
list = [4, 3, 9, 1, 5, 2]
print list
list.sort()
print list
#иЊУеЗЇ
[4, 3, 9, 1, 5, 2]
[1, 2, 3, 4, 5, 9]
йАЪињЗеѓєжѓФдЄЛйЭҐзЪДдї£з†БпЉМеПѓдї•еПСзО∞дЄ§зІНжЦєж≥ХзЪДеМЇеИЂжШѓпЉЪlist.sort()жФєеПШдЇЖеОЯlistзЪДй°ЇеЇПпЉМиАМsortedж≤°жЬЙгАВ
#sorted(list)
list = ["h", "a", "p", "d", "i", "b"]
print list
print sorted(list)
print list
#иЊУеЗЇ
["h", "a", "p", "d", "i", "b"]
["a", "b", "d", "h", "i", "p"]
["h", "a", "p", "d", "i", "b"]
дЇМзїіеИЧи°®жОТеЇП
йАЪињЗlambdaи°®иЊЊеЉПеЃЮзО∞дЇМзїіеИЧи°®жОТеЇПпЉМеєґдЄФжМЙзЕІзђђдЇМдЄ™еЕ≥йФЃе≠ЧињЫи°МжОТеЇПгАВеПВиАГ
#list.sort(func=None, key=None, reverse=False)
list = [("Tom",4),("Jack",7),("Daly",9),("Mary",1),("God",5),("Yuri",3)]
print list
list.sort(lambda x,y:cmp(x[1],y[1]))
print list
#иЊУеЗЇ
[("Tom", 4), ("Jack", 7), ("Daly", 9), ("Mary", 1), ("God", 5), ("Yuri", 3)]
[("Mary", 1), ("Yuri", 3), ("Tom", 4), ("God", 5), ("Jack", 7), ("Daly", 9)]
йҐШзЫЃдЄ≠е¶ВжЮЬзђђдЄАдЄ™жХ∞е≠ШеВ®жЦЗдїґдЄ≠иѓїеПЦзЪДи°МеПЈпЉМзђђдЇМдЄ™жХ∞е≠ШеВ®дЇЇеП£жХ∞йЗПпЉМж≠§жЧґеПѓеѓєзђђдЇМдЄ™жХ∞ињЫи°МжОТеЇПгАВйЬАи¶Бж≥®жДПзЪДжШѓеЃГдїђдЄАзїД(1,93)жШѓtupleеЕГзїДгАВ
#list.sort(func=None, key=None, reverse=False)
list = [(1,93),(2,71),(3,89),(4,93),(5,85),(6,77)]
print list
list.sort(key=lambda x:x[1])
print list
#иЊУеЗЇ
[(1, 93), (2, 71), (3, 89), (4, 93), (5, 85), (6, 77)]
[(2, 71), (6, 77), (5, 85), (3, 89), (1, 93), (4, 93)]
lambadaи°®иЊЊеЉП
еЬ®дЄКињ∞дї£з†БдЄ≠пЉМе¶ВжЮЬињШдЄНзЯ•йБУlambadaжШѓдїАдєИйђЉдЄЬи•њзЪДиѓЭпЉЯйВ£жИСе∞±жЭ•еЄЃдљ†еЫЮй°ЊдЇЖгАВ
pythonеЕБиЃЄдљњзФ®lambdaеЕ≥йФЃе≠ЧеИЫйА†еМњеРНеЗљжХ∞пЉМеЃГдЄНйЬАи¶Бдї•ж†ЗеЗЖзЪДжЦєеЉПжЭ•е£∞жШОпЉМе¶Вdefиѓ≠еП•гАВзДґиАМдљЬдЄЇеЗљжХ∞пЉМеЃГдїђдєЯиГљжЬЙеПВжХ∞гАВ
lambdaе∞±жШѓдЄАдЄ™и°®иЊЊеЉПпЉМиАМдЄНжШѓдЄАдЄ™дї£з†БеЭЧгАВиАМдЄФињЩдЄ™и°®иЊЊжШѓзЪДеЃЪдєЙењЕй°їеТМе£∞жШОжФЊеЬ®еРМдЄАи°МпЉМиГљеЬ®lambdaдЄ≠е∞Би£ЕжЬЙйЩРзЪДйАїиЊСињЫеОїпЉМиµЈеИ∞дЄАдЄ™еЗљжХ∞йАЯеЖЩзЪДдљЬзФ®гАВдЊЛе¶ВпЉЪ
#lambda [arg1[, arg2, ..., argN]]:expression
f = lambda x,y,z:x+y+z
num = f(1,2,3)
print "lambda: " + str(num)
#з≠ЙдїЈдЇО
def add(x,y,z):
return x+y+z
num = add(1,2,3)
print "function: " + str(num)
#иЊУеЗЇ
lambda: 6
function: 6
дЇМ. е§ДзРЖtxtжЦЗжЬђ
дЄЛйЭҐжШѓйАЪињЗtxtжЦЗдїґжМЙи°МиѓїеПЦпЉМеєґиОЈеПЦйЭҐзІѓињЫи°МжОТеЇПгАВеЕґдЄ≠ж†ЄењГдї£з†Бе¶ВдЄЛпЉЪ
иѓїеПЦжЦЗдїґ&еИЧи°®жЈїеК†
source = open("F:Student1Area.txt","r")
lines = source.readlines()
L = [] #еИЧи°®дЇМзїі еЫљеЃґи°МжХ∞ дЇЇеП£жХ∞
count = 1 #ељУеЙНеЫљеЃґеЬ®жЦЗдїґдЄ≠зђђcountи°М
for line in lines:
line = line.rstrip("
") #еОїйЩ§жНҐи°М
.... #иОЈеПЦжОТеРНеТМйЭҐзІѓ
fNum = string.atof(number) #йЭҐзІѓ
L.append((count,ffNum)) #еИЧи°®жЈїеК†
count = count + 1
else:
print "End While"
source.close()
еИЧи°®жОТеЇП
L.sort(lambda x,y:cmp(x[1],y[1]),reverse = True)
#йБНеОЖињЗз®Л и°®з§ЇзђђiеРН (жЦЗдїґзђђxи°М,йЭҐзІѓyеє≥жЦєеЕђйЗМ)
#йЗНзВє L[i]иЊУеЗЇеИЧи°® 1 (46, 17075200.0) L[i][0]и°®з§ЇеЕГзїДtupleзђђдЄАдЄ™жХ∞ 1 46
for i in range(len(L)):
print (i+1), L[i]
иОЈеПЦйЭҐзІѓе≠Чзђ¶дЄ≤
line = line.rstrip("
") #еОїйЩ§жНҐи°М
start = line.find(r"V:")
end = line.find(r"еє≥жЦєеЕђйЗМ")
number = line[start+2:end]
number = number.replace(",","") #еОїйЩ§","
#иЊУеЗЇ
line => C:еЫљеЃґ E:дЄ≠еНОдЇЇж∞СеЕ±еТМеЫљ A:еЫљеЬЯйЭҐзІѓ V:9,634,057жИЦ9,736,000еє≥жЦєеЕђйЗМпЉИдЄЦзХМзђђ3/4еРНпЉЙ
number => 9634057жИЦ9736000
жЬАеРОеРМжЧґйЬАи¶Бе§ДзРЖеРДзІНе≠Чзђ¶дЄ≤жГЕеЖµпЉМе¶ВвАШжИЦвАЩгАБвАШдЄЗвАЩи¶БдєШ10000гАБеИ†йЩ§вАШ[1]вАЩз≠ЙгАВжЫізЃАеНХзЪДжЦєж≥ХжШѓйАЪињЗж≠£еИЩи°®иЊЊеЉПжИЦиОЈеПЦзђђдЄАдЄ™йЭЮжХ∞е≠Че≠Чзђ¶гАВ
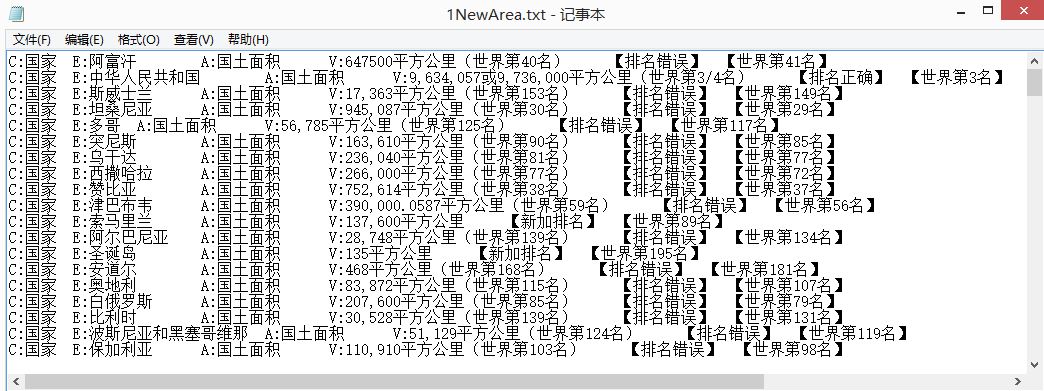
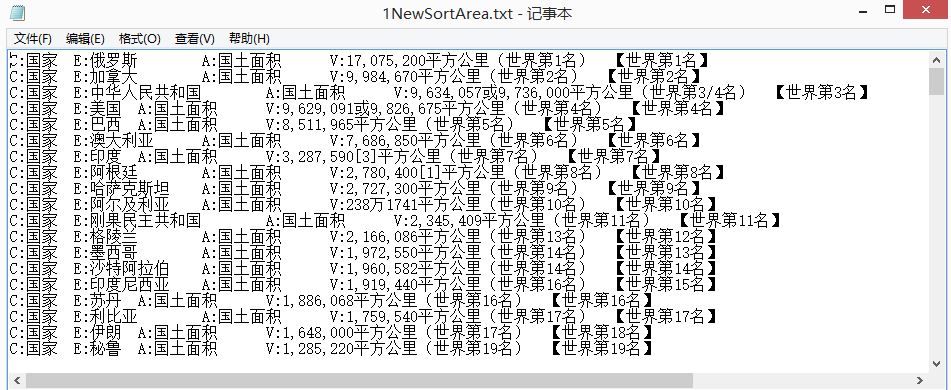
ињРи°МзїУжЮЬе¶ВдЄЛжЙАз§ЇпЉМжОТеЇПеРОзЪДtxtеТМзЇ†йФЩtxtпЉЪ
дї£з†Бе¶ВдЄЛпЉЪ
# coding=utf-8
import time
import re
import os
import string
import sys
source = open("F:Student1Area.txt","r")
lines = source.readlines()
count = 1
L = [] #еИЧи°®дЇМзїі еЫљеЃґи°МжХ∞ дЇЇеП£жХ∞
"""
зђђдЄАйГ®еИЖ иОЈеПЦеЫљеЬЯйЭҐзІѓ
"""
print "Start!!!"
for line in lines:
line = line.rstrip("
") #еОїйЩ§жНҐи°М
start = line.find(r"V:")
end = line.find(r"еє≥жЦєеЕђйЗМ")
number = line[start+2:end]
number = number.replace(",","") #еОїйЩ§","
fNum = 0.0
if "дЄЗ" in number:
end = line.find(r"дЄЗ")
newNum = line[start+2:end]
fNum = string.atof(newNum)*10000
else: #е¶ВдљХдЉШеМЦдї£з†Б еЕ®е±АеПШйЗП
if "/" in number:
end = line.find(r"/")
newNum = line[start+2:end]
newNum = newNum.replace(",","")
fNum = string.atof(newNum)
elif "(" in number:
end = line.find(r"(")
newNum = line[start+2:end]
newNum = newNum.replace(",","")
fNum = string.atof(newNum)
elif "[" in number:
end = line.find(r"[")
newNum = line[start+2:end]
newNum = newNum.replace(",","")
fNum = string.atof(newNum)
elif "жИЦ" in number:
end = line.find(r"жИЦ")
newNum = line[start+2:end]
newNum = newNum.replace(",","")
fNum = string.atof(newNum)
elif " " in number:
end = line.find(r" ")
newNum = line[start+2:end]
newNum = newNum.replace(",","")
fNum = string.atof(newNum)
else:
fNum = string.atof(number)
#print line
#print number
#print fNum
L.append((count,fNum))
count = count + 1
else:
print "End While"
source.close()
"""
зђђдЇМйГ®еИЖ дїОе§ІеИ∞е∞ПжОТеЇП
еПВзЬЛ http://blog.chinaunix.net/uid-20775448-id-4222915.html
"""
L.sort(lambda x,y:cmp(x[1],y[1]),reverse = True)
#print L
#йБНеОЖињЗз®Л и°®з§ЇзђђiеРН (жЦЗдїґзђђxи°М,йЭҐзІѓyеє≥жЦєеЕђйЗМ)
#йЗНзВє L[i]иЊУеЗЇеИЧи°® 1 (46, 17075200.0) L[i][0]и°®з§ЇеЕГзїДtupleзђђдЄАдЄ™жХ∞ 1 46
for i in range(len(L)):
print (i+1), L[i]
"""
зђђдЄЙйГ®еИЖ иѓїеЖЩжЦЗдїґ
"""
source = open("F:Student1Area.txt","r")
lines = source.readlines()
result = open("F:Student1NewArea.txt","w")
count = 1
for line in lines:
line = line.rstrip("
")
#иОЈеПЦеИЧи°®LдЄ≠жОТеРНдљНзљЃpm
pm = 0
for i in range(len(L)):
if count==L[i][0]:
pm = i+1
break
#иОЈеПЦжЦЗдїґдЄ≠еРНжђ°
if "дЄЦзХМзђђ" in line:
start = line.find(r"дЄЦзХМзђђ")
end = line.find(r"еРН")
number = line[start+9:end]
if "/" in number: #йШ≤ж≠ҐдЄ≠еЫљзђђ3/4еРН
end = line.find(r"/")
number = line[start+9:end]
if "еМЕжЛђжµЈе§Ц" in number:
number = "41"
print number,pm,type(number),type(pm)
if string.atoi(number)==pm:
line = line + " гАРжОТеРНж≠£з°ЃгАС гАРдЄЦзХМзђђ" + str(pm) + "еРНгАС"
result.write(line+"
")
else:
line = line + " гАРжОТеРНйФЩиѓѓгАС гАРдЄЦзХМзђђ" + str(pm) + "еРНгАС"
result.write(line+"
")
else: #жЦЗдїґдЄ≠ж≤°жЬЙжОТеРН
line = line + " гАРжЦ∞еК†жОТеРНгАС гАРдЄЦзХМзђђ" + str(pm) + "еРНгАС"
result.write(line+"
")
count = count + 1
else:
print "End Sorted"
source.close()
result.close()
"""
зђђеЫЫйГ®еИЖ иЊУеЗЇдЄАдЄ™жОТеЇПе•љзЪДжЦЗдїґ дЊњдЇОиІВеѓЯ
"""
source = open("F:Student1Area.txt","r")
lines = source.readlines()
result = open("F:Student1NewSortArea.txt","w")
#iи°®з§ЇзђђiеРН L[i][0]и°®з§Їи°МжХ∞
pm = 0
for i in range(len(L)):
pm = L[i][0]
count = 1
for line in lines:
line = line.rstrip("
")
if count==pm:
line = line + " гАРдЄЦзХМзђђ" + str(i+1) + "еРНгАС"
result.write(line+"
")
break
else:
count = count + 1
else:
print "End Sorted Second"
source.close()
result.close()
жЬАеРОеЄМжЬЫжЦЗзЂ†еѓєдљ†жЬЙжЙАеЄЃеК©пЉМжЦЗзЂ†дЄїи¶БйАЪињЗиЃ≤ињ∞дЄАдЄ™еЃЮйЩЕжУНдљЬпЉМеЄЃдљ†еЈ©еЫЇе≠¶дє†lietеИЧи°®зЪДдЇМзїіжОТеЇПеТМе≠Чзђ¶дЄ≤txtе§ДзРЖгАВе¶ВжЮЬжЦЗдЄ≠жЬЙйФЩиѓѓжИЦдЄНиґ≥дєЛе§ДпЉМињШиѓЈжµЈжґµ~
(By:Eastmount 2015-9-16 жЩЪдЄК9зВє http://blog.csdn.net/eastmount/)