

>жңҖиҝ‘ејҖе§ӢдәҶжЁЎејҸиҜҶеҲ«зҡ„еӯҰд№ пјҢеҜ№жЁЎејҸе’ҢжЁЎејҸзұ»зҡ„жҰӮеҝөжңүдёҖдёӘеҹәжң¬зҡ„дәҶи§ЈпјҢ并дҪҝз”ЁMATLABе®һзҺ°дёҖдәӣжЁЎејҸзұ»зҡ„з”ҹжҲҗгҖӮиҖҢжҺҘдёӢжқҘеҰӮдҪ•еҜ№иҝҷдәӣжЁЎејҸиҝӣиЎҢеҲҶзұ»жҲҗдёәдәҶеӯҰд№ зҡ„第дәҢдёӘйҮҚзӮ№гҖӮжҲ‘们йғҪзҹҘйҒ“пјҢдёҖдёӘе…ёеһӢзҡ„жЁЎејҸиҜҶеҲ«зі»з»ҹжҳҜз”ұзү№еҫҒжҸҗеҸ–е’ҢжЁЎејҸеҲҶзұ»дёӨдёӘйҳ¶ж®өз»„жҲҗзҡ„пјҢиҖҢе…¶дёӯжЁЎејҸеҲҶзұ»еҷЁ(Classifier)зҡ„жҖ§иғҪзӣҙжҺҘеҪұе“Қж•ҙдёӘиҜҶеҲ«зі»з»ҹзҡ„жҖ§иғҪгҖӮ >еӣ жӯӨжңүеҝ…иҰҒжҺўи®ЁдёҖдёӢеҰӮдҪ•иҜ„д»·еҲҶзұ»еҷЁзҡ„жҖ§иғҪпјҢиҝҷжҳҜдёҖдёӘй•ҝжңҹжҺўзҙўзҡ„иҝҮзЁӢ.
дёҖгҖҒж•Ҹж„ҹжҖ§е’Ңзү№ејӮжҖ§
д»ҘдёӢдҫӢеӯҗеҒҮе®ҡxжҳҜдёҖдёӘиҝһз»ӯйҡҸжңәеҸҳйҮҸпјҢеҜ№дәҺзұ»еҲ«зҠ¶жҖҒ В е’Ң
В е’Ң В зҡ„xзҡ„жҰӮзҺҮеҜҶеәҰеҮҪж•°еҰӮеӣҫжүҖзӨәпјҡ
В зҡ„xзҡ„жҰӮзҺҮеҜҶеәҰеҮҪж•°еҰӮеӣҫжүҖзӨәпјҡ
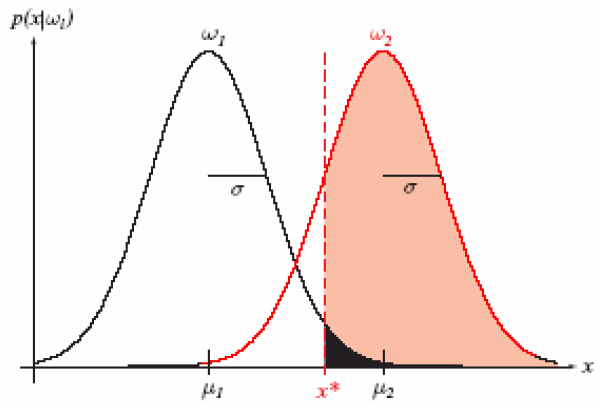
иҝҷйҮҢеҒҮи®ҫе…ҲйӘҢжҰӮзҺҮе·ІзҹҘпјҢеҜ№дәҺдёҖдёӘдәҢеҲҶзұ»й—®йўҳпјҢеҸҜд»Ҙе®ҡд№үд»ҘдёӢеӣӣдёӘз»ҹи®ЎеҖјпјҡ

еҸҜд»Ҙе°Ҷе®һдҫӢеҲҶжҲҗжӯЈзұ»пјҲPositiveпјүжҲ–иҙҹзұ»пјҲNegativeпјүгҖӮиҝҷж ·дјҡеҮәзҺ°еӣӣз§ҚеҲҶзұ»з»“жһңпјҡ
TPпјҲTrue PositiveпјүпјҡжӯЈзЎ®зҡ„жӯЈдҫӢпјҢдёҖдёӘе®һдҫӢжҳҜжӯЈзұ»е№¶дё”д№ҹиў«еҲӨе®ҡжҲҗжӯЈзұ»пјӣВ
FNпјҲFalse Negativeпјүпјҡй”ҷиҜҜзҡ„еҸҚдҫӢпјҢжјҸжҠҘпјҢжң¬дёәжӯЈзұ»дҪҶеҲӨе®ҡдёәеҒҮзұ»пјӣВ
FPпјҲFalse Positiveпјүпјҡй”ҷиҜҜзҡ„жӯЈдҫӢпјҢиҜҜжҠҘпјҢжң¬дёәеҒҮзұ»дҪҶеҲӨе®ҡдёәжӯЈзұ»пјӣВ
TNпјҲTrue NegativeпјүпјҡжӯЈзЎ®зҡ„еҸҚдҫӢпјҢдёҖдёӘе®һдҫӢжҳҜеҒҮзұ»е№¶дё”д№ҹиў«еҲӨе®ҡжҲҗеҒҮзұ»пјӣ
ж №жҚ®д»ҘдёҠеӣӣз§Қжғ…еҶөпјҢеј•еҮәд»ҘдёӢе…¬ејҸпјҡ
ж•Ҹж„ҹжҖ§пјҢеҸҲз§°зңҹжӯЈзұ»зҺҮ(true positive rate ,TPR)пјҢе®ғиЎЁзӨәдәҶеҲҶзұ»еҷЁжүҖиҜҶеҲ«еҮәзҡ„жӯЈе®һдҫӢеҚ жүҖжңүжӯЈе®һдҫӢзҡ„жҜ”дҫӢгҖӮи®Ўз®—е…¬ејҸдёәпјҡ
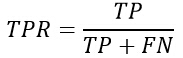
зү№ејӮжҖ§пјҢеҸҲз§°иҙҹжӯЈзұ»зҺҮ(False positive rate, FPR)пјҢе®ғиЎЁзӨәзҡ„жҳҜеҲҶзұ»еҷЁй”ҷи®ӨдёәжӯЈзұ»зҡ„иҙҹе®һдҫӢеҚ жүҖжңүиҙҹе®һдҫӢзҡ„жҜ”дҫӢгҖӮи®Ўз®—е…¬ејҸдёәпјҡ
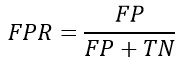
йҷӨжӯӨд№ӢеӨ–пјҢиҝҳжңүзңҹиҙҹзұ»зҺҮпјҲTrue Negative RateпјҢTNRпјүпјҢи®Ўз®—е…¬ејҸдёәпјҡ

иҙҹиҙҹзұ»зҺҮпјҹпјҲFalse Negative RateпјҢFNRпјүпјҢи®Ўз®—е…¬ејҸдёәпјҡ
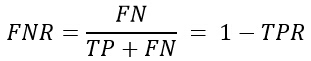
иҝҷдёӨдёӘе…¬ејҸз”ЁдәҺF scoreжҖ§иғҪиҜ„д»·гҖӮ
дәҢгҖҒROCжӣІзәҝ
жҺҘ收жңәе·ҘдҪңзү№еҫҒжӣІзәҝ пјҲreceiver operating characteristic curveпјҢз®Җз§°ROCжӣІзәҝпјүпјҢеҸҲз§°дёәж„ҹеҸ—жҖ§жӣІзәҝпјҲsensitivity curveпјүгҖӮROCжӣІзәҝжҳҜж №жҚ®дёҖзі»еҲ—дёҚеҗҢзҡ„дәҢеҲҶзұ»ж–№ејҸпјҢе°ҶTPRе®ҡд№үдёәXиҪҙпјҢе°ҶFPRе®ҡд№үдёәYиҪҙиҖҢз»ҳеҲ¶зҡ„жӣІзәҝгҖӮжӣІзәҝдёӢйқўз§Ҝи¶ҠеӨ§пјҢеҲҶзұ»зҡ„еҮҶзЎ®жҖ§е°ұи¶Ҡй«ҳгҖӮеңЁROCжӣІзәҝдёҠпјҢжңҖйқ иҝ‘еқҗж Үеӣҫе·ҰдёҠж–№зҡ„зӮ№дёәзҒөж•ҸжҖ§е’Ңзү№ејӮжҖ§еқҮиҫғй«ҳзҡ„дёҙз•ҢеҖјгҖӮ
ROCжӣІзәҝдёҠеҗ„зӮ№еҸҚжҳ зқҖзӣёеҗҢзҡ„ж„ҹеҸ—жҖ§пјҢе®ғ们йғҪжҳҜеҜ№еҗҢдёҖдҝЎеҸ·еҲәжҝҖзҡ„еҸҚеә”пјҢеҸӘдёҚиҝҮжҳҜеңЁеҮ з§ҚдёҚеҗҢзҡ„еҲӨе®ҡж ҮеҮҶдёӢжүҖеҫ—зҡ„з»“жһңиҖҢе·ІгҖӮжҺҘеҸ—иҖ…ж“ҚдҪңзү№жҖ§жӣІзәҝе°ұжҳҜд»ҘиҷҡжҠҘжҰӮзҺҮдёәжЁӘиҪҙпјҢеҮ»дёӯжҰӮзҺҮдёәзәөиҪҙжүҖз»„жҲҗзҡ„еқҗж ҮеӣҫпјҢе’Ңиў«иҜ•еңЁзү№е®ҡеҲәжҝҖжқЎд»¶дёӢз”ұдәҺйҮҮз”ЁдёҚеҗҢзҡ„еҲӨж–ӯж ҮеҮҶеҫ—еҮәзҡ„дёҚеҗҢз»“жһңз”»еҮәзҡ„жӣІзәҝгҖӮ
ROCжӣІзәҝжңҖеҲқжәҗдәҺ20дё–зәӘ70е№ҙд»Јзҡ„дҝЎеҸ·жЈҖжөӢзҗҶи®әпјҢе®ғеҸҚжҳ дәҶFPRдёҺTPRд№Ӣй—ҙжқғиЎЎзҡ„жғ…еҶөпјҢйҖҡдҝ—ең°жқҘиҜҙпјҢеҚіеңЁTPRйҡҸзқҖFPRйҖ’еўһзҡ„жғ…еҶөдёӢпјҢи°Ғеўһй•ҝеҫ—жӣҙеҝ«пјҢеҝ«еӨҡе°‘зҡ„й—®йўҳгҖӮTPRеўһй•ҝеҫ—и¶Ҡеҝ«пјҢжӣІзәҝи¶ҠеҫҖдёҠеұҲпјҢAUCе°ұи¶ҠеӨ§пјҢеҸҚжҳ дәҶжЁЎеһӢзҡ„еҲҶзұ»жҖ§иғҪе°ұи¶ҠеҘҪгҖӮеҪ“жӯЈиҙҹж ·жң¬дёҚе№іиЎЎж—¶пјҢиҝҷз§ҚжЁЎеһӢиҜ„д»·ж–№ејҸжҜ”иө·дёҖиҲ¬зҡ„зІҫзЎ®еәҰиҜ„д»·ж–№ејҸзҡ„еҘҪеӨ„е°Өе…¶жҳҫи‘—гҖӮдёҖдёӘе…ёеһӢзҡ„ROCжӣІзәҝдёӢеӣҫжүҖзӨәпјҡ
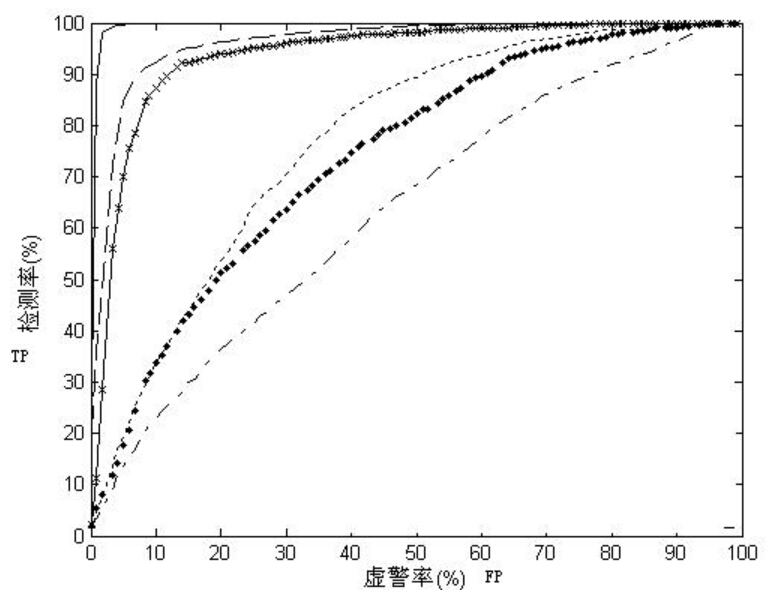
жӣҙеӨҡе…ідәҺROCжӣІзәҝзҡ„з»Ҹе…ёдҫӢеӯҗеҸҜеҸӮиҖғпјҡhttp://blog.csdn.net/abcjennifer/article/details/7359370
дёүгҖҒж··ж·Ҷзҹ©йҳө
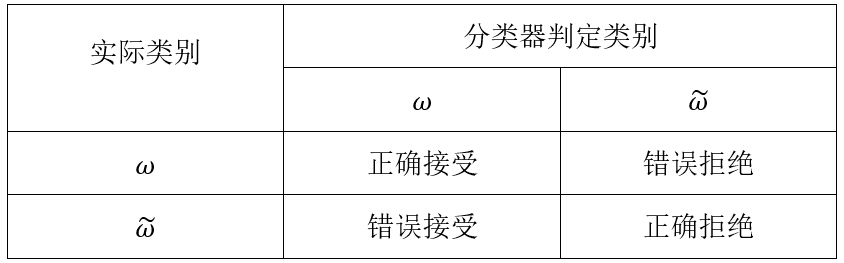
ж··ж·Ҷзҹ©йҳө(Confusion matrix)пјҢеңЁдәәе·ҘжҷәиғҪйўҶеҹҹдёӯпјҢе°ұжҳҜз”ЁдәҺжҖ»з»“жңүзӣ‘зқЈеӯҰд№ зҡ„еҲҶзұ»з»“жһңзҡ„зҹ©йҳөгҖӮжІҝзқҖдё»еҜ№и§’зәҝдёҠзҡ„йЎ№иЎЁзӨәжӯЈзЎ®еҲҶзұ»зҡ„жҖ»ж•°пјҢе…¶д»–йқһдё»еҜ№и§’зәҝзҡ„йЎ№иЎЁзӨәеҲҶзұ»зҡ„й”ҷиҜҜж•°пјҢеҰӮдёӢиЎЁжүҖзӨәгҖӮдәҢеҲҶй—®йўҳеӯҳеңЁвҖңй”ҷиҜҜжҺҘеҸ—вҖқе’ҢвҖңй”ҷиҜҜжӢ’з»қвҖқдёӨз§ҚдёҚеҗҢзұ»еһӢзҡ„й”ҷиҜҜгҖӮиӢҘе°ҶдәҢеҲҶй—®йўҳзҡ„ж··ж·Ҷзҹ©йҳөеҪ’дёҖеҢ–пјҢе°ұжҳҜдёҖдёӘе…ідәҺ0е’Ң1дәҢеҖјзҡ„зҰ»ж•ЈеҸҳйҮҸзҡ„иҒ”еҗҲеҲҶеёғжҰӮзҺҮгҖӮеҜ№дәҺдәҢеҲҶзұ»й—®йўҳжқҘиҜҙпјҢж··ж·Ҷзҹ©йҳөеҸҜд»Ҙз”ЁдёӢйқўзҡ„еҪўејҸиЎЁзӨәпјҡ
еӣӣгҖҒF score
з”ұдәҺеҲҶзұ»еҮҶзЎ®зҺҮжңү时并дёҚиғҪеҫҲеҘҪең°зӘҒеҮәж ·жң¬йӣҶзҡ„зү№зӮ№д»ҘеҸҠеҲӨж–ӯдёҖдёӘеҲҶзұ»еҷЁзҡ„жҖ§иғҪпјҢеҜ№дәҺдәҢеҲҶзұ»й—®йўҳпјҢеҸҜд»ҘдҪҝз”ЁВ е’ҢВ иҝҷдёӨдёӘеҸӮж•°жқҘиҜ„д»·еҲҶзұ»еҷЁзҡ„жҖ§иғҪгҖӮF Scoreзҡ„е®ҡд№үеҸҜеҸӮз…§дёҖзҜҮеҗҚдёәпјҡMining Comparative Sentences and Relationsзҡ„и®әж–ҮгҖӮе…¶дёӯTNRе’ҢFNRеҲҶеҲ«з”Ёprecision, recallжқҘд»ЈжӣҝгҖӮ
дёҖиҲ¬и®ӨдёәпјҢFиҜ„еҲҶи¶Ҡй«ҳеҲҷеҲҶзұ»еҷЁеҜ№дәҺжӯЈж ·жң¬жҳҜеҲҶзұ»ж•Ҳжһңи¶ҠеҘҪгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢTNRе’ҢFNRдјҡдә’зӣёеҪұе“ҚпјҢеӣ жӯӨпјҢеҚ•зӢ¬дҪҝз”ЁдёҖдёӘеҸӮж•°жқҘиҜ„д»·еҲҶзұ»еҷЁзҡ„жҖ§иғҪпјҢ并дёҚиғҪе…Ёйқўзҡ„иҜ„д»·дёҖдёӘеҲҶзұ»еҷЁгҖӮгҖӮ