

[python] дЄУйҐШеЕЂ.е§ЪзЇњз®ЛзЉЦз®ЛдєЛthreadеТМthre
е∞±дЄ™дЇЇиАМи®АпЉМе≠¶дЇЖињЩдєИе§ЪеєізЪДиѓЊз®ЛеПИеЖЩдЇЖињЩдєИе§ЪеєізЪДз®ЛеЇПпЉМиЩљзДґж≤°жЬЙжґЙеПКеИ∞дЉБдЄЪзЇІзЪДй°єзЫЃпЉМдљЖињШжШѓдљУдЉЪеИ∞дЇЖжЬЙеЗ†дЄ™зЯ•иѓЖзВєжШѓйЭЮеЄЄйЗНи¶БзЪДпЉМеМЕжЛђпЉЪйЭҐеРСеѓєи±°зЪДжАЭжГ≥гАБе¶ВдљХжЮґжЮДдЄАдЄ™й°єзЫЃгАБиЃЊиЃ°ж®°еЉПжЭ•еЕЈдљУиІ£еЖ≥йЧЃйҐШгАБеЇФзФ®жЬЇеЩ®е≠¶дє†еТМжЈ±еЇ¶е≠¶дє†зЪДжЦєж≥ХпЉМељУзДґдєЯеМЕжЛђжИСињЩзѓЗжЦЗзЂ†зЪДеЖЕеЃєвАФвАФе§ЪзЇњз®ЛеТМеєґи°МеМЦе§ДзРЖжХ∞жНЃгАВ
ињЩзѓЗжЦЗзЂ†дЄїи¶БжШѓеПВиАГWesley J. ChunзЪДгАКPythonж†ЄењГзЉЦз®Л(зђђдЇМзЙИ)гАЛдє¶з±Не§ЪзЇњз®ЛйГ®еИЖпЉМеєґзїУеРИжИСдї•еЙНзЪДдЄАдЇЫеЃЮдЊЛињЫи°МзЃАеНХеИЖжЮРгАВе∞§еЕґжШѓеЬ®е§ІжХ∞жНЃгАБHadoopSparkгАБеИЖеЄГеЉПеЉАеПСжµБи°МзЪДдїК姩пЉМињЩдЇЫеЯЇз°АеРМж†ЈеЊИйЗНи¶БгАВеЄМжЬЫеѓєдљ†жЬЙжЙАеЄЃеК©еРІпЉБ
PSпЉЪжО®иНРе§ІеЃґйШЕиѓїгАКPythonж†ЄењГзЉЦз®ЛгАЛеТМгАКPythonеЯЇз°АжХЩз®ЛгАЛдЄ§жЬђдє¶~
еЉЇжО®пЉЪhttp://www.cnblogs.com/huxi/archive/2010/06/26/1765808.html
дЄА. зЇњз®ЛеТМињЫз®ЛзЪДж¶Вењµ
1.дЄЇдїАдєИеЉХеЕ•е§ЪзЇњз®ЛзЉЦз®ЛпЉЯ
еЬ®е§ЪзЇњз®ЛпЉИMultithreadedпЉМMTпЉЙзЉЦз®ЛеЗЇзО∞дєЛеЙНпЉМзФµиДСз®ЛеЇПзЪДињРи°МзФ±дЄАдЄ™жЙІи°МеЇПеИЧзїДжИРпЉМжЙІи°МеЇПеИЧжМЙй°ЇеЇПеЬ®дЄїжЬЇзЪДдЄ≠е§Ѓе§ДзРЖеЩ®CPUдЄ≠ињРи°МгАВеН≥дљњжХідЄ™з®ЛеЇПзФ±е§ЪдЄ™зЫЄдЇТзЛђзЂЛжЧ†еЕ≥зЪДе≠РдїїеК°зїДжИРпЉМз®ЛеЇПйГљдЉЪй°ЇеЇПжЙІи°МгАВ
зФ±дЇОеєґи°Ме§ДзРЖеПѓдї•е§ІеєЕеЇ¶еЬ∞жПРеНЗжХідЄ™дїїеК°зЪДжХИзОЗпЉМжХЕеЉХеЕ•е§ЪзЇњз®ЛзЉЦз®ЛгАВ
е§ЪзЇњз®ЛдЄ≠дїїеК°еЕЈжЬЙдї•дЄЛзЙєзВєпЉЪ
(1) ињЩдЇЫдїїеК°зЪДжЬђиі®жШѓеЉВж≠•зЪДпЉМйЬАи¶БжЬЙе§ЪдЄ™еєґеПСдЇЛеК°пЉЫ
(2) еРДдЄ™дЇЛеК°зЪДињРи°Мй°ЇеЇПеПѓдї•жШѓдЄНз°ЃеЃЪзЪДгАБйЪПжЬЇзЪДгАБдЄНеПѓйҐДжµЛзЪДгАВ
ињЩж†ЈзЪДзЉЦз®ЛдїїеК°еПѓдї•еИЖжИРе§ЪдЄ™жЙІи°МжµБпЉМжѓПдЄ™жµБйГљжЬЙдЄАдЄ™и¶БеЃМжИРзЪДзЫЃж†ЗгАВеЖНж†єжНЃдЄНеРМзЪДеЇФзФ®пЉМињЩдЇЫе≠РдїїеК°еПѓиГљйГљи¶БиЃ°зЃЧеЗЇдЄАдЄ™дЄ≠йЧізїУжЮЬпЉМзФ®дЇОеРИеєґеЊЧеИ∞жЬАеРОзЪДзїУжЮЬгАВ
2.дїАдєИжШѓињЫз®ЛпЉЯ
иЃ°зЃЧжЬЇз®ЛеЇПеП™дЄНињЗжШѓз£БзЫШдЄ≠еПѓжЙІи°МзЪДдЇМињЫеИґпЉИжИЦеЕґдїЦз±їеЮЛпЉЙзЪДжХ∞жНЃгАВеЃГдїђеП™жЬЙеܮ襀胿еПЦеИ∞еЖЕе≠ШдЄ≠пЉМ襀жУНдљЬз≥їзїЯи∞ГзФ®жЧґжЙНеЉАеІЛеЃГдїђзЪДзФЯеСљеС®жЬЯгАВ
ињЫз®ЛпЉИдЇ¶зІ∞дЄЇйЗНйЗПзЇІињЫз®ЛпЉЙжШѓз®ЛеЇПзЪДдЄАжђ°жЙІи°МгАВжѓПдЄ™ињЫз®ЛйГљжЬЙиЗ™еЈ±зЪДеЬ∞еЭАз©ЇйЧігАБеЖЕе≠ШгАБжХ∞жНЃж†ИеПКеЕґдїЦиЃ∞ељХеЕґињРи°Миљ®ињєзЪДиЊЕеК©жХ∞жНЃгАВжУНдљЬз≥їзїЯзЃ°зРЖеЬ®еЕґдЄКињРи°МжЙАжЬЙзЪДињЫз®ЛпЉМеєґдЄЇињЩдЇЫињЫз®ЛеЕђеє≥еИЖйЕНжЧґйЧігАБињЫз®ЛдєЯеПѓдї•йАЪињЗforkеТМspawnжУНдљЬжЭ•еЃМжИРеЕґдїЦзЪДдїїеК°гАВ
дЄНињЗињЫз®ЛжЬЙиЗ™еЈ±зЪДеЖЕе≠Шз©ЇйЧіпЉМжХ∞жНЃж†Из≠ЙпЉМжЙАдї•еП™иГљдљњзФ®ињЫз®ЛйЧійАЪиЃѓпЉИinterprocess communication, IPCпЉЙпЉМиАМдЄНиГљзЫіжО•еЕ±дЇЂдњ°жБѓгАВ
3.дїАдєИжШѓзЇњз®ЛпЉЯ
зЇњз®ЛпЉИдЇ¶зІ∞дЄЇиљїйЗПзЇІињЫз®ЛпЉЙиЈЯињЫз®ЛжЬЙдЇЫзЫЄдЉЉпЉМдЄНеРМзЪДжШѓпЉЪжЙАжЬЙзЪДзЇњз®ЛињРи°МеЬ®еРМдЄАдЄ™ињЫз®ЛдЄ≠пЉМеЕ±дЇЂзЫЄеРМзЪДињРи°МзОѓеҐГгАВеЃГдїђеσ俕襀жГ≥и±°жИРжШѓеЬ®дЄїињЫз®ЛжИЦвАЬдЄїзЇњз®ЛвАЭдЄ≠еєґи°МињРи°МзЪДвАЬињЈдљ†ињЫз®ЛвАЭгАВ
зЇњз®ЛжЬЙеЉАеІЛпЉМй°ЇеЇПжЙІи°МеТМзїУжЭЯдЄЙйГ®еИЖгАВеЃГжЬЙдЄАдЄ™иЗ™еЈ±зЪДжМЗдї§жМЗйТИпЉМиЃ∞ељХиЗ™еЈ±ињРи°МеИ∞дїАдєИеЬ∞жЦєгАВзЇњз®ЛзЪДињРи°МеПѓиÚ襀жКҐеН†пЉИдЄ≠жЦ≠пЉЙжИЦжЪВжЧґзЪД襀жМВиµЈпЉИзЭ°зЬ†пЉЙпЉМиЃ©еЕґдїЦзЇњз®ЛињРи°МпЉМињЩеПЂеБЪиЃ©ж≠•гАВ
дЄАдЄ™ињЫз®ЛдЄ≠зЪДеРДдЄ™зЇњз®ЛдєЛйЧіеЕ±дЇЂеРМдЄАзЙЗжХ∞жНЃз©ЇйЧіпЉМжЙАдї•зЇњз®ЛдєЛйЧіеПѓдї•жѓФињЫз®ЛдєЛйЧіжЫіжЦєдЊњеЬ∞еЕ±дЇЂжХ∞жНЃдї•еПКзЫЄдЇТйАЪиЃѓгАВзЇњз®ЛдЄАиИђйГљжШѓеєґеПСжЙІи°МзЪДпЉМж≠£жШѓзФ±дЇОињЩзІНеєґи°МеТМжХ∞жНЃеЕ±дЇЂзЪДжЬЇеИґдљњеЊЧе§ЪдЄ™дїїеК°зЪДеРИдљЬеПШжИРеПѓиГљгАВ
еЃЮйЩЕдЄКпЉМеЬ®еНХCPUзЪДз≥їзїЯдЄ≠пЉМзЬЯж≠£зЪДеєґеПСжШѓдЄНеПѓиГљзЪДпЉМжѓПдЄ™зЇњз®ЛдЉЪ襀еЃЙжОТжИРжѓПжђ°еП™ињРи°МдЄАе∞ПдЉЪпЉМзДґеРОе∞±жККCPUиЃ©еЗЇжЭ•пЉМиЃ©еЕґдїЦзЪДзЇњз®ЛеОїињРи°МгАВеЬ®ињЫз®ЛзЪДжХідЄ™ињРи°МињЗз®ЛдЄ≠пЉМжѓПдЄ™зЇњз®ЛйГљеП™еБЪиЗ™еЈ±зЪДдЇЛпЉМеЬ®йЬАи¶БзЪДжЧґеАЩиЈЯеЕґдїЦзЪДзЇњз®ЛеЕ±дЇЂињРи°МзЪДзїУжЮЬгАВ
ељУзДґпЉМињЩж†ЈзЪДеЕ±дЇЂеєґдЄНжШѓеЃМеЕ®ж≤°жЬЙеН±йЩ©зЪДгАВе¶ВжЮЬе§ЪдЄ™зЇњз®ЛеЕ±еРМиЃњйЧЃеРМдЄАзЙЗжХ∞жНЃпЉМеИЩзФ±дЇОжХ∞жНЃиЃњйЧЃзЪДй°ЇеЇПдЄНеРМпЉМжЬЙеПѓиГљеѓЉиЗіжХ∞жНЃзїУжЮЬзЪДдЄНдЄАиЗізЪДйЧЃйҐШпЉМеН≥зЂЮжАБжЭ°дїґпЉИrace conditionпЉЙгАВеРМж†ЈпЉМе§Іе§ЪжХ∞зЇњз®ЛеЇУйГљеЄ¶жЬЙдЄАдЇЫеИЧзЪДеРМж≠•еОЯиѓ≠пЉМжЭ•жОІеИґзЇњз®ЛзЪДжЙІи°МеТМжХ∞жНЃзЪДиЃњйЧЃгАВ
еП¶дЄАдЄ™йЬАи¶Бж≥®жДПзЪДжШѓзФ±дЇОжЬЙзЪДеЗљжХ∞дЉЪеЬ®еЃМжИРдєЛеЙНйШїе°ЮдљПпЉМеЬ®ж≤°жЬЙзЙєеИЂдЄЇе§ЪзЇњз®ЛеБЪдњЃжФєзЪДжГЕеЖµдЄЛпЉМињЩзІНвАЬиі™е©™вАЭзЪДеЗљжХ∞дЉЪиЃ©CPUзЪДжЧґйЧіеИЖйЕНжЬЙжЙАеАЊжЦЬпЉМеѓЉиЗіеРДдЄ™зЇњз®ЛеИЖйЕНеИ∞зЪДињРи°МжЧґйЧіеПѓиГљдЄНе∞љзЫЄеРМпЉМдЄНе∞љеЕђеє≥гАВ
4.зЃАињ∞ињЫз®ЛеТМзЇњз®ЛзЪДеМЇеИЂ
еПВиАГдЄЛйЭҐдЄЙзѓЗжЦЗзЂ†пЉЪ
ињЫз®ЛеТМзЇњз®ЛеЕ≥з≥їеПКеМЇеИЂ -¬†yaosiming2011
ињЫз®ЛдЄОзЇњз®ЛзЪДеМЇеИЂ -¬†flashsky
еЇФе±КзФЯзїПеЕЄйЭҐиѓХйҐШпЉЪиѓіиѓіињЫз®ЛдЄОзЇњз®ЛзЪДеМЇеИЂдЄОиБФз≥ї -¬†way_testlife
дЇМ. PythonзЇњз®ЛеТМеЕ®е±АиІ£йЗКеЩ®йФБ
1.еЕ®е±АиІ£йЗКеЩ®йФБ(GIL)
Pythonдї£з†БзЪДжЙІи°МзФ±PythonиЩЪжЛЯжЬЇпЉИдєЯеПЂиІ£йЗКеЩ®дЄїеЊ™зОѓпЉЙжЭ•жОІеИґгАВPythonеЬ®иЃЊзљЃдєЛеИЭе∞±иАГиЩСеИ∞и¶БеЬ®дЄїеЊ™зОѓдЄ≠пЉМеРМжЧґеП™жЬЙдЄАдЄ™зЇњз®ЛеЬ®жЙІи°МпЉМе∞±еГПеНХCPUзЪДз≥їзїЯдЄ≠ињРи°Ме§ЪдЄ™ињЫз®ЛйВ£ж†ЈпЉМеЖЕе≠ШдЄ≠еПѓдї•е≠ШжФЊе§ЪдЄ™з®ЛеЇПпЉМдљЖдїїжДПжЧґеИїпЉМеП™жЬЙдЄАдЄ™з®ЛеЇПеЬ®CPUдЄ≠ињРи°МгАВеРМж†ЈпЉМиЩљзДґPythonиІ£йЗКеЩ®еПѓдї•вАЬињРи°МвАЭе§ЪдЄ™зЇњз®ЛпЉМдљЖдїїжДПжЧґеИїпЉМеП™жЬЙдЄАдЄ™зЇњз®ЛеЬ®иІ£йЗКеЩ®дЄ≠ињРи°МгАВ
еѓєPythonиЩЪжЛЯжЬЇзЪДиЃњйЧЃзФ±еЕ®е±АиІ£йЗКеЩ®йФБпЉИglobal interpreter lockпЉМGILпЉЙжЭ•жОІеИґпЉМж≠£жШѓињЩдЄ™йФБиГљдњЭиѓБеРМдЄАжЧґеИїеП™жЬЙдЄАдЄ™зЇњз®ЛеЬ®ињРи°МгАВеЬ®е§ЪзЇњз®ЛзОѓеҐГдЄ≠пЉМPythonиЩЪжЛЯжЬЇжМЙдЄАдЄЛжЦєеЉПжЙІи°МпЉЪ
(1) иЃЊзљЃGIL
(2) еИЗжНҐеИ∞дЄАдЄ™зЇњз®ЛеОїињРи°М
(3) ињРи°МпЉЪ
a. жМЗеЃЪжХ∞йЗПзЪДе≠ЧиКВз†БзЪДжМЗдї§пЉМжИЦиАЕ
b. зЇњз®ЛдЄїеК®иЃ©еЗЇжОІеИґпЉИеПѓдї•и∞ГзФ®time.sleep(0)пЉЙ
(4) жККзЇњз®ЛиЃЊзљЃдЄЇзЭ°зЬ†зКґжАБ
(5) иІ£йФБGIL
(6) еЖНжђ°йЗНе§Ндї•дЄКжЙАжЬЙж≠•й™§
еЬ®и∞ГзФ®е§ЦйГ®дї£з†БпЉИе¶ВC/C++жЙ©е±ХеЗљжХ∞пЉЙзЪДжЧґеАЩпЉМGILе∞ЖдЉЪ襀йФБеЃЪпЉМзЫіеИ∞ињЩдЄ™еЗљжХ∞зїУжЭЯдЄЇж≠ҐпЉИзФ±дЇОињЩжЬЯйЧіж≤°жЬЙPythonзЪДе≠ЧиКВз†Б襀ињРи°МпЉМжЙАдї•дЄНдЉЪеБЪзЇњз®ЛеИЗжНҐпЉЙгАВзЉЦеЖЩжЙ©е±ХзЪДз®ЛеЇПеСШеПѓдї•дЄїеК®иІ£йФБGILгАВдЄНињЗPythonеЉАеПСдЇЇеСШеИЩдЄНзФ®жЛЕењГеЬ®ињЩдЇЫжГЕеЖµдЄЛдљ†зЪДPythonдї£з†БдЉЪ襀йФБдљПгАВ
еѓєжЇРдї£з†БпЉМиІ£йЗКеЩ®дЄїеЊ™зОѓеТМGILжДЯеЕіиґ£зЪДдЇЇпЉМеПѓдї•зЬЛзЬЛPython/ceval.cжЦЗдїґгАВ
2.йААеЗЇзЇњз®Л
ељУдЄАдЄ™зЇњз®ЛзїУжЭЯиЃ°зЃЧпЉМеЃГе∞±йААеЗЇдЇЖгАВзЇњз®ЛеПѓдї•и∞ГзФ®thread.exit()дєЛз±їзЪДйААеЗЇеЗљжХ∞пЉМдєЯеПѓдї•дљњзФ®PythonйААеЗЇињЫз®ЛзЪДж†ЗеЗЖжЦєж≥ХпЉМе¶Вsys.exit()жИЦжКЫеЗЇдЄАдЄ™SystemExitеЉВеЄЄз≠ЙгАВдЄНињЗпЉМдљ†дЄНеПѓдї•зЫіжО•жЭАжОЙKillдЄАдЄ™зЇњз®ЛгАВ
еРОйЭҐдЉЪиЃ≤ињ∞дЄ§дЄ™дЄОзЇњз®ЛзЫЄеЕ≥зЪДж®°еЭЧпЉМеЬ®ињЩдЄ§дЄ™ж®°еЭЧдЄ≠пЉМиѓ•дє¶дЄ≠дЄНеїЇиЃЃдљњзФ®threadж®°еЭЧгАВдЄїи¶БеОЯеЫ†жШѓељУдЄїзЇњз®ЛйААеЗЇзЪДжЧґеАЩпЉМеЕґдїЦжЙАжЬЙзЇњз®Лж≤°жЬЙ襀жЄЕйЩ§е∞±йААеЗЇдЇЖгАВиАМthreadingж®°еЭЧе∞±иГљз°ЃдњЭжЙАжЬЙвАЬйЗНи¶БзЪДвАЭе≠РзЇњз®ЛйГљйААеЗЇеРОпЉМињЫз®ЛжЙНдЉЪзїУжЭЯгАВ
дЄїзЇњз®ЛеЇФиѓ•жШѓдЄАдЄ™е•љзЪДзЃ°зРЖиАЕпЉМеЃГи¶БдЇЖиІ£жѓПдЄ™зЇњз®ЛйГљи¶БеБЪдЇЫдїАдєИдЇЛпЉМзЇњз®ЛйГљйЬАи¶БдїАдєИжХ∞жНЃеТМдїАдєИеПВжХ∞пЉМдї•еПКеЬ®зЇњз®ЛзїУжЭЯзЪДжЧґеАЩпЉМеЃГдїђйГљжПРдЊЫдЇЖдїАдєИзїУжЮЬгАВињЩж†ЈпЉМдЄїзЇњз®Ле∞±еПѓдї•жККеРДдЄ™зЇњз®ЛзЪДзїУжЮЬзїДжИРдЄАдЄ™жЬЙжДПдєЙзЪДжЬАеРОзїУжЮЬгАВ
еЬ®Python2.7дЇ§дЇТеЉПиІ£йЗКеЩ®дЄ≠еѓЉеЕ•import threadж≤°жЬЙжК•йФЩеН≥и°®з§ЇзЇњз®ЛеПѓзФ®гАВ
3.ж≤°жЬЙзЇњз®ЛзЪДдЊЛе≠Р
дљњзФ®time.sleep()еЗљжХ∞жЭ•жЉФз§ЇзЇњз®ЛзЪДеЈ•дљЬпЉМињЩдЄ™дЊЛе≠РдЄїи¶БдЄЇеРОйЭҐзЇњз®ЛеБЪеѓєжѓФгАВtime.sleep()йЬАи¶БдЄАдЄ™жµЃзВєеЮЛзЪДеПВжХ∞пЉМжЭ•жМЗеЃЪвАЬзЭ°зЬ†вАЭзЪДжЧґйЧіпЉИеНХдљНзІТпЉЙгАВињЩе∞±зЫЄељУдЇОз®ЛеЇПзЪДињРи°МдЉЪ襀жМВиµЈжМЗеЃЪзЪДжЧґйЧігАВ
дї£з†БиІ£йЗКпЉЪдЄ§дЄ™иЃ°жЧґеЩ®пЉМloop0зЭ°зЬ†4зІТпЉМloop1()зЭ°зЬ†2зІТпЉМеЃГдїђжШѓеЬ®дЄАдЄ™ињЫз®ЛжИЦиАЕзЇњз®ЛдЄ≠пЉМй°ЇеЇПеЬ∞жЙІи°Мloop0()еТМloop1()пЉМйВ£жАїињРи°МжЧґйЧідЄЇ6зІТгАВжЬЙеПѓиГљеРѓеК®ињЗз®ЛдЄ≠дЉЪеЖНиК±дЇЫжЧґйЧігАВ
from time import sleep, ctime
def loop0():
print "Start loop 0 at:", ctime()
sleep(4)
print "Loop 0 done at:", ctime()
def loop1():
print "Start loop 1 at:", ctime()
sleep(2)
print "Loop 1 done at:", ctime()
def main():
print "Starting at:", ctime()
loop0()
loop1()
print "All done at:", ctime()
if __name__ == "__main__":
main()
дї£з†БзЪДињРи°МзїУжЮЬе¶ВдЄЛеЫЊжЙАз§ЇпЉМеЃГе∞ЖеТМеРОйЭҐзЪДеєґи°Мдї£з†БеБЪеѓєжѓФгАВ

4.йБњеЕНдљњзФ®threadж®°еЭЧ
PythonжПРдЊЫдЇЖеЗ†дЄ™зФ®дЇОе§ЪзЇњз®ЛзЉЦз®ЛзЪДж®°еЭЧпЉМеМЕжЛђthreadгАБthreadingеТМQueueз≠ЙгАВ
(1) threadж®°еЭЧ: еЕБиЃЄз®ЛеЇПеСШеИЫеїЇеТМзЃ°зРЖзЇњз®ЛпЉМеЃГжПРдЊЫдЇЖеЯЇжЬђзЪДзЇњз®ЛеТМйФБзЪДжФѓжМБгАВ
(2) threadingж®°еЭЧ: еЕБиЃЄз®ЛеЇПеСШеИЫеїЇеТМзЃ°зРЖзЇњз®ЛпЉМеЃГжПРдЊЫдЇЖжЫійЂШзЇІеИЂпЉМжЫіеЉЇзЪДзЇњз®ЛзЃ°зРЖзЪДеКЯиГљгАВ
(3) Queueж®°еЭЧ: еЕБиЃЄзФ®жИЈеИЫеїЇдЄАдЄ™еПѓзФ®дЇОе§ЪдЄ™зЇњз®ЛйЧіеЕ±дЇЂжХ∞жНЃзЪДйШЯеИЧжХ∞жНЃзїУжЮДгАВ
дЄЛйЭҐзЃАеНХеИЖжЮРдЄЇдїАдєИйЬАи¶БйБњеЕНдљњзФ®threadж®°еЭЧпЉЯ
(1) й¶ЦеЕИжЫійЂШзЇІеИЂзЪДthreadingж®°еЭЧжЫідЄЇеЕИињЫпЉМеѓєзЇњз®ЛзЪДжФѓжМБжЫідЄЇеЃМеЦДпЉМиАМдЄФдљњзФ®threadж®°еЭЧйЗМзЪДе±ЮжАІжЬЙеПѓиГљдЉЪдЄОthreadingеЗЇзО∞еЖ≤з™БгАВ
(2) еЕґжђ°пЉМдљОзЇІеИЂзЪДthreadж®°еЭЧзЪДеРМж≠•еОЯиѓ≠еЊИе∞СпЉИеЃЮйЩЕеП™жЬЙдЄАдЄ™пЉЙпЉМиАМthreadingж®°еЭЧеИЩжЬЙеЊИе§ЪгАВ
(3) еП¶дЄАдЄ™еОЯеЫ†жШѓthreadеѓєдљ†зЪДињЫз®ЛдїАдєИжЧґеАЩеЇФиѓ•зїУжЭЯеЃМеЕ®ж≤°жЬЙжОІеИґпЉМељУдЄїзЇњз®ЛзїУжЭЯжЧґпЉМжЙАжЬЙзЪДзЇњз®ЛйГљдЉЪ襀劯еИґзїУжЭЯжОЙпЉМж≤°жЬЙи≠¶еСКдєЯдЄНдЉЪжЬЙж≠£еЄЄзЪДжЄЕйЩ§еЈ•дљЬгАВиАМthreadingж®°еЭЧиГљз°ЃдњЭйЗНи¶БзЪДе≠РзЇњз®ЛйААеЗЇеРОињЫз®ЛжЙНйААеЗЇгАВ
ељУзДґпЉМдЄЇдЇЖдљ†жЫіе•љзЪДзРЖиІ£зЇњз®ЛпЉМињШжШѓдЉЪеѓєthreadињЫи°МиЃ≤иІ£гАВдљЖжШѓжИСдїђеП™еїЇиЃЃйВ£дЇЫжЬЙзїПй™МзЪДдЄУеЃґжГ≥иЃњйЧЃзЇњз®ЛзЪДеЇХе±ВзїУжЮДжЧґпЉМжЙНдљњзФ®threadж®°еЭЧгАВиАМе¶ВжЮЬеПѓдї•пЉМдљ†зЪДзђђдЄАдЄ™зЇњз®Лз®ЛеЇПеЇФе∞љеПѓиГљдљњзФ®threadingз≠ЙйЂШзЇІеИЂзЪДж®°еЭЧгАВ
 
дЄЙ. threadж®°еЭЧ
1.еЯЇз°АзЯ•иѓЖ
й¶ЦеЕИжЭ•зЬЛзЬЛthreadж®°еЭЧйГљжПРдЊЫдЇЖдЇЫдїАдєИгАВйЩ§дЇЖдЇІзФЯзЇњз®Ле§ЦпЉМthreadж®°еЭЧдєЯжПРдЊЫдЇЖеЯЇжЬђзЪДеРМж≠•жХ∞жНЃзїУжЮДйФБеѓєи±°пЉИlock objectпЉМдєЯеПЂеОЯиѓ≠йФБгАБзЃАеНХйФБгАБдЇТжЦ•йФБгАБдЇТжЦ•йЗПгАБдЇМеАЉдњ°еПЈйЗПпЉЙгАВеРМж≠•еОЯиѓ≠дЄОзЇњз®ЛзЪДзЃ°зРЖжШѓеѓЖдЄНеПѓеИЖзЪДгАВ
еЄЄзФ®зЪДзЇњз®Лж®°еЭЧеЗљжХ∞
ж®°еЭЧеЗљжХ∞ | жППињ∞ |
start_new_thread(function, args kwargs=None) | дЇІзФЯдЄАдЄ™жЦ∞зЇњз®ЛпЉМеЬ®жЦ∞зЇњз®ЛдЄ≠зФ®жМЗеЃЪзЪДеПВжХ∞еТМеПѓйАЙзЪДkwargsжЭ•и∞ГзФ®иѓ•еЗљжХ∞ |
allocate_lock() | еИЖйЕНдЄАдЄ™LockTypeз±їеЮЛзЪДйФБеѓєи±° |
exit() | иЃ©зЇњз®ЛйААеЗЇ |
LockTypeз±їеЮЛйФБеѓєи±°жЦє
з±їеЮЛйФБеѓєи±°жЦєж≥Х | жППињ∞ |
acquire(wait=None) | е∞ЭиѓХиОЈеПЦйФБеѓєи±° |
locked() | е¶ВжЮЬиОЈеПЦдЇЖйФБеѓєи±°ињФеЫЮTrueпЉМеР¶еИЩињФеЫЮFalse |
release() | йЗКжФЊйФБ |
start_new_thread()еЗљжХ∞жШѓthreadж®°еЭЧзЪДдЄАдЄ™еЕ≥йФЃеЗљжХ∞пЉМеЃГзЪДиѓ≠ж≥ХеТМеЖЕеїЇзЪДapply()еЗљжХ∞дЄАж†ЈпЉМеЕґеПВжХ∞дЄЇпЉЪеЗљжХ∞пЉМеЗљжХ∞зЪДеПВжХ∞дї•еПКеПѓйАЙзЪДеЕ≥йФЃе≠ЧзЪДеПВжХ∞гАВдЄНеРМзЪДжШѓпЉМеЗљжХ∞дЄНжШѓеЬ®дЄїзЇњз®ЛйЗМињРи°МпЉМиАМжШѓдЇІзФЯдЄАдЄ™жЦ∞зЪДзЇњз®ЛжЭ•ињРи°МињЩдЄ™еЗљжХ∞гАВ
2.Threadж®°еЭЧеЃЮзО∞дї£з†Б
зО∞еЬ®еЃЮзО∞дЄАдЄ™зЇњз®ЛзЪДдї£з†БпЉМдЄОеЙНйЭҐж≤°жЬЙзЇњз®ЛжАїињРи°МжЧґйЧідЄЇ6зІТзЪДињЫи°МеѓєжѓФгАВ
import thread
from time import sleep, ctime
def loop0():
print "Start loop 0 at:", ctime()
sleep(4)
print "Loop 0 done at:", ctime()
def loop1():
print "Start loop 1 at:", ctime()
sleep(2)
print "Loop 1 done at:", ctime()
def main():
try:
print "Starting at:", ctime()
thread.start_new_thread(loop0, ())
thread.start_new_thread(loop1, ())
sleep(6)
print "All done at:", ctime()
except Exception,e:
print "Error:",e
finally:
print "END
"
if __name__ == "__main__":
main()
дї£з†БиІ£йЗКпЉЪ
дљњзФ®threadж®°еЭЧжПРдЊЫзЃАеНХзЪДйҐЭе§ЪзЇњз®ЛжЬЇеИґгАВloop0еТМloop1еєґеПСеЬ∞襀жЙІи°МпЉИжШЊзДґпЉМзЯ≠зЪДйВ£дЄ™еЕИзїУжЭЯпЉЙпЉМжАїзЪДињРи°МжЧґйЧідЄЇжЬАжЕҐзЪДйВ£дЄ™зЇњз®ЛзЪДињРи°МжЧґйЧіпЉМиАМдЄНжШѓжЙАжЬЙзЪДзЇњз®ЛзЪДињРи°МжЧґйЧідєЛеТМгАВstart_new_thread()и¶Бж±ВдЄАеЃЪи¶БжЬЙеЙНдЄ§дЄ™еПВжХ∞пЉМеН≥дљњињРи°МзЪДеЗљжХ∞дЄНи¶БеПВжХ∞пЉМдєЯи¶БдЉ†дЄАдЄ™з©ЇзЪДеЕГзїДгАВ
зФ±дЇОйЗЗзФ®Python IDLEињРи°МжАїжШѓжК•йФЩRuntimeпЉМиАМдЄФеЈ≤зїПиЃЊзљЃдЇЖsleep(6)гАВињРи°МдЄАдЄ™зЇњз®ЛеЛЙеЉЇиГљињРи°МпЉМдЄ§дЄ™зЇњз®ЛжЧ†иЃЇжШѓthreadжИЦthreadingйГљжК•йФЩпЉМдЉ∞иЃ°зОѓеҐГйЕНзљЃйЧЃйҐШгАВ
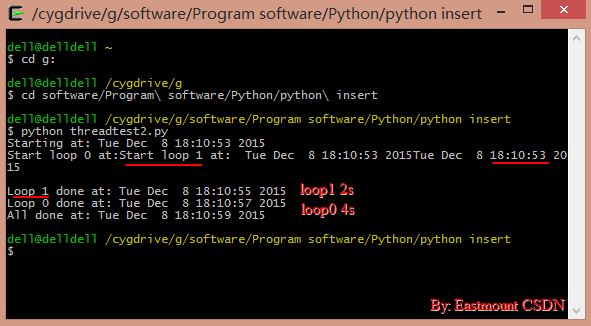
жЬАеРОйЗЗзФ®Cygwin Terminalж®°жЛЯLinuxдЄЛињРи°Мз®ЛеЇПгАВеПѓдї•еПСзО∞loop1еТМloop0жШѓеєґеПСжЙІи°МзЪДпЉМеЕґдЄ≠loop1еЕИзїУжЭЯињРи°М2зІТпЉМиАМloop0ињРи°М4зІТгАВ
еРМжЧґз®ЛеЇПдЄїеЗљжХ∞дЄ≠е§ЪдЇЖдЄ™sleep(6)пЉМдЄЇдїАдєИи¶БеК†ињЩдЄАеП•иѓЭеСҐпЉЯ
еЫ†дЄЇе¶ВжЮЬжИСдїђж≤°жЬЙиЃ©дЄїзЇњз®ЛеБЬдЄЛжЭ•пЉМйВ£дЄїзЇњз®Ле∞±дЉЪињРи°МдЄЛдЄАжЭ°иѓ≠еП•пЉМжШЊз§ЇвАЬAll doneвАЭпЉМзДґеРОе∞±еЕ≥йЧ≠ињРи°МзЭАloop0еТМloop1зЪДдЄ§дЄ™зЇњз®ЛпЉМйААеЗЇдЇЖгАВ
жИСдїђж≤°жЬЙеЖЩиЃ©дЄїзЇњз®ЛеБЬдЄЛжЭ•з≠ЙжЙАжЬЙе≠РзЇњз®ЛзїУжЭЯеРОеЖНзїІзї≠ињРи°МзЪДдї£з†БпЉМињЩе∞±жШѓеЙНйЭҐжЙАиѓізЪДйЬАи¶БеРМж≠•зЪДеОЯеЫ†гАВеЬ®ињЩйЗМпЉМжИСдїђдљњзФ®sleep(6)дљЬдЄЇеРМж≠•жЬЇеИґгАВиЃЊзљЃ6зІТпЉМдЄ§дЄ™зЇњз®ЛдЄАдЄ™4зІТпЉИ53-57пЉЙпЉМдЄАдЄ™2зІТпЉИ53-55пЉЙпЉМеЬ®дЄїзЇњз®Лз≠ЙеЊЕ6зІТпЉИ53-59пЉЙеРОеЇФиѓ•еЈ≤зїПзїУжЭЯдЇЖгАВ
cygwinйЬАи¶БзФ®еИ∞зЪДеЄЄиІБзФ®ж≥ХеМЕжЛђпЉМдєЯеПѓдї•еЃЙи£ЕVIMзЉЦиЊСеЩ®пЉЪ
¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬†cd c: ¬† ¬†гААгААгААгААгААгАА ¬†ињЫеЕ• "c:" зЫЃељХпЉМз©Їж†ЉзФ®" "иљђдєЙе≠Чзђ¶
¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬†pwd ¬† ¬† ¬†гААгААгАА гААгАА ¬† жШЊз§ЇеЈ•дљЬиЈѓеЊД
¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬†ls ¬† ¬† ¬† ¬† гААгААгААгААгААгААжЯ•зЬЛзЫЃељХдЄ≠зЪДжЦЗдїґ
¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬†file test.py ¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬† жЯ•зЬЛжЦЗдїґеЖЕеЃє
¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬† ¬†python test.py ¬† ¬† ¬† ¬† ¬†ињРи°Мpythonз®ЛеЇП
йЕНзљЃжЦєж≥ХиІБпЉЪhttp://blog.sina.com.cn/s/blog_691ebcfc0101lgme.html
дЄЛиљљеЬ∞еЭАиІБпЉЪhttp://pan.baidu.com/s/1jGYEtro
3.зЇњз®ЛеК†йФБжЦєж≥Х
йВ£дєИпЉМжЬЙдїАдєИе•љзЪДзЃ°зРЖзЇњз®ЛзЪДжЦєж≥ХеСҐпЉЯиАМдЄНжШѓеЬ®дЄїзЇњз®ЛйЗМеБЪдЄ™йҐЭе§ЦзЪДеїґжЧґ6зІТжУНдљЬгАВеЫ†дЄЇжАїзЪДињРи°МжЧґйЧіеєґдЄНжѓФеНХзЇњз®ЛзЪДдї£з†Бе∞СпЉЫиАМдЄФдљњзФ®sleep()еЗљжХ∞еБЪзЇњз®ЛзЪДеРМж≠•жУНдљЬжШѓдЄНеПѓйЭ†зЪДпЉЫе¶ВжЮЬеЊ™зОѓзЪДжЙІи°МжЧґйЧідЄНиГљдЇЛеЕИз°ЃеЃЪзЪДиѓЭпЉМињЩеПѓиГљдЉЪйА†жИРдЄїзЇњз®ЛињЗжЧ©жИЦињЗжЩЪзЪДйААеЗЇгАВ
ињЩе∞±йЬАи¶БеЉХеЕ•йФБзЪДж¶ВењµгАВдЄЛйЭҐдї£з†БжЙІи°МloopеЗљжХ∞пЉМдЄОеЙНйЭҐдї£з†БзЪДеМЇеИЂжШѓдЄНзФ®дЄЇзЇњз®ЛдїАдєИжЧґеАЩзїУжЭЯеЖНеБЪйҐЭе§ЦзЪДз≠ЙеЊЕдЇЖгАВдљњзФ®йФБдєЛеРОпЉМеПѓдї•еЬ®дЄ§дЄ™зЇњз®ЛйГљйААеЗЇеРОпЉМй©ђдЄКйААеЗЇгАВ
#coding=utf-8
import thread
from time import sleep, ctime
loops = [4,2] #з≠ЙеЊЕжЧґйЧі
#йФБеЇПеПЈ з≠ЙеЊЕжЧґйЧі йФБеѓєи±°
def loop(nloop, nsec, lock):
print "start loop", nloop, "at:", ctime()
sleep(nsec)
print "loop", nloop, "done at:", ctime()
lock.release() #иІ£йФБ
def main():
print "starting at:", ctime()
locks =[]
nloops = range(len(loops)) #дї•loopsжХ∞зїДеИЫеїЇеИЧи°®еєґиµЛеАЉзїЩnloops
for i in nloops:
lock = thread.allocate_lock() #еИЫеїЇйФБеѓєи±°
lock.acquire() #иОЈеПЦйФБеѓєи±° еК†йФБ
locks.append(lock) #ињљеК†еИ∞locks[]жХ∞зїДдЄ≠
#жЙІи°Ме§ЪзЇњз®Л (еЗљжХ∞еРН,еЗљжХ∞еПВжХ∞)
for i in nloops:
thread.start_new_thread(loop,(i,loops[i],locks[i]))
#еЊ™зОѓз≠ЙеЊЕй°ЇеЇПж£АжЯ•жѓПдЄ™жЙАйГљиҐЂиІ£йФБжЙНеБЬж≠Ґ
for i in nloops:
while locks[i].locked():
pass
print "all end:", ctime()
if __name__ == "__main__":
main()
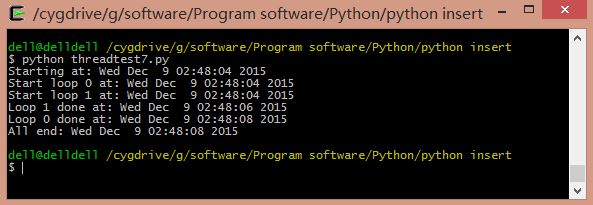
ињРи°МзїУжЮЬе¶ВдЄЛпЉЪ
Starting at: Tue Dec  8 21:57:56 2015
Start loop 0 at: Tue Dec  8 21:57:56 2015
Start loop 1 at: Tue Dec  8 21:57:56 2015
Loop 1 done at: Tue Dec  8 21:57:58 2015
Loop 0 done at: Tue Dec  8 21:58:00 2015
All end: Tue Dec  8 21:58:00 2015
жИСдїђеЬ®еЗљжХ∞дЄ≠иЃ∞ељХдЄЛеЊ™зОѓзЪДеПЈз†БеТМзЭ°зЬ†зЪДжЧґйЧіпЉМеРМжЧґжѓПдЄ™зЇњз®ЛйГљдЉЪ襀еИЖйЕНдЄАдЄ™дЇЛеЕИеЈ≤зїПиОЈеЊЧзЪДйФБпЉМеЬ®sleep()зЪДжЧґйЧіеИ∞дЇЖдєЛеРОе∞±йЗКжФЊзЫЄеЇФзЪДйФБдї•йАЪзЯ•дљПзЇњз®ЛпЉМињЩдЄ™зЇњз®ЛеЈ≤зїПзїУжЭЯдЇЖгАВ
(1) loops[4, 2]еЃЪдєЙзЭ°зЬ†жЧґйЧі nloops=range(len(loops))еИЫеїЇеИЧи°®[0, 1] еПЈз†БпЉЫ
(2) и∞ГзФ®thread.allocate_lock()еЗљжХ∞еИЫеїЇдЄАдЄ™йФБзЪДеИЧи°®пЉМеєґеИЖеИЂи∞ГзФ®еРДдЄ™йФБзЪДacquire()еЗљжХ∞иОЈеЊЧйФБеѓєи±°гАВиОЈеЊЧйФБи°®з§ЇвАЬжККйФБйФБдЄКвАЭпЉМеєґжФЊеИ∞йФБеИЧи°®locksдЄ≠пЉЫ
(3) еЖНеЊ™зОѓеИЫеїЇзЇњз®ЛпЉМи∞ГзФ®thread.start_new_thread(loop,(i,loops[i],locks[i]))гАВеПВжХ∞еѓєеЇФзЇњз®ЛеЊ™зОѓеПЈгАБзЭ°зЬ†жЧґйЧіеТМйФБгАВ
(4) еЬ®зЇњз®ЛзїУжЭЯжЧґпЉМйЬАи¶БеБЪиІ£йФБжУНдљЬпЉМи∞ГзФ®lock.release()еЗљжХ∞пЉЫ
(5) жЬАеРОдЄАдЄ™еЊ™зОѓжШѓеЭРеЬ®йВ£дЄАзЫіз≠ЙеЊЕпЉИиЊЊеИ∞жЪВеБЬдЄїзЇњз®ЛзЪДзЫЃзЪДпЉЙпЉМзЫіеИ∞дЄ§дЄ™йФБйГљиҐЂиІ£йФБжЙНзїІзї≠ињРи°МгАВеЃГжШѓй°ЇеЇПж£АжЯ•жѓПдЄ™йФБпЉМдЄїзЇњз®ЛйЬАдЄНеБЬеЬ∞еѓєжЙАжЬЙйФБињЫи°Мж£АжЯ•зЫіеИ∞йГљйЗКжФЊгАВ
дЄЇдїАдєИжИСдїђдЄНеЬ®еИЫеїЇйФБзЪДеЊ™зОѓйЗМеИЫеїЇзЇњз®ЛеСҐпЉЯдЄАжЦєйЭҐжШѓжГ≥еЃЮзО∞зЇњз®ЛзЪДеРМж≠•пЉМжЙАдї•и¶БиЃ©вАЬжЙАжЬЙзЪДй©ђеРМжЧґеЖ≤еЗЇж†Еж†ПвАЭпЉЫеП¶е§ЦиОЈеПЦйФБи¶БиК±дЇЫжЧґйЧіпЉМе¶ВжЮЬзЇњз®ЛйААеǯ姙圀пЉМеПѓиГљеѓЉиЗіињШж≤°жЬЙиОЈеЊЧйФБпЉМзЇњз®Ле∞±еЈ≤зїПзїУжЭЯдЇЖгАВ
жЬАеРОеЖНеЉЇи∞ГдЄЛпЉМthreadж®°еЭЧдїЕдїЕдЇЖиІ£е∞±и°МпЉМдљ†еЇФиѓ•дљњзФ®жЫійЂШзЇІеИЂзЪДthreadingз≠ЙгАВ
еЫЫ. threadingж®°еЭЧ
threadingж®°еЭЧдЄНдїЕжПРдЊЫдЇЖThreadз±їпЉМињШжПРдЊЫдЇЖеРДзІНйЭЮеЄЄе•љзФ®зЪДеРМж≠•жЬЇеИґгАВе¶ВдЄЛи°®еИЧеЗЇдЇЖthreadingж®°еЭЧйЗМжЙАжЬЙзЪДеѓєи±°гАВ
threadingж®°еЭЧеѓєи±° | жППињ∞ |
Thread | и°®з§ЇдЄАдЄ™зЇњз®ЛзЪДжЙІи°МзЪДеѓєи±° |
Lock | йФБеОЯиѓ≠еѓєи±°пЉИиЈЯthreadж®°еЭЧйЗМзЪДйФБеѓєи±°зЫЄеРМпЉЙ |
RLock | еПѓйЗНеЕ•йФБеѓєи±°гАВдљњеНХзЇњз®ЛеПѓдї•еЖНжђ°иОЈеЊЧеЈ≤зїПиОЈеЊЧдЇЖзЪДйФБпЉИйАТељТйФБеЃЪпЉЙ |
Condition | жЭ°дїґеПШйЗПеѓєи±°иГљиЃ©дЄАдЄ™зЇњз®ЛеБЬдЄЛжЭ•пЉМз≠ЙеЊЕеЕґдїЦзЇњз®Лжї°иґ≥дЇЖжЯРдЄ™вАЬжЭ°дїґвАЭгАВе¶ВзКґжАБзЪДжФєеПШжИЦеАЉзЪДжФєеПШ |
Event | йАЪзФ®зЪДжЭ°дїґеПШйЗПгАВе§ЪдЄ™зЇњз®ЛеПѓдї•з≠ЙеЊЕжЯРдЄ™жЧґйЧізЪДеПСзФЯпЉМеЬ®дЇЛдїґеПСзФЯеРОпЉМжЙАжЬЙзЪДзЇњз®ЛйÚ襀жњАжії |
Semaphore | дЄЇз≠ЙеЊЕйФБзЪДзЇњз®ЛжПРдЊЫдЄАдЄ™з±їдЉЉвАЬз≠ЙеАЩеЃ§вАЭзЪДзїУжЮД |
BoundedSemaphore | дЄОSemaphoreз±їдЉЉпЉМеП™жШѓеЃГдЄНеЕБиЃЄиґЕињЗеИЭеІЛеАЉ |
Timer | дЄОthreadз±їдЉЉпЉМеП™жШѓеЃГи¶Бз≠ЙеЊЕдЄАжЃµжЧґйЧіеРОжЙНеЉАеІЛињРи°М |
1.еЃИжК§зЇњз®Л
еЕґдЄ≠threadж®°еЭЧйЬАи¶БйБњеЕНзЪДдЄАдЄ™еОЯеЫ†жШѓпЉЪеЃГдЄНжФѓжМБеЃИжК§зЇњз®ЛгАВељУдЄїзЇњз®ЛйААеЗЇжЧґпЉМжЙАжЬЙзЪДе≠РзЇњз®ЛдЄНиЃЇеЃГдїђжШѓеР¶ињШеЬ®еЈ•дљЬпЉМйГљдЉЪ襀劯и°МйААеЗЇгАВжЬЙжЧґжИСдїђеєґдЄНжЬЯжЬЫињЩзІНи°МдЄЇпЉМињЩе∞±еЉХеЕ•дЇЖеЃИжК§зЇњз®ЛзЪДж¶ВењµгАВ
Threadingж®°еЭЧжФѓжМБеЃИжК§зЇњз®ЛпЉМеЃГдїђеЈ•дљЬжµБз®Ле¶ВдЄЛпЉЪеЃИжК§зЇњз®ЛдЄАиИђжШѓдЄАдЄ™з≠ЙеЊЕеЃҐжИЈиѓЈж±ВзЪДжЬНеК°еЩ®пЉМе¶ВжЮЬж≤°жЬЙеЃҐжИЈжПРеЗЇиѓЈж±ВпЉМеЃГе∞±еЬ®йВ£з≠ЙзЭАгАВе¶ВжЮЬдљ†иЃЊеЃЪдЄАдЄ™зЇњз®ЛдЄЇеЃИжК§зЇњз®ЛпЉМе∞±и°®з§Їдљ†еЬ®иѓіињЩдЄ™зЇњз®ЛжШѓдЄНйЗНи¶БзЪДпЉМеЬ®ињЫз®ЛйААеЗЇжЧґпЉМдЄНзФ®з≠ЙеЊЕињЩдЄ™зЇњз®ЛйААеЗЇпЉМж≠£е¶ВзљСзїЬзЉЦз®ЛдЄ≠жЬНеК°еЩ®зЇњз®ЛињРи°МеЬ®дЄАдЄ™жЧ†йЩРеЊ™зОѓдЄ≠пЉМдЄАиИђдЄНдЉЪйААеЗЇзЪДгАВ
е¶ВжЮЬдљ†зЪДдЄїзЇњз®Ли¶БйААеЗЇзЪДжЧґеАЩпЉМдЄНзФ®з≠ЙеЊЕйВ£дЇЫе≠РзЇњз®ЛеЃМжИРпЉМйВ£е∞±иЃЊеЃЪињЩдЇЫзЇњз®ЛзЪДdaemonе±ЮжАІгАВеН≥пЉМзЇњз®ЛеЉАеІЛпЉИи∞ГзФ®thread.start()пЉЙдєЛеЙНпЉМи∞ГзФ®setDaemon()еЗљжХ∞иЃЊеЃЪзЇњз®ЛзЪДdaemonж†ЗеЗЖпЉИthread.setDaemon(True)пЉЙе∞±и°®з§ЇињЩдЄ™зЇњз®ЛвАЬдЄНйЗНи¶БвАЭгАВ
е¶ВжЮЬдљ†жГ≥и¶Бз≠ЙеЊЕе≠РзЇњз®ЛеЃМжИРеЖНйААеЗЇпЉМйВ£е∞±дїАдєИйГљдЄНзФ®еБЪпЉМжИЦиАЕжШЊз§ЇеЬ∞и∞ГзФ®thread.setDaemon(False)дї•дњЭиѓБеЕґdaemonж†ЗењЧдљНFalseгАВдљ†еПѓдї•и∞ГзФ®thread.isDaemon()еЗљжХ∞жЭ•еИ§жЦ≠еЕґdaemonж†ЗењЧзЪДеАЉгАВ
жЦ∞зЪДе≠РзЇњз®ЛдЉЪзїІжЙњеЕґзИґзЇњз®ЛзЪДdaemonж†ЗењЧпЉМжХідЄ™PythonдЉЪеЬ®жЙАжЬЙзЪДйЭЮеЃИжК§зЇњз®ЛйААеЗЇеРОжЙНдЉЪзїУжЭЯпЉМеН≥ињЫз®ЛдЄ≠ж≤°жЬЙйЭЮеЃИжК§зЇњз®Ле≠ШеЬ®зЪДжЧґеАЩжЙНзїУжЭЯгАВ
2.Threadз±ї
threadingзЪДThreadз±їжШѓдљ†дЄїи¶БзЪДињРи°Меѓєи±°гАВеЃГжЬЙеЊИе§Ъthreadж®°еЭЧйЗМж≤°жЬЙзЪДеЗљжХ∞гАВ
еЗљжХ∞ | жППињ∞ |
start() | еЉАеІЛзЇњз®ЛзЪДжЙІи°М |
run() | еЃЪдєЙзЇњз®ЛзЪДеКЯиГљзЪДеЗљжХ∞пЉИдЄАиИђдЉЪ襀е≠Рз±їйЗНеЖЩпЉЙ |
join(timeout=None) | з®ЛеЇПжМВиµЈпЉМзЫіеИ∞зЇњз®ЛзїУжЭЯпЉЫе¶ВжЮЬзїЩдЇЖtimeoutпЉМеИЩжЬАе§ЪйШїе°ЮtimeoutзІТ |
getName() | ињФеЫЮзЇњз®ЛзЪДеРНе≠Ч |
setName(name) | иЃЊзљЃзЇњз®ЛзЪДеРНе≠Ч |
isAlive() | еЄГе∞Фж†ЗењЧпЉМи°®з§ЇињЩдЄ™зЇњз®ЛжШѓеР¶ињШеЬ®ињРи°МдЄ≠ |
isDaemon() | ињФеЫЮзЇњз®ЛзЪДdaemonж†ЗењЧ |
setDaemon(daemonic) | жККзЇњз®ЛзЪДdaemonж†ЗењЧиЃЊдЄЇdaemonicпЉИдЄАеЃЪи¶БеЬ®и∞ГзФ®start()еЗљжХ∞еЙНи∞ГзФ®пЉЙ |
¬† ¬† ¬† зФ®Threadз±їпЉМеПѓдї•зФ®е§ЪзІНжЦєж≥ХжЭ•еИЫеїЇзЇњз®ЛгАВзО∞еЬ®дїЛзїНдЄЙзІНжЦєж≥ХпЉМдљ†еПѓдї•йАЙжЛ©иЗ™еЈ±еЦЬ搥жИЦз§ЊеТМиЗ™еЈ±з®ЛеЇПзЪДжЦєж≥ХпЉИйАЪеЄЄйАЙжЛ©жЬАеРОдЄАдЄ™пЉЙпЉЪ
¬† ¬† ¬† (1) еИЫеїЇдЄАдЄ™ThreadзЪДеЃЮдЊЛпЉМдЉ†зїЩеЃГдЄАдЄ™еЗљжХ∞пЉЫ
¬† ¬† ¬† (2) еИЫеїЇдЄАдЄ™ThreadзЪДеЃЮдЊЛпЉМдЉ†зїЩеЃГдЄАдЄ™еПѓи∞ГзФ®зЪДз±їеѓєи±°пЉЫ
¬† ¬† ¬† (3) дїОThreadжіЊзФЯеЗЇдЄАдЄ™е≠Рз±їпЉМеИЫеїЇдЄАдЄ™ињЩдЄ™е≠Рз±їзЪДеЃЮдЊЛгАВ
3.еИЫеїЇThreadеЃЮдЊЛпЉМдЉ†зїЩеЃГдЄАдЄ™еЗљжХ∞
ињЩзђђдЄАдЄ™дЊЛе≠РдљњзФ®жЦєж≥ХдЄАпЉМжККеЗљжХ∞еПКеЕґеПВжХ∞е¶ВдЄКйЭҐThreadж®°еЭЧзЪДдЊЛе≠РдЄАж†ЈдЉ†ињЫеОїгАВдЄїи¶БеПШеМЦеМЕжЛђпЉЪжЈїеК†дЇЖдЄАдЇЫThreadеѓєи±°пЉЫеЬ®еЃЮдЊЛеМЦжѓПдЄ™Threadеѓєи±°жЧґпЉМжККеЗљжХ∞пЉИtargetпЉЙеТМеПВжХ∞пЉИargsпЉЙйГљдЉ†ињЫеОїпЉМеЊЧеИ∞ињФеЫЮзЪДThreadеЃЮдЊЛгАВ
еЃЮдЊЛеМЦдЄАдЄ™Threadи∞ГзФ®Thread()жЦєж≥ХдЄОи∞ГзФ®thread.start_new_thread()дєЛйЧізЪДжЬАе§ІеМЇеИЂжШѓпЉЪжЦ∞зЪДзЇњз®ЛдЄНдЉЪзЂЛеН≥еЉАеІЛгАВеЬ®дљ†еИЫеїЇзЇњз®Леѓєи±°пЉМдљЖдЄНжГ≥й©ђдЄКеЉАеІЛињРи°МзЇњз®ЛзЪДжЧґеАЩпЉМињЩжШѓдЄАдЄ™еЊИжЬЙзФ®зЪДеРМж≠•зЙєжАІгАВ
threadingж®°еЭЧзЪДThreadз±їжЬЙдЄАдЄ™join()еЗљжХ∞пЉМеЕБиЃЄдЄїзЇњз®Лз≠ЙеЊЕзЇњз®ЛзЪДзїУжЭЯгАВ
#coding=utf-8
import threading
from time import sleep, ctime
loops = [4,2] #зЭ°зЬ†жЧґйЧі
def loop(nloop, nsec):
print "Start loop", nloop, "at:", ctime()
sleep(nsec)
print "Loop", nloop, "done at:", ctime()
def main():
print "Starting at:", ctime()
threads = []
nloops = range(len(loops)) #еИЧи°®[0,1]
#еИЫеїЇзЇњз®Л
for i in nloops:
t = threading.Thread(target=loop,args=(i,loops[i]))
threads.append(t)
#еЉАеІЛзЇњз®Л
for i in nloops:
threads[i].start()
#з≠ЙеЊЕжЙАжЬЙзїУжЭЯзЇњз®Л
for i in nloops:
threads[i].join()
print "All end:", ctime()
if __name__ == "__main__":
main()
ињРи°МзїУжЮЬе¶ВдЄЛеЫЊжЙАз§ЇпЉЪеЕґдЄ≠loop0еТМloop1еєґи°МжЙІи°МпЉМloop1еЕИзїУжЭЯеЕ±жЙІи°М2зІТпЉМloop0еРОзїУжЭЯжЙІи°М4зІТпЉМжАїеЕ±ињРи°МжЧґйЧі4зІТгАВж≥®жДПпЉЪж≠§жЧґStartжШѓеИЖи°МжШЊз§ЇдЇЖгАВ

жЙАжЬЙзЪДзЇњз®ЛйГљеИЫеїЇдєЛеРОпЉМеЖНдЄАиµЈи∞ГзФ®start()еЗљжХ∞еРѓеК®зЇњз®ЛпЉМиАМдЄНжШѓеИЫеїЇдЄАдЄ™еРѓеК®дЄАдЄ™гАВиАМдЄФпЉМдЄНзФ®еЖНзЃ°зРЖдЄАе†ЖйФБпЉИеИЖйЕНйФБгАБиОЈеЊЧйФБгАБйЗКжФЊйФБгАБж£АжЯ•йФБзЪДзКґжАБз≠ЙпЉЙпЉМеП™и¶БзЃАеНХеЬ∞еѓєжѓПдЄ™зЇњз®Ли∞ГзФ®join()еЗљжХ∞е∞±еПѓдї•дЇЖгАВ
join()дЉЪз≠ЙеИ∞зЇњз®ЛзїУжЭЯпЉМжИЦиАЕеЬ®зїЩдЇЖtimeoutеПВжХ∞зЪДжЧґеАЩпЉМз≠ЙеИ∞иґЕжЧґдЄЇж≠ҐгАВдљњзФ®join()жѓФдљњзФ®дЄАдЄ™з≠ЙеЊЕйФБйЗКжФЊзЪДжЧ†йЩРеЊ™зОѓжЄЕж•ЪдЄАдЇЫпЉИдєЯзІ∞вАЬиЗ™жЧЛйФБвАЭпЉЙгАВ
join()зЪДеП¶дЄАдЄ™жѓФиЊГйЗНи¶БзЪДжЦєж≥ХжШѓеЃГеПѓдї•еЃМеЕ®дЄНзФ®и∞ГзФ®гАВдЄАжЧ¶зЇњз®ЛеРѓеК®еРОпЉМе∞±дЉЪдЄАзЫіињРи°МпЉМзЫіеИ∞зЇњз®ЛзЪДеЗљжХ∞зїУжЭЯпЉМйААеЗЇдЄЇж≠ҐгАВ
е¶ВжЮЬдљ†зЪДдЄїзЇњз®ЛйЩ§дЇЖз≠ЙзЇњз®ЛзїУжЭЯе§ЦпЉМињШжЬЙеЕґдїЦзЪДдЇЛжГЕи¶БеБЪпЉИе¶Ве§ДзРЖжИЦз≠ЙеЊЕеЕґдїЦзЪДеЃҐжИЈиѓЈж±ВпЉЙпЉМйВ£е∞±дЄНзФ®и∞ГзФ®join()пЉМеП™жЬЙеЬ®дљ†и¶Бз≠ЙеЊЕзЇњз®ЛзїУжЭЯзЪДжЧґеАЩжЙНи¶Би∞ГзФ®join()гАВ
4.еИЫеїЇдЄАдЄ™ThreadеЃЮдЊЛпЉМдЉ†зїЩеЃГдЄАдЄ™еПѓи∞ГзФ®зЪДз±їеѓєи±°
ињЩжШѓзђђдЇМдЄ™жЦєж≥ХпЉМдЄОдЉ†дЄАдЄ™еЗљжХ∞еЊИзЫЄдЉЉпЉМдљЖеЃГжШѓдЉ†дЄАдЄ™еПѓи∞ГзФ®зЪДз±їзЪДеЃЮдЊЛдЊЫзЇњз®ЛеРѓеК®зЪДжЧґеАЩжЙІи°МпЉМињЩжШѓе§ЪзЇњз®ЛзЉЦз®ЛзЪДдЄАдЄ™жЫідЄЇйЭҐеРСеѓєи±°зЪДжЦєж≥ХгАВзЫЄеѓєдЇОдЄАдЄ™жИЦеЗ†дЄ™еЗљжХ∞жЭ•иѓіпЉМзФ±дЇОз±їеѓєи±°йЗМеПѓдї•дљњзФ®з±їиѓЈжЙУзЪДеКЯиГљпЉМеПѓдї•дњЭе≠ШжЫіе§ЪзЪДдњ°жБѓпЉМињЩзІНжЦєж≥ХжЫідЄЇзБµжіїгАВ
#coding=utf-8
import threading
from time import sleep, ctime
loops = [4,2] #зЭ°зЬ†жЧґйЧі
class ThreadFunc(object):
def __init__(self, func, args, name=""):
self.name=name
self.func=func
self.args=args
def __call__(self):
apply(self.func, self.args)
def loop(nloop, nsec):
print "Start loop", nloop, "at:", ctime()
sleep(nsec)
print "Loop", nloop, "done at:", ctime()
def main():
print "Starting at:", ctime()
threads=[]
nloops = range(len(loops)) #еИЧи°®[0,1]
for i in nloops:
#и∞ГзФ®ThreadFuncз±їеЃЮдЊЛеМЦзЪДеѓєи±°пЉМеИЫеїЇжЙАжЬЙзЇњз®Л
t = threading.Thread(
target=ThreadFunc(loop, (i,loops[i]), loop.__name__)
)
threads.append(t)
#еЉАеІЛзЇњз®Л
for i in nloops:
threads[i].start()
#з≠ЙеЊЕжЙАжЬЙзїУжЭЯзЇњз®Л
for i in nloops:
threads[i].join()
print "All end:", ctime()
if __name__ == "__main__":
main()
ињРи°МзїУжЮЬе¶ВдЄЛеЫЊжЙАз§ЇпЉМдЉ†йАТзЪДжШѓдЄАдЄ™еПѓи∞ГзФ®зЪДз±їпЉМиАМдЄНжШѓдЄАдЄ™еЗљжХ∞гАВ
еИЫеїЇThreadеѓєи±°жЧґдЉЪеЃЮдЊЛеМЦдЄАдЄ™еПѓи∞ГзФ®з±їThreadFuncзЪДз±їеѓєи±°гАВињЩдЄ™з±їдњЭе≠ШдЇЖеЗљжХ∞зЪДеПВжХ∞пЉМеЗљжХ∞жЬђиЇЂдї•еПКеЗљжХ∞зЪДеРНе≠Че≠Чзђ¶дЄ≤гАВ
жЮДйА†еЩ®init()еЗљжХ∞пЉЪеИЭеІЛеМЦиµЛеАЉеЈ•дљЬпЉЫ
зЙєжЃКеЗљжХ∞call()пЉЪзФ±дЇОжИСдїђеЈ≤зїПжЬЙи¶БзФ®зЪДеПВжХ∞пЉМжЙАдї•е∞±дЄНзФ®еЖНдЉ†еИ∞Thread()жЮДйА†еЩ®дЄ≠пЉЫзФ±дЇОжИСдїђжЬЙдЄАдЄ™еПВжХ∞зЪДеЕГзїДпЉМињЩжЧґи¶БеЬ®дї£з†БдЄ≠дљњзФ®apply()еЗљжХ∞гАВ
apply(func¬†[,¬†args¬†[,¬†kwargs¬†]])¬†еЗљжХ∞пЉЪзФ®дЇОељУеЗљжХ∞еПВжХ∞еЈ≤зїПе≠ШеЬ®дЇОдЄАдЄ™еЕГзїДжИЦе≠ЧеЕЄдЄ≠жЧґпЉМйЧіжО•еЬ∞и∞ГзФ®еЗљжХ∞гАВargsжШѓдЄАдЄ™еМЕеРЂе∞Жи¶БжПРдЊЫзїЩеЗљжХ∞зЪДжМЙдљНзљЃдЉ†йАТзЪДеПВжХ∞зЪДеЕГзїДгАВе¶ВжЮЬзЬБзХ•дЇЖargsпЉМдїїдљХеПВжХ∞йГљдЄНдЉЪ襀䊆йАТпЉМkwargsжШѓдЄАдЄ™еМЕеРЂеЕ≥йФЃе≠ЧеПВжХ∞зЪДе≠ЧеЕЄгАВ
def say(a, b):
print a, b
apply(say,("Eastmount", "PythonзЇњз®Л"))
# иЊУеЗЇ
# Eastmount PythonзЇњз®Л
5.ThreadжіЊзФЯдЄАдЄ™е≠Рз±їпЉМеИЫеїЇињЩдЄ™е≠Рз±їзЪДеЃЮдЊЛ
ињЩжШѓзђђдЄЙдЄ™жЦєж≥ХпЉМдЄїи¶БжШѓе¶ВдљХе≠Рз±їеМЦThreadз±їпЉМиѓ•жЦєж≥ХдЄОзђђдЇМдЄ™жЦєж≥Хз±їдЉЉгАВеЕґдЄ≠еИЫеїЇе≠Рз±їжЦєж≥ХеТМи∞ГзФ®з±їеѓєи±°жЦєж≥ХзЪДжЬАйЗНи¶БжФєеПШжШѓпЉЪ
(1) MyThreadе≠Рз±їзЪДжЮДйА†еЩ®дЄАеЃЪи¶БеЕИи∞ГзФ®еЯЇз±їзЪДжЮДйА†еЩ®пЉЫ
(2) дєЛеЙНзЙєжЃКеЗљжХ∞call()еЬ®е≠Рз±їдЄ≠пЉМеРНе≠Чи¶БжФєдЄЇrun()гАВ
#coding=utf-8
import threading
from time import sleep, ctime
loops = [4,2] #зЭ°зЬ†жЧґйЧі
class MyThread(threading.Thread):
def __init__(self, func, args, name=""):
threading.Thread.__init__(self)
self.name=name
self.func=func
self.args=args
def run(self): #run()еЗљжХ∞
apply(self.func, self.args)
def loop(nloop, nsec):
print "Start loop", nloop, "at:", ctime()
sleep(nsec)
print "Loop", nloop, "done at:", ctime()
def main():
print "Starting at:", ctime()
threads=[]
nloops = range(len(loops)) #еИЧи°®[0,1]
for i in nloops:
#е≠Рз±їMyThreadеЃЮдЊЛеМЦпЉМеИЫеїЇжЙАжЬЙзЇњз®Л
t = MyThread(loop, (i,loops[i]), loop.__name__)
threads.append(t)
#еЉАеІЛзЇњз®Л
for i in nloops:
threads[i].start()
#з≠ЙеЊЕжЙАжЬЙзїУжЭЯзЇњз®Л
for i in nloops:
threads[i].join()
print "All end:", ctime()
if __name__ == "__main__":
main()
ињРи°МзїУжЮЬе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ

6.зЇњз®ЛињРи°МжЦРж≥ҐйВ£е•СгАБйШґдєШеТМеК†еТМ
йЬАи¶БеЬ®MyThreadз±їдЄ≠еК†еЕ•иЊУеЗЇдњ°жБѓпЉМйЩ§дЇЖдљњзФ®apply()еЗљжХ∞ињРи°МжЦРж≥ҐйВ£е•СгАБжО•иІ¶еТМеК†еТМеЗљжХ∞е§ЦпЉМињШжККзїУжЮЬдњЭе≠ШеИ∞еЃЮзО∞зЪДself.resе±ЮжАІдЄ≠пЉМеєґеИЫеїЇдЄАдЄ™еЗљжХ∞getResult()еЊЧеИ∞зїУжЮЬгАВжНҐеП•иѓЭиѓіпЉМе≠Рз±їжЦєж≥ХжЫіеК†зБµжіїгАВ
#coding=utf-8
import threading
from time import sleep, ctime
class MyThread(threading.Thread):
def __init__(self, func, args, name=""):
threading.Thread.__init__(self)
self.name=name
self.func=func
self.args=args
def getResult(self):
return self.res
def run(self): #run()еЗљжХ∞
print "Starting", self.name, "at:", ctime()
self.res = apply(self.func, self.args)
print self.name, "finished at:", ctime()
¬† ¬† ¬† еЬ®threadfunc.pyжЦЗдїґдЄ≠и∞ГзФ®еЙНйЭҐеЃЪдєЙзЪДThreadе≠Рз±їпЉМmyThread.pyдЄ≠зЪДMyThreadз±їгАВзФ±дЇОињЩдЇЫеЗљжХ∞ињРи°МеЊЧеЊИењЂпЉИжЦРж≥ҐйВ£е•СеЗљжХ∞ињРи°МжЕҐдЇЫпЉЙпЉМдљњзФ®sleep()еЗљжХ∞жѓФиЊГеЃГдїђзЪДжЧґйЧігАВеЃЮйЩЕеЈ•дљЬдЄ≠дЄНйЬАи¶БжЈїеК†sleep()еЗљжХ∞гАВ
#coding=utf-8
from myThread import MyThread #myThread.pyжЦЗдїґдЄ≠MyThreadз±ї
from time import sleep, ctime
#жЦРж≥ҐйВ£е•СеЗљжХ∞
def fib(x):
sleep(0.005)
if x < 2:
return 1
return (fib(x-2) + fib(x-1))
#йШґдєШеЗљжХ∞ factorial calculation
def fac(x):
sleep(0.1)
if x < 2:
return 1
return (x * fac(x-1))
#ж±ВеТМеЗљжХ∞
def sum(x):
sleep(0.1)
if x < 2:
return 1
return (x + sum(x-1))
funcs = [fib, fac, sum]
n = 14
def main():
nfuncs = range(len(funcs))
print "***еНХзЇњз®ЛжЦєж≥Х***"
for i in nfuncs:
print "Starting", funcs[i].__name__, "at:", ctime()
print funcs[i](n)
print "Finished", funcs[i].__name__, "at:", ctime()
print "***зїУжЭЯеНХзЇњз®Л***"
print " "
print "***е§ЪзЇњз®ЛжЦєж≥Х***"
threads = []
for i in nfuncs:
#и∞ГзФ®MyThreadз±їеЃЮдЊЛеМЦзЪДеѓєи±°пЉМеИЫеїЇжЙАжЬЙзЇњз®Л
t = MyThread(funcs[i], (n,), funcs[i].__name__)
threads.append(t)
#еЉАеІЛзЇњз®Л
for i in nfuncs:
threads[i].start()
#з≠ЙеЊЕжЙАжЬЙзїУжЭЯзЇњз®Л
for i in nfuncs:
threads[i].join()
print threads[i].getResult()
print "***зїУжЭЯе§ЪзЇњз®Л***"
if __name__ == "__main__":
main()
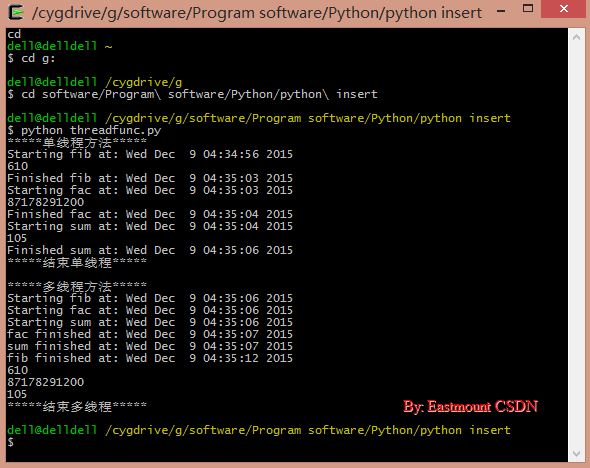
ињРи°МзїУжЮЬе¶ВдЄЛеЫЊжЙАз§ЇпЉМеНХзЇњз®ЛињРи°М10sпЉМе§ЪзЇњз®ЛињРи°М6sгАВ
иЗ≥дЇОQueueж®°еЭЧињЩйЗМе∞±дЄНеЖНеПЩињ∞дЇЖгАВ
дЄЛйЭҐдїЛзїНйЩ§дЇЖеРДзІНеРМж≠•еѓєи±°еТМзЇњз®Леѓєи±°е§ЦпЉМthreadingж®°еЭЧињШжПРдЊЫдЇЖдЄАдЇЫеЗљжХ∞гАВ
еЗљжХ∞ | жППињ∞ |
activeCount() | ељУеЙНжіїеК®зЪДзЇњз®Леѓєи±°зЪДжХ∞йЗП |
currentThread() | ињФеЫЮељУеЙНзЇњз®Леѓєи±° |
enumerate() | ињФеЫЮељУеЙНжіїеК®зЇњз®ЛзЪДеИЧи°® |
settrace(func) | дЄЇжЙАжЬЙзЇњз®ЛиЃЊзљЃдЄАдЄ™иЈЯиЄ™еЗљжХ∞ |
setprofile(func) | дЄЇжЙАжЬЙзЇњз®ЛиЃЊзљЃдЄАдЄ™profileеЗљжХ∞ |
жЬАеРОзїЩеЗЇдЄАдЇЫе§ЪзЇњз®ЛзЉЦз®ЛдЄ≠еПѓиГљзФ®еЊЧеИ∞зЪДж®°еЭЧгАВ
ж®°еЭЧ | жППињ∞ |
thread | еЯЇжЬђзЪДгАБдљОзЇІеИЂзЪДзЇњз®Лж®°еЭЧ |
threading | йЂШзЇІеИЂзЪДзЇњз®ЛеТМеРМж≠•еѓєи±° |
Queue | дЊЫе§ЪзЇњз®ЛдљњзФ®зЪДеРМж≠•еЕИињЫеЕИеЗЇпЉИFIFOпЉЙйШЯеИЧ |
mutex | дЇТжЦ•еѓєи±° |
SocketServer | еЕЈжЬЙзЇњз®ЛжОІеИґзЪДTCPеТМUDPзЃ°зРЖеЩ® |
жАїдєЛпЉМињЩзѓЗжЦЗзЂ†дЄїи¶БжШѓеПВиАГгАКPythonж†ЄењГзЉЦз®ЛгАЛзЪДпЉМеЄМжЬЫжЦЗзЂ†еѓєдљ†жЬЙжЙАеЄЃеК©~е∞§еЕґжШѓеИЭе≠¶PythonзЉЦз®ЛзЪДпЉМеРМжЧґдЄЇеРОйЭҐжИСе≠¶дє†е§ЪзЇњз®ЛзЪДзИђиЩЂжИЦеИЖеЄГеЉПзИђиЩЂеБЪйУЇеЮЂгАВињЩзѓЗжЦЗзЂ†иК±дЇЖиЗ™еЈ±дЄАдЇЫжЧґйЧіпЉМеЖЩеИ∞еНКе§ЬпЉЫеЖЩжЦЗдЄНжШУпЉМдЄФзЬЛдЄФзПНжГЬеРІпЉБеЛњеЦЈ~
пЉИBy:Eastmount 2015-12-09 еНКе§Ь5зВє ¬†http://blog.csdn.net/eastmount/пЉЙ¬†¬†