

д№ӢеүҚеӯҰд№ дәҶиҙқеҸ¶ж–ҜеҲҶзұ»еҷЁзҡ„жһ„йҖ е’ҢдҪҝз”ЁпјҢе…¶дёӯж ёеҝғзҡ„йғЁеҲҶжҳҜеҫ—еҲ°дәӢ件зҡ„е…ҲйӘҢжҰӮзҺҮ并计算еҮәеҗҺйӘҢжҰӮзҺҮВ пјҢиҖҢдәӢе®һдёҠеңЁе®һйҷ…дҪҝз”ЁдёӯпјҢеҫҲеӨҡж—¶еҖҷж— жі•еҫ—еҲ°иҝҷдәӣе®Ңж•ҙзҡ„дҝЎжҒҜпјҢеӣ жӯӨжҲ‘们йңҖиҰҒдҪҝз”ЁеҸҰеӨ–дёҖдёӘйҮҚиҰҒзҡ„е·Ҙе…·вҖ”вҖ”еҸӮж•°дј°и®ЎгҖӮ
еҸӮж•°дј°и®ЎжҳҜеңЁе·ІзҹҘзі»з»ҹжЁЎеһӢз»“жһ„ж—¶пјҢз”Ёзі»з»ҹзҡ„иҫ“е…Ҙе’Ңиҫ“еҮәж•°жҚ®и®Ўз®—зі»з»ҹжЁЎеһӢеҸӮж•°зҡ„иҝҮзЁӢгҖӮ18дё–зәӘжң«еҫ·еӣҪж•°еӯҰ家C.F.й«ҳж–ҜйҰ–е…ҲжҸҗеҮәеҸӮж•°дј°и®Ўзҡ„ж–№жі•пјҢд»–з”ЁжңҖе°ҸдәҢд№ҳжі•и®Ўз®—еӨ©дҪ“иҝҗиЎҢзҡ„иҪЁйҒ“гҖӮ20дё–зәӘ60е№ҙд»ЈпјҢйҡҸзқҖз”өеӯҗи®Ўз®—жңәзҡ„жҷ®еҸҠпјҢеҸӮж•°дј°и®ЎжңүдәҶйЈһйҖҹзҡ„еҸ‘еұ•гҖӮеҸӮж•°дј°и®ЎжңүеӨҡз§Қж–№жі•пјҢжңүжңҖе°ҸдәҢд№ҳжі•гҖҒжһҒеӨ§дјјз„¶жі•гҖҒжһҒеӨ§йӘҢеҗҺжі•гҖҒжңҖе°ҸйЈҺйҷ©жі•е’ҢжһҒе°ҸеҢ–жһҒеӨ§зҶөжі•зӯүгҖӮеңЁдёҖе®ҡжқЎд»¶дёӢпјҢеҗҺйқўдёүдёӘж–№жі•йғҪдёҺжһҒеӨ§дјјз„¶жі•зӣёеҗҢгҖӮжңҖеҹәжң¬зҡ„ж–№жі•жҳҜжңҖе°ҸдәҢд№ҳжі•е’ҢжһҒеӨ§дјјз„¶жі•гҖӮиҝҷйҮҢдҪҝз”ЁMATLABе®һзҺ°еҮ з§Қз»Ҹе…ёзҡ„ж–№жі•е№¶з ”з©¶е…¶дј°и®Ўзү№жҖ§гҖӮ
зӣ®еүҚзҗҶи®әйғЁеҲҶе°ҡеңЁз ”究еҪ“дёӯпјҢж— жі•и§ЈйҮҠеҫ—еҫҲжё…жҘҡпјҢиҝҷжҳҜдёҖдёӘй•ҝжңҹзҡ„еӯҰд№ иҝҮзЁӢгҖӮ
дёҖгҖҒжңҖеӨ§дјјз„¶дј°и®Ўжі•
жңҖеӨ§дјјз„¶дј°и®ЎжҳҜдёҖз§Қз»ҹи®Ўж–№жі•пјҢе®ғз”ЁжқҘжұӮдёҖдёӘж ·жң¬йӣҶзҡ„зӣёе…іжҰӮзҺҮеҜҶеәҰеҮҪж•°зҡ„еҸӮж•°гҖӮиҝҷдёӘж–№жі•жңҖж—©жҳҜйҒ—дј еӯҰ家д»ҘеҸҠз»ҹи®ЎеӯҰ家зҪ—зәіеҫ·вҖўиҙ№йӣӘзҲөеЈ«еңЁ 1912 е№ҙиҮі1922 е№ҙй—ҙејҖе§ӢдҪҝз”Ёзҡ„гҖӮиҝҷз§Қж–№жі•зҡ„еҹәжң¬жҖқжғіжҳҜпјҡеҪ“д»ҺжЁЎеһӢжҖ»дҪ“йҡҸжңәжҠҪеҸ–nз»„ж ·жң¬и§ӮжөӢеҖјеҗҺпјҢжңҖеҗҲзҗҶзҡ„еҸӮж•°дј°и®ЎйҮҸеә”иҜҘдҪҝеҫ—д»ҺжЁЎеһӢдёӯжҠҪеҸ–иҜҘnз»„ж ·жң¬и§ӮжөӢеҖјзҡ„жҰӮзҺҮжңҖеӨ§пјҢиҖҢдёҚжҳҜеғҸжңҖе°ҸдәҢд№ҳдј°и®Ўжі•ж—ЁеңЁеҫ—еҲ°дҪҝеҫ—жЁЎеһӢиғҪжңҖеҘҪең°жӢҹеҗҲж ·жң¬ж•°жҚ®зҡ„еҸӮж•°дј°и®ЎйҮҸгҖӮ
жңҖеӨ§дјјз„¶дј°и®Ўзҡ„дјҳзӮ№дё»иҰҒжңүпјҡВ
1. йҡҸзқҖж ·жң¬ж•°йҮҸзҡ„еўһеҠ пјҢ收ж•ӣжҖ§еҸҳеҘҪпјӣВ
2. жҜ”д»»дҪ•е…¶д»–зҡ„иҝӯд»ЈжҠҖжңҜйғҪз®ҖеҚ•пјҢйҖӮеҗҲе®һз”ЁгҖӮ
жңҖеӨ§еӣӣ然估计зҡ„дёҖиҲ¬еҺҹзҗҶпјҡ
еҒҮи®ҫжңүcдёӘзұ»пјҢдё”пјҡ
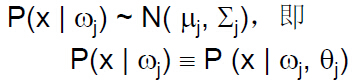
еңЁжӯЈжҖҒеҲҶеёғж—¶жңүпјҡ
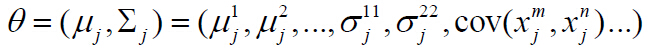
еҒҮи®ҫж•°жҚ®йӣҶеҗҲDеҲ’еҲҶжҲҗзҡ„зұ»дёә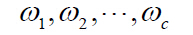
жҲ‘们еҸҜд»Ҙе°Ҷж•°жҚ®йӣҶеҗҲDеҲ’еҲҶжҲҗдә’дёҚзӣёдәӨзҡ„ж ·жң¬еӯҗйӣҶеҗҲпјҢжҜҸдёҖдёӘеӯҗйӣҶеҗҲдёӯзҡ„ж ·жң¬еұһдәҺеҗҢдёҖзұ»гҖӮеҜ№жҜҸдёҖдёӘж•°жҚ®йӣҶеҗҲDi пјҢеҚ•зӢ¬дј°и®ЎиҮӘе·ұзҡ„ В пјҢиҝҷж ·еҸӘйңҖдј°и®Ўе…¶еҸӮж•°еҚіеҸҜеҫ—еҲ°еҲҶеёғеҮҪж•°гҖӮ
В пјҢиҝҷж ·еҸӘйңҖдј°и®Ўе…¶еҸӮж•°еҚіеҸҜеҫ—еҲ°еҲҶеёғеҮҪж•°гҖӮ
иҝҷж ·пјҢеҒҮи®ҫйӣҶеҗҲDеҢ…еҗ«еҗҢдёҖзұ»nдёӘж ·жң¬, x1, x2,вҖҰ, xnпјҢдё”иҝҷдәӣж ·жң¬жҳҜзӢ¬з«ӢжҠҪж ·еҫ—еҲ°зҡ„пјҢеҲҷпјҡВ 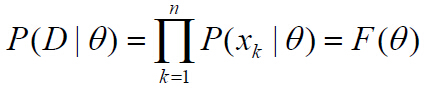
P(D | Оё)з§°дёәж ·жң¬йӣҶеҗҲпјӨзҡ„似然еҮҪж•°гҖӮеҸӮж•°Оё зҡ„жңҖеӨ§дјјз„¶дј°и®ЎжҳҜйҖҡиҝҮдҪҝе®ҡд№үзҡ„P(D | Оё) жңҖеӨ§еҢ–еҫ—еҲ°зҡ„Оёзҡ„еҖјпјҢдҪҝеҫ—е®һйҷ…и§ӮжөӢеҲ°зҡ„ж ·жң¬йӣҶеҗҲе…·жңүжңҖеӨ§зҡ„жҰӮзҺҮгҖӮеңЁе®һйҷ…дёӯпјҢеҸҜд»ҘеҜ№дјјз„¶еҮҪж•°иҝӣиЎҢеҜ№ж•°иҝҗз®—пјҢдёәжӯӨе®ҡд№үеҜ№ж•°дјјз„¶еҮҪж•°еҰӮдёӢпјҡ
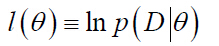
иҝҷж ·жңүпјҡ
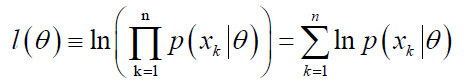
е…¶еҜјж•°е®ҡд№үдёәпјҡ

пјҲжіЁпјҡз”ұдәҺиҮӘ然еҜ№ж•°еҮҪж•°жҳҜеҚ•и°ғеўһеҮҪж•°пјҢеӣ жӯӨеҜ№ж•°дјјз„¶еҮҪж•°е’Ң似然еҮҪж•°зҡ„жһҒеҖјзӮ№зҡ„дҪҚзҪ®зӣёеҗҢпјҒпјү
иҝҷйҮҢжҲ‘们иҰҒеҜ»жүҫжңҖдјҳи§ЈпјҢиҝҷжҳҜжңҖеӨ§дјјз„¶дј°и®Ўзҡ„еҹәжң¬жҖқжғігҖӮжңҖдјҳи§Јзҡ„еҝ…иҰҒжқЎд»¶жҳҜпјҡ
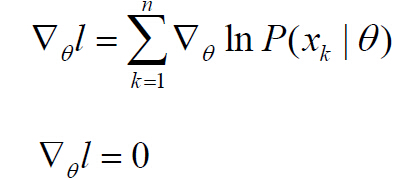
иӢҘОёз”ұpдёӘеҸӮж•°з»„жҲҗпјҢеҲҷдёҠејҸд»ЈиЎЁpдёӘж–№зЁӢз»„жҲҗзҡ„ж–№зЁӢз»„гҖӮдёӢдёҖжӯҘжҳҜжұӮеҸ–似然еҮҪж•°зҡ„жһҒеҖјзӮ№пјҡ
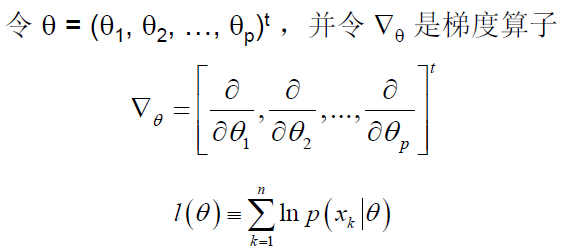
жӯӨж—¶й—®йўҳеҸҜд»ҘйҮҚж–°иЎЁиҝ°дёәпјҡжұӮеҜ№ж•°дјјз„¶еҮҪж•°зҡ„жһҒеҖјзӮ№еҸӮж•°ОёпјҢдҪҝеҜ№ж•°дјјз„¶еҮҪж•°еҸ–еҫ—жңҖеӨ§еҖјпјҡ
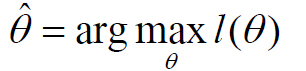
ж №жҚ®д»ҘдёҠе…¬ејҸпјҢеңЁж ·жң¬зӮ№жңҚд»ҺжӯЈжҖҒеҲҶеёғпјҢдё”еқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳөжңӘзҹҘзҡ„жғ…еҶөдёӢпјҢжҲ‘们еҸҜд»Ҙеҫ—еҲ°д»ҘдёӢдёӨдёӘе…¬ејҸпјҢеҲҶеҲ«и®Ўз®—дј°и®ЎеқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳөгҖӮ
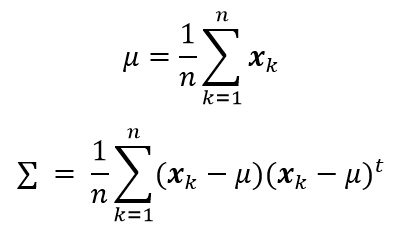
дәҢгҖҒиҙқеҸ¶ж–Ҝдј°и®Ўжі•
еңЁжңҖеӨ§дјјз„¶дј°и®ЎдёӯпјҢеҒҮи®ҫеҸӮж•°ОёжңӘзҹҘпјҢдҪҶдәӢе®һдёҠе®ғжҳҜзЎ®е®ҡзҡ„йҮҸгҖӮеңЁиҖҢеңЁиҙқеҸ¶ж–Ҝдј°и®Ўжі•дёӯпјҢеҸӮж•°Оёи§ҶдёәдёҖдёӘйҡҸжңәеҸҳйҮҸгҖӮеҗҺйӘҢжҰӮзҺҮP(x| D) зҡ„и®Ўз®—жҳҜиҙқеҸ¶ж–ҜеӯҰд№ зҡ„жңҖз»Ҳзӣ®зҡ„пјҢе…¶ж ёеҝғй—®йўҳжҳҜз»ҷе®ҡж ·жң¬йӣҶеҗҲDпјҢи®Ўз®—P(Оё| D)гҖӮж–№жі•дәҢе’Ңж–№жі•дёүе°ұеұһдәҺиҙқеҸ¶ж–Ҝдј°и®Ўжі•гҖӮпјҲе…¬ејҸзҡ„жҺЁеҜјжңүеҫ…иҝӣдёҖжӯҘз ”з©¶пјү
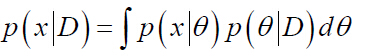
зҰ»ж•Јжғ…еҶөпјҡ
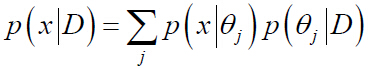
дёүгҖҒдј°и®Ўж–№жі•зҡ„е…¬ејҸжҖ»з»“
иҝҷйҮҢеҒҮи®ҫж ·жң¬зӮ№жңҚд»ҺжӯЈжҖҒеҲҶеёғпјҢдё”еқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳөжңӘзҹҘзҡ„жғ…еҶөдёӢпјҢж–№жі•дёҖи®Ўз®—дј°и®ЎеқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳөпјҡ
ж–№жі•дәҢи®Ўз®—дј°и®ЎеқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳөпјҡ
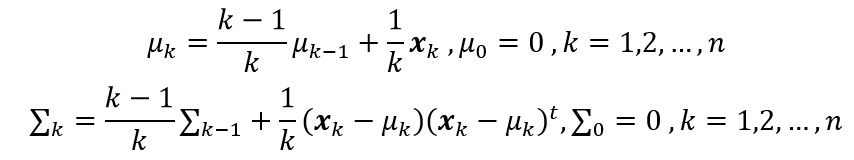
ж–№жі•дёүи®Ўз®—дј°и®ЎеқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳөпјҡ
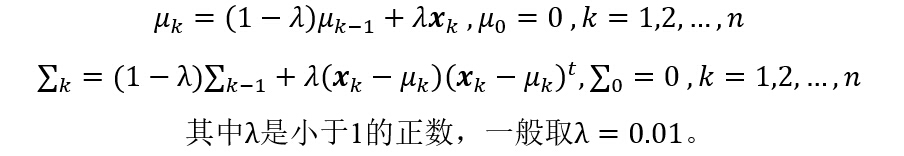
е…¶дёӯпјҢО» жҳҜдёҖдёӘе°ҸдәҺ1зҡ„жӯЈж•°пјҢдёҖиҲ¬еҸҜеҸ–О»=0.01гҖӮеҸҜд»ҘзңӢеҲ°пјҢж–№жі•дәҢе’Ңж–№жі•дёүеқҮдҪҝз”Ёиҝӯд»Јзҡ„ж–№жі•жұӮи§ЈжҜҸдёҖжӯҘзҡ„еқҮеҖјзҹўйҮҸе’ҢеҚҸж–№е·®зҹ©йҳөгҖӮ
еӣӣгҖҒдј°и®ЎиҜҜе·®
еңЁж–№жі•дәҢгҖҒдёүдёӯпјҢеңЁз¬¬kжӯҘзҡ„дј°и®ЎиҜҜе·®еҸҜд»Ҙз”ұдёӢйқўзҡ„е…¬ејҸи®Ўз®—пјҡ
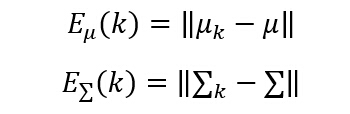
дёҠйқўзҡ„ жҳҜеҗ‘йҮҸе’Ңзҹ©йҳөиҢғж•°пјҢдёҖиҲ¬еҸҜд»ҘеҸ–欧ж°ҸиҢғж•°зҡ„еҪўејҸгҖӮ
жҳҜеҗ‘йҮҸе’Ңзҹ©йҳөиҢғж•°пјҢдёҖиҲ¬еҸҜд»ҘеҸ–欧ж°ҸиҢғж•°зҡ„еҪўејҸгҖӮ
дә”гҖҒе®һйӘҢжӯҘйӘӨдёҺи®Ёи®ә
еҜ№дёҚеҗҢз»ҙж•°дёӢзҡ„й«ҳж–ҜжҰӮзҺҮеҜҶеәҰжЁЎеһӢпјҢз”ЁжңҖеӨ§дјјз„¶дј°и®Ўзӯүж–№жі•еҜ№е…¶еҸӮж•°иҝӣиЎҢдј°и®ЎгҖӮеҒҮи®ҫжңүжҰӮзҺҮеҜҶеәҰдёәй«ҳж–ҜеҲҶеёғp(x) ~N(Ој,вҲ‘)зҡ„ж ·жң¬йӣҶеҗҲS={xk,k = 1,2,вҖҰ,n}пјҢеҸҜд»ҘдҪҝз”Ёд»ҘдёҠд»Ӣз»Қзҡ„дёүз§Қж–№жі•иҝӣиЎҢеқҮеҖјзҹўйҮҸе’ҢеҚҸж–№е·®зҹ©йҳөзҡ„еҸӮж•°дј°и®ЎпјҢе®һйӘҢжӯҘйӘӨдё»иҰҒеҢ…жӢ¬д»ҘдёӢеҮ дёӘйғЁеҲҶпјҡ
1)еҸӮиҖғ:http://blog.csdn.net/liyuefeilong/article/details/44247589В дёӯзҡ„зЁӢеәҸпјҢи°ғз”ЁжЁЎејҸзұ»з”ҹжҲҗеҮҪж•°MixGaussianпјҢиҰҒжұӮз»ҷе®ҡдёҖз»„еқҮеҖјпјҲеқҮеҖјеҗ‘йҮҸпјүе’Ңж–№е·®пјҲеҚҸж–№е·®зҹ©йҳөпјүпјҢз”ҹжҲҗдёҖз»ҙгҖҒдәҢз»ҙжҲ–дёүз»ҙзҡ„й«ҳж–ҜеҲҶеёғзҡ„ж•ЈзӮ№пјҢжҜҸдёҖз»„ж•°жҚ®йӣҶеҗҲзҡ„ж ·жң¬дёӘж•°дёә100гҖӮ
2)еҲ©з”ЁдёҠйқўд»Ӣз»Қзҡ„ж–№жі•дёҖгҖҒж–№жі•дәҢе’Ңж–№жі•дёүпјҢеҲҶеҲ«дј°и®Ўиҝҷдёүз»„ж•°жҚ®зҡ„еқҮеҖјпјҲеқҮеҖјеҗ‘йҮҸпјүе’Ңж–№е·®пјҲеҚҸж–№е·®зҹ©йҳөпјүгҖӮ
3)еҲ©з”ЁдёҠйқўд»Ӣз»Қзҡ„иҜҜе·®и®Ўз®—е…¬ејҸпјҢи®Ўз®—ж–№жі•дёҖгҖҒж–№жі•дәҢе’Ңж–№жі•дёүзҡ„дј°и®ЎиҜҜе·®гҖӮеҜ№дәҺж–№жі•дәҢе’Ңж–№жі•дёүпјҢи®Ўз®—жҜҸдёҖж¬Ўиҝӯд»Јдј°и®Ўзҡ„иҜҜе·®еҖјпјҢ并з»ҳеҲ¶еҮәиҜҜе·®жӣІзәҝеӣҫгҖӮ
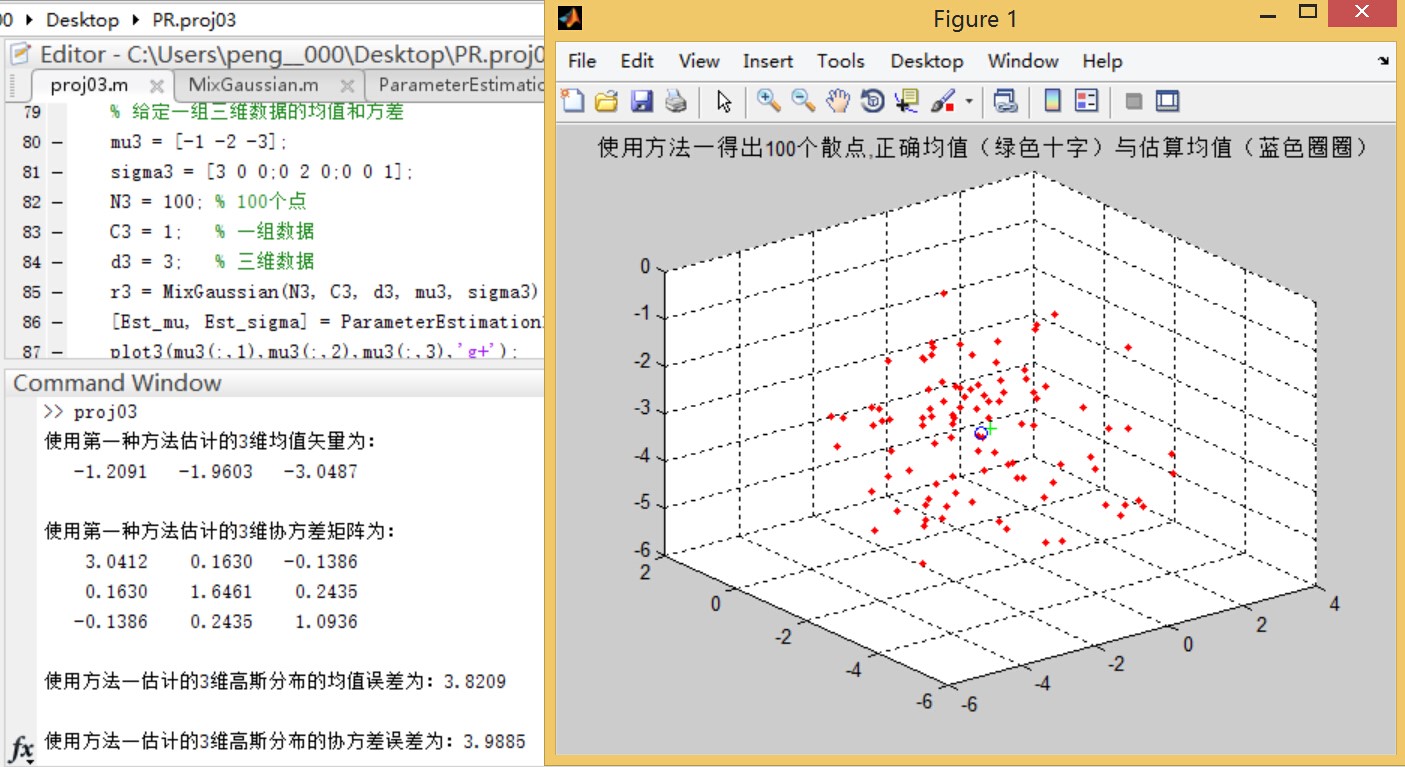
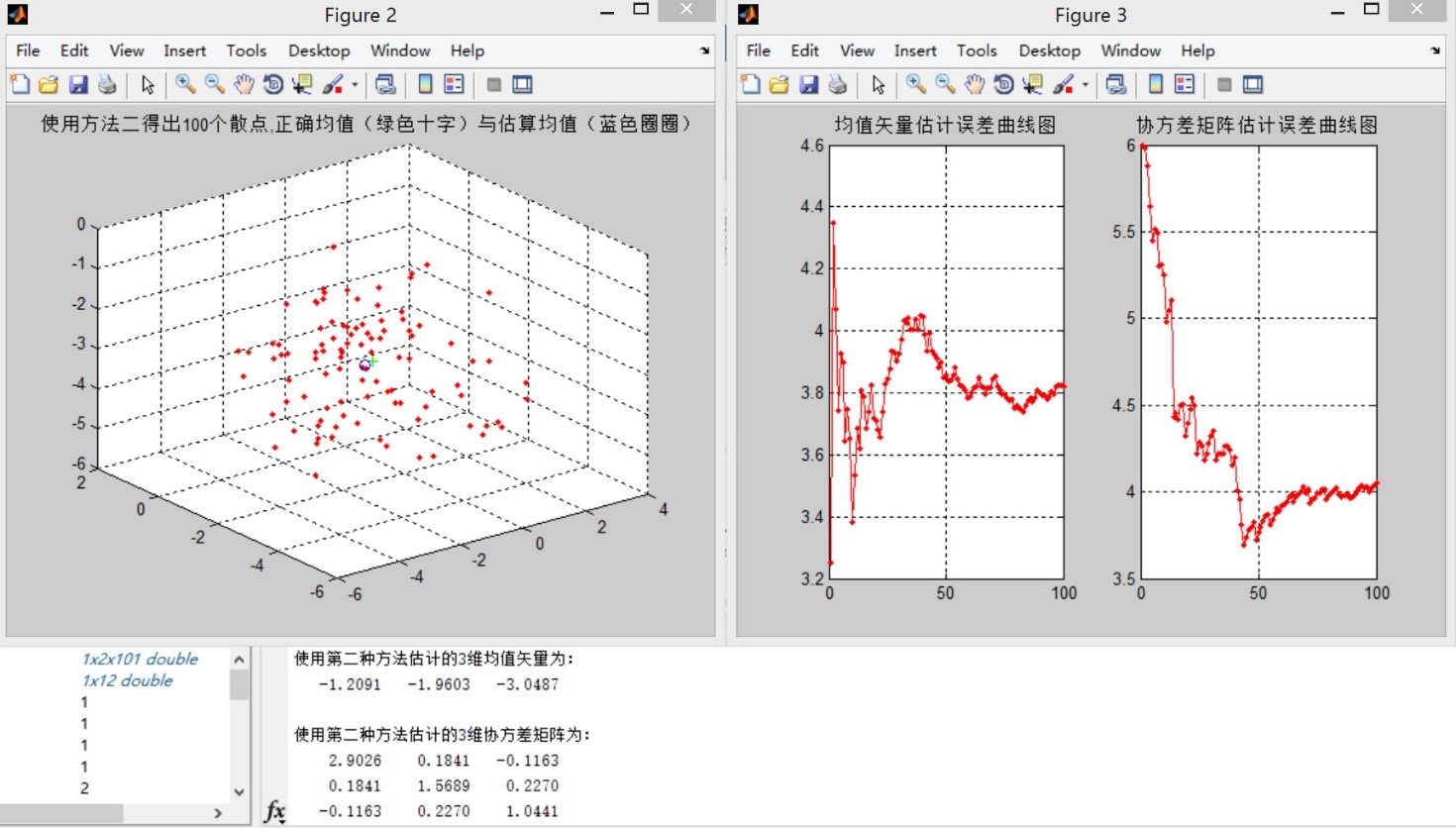
иҝҷйҮҢз”ҹжҲҗдёүз»ҙж•ЈзӮ№еӣҫпјҢд»ҘдёӢжҳҜдёүз§Қж–№жі•зҡ„дј°и®Ўз»“жһңдёҺиҜҜе·®жӣІзәҝеӣҫпјҡ
ж–№жі•дёҖпјҡ
ж–№жі•дәҢпјҡ
ж–№жі•дёүпјҡ
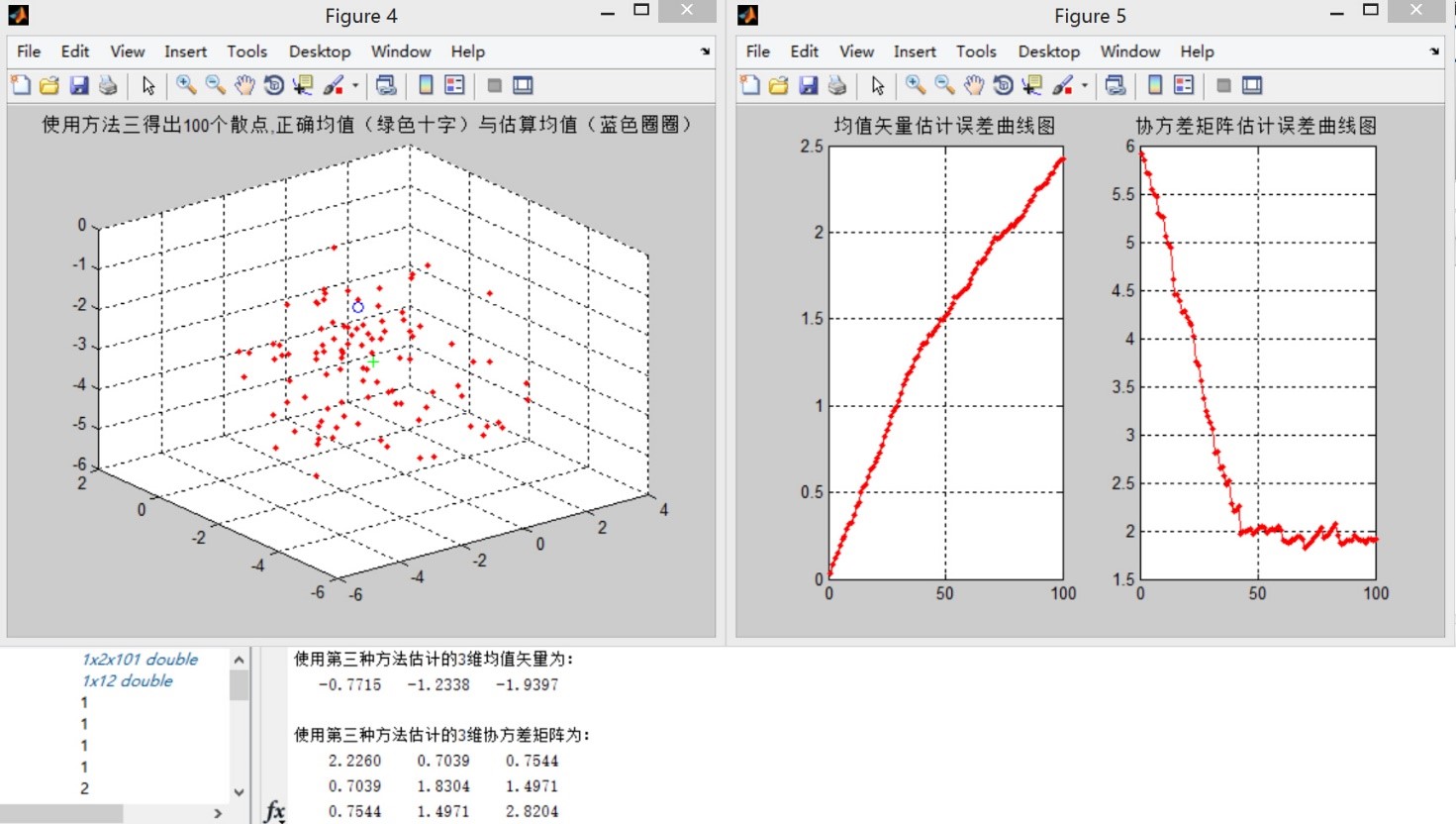
з»“и®әдёҖпјҡВ и§ӮеҜҹиҜҜе·®жӣІзәҝеӣҫпјҢж–№жі•дёүеңЁдј°и®Ўж ·жң¬зӮ№дёӘж•°е°‘зҡ„ж—¶еҖҷжҜ”ж–№жі•дәҢзҡ„еқҮеҖјиҜҜе·®жӣҙе°ҸпјҢдҪҶж–№жі•дәҢзҡ„еқҮеҖјиҜҜе·®жӣІзәҝжҖ»дҪ“е‘ҲеҚ•и°ғйҖ’еҮҸзҡ„иө°еҠҝпјҢиҖҢж–№жі•дёүжӯЈеҘҪзӣёеҸҚгҖӮеңЁи§ӮеҜҹиҜҜе·®жӣІзәҝж—¶пјҢж— жі•жүҫеҮәжӣҙеӨҡеҸҜйқ зҡ„规еҫӢгҖӮиҖғиҷ‘еҲ°иҝҷйҮҢж ·жң¬зӮ№еҸӘжңү100дёӘпјҢеӣ жӯӨеўһеҠ ж ·жң¬зӮ№дёӘж•°иҝӣиЎҢе®һйӘҢгҖӮ
4)еңЁ(1)дёӯпјҢе°ҶжҜҸдёҖдёӘж•°жҚ®йӣҶеҗҲзҡ„ж ·жң¬дёӘж•°еҸҳдёә10000пјҢйҮҚж–°з”ҹжҲҗж•°жҚ®йӣҶеҗҲпјҢйҮҚеӨҚ(2) (3)дёӯзҡ„е®һйӘҢгҖӮ
ж–№жі•дёҖпјҡ
ж–№жі•дәҢпјҡ
ж–№жі•дёүпјҡ
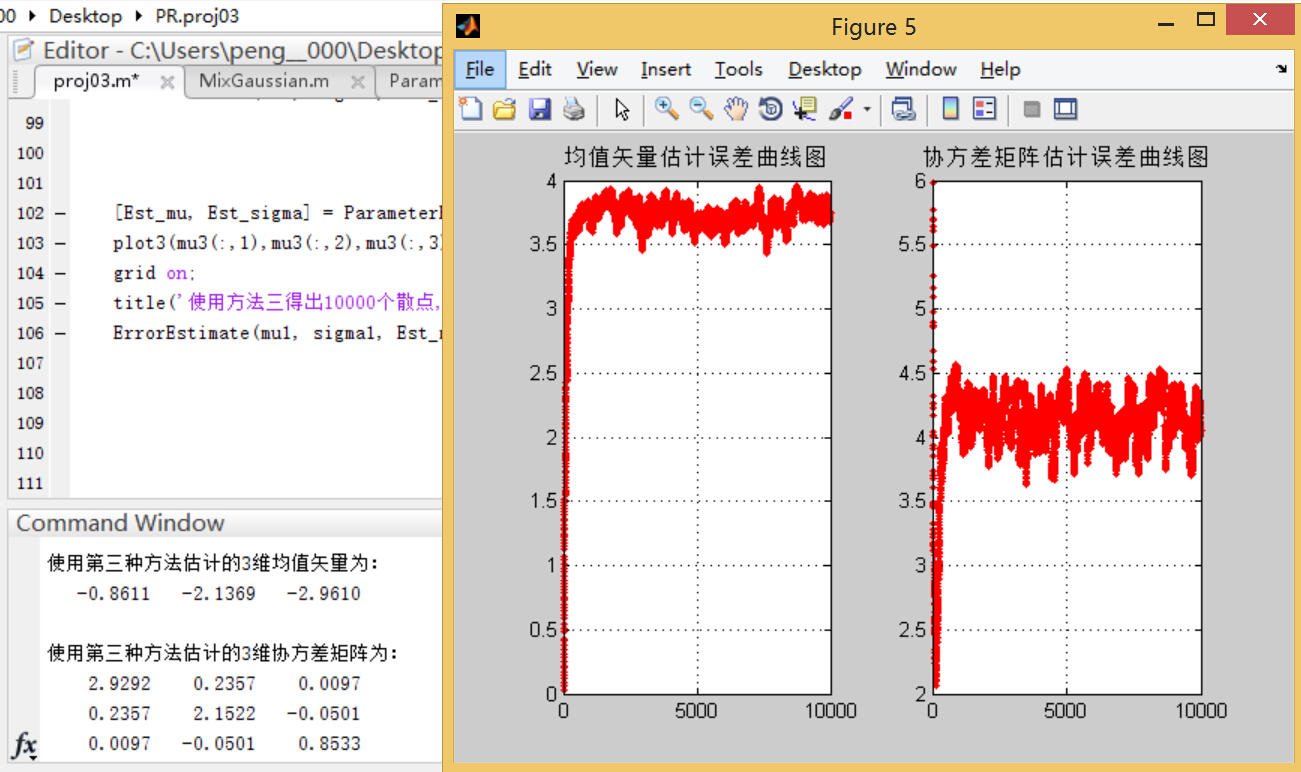
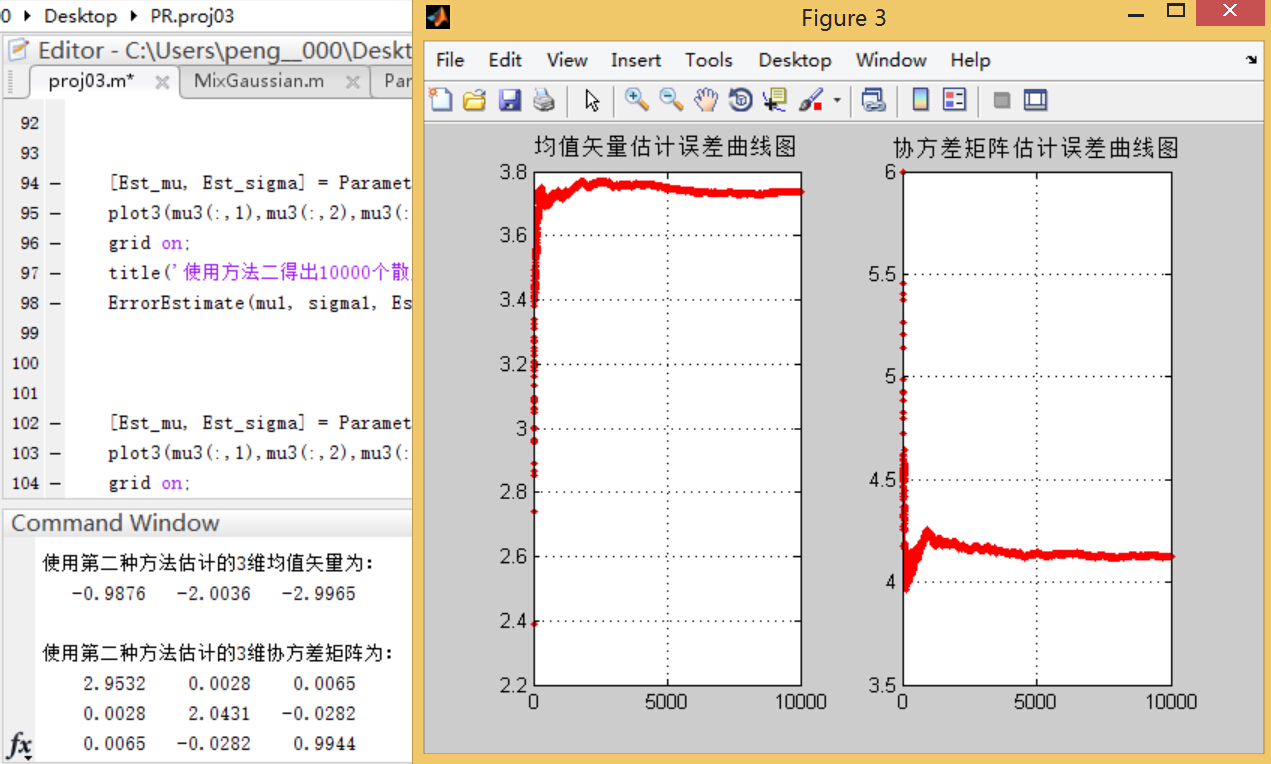
з»“и®әдәҢпјҡеҸҜд»ҘзңӢеҲ°пјҢдҪҝз”Ёж–№жі•дәҢиҝӣиЎҢиҝӯд»ЈжұӮеҸ–еқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳөзҡ„ж–№жі•зҡ„иҜҜе·®жӣІзәҝйҡҸзқҖж ·жң¬зӮ№ж•°зҡ„еўһеӨҡиҖҢеҢәеҹҹе№ізј“пјӣзӣёжҜ”д№ӢдёӢпјҢж–№жі•дёүзҡ„иҜҜе·®жӣІзәҝеҸҳеҢ–е№…еәҰиҫғеӨ§пјҢиҖҢдё”еңЁж ·жң¬дёӘж•°иҫғеӨҡзҡ„жғ…еҶөдёӢиҜҜе·®иҰҒеӨ§дәҺж–№жі•дәҢгҖӮ
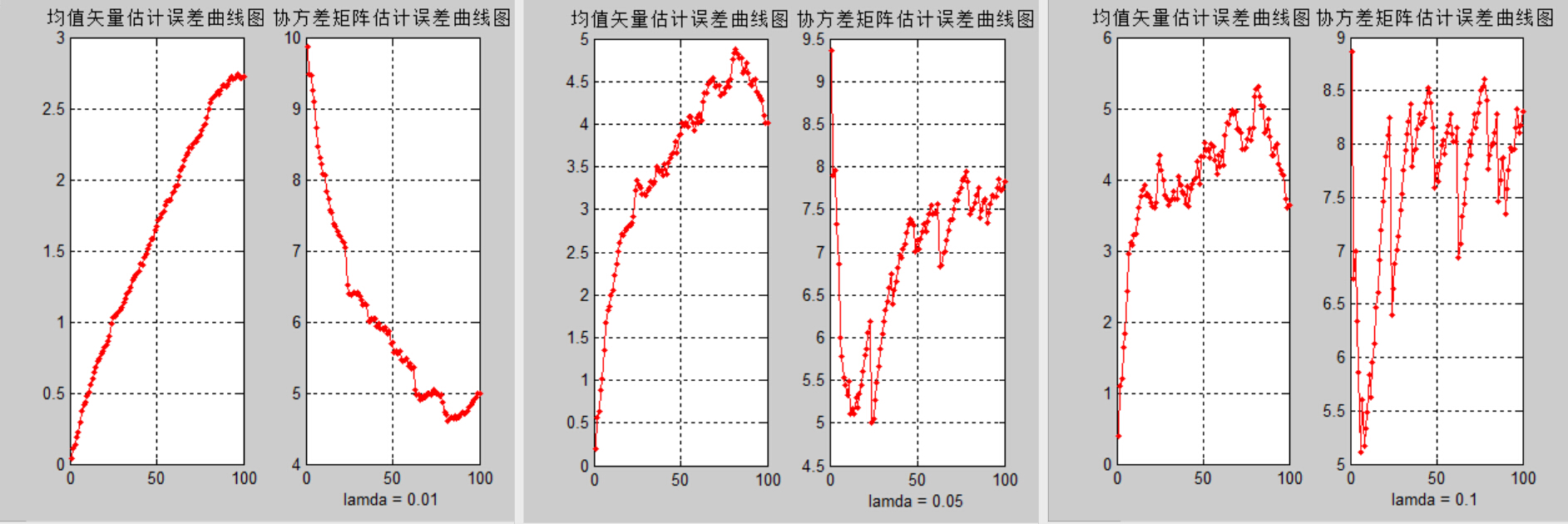
5)иҜҘйғЁеҲҶжҳҜи®әиҜҒж–№жі•дёүдёӯО»зҡ„еҸ–еҖјеҜ№дј°и®ЎиҜҜе·®зҡ„еҪұе“ҚгҖӮиҝҷйҮҢйҖүеҸ–дёҚеҗҢзҡ„О»еҖјпјҢйҮҚеӨҚ(2) (3) (4)дёӯзҡ„е®һйӘҢпјҢи§ӮеҜҹз»“жһңзҡ„ејӮеҗҢпјҢ并еҠ д»Ҙи§ЈйҮҠеҲҶжһҗгҖӮ
100ж•°жҚ®lamdaжҜ”иҫғпјҡ
10000ж•°жҚ®lamdaжҜ”иҫғпјҡ
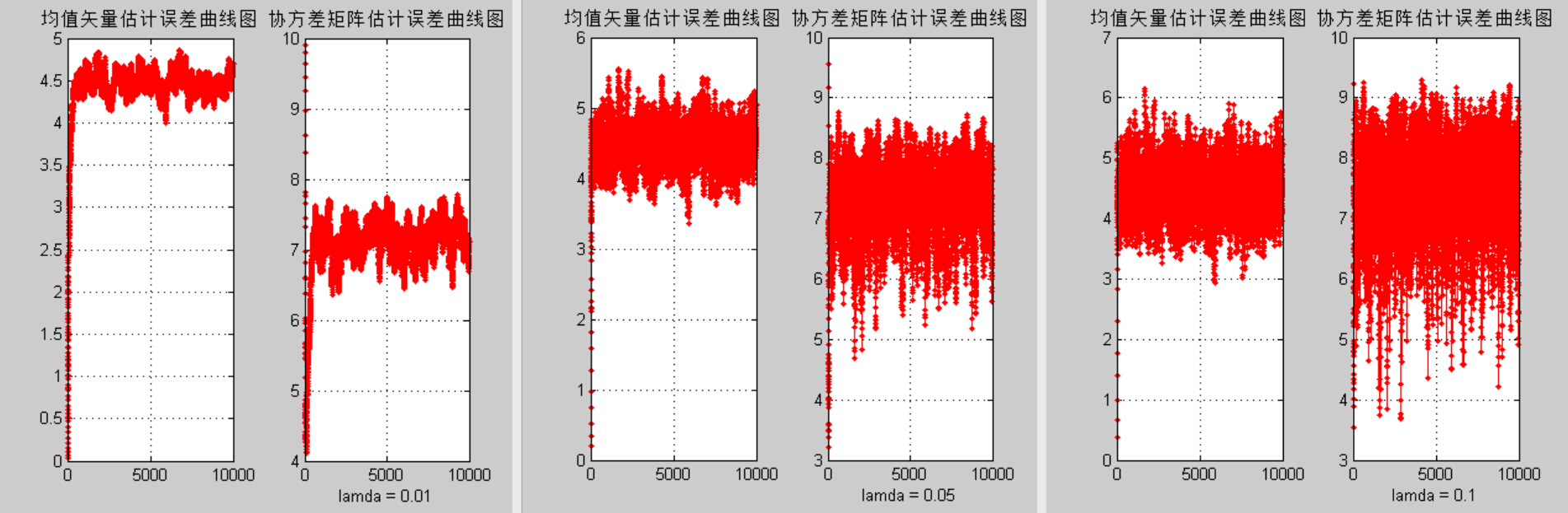
з»“и®әдёүпјҡз»“еҗҲиҫ“еҮәз»“жһңеҸҜд»ҘеҸ‘зҺ°пјҢж–№жі•дёүдёӯО»зҡ„еҸ–еҖјеҜ№еқҮеҖјзҹўйҮҸдј°и®Ўе’ҢеҚҸж–№е·®зҹ©йҳөдј°и®Ўзҡ„иҜҜе·®жңүеҫҲеӨ§еҪұе“ҚпјҢиҝҮеӨ§зҡ„О»еҸ–еҖјдјҡеҜјиҮҙжӣҙеӨ§зҡ„дј°и®ЎиҜҜе·®пјҢеӣ жӯӨйҖҡеёёО»еҸ–0.01гҖӮ
жҖ»з»“пјҡз”ұдәҺе®һйӘҢйҮҮз”ЁдәҶжңүйҷҗж ·жң¬дј°и®ЎеёҰжқҘдәҶдёҖе®ҡзҡ„дј°и®ЎиҜҜе·®пјҢиҝҷдёҖиҜҜе·®зҡ„еҪұе“ҚеҸҜд»ҘйҖҡиҝҮеўһеҠ ж ·жң¬дёӘж•°зҡ„ж–№жі•жқҘеҮҸе°ҸгҖӮеңЁзҗҶи®әдёҠпјҢиҙқеҸ¶ж–Ҝдј°и®Ўж–№жі•жңүеҫҲејәзҡ„зҗҶи®әе’Ңз®—жі•еҹәзЎҖпјҢдҪҶе®һйҷ…дёӯпјҢжңҖеӨ§дјјз„¶дј°и®Ўз®—жі•жӣҙеҠ з®ҖдҫҝпјҢиҖҢдё”и®ҫи®ЎеҮәзҡ„еҲҶзұ»еҷЁжҖ§иғҪеҮ д№ҺдёҺиҙқеҸ¶ж–Ҝж–№жі•еҫ—еҲ°зҡ„з»“жһңзӣёе·®ж— еҮ гҖӮиӢҘзў°еҲ°ж ·жң¬зӮ№дёӘж•°еҫҲе°‘ж—¶пјҢеҸҜд»Ҙе°қиҜ•дҪҝз”Ёж–№жі•дёүиҝӣиЎҢдј°и®ЎгҖӮ
жңҖеҗҺз»ҷеҮәеҮ дёӘдё»иҰҒеҮҪж•°зҡ„е®ҡд№үпјҢеҸӘйңҖз®ҖеҚ•и®ҫзҪ®еҸӮж•°е°ұеҸҜд»Ҙи°ғз”ЁиҝҷдәӣеҮҪж•°пјҡ
% ж–№жі•дёҖиҝӣиЎҢеҸӮж•°дј°и®ЎпјҢиҫ“еҮәдј°и®ЎеқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳө
function [mu,sigma] = ParameterEstimation1(r)
[x,y] = size(r);
% ж•ЈзӮ№зҡ„еқҮеҖји®Ўз®—
mu = sum(r)/x;
% ж•ЈзӮ№зҡ„еҚҸж–№е·®зҹ©йҳөи®Ўз®—
a = 0;
for i = 1:x
a = a + (r(i,:,:) - mu)" * (r(i,:,:) - mu);
end
sigma = a/x;
disp(["дҪҝ用第дёҖз§Қж–№жі•дј°и®Ўзҡ„",num2str(y),"з»ҙеқҮеҖјзҹўйҮҸдёәпјҡ"]);
disp(mu);
disp(["дҪҝ用第дёҖз§Қж–№жі•дј°и®Ўзҡ„",num2str(y),"з»ҙеҚҸж–№е·®зҹ©йҳөдёәпјҡ"]);
disp(sigma);
if y == 1
k=-3:0.1:x;
x=mu + 0.*k; % дә§з”ҹдёҖдёӘе’Ңyй•ҝеәҰзӣёеҗҢзҡ„xж•°з»„
plot(x,k,"g-");
else if y == 2
figure;
plot(r(:,1),r(:,2),"r.");
hold on;
plot(mu(1,1),mu(1,2),"bo");
else if y == 3
figure;
plot3(r(:,1),r(:,2),r(:,3),"r.");
hold on;
plot3(mu(1,1),mu(1,2),mu(1,3),"bo");
end
end
end
title("дҪҝз”Ёж–№жі•дёҖеҫ—еҮәж•ЈзӮ№еӣҫдёҺдј°з®—еқҮеҖјпјҲи“қиүІеңҲеңҲпјү");
% ж–№жі•дәҢиҝӣиЎҢеҸӮж•°дј°и®ЎпјҢиҫ“еҮәдј°и®ЎеқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳө
function [mu,sigma] = ParameterEstimation2(r)
[x,y] = size(r);
% еҘ—з”Ёе…¬ејҸеүҚеқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳөзҡ„еҲқеҖј
mu = zeros(1,y);
sigma = zeros(y,y);
for i = 1:x
mu(:,:,i+1) = mu(:,:,i)*(i-1)/i + r(i,:)/i;
sigma(:,:,i+1) = sigma(:,:,i)*(i-1)/i + (r(i,:) - mu(:,:,i+1))" * (r(i,:) - mu(:,:,i+1)) ./i;
end
disp(["дҪҝ用第дәҢз§Қж–№жі•дј°и®Ўзҡ„",num2str(y),"з»ҙеқҮеҖјзҹўйҮҸдёәпјҡ"]);
disp(mu(1,:,x+1));
disp(["дҪҝ用第дәҢз§Қж–№жі•дј°и®Ўзҡ„",num2str(y),"з»ҙеҚҸж–№е·®зҹ©йҳөдёәпјҡ"]);
disp(sigma(:,:,x+1));
if y == 1
k=-3:0.1:x;
x=mu(1,1,x+1) + 0.*k; % дә§з”ҹдёҖдёӘе’Ңyй•ҝеәҰзӣёеҗҢзҡ„xж•°з»„
plot(x,k,"g-");
else if y == 2
figure;
plot(r(:,1),r(:,2),"r.");
hold on;
plot(mu(1,1,x+1),mu(1,2,x+1),"bo");
else if y == 3
figure;
plot3(r(:,1),r(:,2),r(:,3),"r.");
hold on;
plot3(mu(1,1,x+1),mu(1,2,x+1),mu(1,3,x+1),"bo");
end
end
end
title("дҪҝз”Ёж–№жі•дәҢеҫ—еҮәж•ЈзӮ№еӣҫдёҺдј°з®—еқҮеҖјпјҲи“қиүІеңҲеңҲпјү");
% ж–№жі•дёүиҝӣиЎҢеҸӮж•°дј°и®ЎпјҢиҫ“еҮәдј°и®ЎеқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳө
% иҫ“е…ҘдёҚеҗҢз»ҙеәҰзҡ„й«ҳж–ҜжҰӮзҺҮеҜҶеәҰжЁЎеһӢпјҢдј°и®ЎеқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳө
% lamdaдёәж–№жі•дёүдёӯзҡ„и°ғиҠӮеҸӮж•°пјҢй»ҳи®Өдёә0.01
function [mu,sigma] = ParameterEstimation3(r, lamda)
% lamdaзҡ„зјәзңҒеҖјдёә0.01
default_lamda = 0.01;
% еҰӮжһңеҸӘиҫ“е…ҘrиҖҢжІЎжңүи®ҫе®ҡlamdaпјҢеҲҷlamdaйҖүз”Ёй»ҳи®ӨеҖј
if nargin == 1
lamda = default_lamda;
end
[x,y] = size(r);
% еҘ—з”Ёе…¬ејҸеүҚеқҮеҖје’ҢеҚҸж–№е·®зҹ©йҳөзҡ„еҲқеҖј
mu = zeros(1,y);
sigma = zeros(y,y);
for i = 1:x
mu(:,:,i+1) = mu(:,:,i)*(1 - lamda) + r(i,:) * lamda;
sigma(:,:,i+1) = sigma(:,:,i)*(1 - lamda) + (r(i,:) - mu(:,:,i+1))" * (r(i,:) - mu(:,:,i+1)) .*lamda;
end
disp(["дҪҝ用第дёүз§Қж–№жі•дј°и®Ўзҡ„",num2str(y),"з»ҙеқҮеҖјзҹўйҮҸдёәпјҡ"]);
disp(mu(1,:,x+1));
disp(["дҪҝ用第дёүз§Қж–№жі•дј°и®Ўзҡ„",num2str(y),"з»ҙеҚҸж–№е·®зҹ©йҳөдёәпјҡ"]);
disp(sigma(:,:,x+1));
if y == 1
k=-3:0.1:x;
x=mu(1,1,x+1) + 0.*k; % дә§з”ҹдёҖдёӘе’Ңyй•ҝеәҰзӣёеҗҢзҡ„xж•°з»„
plot(x,k,"g-");
else if y == 2
figure;
plot(r(:,1),r(:,2),"r.");
hold on;
plot(mu(1,1,x+1),mu(1,2,x+1),"bo");
else if y == 3
figure;
plot3(r(:,1),r(:,2),r(:,3),"r.");
hold on;
plot3(mu(1,1,x+1),mu(1,2,x+1),mu(1,3,x+1),"bo");
end
end
end
title("дҪҝз”Ёж–№жі•дёүеҫ—еҮәж•ЈзӮ№еӣҫдёҺдј°з®—еқҮеҖјпјҲи“қиүІеңҲеңҲпјү");
% иҜҜе·®дј°и®ЎеҮҪж•°
function ErrorEstimate(mu, sigma, Est_mu, Est_sigma)
[x,y,z] = size(Est_mu);
if z == 1
Emu = norm((Est_mu - mu),2);
Esigma = norm((Est_sigma - sigma),2);
fprintf(["дҪҝз”Ёж–№жі•дёҖдј°и®Ўзҡ„",num2str(y),"з»ҙй«ҳж–ҜеҲҶеёғзҡ„еқҮеҖјиҜҜе·®дёәпјҡ",num2str(Emu),"
"]);
fprintf(["
дҪҝз”Ёж–№жі•дёҖдј°и®Ўзҡ„",num2str(y),"з»ҙй«ҳж–ҜеҲҶеёғзҡ„еҚҸж–№е·®иҜҜе·®дёәпјҡ",num2str(Esigma),"
"]);
else
for i = 1:z-1
Emu(i) = norm((Est_mu(:,:,i+1) - mu),2);
Esigma(i) = norm((Est_sigma(:,:,i+1) - sigma),2);
end
x = 1:1:z-1;
figure;
subplot(1,2,1);
plot(x,Emu,"r.-");
title("еқҮеҖјзҹўйҮҸдј°и®ЎиҜҜе·®жӣІзәҝеӣҫ");
grid on;
subplot(1,2,2),plot(x,Esigma,"r.-");
title("еҚҸж–№е·®зҹ©йҳөдј°и®ЎиҜҜе·®жӣІзәҝеӣҫ");
grid on;
end