

жң¬ж–Үзҡ„зӣ®зҡ„жҳҜеӯҰд№ е’ҢжҺҢжҸЎBPзҘһз»ҸзҪ‘з»ңзҡ„еҺҹзҗҶеҸҠе…¶еӯҰд№ з®—жі•гҖӮеңЁMATLABе№іеҸ°дёҠзј–зЁӢжһ„йҖ дёҖдёӘ3-3-1еһӢзҡ„singmoidдәәе·ҘзҘһз»ҸзҪ‘з»ңпјҢ并дҪҝз”ЁйҡҸжңәеҸҚеҗ‘дј ж’ӯз®—жі•е’ҢжҲҗжү№еҸҚеҗ‘дј ж’ӯз®—жі•жқҘи®ӯз»ғиҝҷдёӘзҪ‘з»ңпјҢиҝҷйҮҢи®ҫзҪ®дёҚеҗҢзҡ„еҲқе§ӢжқғеҖјпјҢз ”з©¶з®—жі•зҡ„еӯҰд№ жӣІзәҝе’Ңи®ӯз»ғиҜҜе·®гҖӮжңүдәҶд»ҘдёҠзҡ„зҗҶи®әеҹәзЎҖпјҢжңҖеҗҺе°Ҷжһ„йҖ 并и®ӯз»ғдёҖдёӘ3-3-4еһӢзҡ„зҘһз»ҸзҪ‘з»ңжқҘеҲҶзұ»4дёӘзӯүжҰӮзҺҮзҡ„дёүз»ҙж•°жҚ®йӣҶеҗҲгҖӮ
дёҖгҖҒжҠҖжңҜи®әиҝ°
1.зҘһз»ҸзҪ‘з»ңз®Җиҝ°
зҘһз»ҸзҪ‘з»ңжҳҜдёҖз§ҚеҸҜд»ҘйҖӮеә”еӨҚжқӮжЁЎеһӢзҡ„йқһеёёзҒөжҙ»зҡ„еҗҜеҸ‘ејҸзҡ„з»ҹи®ЎжЁЎејҸиҜҶеҲ«жҠҖжңҜгҖӮиҖҢеҸҚеҗ‘дј ж’ӯз®—жі•жҳҜеӨҡеұӮзҘһз»ҸзҪ‘з»ңжңүзӣ‘зқЈи®ӯз»ғдёӯжңҖз®ҖеҚ•д№ҹжңҖдёҖиҲ¬зҡ„ж–№жі•д№ӢдёҖпјҢе®ғжҳҜзәҝжҖ§LMSз®—жі•зҡ„иҮӘ然延伸гҖӮ
зҪ‘з»ңеҹәжң¬зҡ„еӯҰд№ ж–№жі•жҳҜд»ҺдёҖдёӘжңӘи®ӯз»ғзҪ‘з»ңејҖе§ӢпјҢеҗ‘иҫ“е…ҘеұӮжҸҗдҫӣдёҖдёӘи®ӯз»ғжЁЎејҸпјҢеҶҚйҖҡиҝҮзҪ‘з»ңдј йҖ’дҝЎеҸ·пјҢ并еҶіе®ҡиҫ“еҮәеұӮзҡ„иҫ“еҮәеҖјгҖӮжӯӨеӨ„зҡ„иҝҷдәӣиҫ“еҮәйғҪдёҺзӣ®ж ҮеҖјиҝӣиЎҢжҜ”иҫғпјӣд»»дёҖе·®еҖјеҜ№еә”дёҖиҜҜе·®гҖӮиҜҘиҜҜе·®жҲ–еҮҶеҲҷеҮҪж•°жҳҜжқғеҖјзҡ„жҹҗз§Қж ҮйҮҸеҮҪж•°пјҢе®ғеңЁзҪ‘з»ңиҫ“еҮәдёҺжңҹжңӣиҫ“еҮәеҢ№й…Қж—¶иҫҫеҲ°жңҖе°ҸгҖӮжқғеҖјеҗ‘зқҖеҮҸе°ҸиҜҜе·®еҖјзҡ„ж–№еҗ‘и°ғж•ҙгҖӮдёҖдёӘBPзҘһз»ҸзҪ‘з»ңзҡ„еҹәжң¬з»“жһ„еҰӮдёӢеӣҫжүҖзӨәпјҢеӣҫдёӯWji,WkjжҳҜйңҖиҰҒеӯҰд№ зҡ„жқғеҖјзҹ©йҳөпјҡ
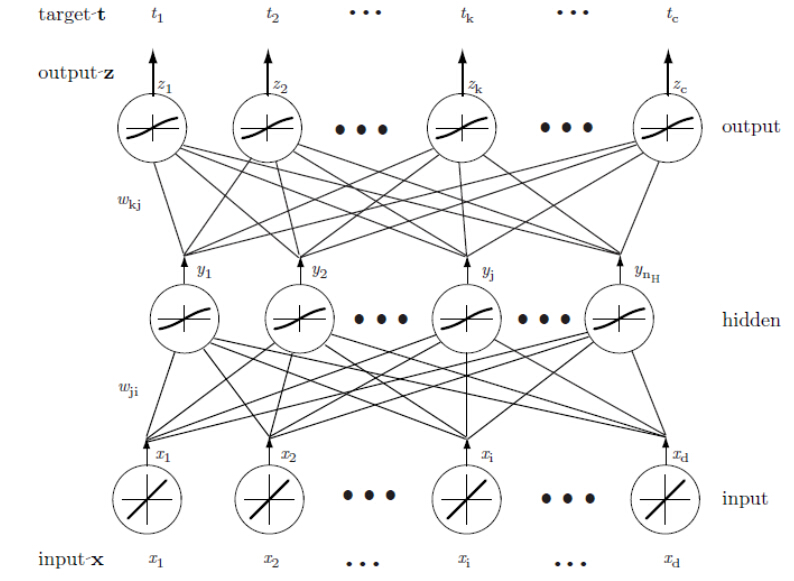
2.дёүеұӮBPзҘһз»ҸзҪ‘з»ң
дёҖдёӘдёүеұӮзҘһз»ҸзҪ‘з»ңжҳҜз”ұдёҖдёӘиҫ“е…ҘеұӮгҖҒдёҖдёӘйҡҗеҗ«еұӮе’ҢдёҖдёӘиҫ“еҮәеұӮз»„жҲҗпјҢ他们з”ұеҸҜдҝ®жӯЈзҡ„жқғеҖјдә’иҝһгҖӮеңЁиҝҷеҹәзЎҖдёҠжһ„е»әзҡ„3-3-1зҘһз»ҸзҪ‘з»ңпјҢжҳҜз”ұдёүдёӘиҫ“е…ҘеұӮгҖҒдёүдёӘйҡҗеҗ«еұӮе’ҢдёҖдёӘиҫ“еҮәеұӮз»„жҲҗгҖӮйҡҗеҗ«еұӮеҚ•е…ғеҜ№е®ғзҡ„еҗ„дёӘиҫ“е…ҘиҝӣиЎҢеҠ жқғжұӮе’Ңиҝҗз®—иҖҢеҪўжҲҗж ҮйҮҸзҡ„вҖңеҮҖжҝҖжҙ»вҖқгҖӮд№ҹе°ұжҳҜиҜҙпјҢеҮҖжҝҖжҙ»жҳҜиҫ“е…ҘдҝЎеҸ·дёҺйҡҗеҗ«еұӮжқғеҖјзҡ„еҶ…з§ҜгҖӮйҖҡеёёеҸҜжҠҠеҮҖжҝҖжҙ»еҶҷжҲҗпјҡ
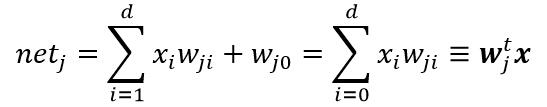
е…¶дёӯxдёәеўһе№ҝиҫ“е…Ҙзү№еҫҒеҗ‘йҮҸпјҲйҷ„еҠ дёҖдёӘзү№еҫҒеҖјx0=1пјүпјҢwдёәжқғеҗ‘йҮҸпјҲйҷ„еҠ дёҖдёӘеҖјW0пјүгҖӮз”ұдёҠйқўзҡ„еӣҫеҸҜзҹҘпјҢиҝҷйҮҢзҡ„дёӢж ҮiжҳҜиҫ“е…ҘеұӮеҚ•е…ғзҡ„зҙўеј•еҖјпјҢjжҳҜйҡҗеҗ«еұӮеҚ•е…ғзҡ„зҙўеј•гҖӮWjiиЎЁзӨәиҫ“е…ҘеұӮеҚ•е…ғiеҲ°йҡҗеҗ«еұӮеҚ•е…ғjзҡ„жқғеҖјгҖӮдёәдәҶи·ҹзҘһз»Ҹз”ҹзү©еӯҰдҪңзұ»жҜ”пјҢиҝҷз§ҚжқғжҲ–иҝһжҺҘиў«з§°дёәвҖңзӘҒи§ҰвҖқпјҢиҝһжҺҘзҡ„еҖјеҸ«вҖңзӘҒи§ҰжқғвҖқгҖӮжҜҸдёҖдёӘйҡҗеҗ«еұӮеҚ•е…ғжҝҖеҸ‘еҮәдёҖдёӘиҫ“еҮәеҲҶйҮҸпјҢиҝҷдёӘеҲҶйҮҸжҳҜеҮҖжҝҖжҙ»netзҡ„йқһзәҝжҖ§еҮҪж•°f(net)пјҢеҚіпјҡ
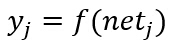
иҝҷйҮҢйңҖиҰҒйҮҚзӮ№и®ӨиҜҶжҝҖжҙ»еҮҪж•°зҡ„дҪңз”ЁгҖӮжҝҖжҙ»еҮҪж•°зҡ„йҖүжӢ©жҳҜжһ„е»әзҘһз»ҸзҪ‘з»ңиҝҮзЁӢдёӯзҡ„йҮҚиҰҒзҺҜиҠӮпјҢдёӢйқўз®ҖиҰҒд»Ӣз»Қеёёз”Ёзҡ„жҝҖжҙ»еҮҪж•°пјҡ
(a)зәҝжҖ§еҮҪж•° ( Liner Function )
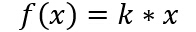
(b) йҳҲеҖјеҮҪж•° ( Threshold Function )
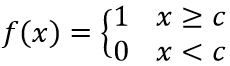
д»ҘдёҠжҝҖжҙ»еҮҪж•°йғҪеұһдәҺзәҝжҖ§еҮҪж•°пјҢдёӢйқўжҳҜдёӨдёӘеёёз”Ёзҡ„йқһзәҝжҖ§жҝҖжҙ»еҮҪж•°пјҡ
(c)SеҪўеҮҪж•° ( Sigmoid Function )
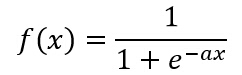
(d) еҸҢжһҒSеҪўеҮҪж•°
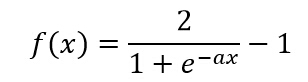
SеҪўеҮҪж•°дёҺеҸҢжһҒSеҪўеҮҪж•°зҡ„еӣҫеғҸеҰӮдёӢпјҡ
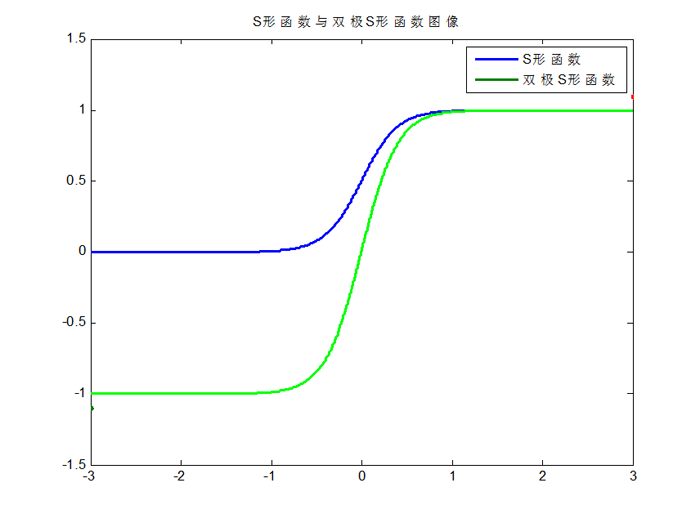
з”ұдәҺSеҪўеҮҪж•°дёҺеҸҢжһҒSеҪўеҮҪж•°йғҪжҳҜеҸҜеҜјзҡ„пјҢеӣ жӯӨйҖӮеҗҲз”ЁеңЁBPзҘһз»ҸзҪ‘з»ңдёӯгҖӮпјҲBPз®—жі•иҰҒжұӮжҝҖжҙ»еҮҪж•°еҸҜеҜјпјү
д»Ӣз»Қе®ҢжҝҖжҙ»еҮҪж•°пјҢзұ»дјјзҡ„пјҢжҜҸдёӘиҫ“еҮәеҚ•е…ғеңЁйҡҗеҗ«еұӮеҚ•е…ғдҝЎеҸ·зҡ„еҹәзЎҖдёҠпјҢдҪҝз”Ёзұ»дјјзҡ„ж–№жі•е°ұеҸҜд»Ҙз®—еҮәе®ғзҡ„еҮҖжҝҖжҙ»еҰӮдёӢпјҡ
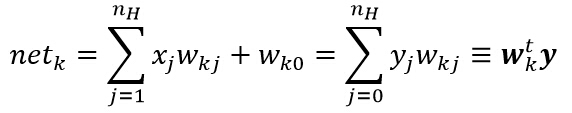
еҗҢзҗҶпјҢиҝҷйҮҢзҡ„дёӢж ҮkжҳҜиҫ“еҮәеұӮеҚ•е…ғзҡ„зҙўеј•еҖјпјҢnHиЎЁзӨәйҡҗеҗ«еұӮеҚ•е…ғзҡ„ж•°зӣ®пјҢиҝҷйҮҢжҠҠеҒҸзҪ®еҚ•е…ғзӯүд»·дәҺдёҖдёӘиҫ“е…ҘжҒ’дёәy0=1зҡ„йҡҗеҗ«еұӮеҚ•е…ғгҖӮе°Ҷиҫ“еҮәеҚ•е…ғи®°дёәzkпјҢиҝҷж ·иҫ“еҮәеҚ•е…ғеҜ№netзҡ„йқһзәҝжҖ§еҮҪж•°еҶҷдёәпјҡ
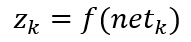
з»јеҗҲд»ҘдёҠе…¬ејҸпјҢжҳҫ然иҫ“еҮәzkеҸҜд»ҘзңӢжҲҗжҳҜиҫ“е…Ҙзү№еҫҒеҗ‘йҮҸxзҡ„еҮҪж•°гҖӮеҪ“жңүcдёӘиҫ“еҮәеҚ•е…ғж—¶пјҢеҸҜд»Ҙиҝҷж ·жқҘиҖғиҷ‘жӯӨзҪ‘з»ңпјҡи®Ўз®—cдёӘеҲӨеҲ«еҮҪж•°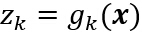 пјҢ并йҖҡиҝҮдҪҝеҲӨеҲ«еҮҪж•°жңҖеӨ§жқҘе°Ҷиҫ“е…ҘдҝЎеҸ·еҲҶзұ»гҖӮеңЁеҸӘжңүдёӨз§Қзұ»еҲ«зҡ„жғ…еҶөдёӢпјҢдёҖиҲ¬еҸӘйҮҮз”ЁеҚ•дёӘиҫ“еҮәеҚ•е…ғпјҢиҖҢз”Ёиҫ“еҮәеҖјzзҡ„з¬ҰеҸ·жқҘж ҮиҜҶдёҖдёӘиҫ“е…ҘжЁЎејҸгҖӮ
пјҢ并йҖҡиҝҮдҪҝеҲӨеҲ«еҮҪж•°жңҖеӨ§жқҘе°Ҷиҫ“е…ҘдҝЎеҸ·еҲҶзұ»гҖӮеңЁеҸӘжңүдёӨз§Қзұ»еҲ«зҡ„жғ…еҶөдёӢпјҢдёҖиҲ¬еҸӘйҮҮз”ЁеҚ•дёӘиҫ“еҮәеҚ•е…ғпјҢиҖҢз”Ёиҫ“еҮәеҖјzзҡ„з¬ҰеҸ·жқҘж ҮиҜҶдёҖдёӘиҫ“е…ҘжЁЎејҸгҖӮ
3.зҪ‘з»ңеӯҰд№
еҸҚеҗ‘дј ж’ӯз®—жі•пјҲBPз®—жі•пјүз”ұдёӨйғЁеҲҶз»„жҲҗпјҡдҝЎжҒҜзҡ„жӯЈеҗ‘дј йҖ’дёҺиҜҜе·®зҡ„еҸҚеҗ‘дј ж’ӯгҖӮеңЁжӯЈеҗ‘дј ж’ӯиҝҮзЁӢдёӯпјҢиҫ“е…ҘдҝЎжҒҜд»Һиҫ“е…Ҙз»Ҹйҡҗеҗ«еұӮйҖҗеұӮи®Ўз®—дј еҗ‘иҫ“еҮәеұӮпјҢ第дёҖеұӮзҘһз»Ҹе…ғзҡ„зҠ¶жҖҒеҸӘеҪұе“ҚдёӢдёҖеұӮзҘһз»Ҹе…ғзҡ„зҠ¶жҖҒгҖӮеҰӮжһңиҫ“еҮәеұӮжІЎжңүеҫ—еҲ°жңҹжңӣзҡ„иҫ“еҮәпјҢеҲҷи®Ўз®—иҫ“еҮәеұӮзҡ„иҜҜе·®еҸҳеҢ–еҖјпјҢ然еҗҺиҪ¬еҗ‘еҸҚеҗ‘дј ж’ӯпјҢйҖҡиҝҮзҪ‘з»ңе°ҶиҜҜе·®дҝЎеҸ·жІҝеҺҹжқҘзҡ„иҝһжҺҘйҖҡи·ҜеҸҚдј еӣһжқҘдҝ®ж”№еҗ„еұӮзҘһз»Ҹе…ғзҡ„жқғеҖјзӣҙиҮіиҫҫеҲ°жңҹжңӣзӣ®ж ҮгҖӮ
зҘһз»ҸзҪ‘з»ңзҡ„еӯҰд№ ж–№жі•жӯЈжҳҜдҫқиө–д»ҘдёҠдёӨдёӘжӯҘйӘӨпјҢеҜ№дәҺеҚ•дёӘжЁЎејҸзҡ„еӯҰд№ и§„еҲҷпјҢиҖғиҷ‘дёҖдёӘжЁЎејҸзҡ„и®ӯз»ғиҜҜе·®пјҢе…Ҳе®ҡд№үдёәиҫ“еҮәз«Ҝзҡ„жңҹжңӣиҫ“еҮәеҖјtkпјҲз”ұж•ҷеёҲдҝЎеҸ·з»ҷеҮәпјүе’Ңе®һйҷ…иҫ“еҮәеҖјzkзҡ„е·®зҡ„е№іж–№е’Ңпјҡ
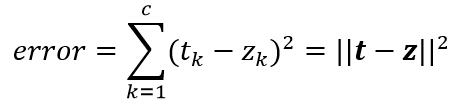
е®ҡд№үзӣ®ж ҮеҮҪж•°пјҡ
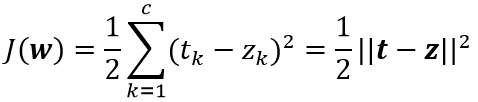
е…¶дёӯtе’ҢzжҳҜй•ҝеәҰдёәcзҡ„зӣ®ж Үеҗ‘йҮҸе’ҢзҪ‘з»ңиҫ“еҮәеҗ‘йҮҸпјӣwиЎЁзӨәзҘһз»ҸзҪ‘з»ңйҮҢзҡ„жүҖжңүжқғеҖјгҖӮ
еҸҚеҗ‘дј ж’ӯз®—жі•еӯҰд№ и§„еҲҷжҳҜеҹәдәҺжўҜеәҰдёӢйҷҚз®—жі•зҡ„гҖӮжқғеҖјйҰ–е…Ҳиў«еҲқе§ӢеҢ–дёәйҡҸжңәеҖјпјҢ然еҗҺеҗ‘иҜҜе·®еҮҸе°Ҹзҡ„ж–№еҗ‘и°ғж•ҙпјҡ
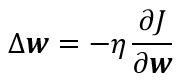
е…¶дёӯО·жҳҜеӯҰд№ зҺҮпјҢиЎЁзӨәжқғеҖјзҡ„зӣёеҜ№еҸҳеҢ–е°әеәҰгҖӮеҸҚеҗ‘дј ж’ӯз®—жі•еңЁз¬¬mж¬Ўиҝӯд»Јж—¶зҡ„жқғеҗ‘йҮҸжӣҙж–°е…¬ејҸеҸҜеҶҷдёәпјҡ
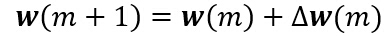
е…¶дёӯmжҳҜзү№е®ҡжЁЎејҸзҡ„зҙўеј•гҖӮз”ұдәҺиҜҜ差并дёҚжҳҜжҳҺжҳҫеҶіе®ҡдәҺWjkпјҢиҝҷйҮҢйңҖиҰҒдҪҝз”Ёй“ҫејҸеҫ®еҲҶжі•еҲҷпјҡ

е…¶дёӯеҚ•е…ғkзҡ„ж•Ҹж„ҹеәҰе®ҡд№үдёәпјҡ
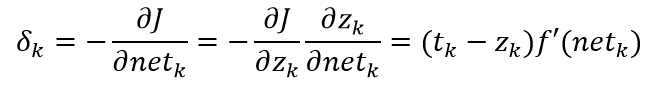
еҸҲжңүпјҡ
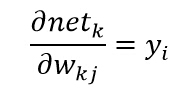
з»јдёҠжүҖиҝ°пјҢйҡҗеҗ«еұӮеҲ°иҫ“еҮәеұӮзҡ„жқғеҖјжӣҙж–°дёәпјҡ
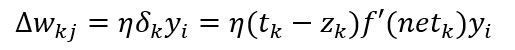
иҫ“е…ҘеұӮеҲ°йҡҗеҗ«еұӮзҡ„жқғеҖјеӯҰд№ и§„еҲҷжӣҙеҫ®еҰҷгҖӮеҶҚиҝҗз”Ёй“ҫејҸжі•еҲҷи®Ўз®—пјҡ

е…¶дёӯпјҡ
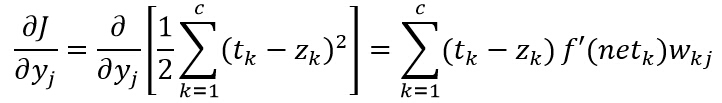
еҸҜд»Ҙз”ЁдёҠејҸжқҘе®ҡд№үйҡҗеҚ•е…ғзҡ„ж•Ҹж„ҹеәҰпјҡ
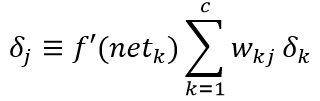
еӣ жӯӨпјҢиҫ“е…ҘеұӮеҲ°йҡҗеҗ«еұӮзҡ„жқғеҖјзҡ„еӯҰд№ и§„еҲҷе°ұжҳҜпјҡ
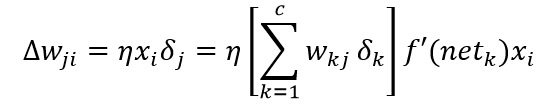
4.и®ӯз»ғеҚҸи®®
еҸҚеҗ‘дј ж’ӯзҡ„йҡҸжңәеҚҸи®®е’ҢжҲҗжү№еҚҸи®®еҰӮдёӢжӯҘйӘӨжүҖзӨәпјҡ

еңЁжҲҗжү№и®ӯз»ғдёӯпјҢжүҖжңүзҡ„и®ӯз»ғжЁЎејҸйғҪе…ҲжҸҗдҫӣдёҖж¬ЎпјҢ然еҗҺе°ҶеҜ№еә”зҡ„жқғеҖјжӣҙж–°зӣёеҠ пјҢеҸӘжңүиҝҷж—¶зҪ‘з»ңйҮҢзҡ„е®һйҷ…жқғеҖјжүҚејҖе§Ӣжӣҙж–°гҖӮиҝҷдёӘиҝҮзЁӢе°ҶдёҖзӣҙиҝӯд»ЈзҹҘйҒ“жҹҗеҒңжӯўеҮҶеҲҷж»Ўи¶ігҖӮ

дәҢгҖҒиҮӘзј–еҮҪж•°е®һзҺ°BPзҪ‘з»ң
д»ҘдёӢз®ҖеҚ•зј–еҶҷдәҶдёҖдёӘ3-3-1дёүеұӮBPзҘһз»ҸзҪ‘з»ңзҡ„жһ„е»әдёҺдёӨз§Қи®ӯз»ғж–№жі•пјҲеҶҷеҫ—жҜ”иҫғжқӮд№ұпјүпјҢд»ҘдёӢжҳҜеҹәжң¬жӯҘйӘӨпјҡ
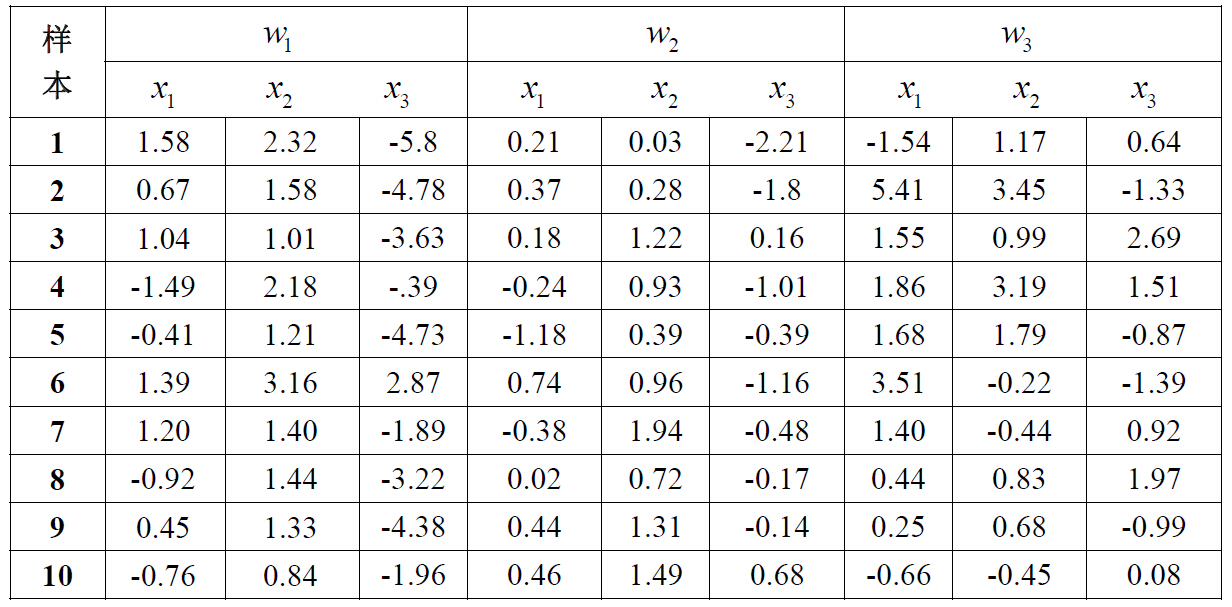
1.жһ„йҖ 3-3-1 еһӢзҡ„sigmoid зҪ‘з»ңпјҢз”Ёд»ҘдёӢиЎЁж јдёӯзҡ„w1е’Ңw2зұ»зҡ„ж•°жҚ®иҝӣиЎҢи®ӯз»ғпјҢ并еҜ№ж–°жЁЎејҸиҝӣиЎҢеҲҶзұ»гҖӮеҲ©з”ЁйҡҸжңәеҸҚеҗ‘дј ж’ӯпјҲз®—жі•1пјүпјҢеӯҰд№ зҺҮО·=0.1пјҢд»ҘеҸҠsigmoidеҮҪж•°пјҢе…¶дёӯa=1.716,b =2/3пјҢдҪңдёәе…¶йҡҗеҚ•е…ғе’Ңиҫ“еҮәеҚ•е…ғзҡ„жҝҖжҙ»еҮҪж•°гҖӮ
2.жһ„йҖ дёүеұӮзҘһз»ҸзҪ‘з»ңпјҢеҸӮж•°еҢ…жӢ¬пјҡиҫ“е…ҘеұӮгҖҒдёӯй—ҙеұӮгҖҒиҫ“еҮәеұӮзҘһз»Ҹе…ғеҗ‘йҮҸпјҢд»ҘеҸҠиҫ“е…ҘеұӮеҲ°дёӯй—ҙеұӮзҡ„жқғеҖјзҹ©йҳөпјҢдёӯй—ҙеұӮеҲ°иҫ“еҮәеұӮзҡ„жқғеҖјзҹ©йҳөпјҢдёӯй—ҙеұӮзҘһз»Ҹе…ғзҡ„еҒҸзҪ®еҗ‘йҮҸпјҢиҫ“еҮәеұӮзҘһз»Ҹе…ғзҡ„еҒҸзҪ®еҗ‘йҮҸзӯүгҖӮе…¶е®һиҙЁжҳҜе®ҡд№үдёҠиҝ°еҸҳйҮҸзҡ„дёҖз»ҙе’ҢдәҢз»ҙж•°з»„гҖӮ
3.зј–еҶҷеҮҪж•°[net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb)пјҢе®һзҺ°BPзҪ‘з»ңзҡ„еүҚйҰҲиҫ“еҮәгҖӮдёәдәҶдҫҝдәҺеҗҺз»ӯзҡ„еӯҰд№ з®—жі•зҡ„е®һзҺ°пјҢиҜҘеҮҪж•°зҡ„иҫ“еҮәеҸҳйҮҸеҢ…еҗ«пјҡ第jдёӘйҡҗеҚ•е…ғеҜ№еҗ„иҫ“е…Ҙзҡ„еҮҖжҝҖжҙ»net_jпјӣ第kдёӘиҫ“еҮәеҚ•е…ғеҜ№еҗ„иҫ“е…Ҙзҡ„еҮҖжҝҖжҙ»net_kпјӣзҪ‘з»ңдёӯйҡҗи—ҸеұӮзҡ„иҫ“еҮәyе’Ңиҫ“еҮәеҚ•е…ғзҡ„иҫ“еҮәеҗ‘йҮҸzгҖӮ
4.зј–еҶҷеҮҪж•°пјҢе®һзҺ°BPзҪ‘з»ңзҡ„жқғеҖјдҝ®жӯЈгҖӮе…¶дёӯпјҢзҘһз»Ҹе…ғеҮҪж•°пјҢеҸҠе…¶еҜјж•°еҸҜеҸӮиҖғпјҡ
зҘһз»Ҹе…ғеҮҪж•°пјҡ
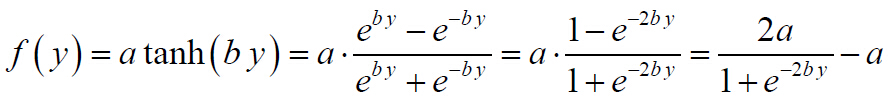
зҘһз»Ҹе…ғеҮҪж•°еҜјж•°пјҡ
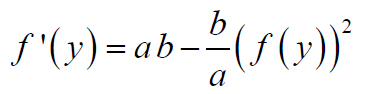
5.зј–еҶҷеҮҪж•°[NewWxy, NewWyz, NewWyb, NewWzb, J] = train(x, t, Wxy, Wyz, Wyb, Wzb)пјҢе®һзҺ°з®—жі•1е’Ң2жүҖиҝ°зҡ„BPзҪ‘з»ңзҡ„и®ӯз»ғз®—жі•пјҢиҫ“еҮәеҗ„жқғеҗ‘йҮҸзҡ„еҸҳеҢ–йҮҸе’ҢеҪ“еүҚзӣ®ж ҮеҮҪж•°еҖјJгҖӮ
% еҮҪж•°пјҡи®Ўз®—дәәе·ҘзҘһз»ҸзҪ‘з»ңзҡ„еҗ„зә§иҫ“еҮә
% иҫ“е…ҘеҸӮж•°:
% xпјҡиҫ“е…ҘеұӮзҘһз»Ҹе…ғеҗ‘йҮҸпјҲ3з»ҙпјү
% WxyпјҡйҡҸжңәз”ҹжҲҗзҡ„д»Һиҫ“е…ҘеұӮеҲ°йҡҗеҗ«еұӮзҡ„жқғеҖјзҹ©йҳө
% WyzпјҡйҡҸжңәз”ҹжҲҗзҡ„д»Һйҡҗеҗ«еұӮеҲ°иҫ“еҮәеұӮзҡ„жқғеҖјзҹ©йҳө
% WybпјҡжқғеҖјеҒҸзҪ®еҗ‘йҮҸ
% WzbпјҡжқғеҖјеҒҸзҪ®еҗ‘йҮҸ
% еҶ…йғЁеҸҳйҮҸдёҺе…¬ејҸпјҡ
% f(net)=a*tanh(b*net)пјҡSigmoidжҝҖжҙ»еҮҪж•°
% aпјҡSigmoidжҝҖжҙ»еҮҪж•°зҡ„еҸӮж•°
% bпјҡSigmoidжҝҖжҙ»еҮҪж•°зҡ„еҸӮж•°
% иҫ“еҮәеҸӮж•°пјҡ
% net_jпјҡ第jдёӘйҡҗеҚ•е…ғеҜ№еҗ„иҫ“е…Ҙзҡ„еҮҖжҝҖжҙ»
% net_kпјҡ第kдёӘиҫ“еҮәеҚ•е…ғеҜ№еҗ„иҫ“е…Ҙзҡ„еҮҖжҝҖжҙ»
% yпјҡйҡҗеҗ«еұӮзҡ„иҫ“еҮәеҗ‘йҮҸ
% zпјҡиҫ“еҮәеҚ•е…ғзҡ„иҫ“еҮәеҗ‘йҮҸ
function [net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb)
% SigmoidжҝҖжҙ»еҮҪж•°зҡ„еҸӮж•°
a = 1.716;
b = 2/3;
net_j = Wxy * x" + Wyb;
y = 3.432 ./ (1 + exp(-1.333 * net_j)) - 1.716;% a * tanh(b * net_j); % йҡҗеҗ«еұӮзҡ„иҫ“еҮә
net_k = Wyz" * y + Wzb;
z = 3.432 ./ (1 + exp(-1.333 * net_k)) - 1.716;%a * tanh(b * net_k); % иҫ“еҮәеұӮз»“жһң
% дәәе·ҘзҘһз»ҸзҪ‘з»ңи®ӯз»ғеҮҪж•°
% иҫ“е…ҘеҸӮж•°:
% xпјҡиҫ“е…ҘеұӮзҘһз»Ҹе…ғеҗ‘йҮҸпјҲ3з»ҙпјү
% tпјҡж•ҷеёҲеҗ‘йҮҸ
% WxyпјҡйҡҸжңәз”ҹжҲҗзҡ„д»Һиҫ“е…ҘеұӮеҲ°йҡҗеҗ«еұӮзҡ„жқғеҖјзҹ©йҳө
% WyzпјҡйҡҸжңәз”ҹжҲҗзҡ„д»Һйҡҗеҗ«еұӮеҲ°иҫ“еҮәеұӮзҡ„жқғеҖјзҹ©йҳө
% WybпјҡжқғеҖјеҒҸзҪ®еҗ‘йҮҸ
% WzbпјҡжқғеҖјеҒҸзҪ®еҗ‘йҮҸ
% еҶ…йғЁеҸҳйҮҸдёҺе…¬ејҸпјҡ
% Error_xyпјҡйҡҗи—ҸеұӮеҸҚдј еӣһиҫ“е…ҘеұӮзҡ„иҜҜе·®
% Error_yzпјҡиҫ“еҮәеұӮеҸҚдј еӣһйҡҗи—ҸеұӮзҡ„иҜҜе·®
% иҫ“еҮәеҸӮж•°пјҡ
% NewWxyпјҡжӣҙж–°еҗҺзҡ„д»Һиҫ“е…ҘеұӮеҲ°йҡҗеҗ«еұӮзҡ„жқғеҖјзҹ©йҳө
% NewWyzпјҡжӣҙж–°еҗҺзҡ„д»Һйҡҗеҗ«еұӮеҲ°иҫ“еҮәеұӮзҡ„жқғеҖјзҹ©йҳө
% NewWybпјҡжӣҙж–°еҗҺзҡ„жқғеҖјеҒҸзҪ®еҗ‘йҮҸ
% NewWzbпјҡжӣҙж–°еҗҺзҡ„жқғеҖјеҒҸзҪ®еҗ‘йҮҸ
function [NewWxy, NewWyz, NewWyb, NewWzb, J] = train(x, t, Wxy, Wyz, Wyb, Wzb)
% еҹәжң¬еҸӮж•°и®ҫе®ҡ
Eta = 0.01; % еӯҰд№ еӣ еӯҗ
% SigmoidжҝҖжҙ»еҮҪж•°зҡ„еҸӮж•°
a = 1.716;
b = 2/3;
% и®Ўз®—и®ӯз»ғж ·жң¬з»ҸиҝҮзҘһз»ҸзҪ‘з»ңеҗҺзҡ„иҫ“еҮә
[net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% и®Ўз®—еҪ“еүҚзӣ®ж ҮеҮҪж•°еҖј
J = power(norm((t - z),2), 2) / 2;
% и®Ўз®—иҫ“еҮәеұӮеҸҚдј еӣһйҡҗи—ҸеұӮзҡ„ж•Ҹж„ҹеәҰ
Error_yz = (t - z) .* (a * b - b / a * z .* z); % zz
% и®Ўз®—йҡҗи—ҸеұӮеҸҚдј еӣһиҫ“е…ҘеұӮзҡ„ж•Ҹж„ҹеәҰ
Error_xy = Wyz * Error_yz .* (a * b - b / a * y .* y);
% и®Ўз®—иҫ“еҮәеұӮеҲ°йҡҗи—ҸеұӮзҡ„жқғеҖјжӣҙж–°йҮҸ
delta_Wyz = Eta * y * Error_yz";
% и®Ўз®—йҡҗи—ҸеұӮеҲ°иҫ“е…ҘеұӮзҡ„жқғеҖјжӣҙж–°йҮҸ
delta_Wxy = Eta * Error_xy * x;
% жӣҙж–°жқғеҖј
NewWxy = Wxy + delta_Wxy;
NewWyz = Wyz + delta_Wyz;
NewWyb = Wyb + Eta * Error_xy;
NewWzb = Wzb + Eta * Error_yz;
function [delta_Wxy, delta_Wyz, Error_xy, Error_yz, J] = BatchTrain(x, t, Wxy, Wyz, Wyb, Wzb)
% еҹәжң¬еҸӮж•°и®ҫе®ҡ
Eta = 0.01; % еӯҰд№ еӣ еӯҗ
% SigmoidжҝҖжҙ»еҮҪж•°зҡ„еҸӮж•°
a = 1.716;
b = 2/3;
% и®Ўз®—и®ӯз»ғж ·жң¬з»ҸиҝҮзҘһз»ҸзҪ‘з»ңеҗҺзҡ„иҫ“еҮә
[net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% и®Ўз®—еҪ“еүҚзӣ®ж ҮеҮҪж•°еҖј
J = 1 / 2 * power(norm(t - z), 2);
% и®Ўз®—иҫ“еҮәеұӮеҸҚдј еӣһйҡҗи—ҸеұӮзҡ„иҜҜе·®
Error_yz = (t - z) .* (a * b - b / a * z .* z);
% и®Ўз®—йҡҗи—ҸеұӮеҸҚдј еӣһиҫ“е…ҘеұӮзҡ„иҜҜе·®
Error_xy = Wyz * Error_yz .* (a * b - b / a * y .* y);
% и®Ўз®—иҫ“еҮәеұӮеҲ°йҡҗи—ҸеұӮзҡ„жқғеҖјжӣҙж–°йҮҸ
delta_Wyz = Eta * Error_yz * y";
% и®Ўз®—йҡҗи—ҸеұӮеҲ°иҫ“е…ҘеұӮзҡ„жқғеҖјжӣҙж–°йҮҸ
delta_Wxy = Eta * Error_xy * x;
% clear all;
% close all;
% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% % BPзҘһз»ҸзҪ‘з»ңе®һйӘҢ
% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
clear;
close all;
% и®ӯз»ғж ·жң¬(3зұ»)
w1 = [ 1.58 2.32 -5.8 ;...
0.67 1.58 -4.78;...
1.04 1.01 -3.63;...
-1.49 2.18 -0.39;...
-0.41 1.21 -4.73;...
1.39 3.16 2.87;...
1.20 1.40 -1.89;...
-0.92 1.44 -3.22;...
0.45 1.33 -4.38;...
-0.76 0.84 -1.96];
w2 = [ 0.21 0.03 -2.21;...
0.37 0.28 -1.8 ;...
0.18 1.22 0.16;...
-0.24 0.93 -1.01;...
-1.18 0.39 -0.39;...
0.74 0.96 -1.16;...
-0.38 1.94 -0.48;...
0.02 0.72 -0.17;...
0.44 1.31 -0.14;...
0.46 1.49 0.68];
w3 = [-1.54 1.17 0.64;...
5.41 3.45 -1.33;...
1.55 0.99 2.69;...
1.86 3.19 1.51;...
1.68 1.79 -0.87;...
3.51 -0.22 -1.39;...
1.40 -0.44 0.92;...
0.44 0.83 1.97;...
0.25 0.68 -0.99;...
-0.66 -0.45 0.08];
% еҲқе§ӢеҢ–жқғеҖј(йҡҸжңәеҲқе§ӢеҢ–)
Wxy = rand(3,3) * 2 - 1;
Wyz = rand(3,1) * 2 - 1;
Wyb = rand(3,1) * 2 - 1;
Wzb = rand() * 2 - 1;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % ж•ҷеёҲеҗ‘йҮҸ
% д»ҘдёӢжҳҜйҡҸжңәеҸҚеҗ‘дј ж’ӯз®—жі•
delta_J = 0.001;
time = 1;
J(time) = 2 * delta_J; % еҸӘжҳҜи®©иҝӯд»ЈејҖе§ӢпјҢжІЎд»Җд№ҲдҪңз”Ё
detJ = 2 * delta_J;
while time < 10000%detJ > delta_J
num = ceil(rand(1) * 20); % йҖүжӢ©дә§з”ҹдёҖдёӘ1еҲ°20д№Ӣй—ҙзҡ„йҡҸжңәж•°
x = w(num, :); % д»»еҸ–wдёӯдёҖдёӘжЁЎејҸ
t = T(num);
time = time + 1; % и®Ўз®—иҝӯд»Јж¬Ўж•°
[NewWxy, NewWyz, NewWyb, NewWzb, J(time)] = train(x, t, Wxy, Wyz, Wyb, Wzb);
% жӣҙж–°жқғеҖј
Wxy = NewWxy;
Wyz = NewWyz;
Wyb = NewWyb;
Wzb = NewWzb;
detJ = abs(J(time) - J(time - 1)); % еүҚеҗҺдёӨж¬Ўзӣ®ж ҮеҮҪж•°зҡ„е·®еҖј
end
Jt = J(2:time); % J(1)е’ҢJ(2)еӯҳеӮЁдәҶзӣёеҗҢзҡ„еҖјпјҢд»ҺJ(2)з®—иө·пјҢиҝӯд»ЈдәҶ(time - 1)ж¬Ў
figure,plot(Jt);grid on;% subplot(1,2,1)
xlabel(["жқғеҖјдёәйҡҸжңәж—¶пјҢиҝӯд»Јж¬Ўж•°дёәпјҡ",num2str(time - 1),"ж¬Ў"]);
for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
a(i) = z;
end
% еҲқе§ӢеҢ–жқғеҖј(0.5е’Ң-0.5)
Wxy = 0.5 * ones(3,3);
Wyz = -0.5 * ones(3,1);
Wyb = 0.5 * ones(3,1);
Wzb = -0.5;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % ж•ҷеёҲеҗ‘йҮҸ
%
% д»ҘдёӢжҳҜйҡҸжңәеҸҚеҗ‘дј ж’ӯз®—жі•
delta_J = 0.001;
time = 1;
% [net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% J(time) = 1 / 2 * power(norm(t - z), 2);
detJ = 2 * delta_J;
while time < 10000%detJ > delta_J
num = ceil(rand(1) * 20); % йҖүжӢ©дә§з”ҹдёҖдёӘ1еҲ°20д№Ӣй—ҙзҡ„йҡҸжңәж•°
x = w(num, :); % д»»еҸ–wдёӯдёҖдёӘжЁЎејҸ
t = T(num);
time = time + 1; % и®Ўз®—иҝӯд»Јж¬Ўж•°
[NewWxy, NewWyz, NewWyb, NewWzb, J(time)] = train(x, t, Wxy, Wyz, Wyb, Wzb);
% жӣҙж–°жқғеҖј
Wxy = NewWxy;
Wyz = NewWyz;
Wyb = NewWyb;
Wzb = NewWzb;
% detJ = abs(J(time) - J(time - 1)); % еүҚеҗҺдёӨж¬Ўзӣ®ж ҮеҮҪж•°зҡ„е·®еҖј
end
Jt = J(2:time); % J(1)е’ҢJ(2)еӯҳеӮЁдәҶзӣёеҗҢзҡ„еҖјпјҢд»ҺJ(2)з®—иө·пјҢиҝӯд»ЈдәҶ(time - 1)ж¬Ў
figure,plot(Jt);grid on;% subplot(1,2,2),
xlabel(["жқғеҖјдёәеӣәе®ҡж—¶пјҢиҝӯд»Јж¬Ўж•°дёәпјҡ",num2str(time - 1),"ж¬Ў"]);
for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
b(i) = z;
end
% д»ҘдёӢжҳҜжҲҗжү№еҸҚеҗ‘дј ж’ӯз®—жі•
Eta = 0.01; % еӯҰд№ еӣ еӯҗ
% еҲқе§ӢеҢ–жқғеҖј(йҡҸжңәеҲқе§ӢеҢ–)
Wxy = rands(3,3);
Wyz = rand(3,1);
Wyb = rand(3,1);
Wzb = rand();
SumDelta_Wxy = zeros(3,3);
SumDelta_Wyz = zeros(3,1);
SumError_xy = zeros(3,1);
SumError_yz = 0;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % ж•ҷеёҲеҗ‘йҮҸ
delta_J = 0.001;
time = 1;
J(time) = 2 * delta_J;
detJ = 2 * delta_J;
% [net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% J(time) = delta_J * 2; % 1 / 2 * power(norm(t - z), 2);
while time < 1000 %detJ > delta_J
time = time + 1; % и®Ўз®—иҝӯд»Јж¬Ўж•°
J(time) = 0;
for num = 1:20
x = w(num, :); % д»»еҸ–w1дёӯдёҖдёӘжЁЎејҸ
t = T(num);
[delta_Wxy, delta_Wyz, Error_xy, Error_yz, Jt] = BatchTrain(x, t, Wxy, Wyz, Wyb, Wzb);
SumDelta_Wxy = SumDelta_Wxy + delta_Wxy;
SumDelta_Wyz = SumDelta_Wyz + delta_Wyz";
SumError_xy = SumError_xy + Error_xy;
SumError_yz = SumError_yz + Error_yz;
J(time) = J(time) + Jt;
end
% жӣҙж–°жқғеҖј
Wxy = Wxy + SumDelta_Wxy;
Wyz = Wyz + SumDelta_Wyz;
Wyb = Wyb + Eta * SumError_xy;
Wzb = Wzb + Eta * SumError_yz;
detJ = abs(J(time) - J(time - 1)); % еүҚеҗҺдёӨж¬Ўзӣ®ж ҮеҮҪж•°зҡ„е·®еҖј
end
Jt = J(1, 2:time); % J(1)е’ҢJ(2)еӯҳеӮЁдәҶзӣёеҗҢзҡ„еҖјпјҢд»ҺJ(2)з®—иө·пјҢиҝӯд»ЈдәҶ(time - 1)ж¬Ў
figure,plot(Jt);grid on;
xlabel(["жқғеҖјдёәйҡҸжңәж—¶пјҢиҝӯд»Јж¬Ўж•°дёәпјҡ",num2str(time - 1),"ж¬Ў"]);
for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
c(i) = z;
end
c
% д»ҘдёӢжҳҜжҲҗжү№еҸҚеҗ‘дј ж’ӯз®—жі•
Eta = 0.001; % еӯҰд№ еӣ еӯҗ
% еҲқе§ӢеҢ–жқғеҖј(0.5е’Ң-0.5)
Wxy = 0.5 * ones(3,3);
Wyz = -0.5 * ones(3,1);
Wyb = 0.5 * ones(3,1);
Wzb = -0.5;
SumDelta_Wxy = zeros(3,3);
SumDelta_Wyz = zeros(3,1);
SumError_xy = zeros(3,1);
SumError_yz = 0;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % ж•ҷеёҲеҗ‘йҮҸ
delta_J = 0.001;
time = 1;
while time < 1000 % detJ > delta_J
time = time + 1; % и®Ўз®—иҝӯд»Јж¬Ўж•°
J(time) = 0;
for num = 1:20
x = w(num, :); % д»»еҸ–w1дёӯдёҖдёӘжЁЎејҸ
t = T(num);
[delta_Wxy, delta_Wyz, Error_xy, Error_yz, Jt] = BatchTrain(x, t, Wxy, Wyz, Wyb, Wzb);
SumDelta_Wxy = SumDelta_Wxy + delta_Wxy;
SumDelta_Wyz = SumDelta_Wyz + delta_Wyz";
SumError_xy = SumError_xy + Error_xy;
SumError_yz = SumError_yz + Error_yz;
J(time) = J(time) + Jt;
end
% жӣҙж–°жқғеҖј
Wxy = Wxy + SumDelta_Wxy;
Wyz = Wyz + SumDelta_Wyz;
Wyb = Wyb + Eta * SumError_xy;
Wzb = Wzb + Eta * SumError_yz;
detJ = abs(J(time) - J(time - 1)); % еүҚеҗҺдёӨж¬Ўзӣ®ж ҮеҮҪж•°зҡ„е·®еҖј
end
Jt = J(1, 2:time); % J(1)е’ҢJ(2)еӯҳеӮЁдәҶзӣёеҗҢзҡ„еҖјпјҢд»ҺJ(2)з®—иө·пјҢиҝӯд»ЈдәҶ(time - 1)ж¬Ў
figure,plot(Jt);grid on;
xlabel(["жқғеҖјдёәеӣәе®ҡж—¶пјҢиҝӯд»Јж¬Ўж•°дёәпјҡ",num2str(time - 1),"ж¬Ў"]);
for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
d(i) = z;
end
d
дёҖдёӘзӣ®ж ҮеҮҪж•°з»ҸеӨҡж¬Ўи®ӯз»ғеҗҺзҡ„еҸҳеҢ–жӣІзәҝпјҡ
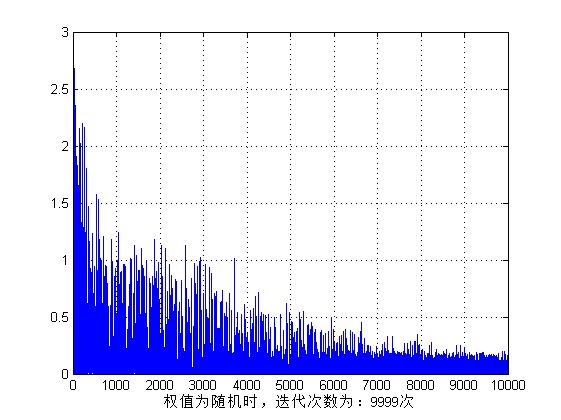
дёүгҖҒи°ғз”ЁMATLABе®һзҺ°BPзҪ‘з»ң
е…¶е®һMATLABдёӯеҸҜзӣҙжҺҘи°ғз”ЁеҮҪж•°жқҘжһ„йҖ зҘһз»ҸзҪ‘з»ңпјҢдҪҶиҮӘе·ұзј–еҶҷзЁӢеәҸе®һзҺ°жңүеҠ©дәҺдәҶи§Јж•ҙдёӘзҘһз»ҸзҪ‘з»ңзҡ„еҗ„дёӘз»ҶиҠӮгҖӮ дҪҝз”ЁMatlabе»әз«ӢеүҚйҰҲзҘһз»ҸзҪ‘з»ңж—¶еҸҜд»ҘдҪҝз”ЁеҲ°дёӢйқў3дёӘеҮҪж•°пјҡ
newff пјҡеүҚйҰҲзҪ‘з»ңеҲӣе»әеҮҪж•°
trainпјҡи®ӯз»ғдёҖдёӘзҘһз»ҸзҪ‘з»ң
simпјҡдҪҝз”ЁзҪ‘з»ңиҝӣиЎҢд»ҝзңҹ
е…ідәҺиҝҷ3дёӘеҮҪж•°зҡ„з”Ёжі•еҰӮдёӢпјҡ
1.newffеҮҪж•°
(1)newffеҮҪж•°зҡ„и°ғз”Ёж–№жі•
newffеҮҪж•°еҸӮж•°еҲ—иЎЁжңүеҫҲеӨҡзҡ„еҸҜйҖүеҸӮж•°пјҢе…·дҪ“еҸҜд»ҘеҸӮиҖғMatlabзҡ„её®еҠ©ж–ҮжЎЈпјҢиҝҷйҮҢд»Ӣз»ҚnewffеҮҪж•°зҡ„дёҖз§Қз®ҖеҚ•зҡ„еҪўејҸгҖӮ
net = newff(A,... % дёҖдёӘn*2зҡ„зҹ©йҳөпјҢ第iиЎҢе…ғзҙ дёәиҫ“е…ҘдҝЎеҸ·xiзҡ„жңҖе°ҸеҖје’ҢжңҖеӨ§еҖј
B,... % дёҖдёӘkз»ҙиЎҢеҗ‘йҮҸпјҢе…¶е…ғзҙ дёәзҪ‘з»ңдёӯеҗ„еұӮиҠӮзӮ№ж•°
{C},... % дёҖдёӘkз»ҙеӯ—з¬ҰдёІиЎҢеҗ‘йҮҸпјҢжҜҸдёҖеҲҶйҮҸдёәеҜ№еә”еұӮзҘһз»Ҹе…ғзҡ„жҝҖжҙ»еҮҪж•°
"trainFun"); % йҖүз”Ёзҡ„и®ӯз»ғз®—жі•
(2)еёёз”Ёзҡ„жҝҖжҙ»еҮҪж•°
еёёз”Ёзҡ„жҝҖжҙ»еҮҪж•°жңүпјҡ
гҖҖгҖҖa) зәҝжҖ§еҮҪж•° (Linear transfer function)пјҡf(x) = xгҖӮиҜҘеҮҪж•°жүҖеҜ№еә”зҡ„еӯ—з¬ҰдёІдёәвҖҷpurelinвҖҷгҖӮ
гҖҖгҖҖb) еҜ№ж•°SеҪўиҪ¬з§»еҮҪж•°( Logarithmic sigmoid transfer function )гҖӮиҜҘеҮҪж•°жүҖеҜ№еә”зҡ„еӯ—з¬ҰдёІдёәвҖҷlogsigвҖҷгҖӮ
гҖҖгҖҖc) еҸҢжӣІжӯЈеҲҮSеҪўеҮҪж•° (Hyperbolic tangent sigmoid transfer function )пјҢд№ҹе°ұжҳҜдёҠйқўжүҖжҸҗеҲ°зҡ„SigmoidеҮҪж•°гҖӮиҜҘеҮҪж•°жүҖеҜ№еә”зҡ„еӯ—з¬ҰдёІдёәвҖҷtansigвҖҷгҖӮ
жіЁпјҡMatlabзҡ„е®үиЈ…зӣ®еҪ•дёӢзҡ„toolbox net net ntransferеӯҗзӣ®еҪ•дёӯжңүжүҖжңүжҝҖжҙ»еҮҪж•°зҡ„е®ҡд№үиҜҙжҳҺгҖӮ
(3)еёёи§Ғзҡ„и®ӯз»ғеҮҪж•°
traingdпјҡжўҜеәҰдёӢйҷҚBPи®ӯз»ғеҮҪж•°(Gradient descent backpropagation)
traingdxпјҡжўҜеәҰдёӢйҷҚиҮӘйҖӮеә”еӯҰд№ зҺҮи®ӯз»ғеҮҪж•°
(4)дёҖдәӣйҮҚиҰҒзҡ„зҪ‘з»ңй…ҚзҪ®еҸӮж•°и®ҫзҪ®
net.trainparam.goalпјҡзҘһз»ҸзҪ‘з»ңи®ӯз»ғзҡ„зӣ®ж ҮиҜҜе·®
net.trainparam.showпјҡ жҳҫзӨәдёӯй—ҙз»“жһңзҡ„е‘Ёжңҹ
net.trainparam.epochsпјҡжңҖеӨ§иҝӯд»Јж¬Ўж•°
net.trainParam.lrпјҡ еӯҰд№ зҺҮ
2.зҘһз»ҸзҪ‘з»ңи®ӯз»ғеҮҪж•°train
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% зҘһз»ҸзҪ‘з»ңи®ӯз»ғеҮҪж•°train
% еҗ„еҸӮж•°зҡ„еҗ«д№үеҰӮдёӢпјҡ
% XпјҡзҪ‘з»ңе®һйҷ…иҫ“е…Ҙ
% YпјҡзҪ‘з»ңеә”жңүиҫ“еҮә
% trпјҡи®ӯз»ғи·ҹиёӘдҝЎжҒҜ
% Y1пјҡзҪ‘з»ңе®һйҷ…иҫ“еҮә
% EпјҡиҜҜе·®зҹ©йҳө
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
[ net, tr, Y1, E ] = train(net, X, Y )
3.simеҮҪж•°
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% еҗ„еҸӮж•°зҡ„еҗ«д№үеҰӮдёӢпјҡ
% netпјҡзҪ‘з»ң
% Xпјҡиҫ“е…Ҙз»ҷзҪ‘з»ңзҡ„K*Nзҹ©йҳөпјҢе…¶дёӯKдёәзҪ‘з»ңиҫ“е…ҘдёӘж•°пјҢNдёәж•°жҚ®ж ·жң¬ж•°
% Yпјҡиҫ“еҮәзҹ©йҳөQ*NпјҢе…¶дёӯQдёәзҘһз»ҸзҪ‘з»ңиҫ“еҮәеҚ•е…ғзҡ„дёӘж•°
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Y = sim(net, X)
еҹәдәҺMATLABиҮӘеёҰеҮҪж•°зҡ„BPзҘһз»ҸзҪ‘з»ңи®ҫи®Ўе®һдҫӢ
дёҖдёӘе®һдҫӢеҸӮиҖғпјҡhttp://blog.csdn.net/gongxq0124/article/details/7681000
еҸӮиҖғй“ҫжҺҘпјҡhttp://www.cnblogs.com/heaad/archive/2011/03/07/1976443.html