

жң¬е®һйӘҢзҡ„зӣ®зҡ„жҳҜеӯҰд№ е’ҢжҺҢжҸЎk-еқҮеҖјиҒҡзұ»з®—жі•гҖӮk-еқҮеҖјз®—жі•жҳҜдёҖз§Қз»Ҹе…ёзҡ„ж— зӣ‘зқЈиҒҡзұ»е’ҢеӯҰд№ з®—жі•пјҢе®ғеұһдәҺиҝӯд»ЈдјҳеҢ–з®—жі•зҡ„иҢғз•ҙгҖӮжң¬е®һйӘҢеңЁMATLABе№іеҸ°дёҠпјҢзј–зЁӢе®һзҺ°дәҶk-еқҮеҖјиҒҡзұ»з®—жі•пјҢ并дҪҝз”Ё20з»„дёүз»ҙж•°жҚ®иҝӣиЎҢжөӢиҜ•пјҢжҜ”иҫғеҲҶзұ»з»“жһңгҖӮе®һйӘҢдёӯеҲқе§ӢиҒҡзұ»дёӯеҝғз”ұдәәдёәи®ҫе®ҡпјҢд»ҘдҫҝдәҺе®һйӘҢз»“жһңзҡ„жҜ”иҫғдёҺеҲҶжһҗгҖӮ
дёҖгҖҒжҠҖжңҜи®әиҝ°
1.ж— зӣ‘зқЈеӯҰд№ е’ҢиҒҡзұ»
еңЁд№ӢеүҚи®ҫи®ЎеҲҶзұ»еҷЁзҡ„ж—¶еҖҷпјҢйҖҡеёёйңҖиҰҒдәӢе…ҲеҜ№и®ӯз»ғж ·жң¬йӣҶзҡ„ж ·жң¬иҝӣиЎҢж Үе®ҡд»ҘзЎ®е®ҡзұ»еҲ«еҪ’еұһгҖӮиҝҷз§ҚеҲ©з”Ёжңүж Үи®°ж ·жң¬йӣҶзҡ„ж–№жі•з§°дёәвҖңжңүзӣ‘зқЈвҖқжҲ–вҖңжңүж•ҷеёҲвҖқж–№жі•гҖӮиҝҷдёҖзұ»ж–№жі•зҡ„дҪҝз”Ёеӣә然еҚҒеҲҶе№ҝжіӣпјҢд№ҹжңүзқҖеҫҲеқҡе®һзҡ„зҗҶи®әеҹәзЎҖпјҢдҪҶеңЁе®һйҷ…иҝҗз”Ёдёӯиҝҷзұ»ж–№жі•з»ҸеёёдјҡйҒҮеҲ°д»ҘдёӢ瓶йўҲпјҡ
- 收йӣҶ并ж Үи®°еӨ§йҮҸж ·жң¬йӣҶжҳҜдёҖ件зӣёеҪ“иҙ№ж—¶иҙ№еҠӣзҡ„еүҚжңҹе·ҘдҪңпјӣ
- зҺ°е®һдёӯеӯҳеңЁеҫҲеӨҡеә”з”ЁпјҢе…¶еҲҶзұ»жЁЎејҸзҡ„жҖ§иҙЁдјҡйҡҸзқҖж—¶й—ҙеҸ‘з”ҹеҸҳеҢ–пјҢеҚ•еҚ•дҪҝз”Ёе·Іж Үи®°ж ·жң¬ж— жі•ж»Ўи¶іиҝҷзұ»жғ…еҶөпјӣ
- жңүдәәеёҢжңӣиғҪйҖҶеҗ‘и§ЈеҶій—®йўҳпјҡе…Ҳз”ЁеӨ§йҮҸжңӘж Үи®°зҡ„ж ·жң¬йӣҶжқҘиҮӘеҠЁең°и®ӯз»ғеҲҶзұ»еҷЁпјҢеҶҚдәәе·Ҙең°ж Үи®°ж•°жҚ®еҲҶз»„зҡ„з»“жһңпјҢеҰӮж•°жҚ®жҢ–жҺҳзҡ„еӨ§еһӢеә”з”ЁпјҢеӣ дёәиҝҷдәӣеә”з”ЁеҫҖеҫҖдёҚзҹҘйҒ“еҫ…еӨ„зҗҶж•°жҚ®зҡ„е…·дҪ“жғ…еҶөгҖӮ
еҸҜд»ҘзңӢеҲ°пјҢж— зӣ‘зқЈеӯҰд№ ж–№жі•зҡ„жҸҗеҮәжҳҜеҚҒеҲҶеҝ…иҰҒзҡ„гҖӮдәӢе®һдёҠпјҢеңЁд»»дҪ•дёҖйЎ№жҺўзҙўжҖ§зҡ„е·ҘдҪңдёӯпјҢж— зӣ‘зқЈзҡ„ж–№жі•еқҮеҗ‘жҲ‘们жҸӯзӨәдәҶи§ӮжөӢж•°жҚ®зҡ„дёҖдәӣжҷ®йҒҚ规еҫӢгҖӮеҫҲеӨҡж— зӣ‘зқЈж–№жі•йғҪеҸҜд»Ҙд»ҘзӢ¬з«ӢдәҺж•°жҚ®зҡ„ж–№ејҸе·ҘдҪңпјҢдёәеҗҺз»ӯжӯҘйӘӨжҸҗдҫӣвҖңзҒөе·§зҡ„йў„еӨ„зҗҶвҖқе’ҢвҖңзҒөе·§зҡ„зү№еҫҒжҸҗеҸ–вҖқзӯүжңүж•Ҳзҡ„еүҚжңҹеӨ„зҗҶгҖӮеңЁж— зӣ‘зқЈзҡ„жғ…еҶөдёӢпјҢиҒҡзұ»з®—жі•жҳҜжЁЎејҸиҜҶеҲ«з ”究дёӯи‘—еҗҚзҡ„дёҖзұ»жҠҖжңҜгҖӮ
2.еҲҶзұ»дёҺиҒҡзұ»зҡ„е·®еҲ«
еҲҶзұ»(Classification)пјҡеҜ№дәҺдёҖдёӘеҲҶзұ»еҷЁпјҢйҖҡеёёйңҖиҰҒдҪ е‘ҠиҜүе®ғвҖңиҝҷдёӘдёңиҘҝиў«еҲҶдёәжҹҗжҹҗзұ»вҖқиҝҷж ·дёҖдәӣдҫӢеӯҗгҖӮйҖҡеёёжғ…еҶөдёӢпјҢдёҖдёӘеҲҶзұ»еҷЁдјҡд»Һе®ғеҫ—еҲ°зҡ„и®ӯз»ғж•°жҚ®дёӯиҝӣиЎҢеӯҰд№ пјҢд»ҺиҖҢе…·еӨҮеҜ№жңӘзҹҘж•°жҚ®иҝӣиЎҢеҲҶзұ»зҡ„иғҪеҠӣпјҢиҝҷз§ҚжҸҗдҫӣи®ӯз»ғж•°жҚ®зҡ„иҝҮзЁӢйҖҡеёёеҸ«еҒҡжңүзӣ‘зқЈеӯҰд№ гҖӮ
иҒҡзұ»(Clustering)пјҡз®ҖеҚ•ең°иҜҙе°ұжҳҜжҠҠзӣёдјјзҡ„дёңиҘҝеҲҶеҲ°дёҖз»„гҖӮиҒҡзұ»зҡ„ж—¶еҖҷпјҢжҲ‘们并дёҚе…іеҝғжҹҗдёҖзұ»жҳҜд»Җд№ҲпјҢиҝҷйҮҢйңҖиҰҒе®һзҺ°зҡ„зӣ®ж ҮеҸӘжҳҜжҠҠзӣёдјјзҡ„дёңиҘҝиҒҡеҲ°дёҖиө·гҖӮеӣ жӯӨпјҢдёҖдёӘиҒҡзұ»з®—жі•йҖҡеёёеҸӘйңҖиҰҒзҹҘйҒ“еҰӮдҪ•и®Ўз®—зӣёдјјеәҰе°ұеҸҜд»ҘејҖе§Ӣе·ҘдҪңдәҶгҖӮеӣ жӯӨпјҢиҒҡзұ»ж–№жі•йҖҡ常并дёҚйңҖиҰҒдҪҝз”Ёи®ӯз»ғж•°жҚ®иҝӣиЎҢеӯҰд№ пјҢеӣ жӯӨжЎ”зұ»ж–№жі•еұһдәҺж— зӣ‘зқЈеӯҰд№ зҡ„иҢғз•ҙгҖӮ
3.еёёи§Ғзҡ„еҲҶзұ»дёҺиҒҡзұ»з®—жі•
жүҖи°“еҲҶзұ»пјҢе°ұжҳҜж №жҚ®ж•°жҚ®ж ·жң¬зҡ„зү№еҫҒжҲ–еұһжҖ§пјҢеҲ’еҲҶеҲ°е·Іжңүзҡ„зұ»еҲ«дёӯгҖӮеүҚйқўдҪҝз”ЁеҲ°зҡ„жЁЎејҸеҲҶзұ»ж–№жі•дё»иҰҒжңүпјҡиҙқеҸ¶ж–ҜеҲҶзұ»з®—жі•(Bayesian classifier) гҖҒPCAдё»еҲҶйҮҸеҲҶжһҗжі•гҖҒFisherзәҝжҖ§еҲӨеҲ«еҲҶжһҗжі•гҖҒParzenзӘ—дј°и®Ўжі•гҖҒk-жңҖиҝ‘йӮ»жі•(k-nearest neighborпјҢkNN)гҖҒеҹәдәҺж”ҜжҢҒеҗ‘йҮҸжңә(SVM)зҡ„еҲҶзұ»еҷЁгҖҒдәәе·ҘзҘһз»ҸзҪ‘з»ң(ANN)е’ҢеҶізӯ–ж ‘еҲҶзұ»жі•зӯүзӯүгҖӮ
еҲҶзұ»дҪңдёәдёҖз§Қжңүзӣ‘зқЈеӯҰд№ ж–№жі•пјҢиҰҒжұӮеҝ…йЎ»еңЁеҲҶзұ»д№ӢеүҚжҳҺзЎ®зҹҘйҒ“еҗ„дёӘзұ»еҲ«зҡ„еҝ…иҰҒзү№еҫҒе’ҢдҝЎжҒҜпјҢ并且ж Үи®°жүҖжңүи®ӯз»ғж ·жң¬йғҪжңүдёҖдёӘзұ»еҲ«дёҺд№ӢзӣёеҜ№еә”гҖӮдҪҶжҳҜеҫҲеӨҡжғ…еҶөдёӢиҝҷдәӣжқЎд»¶еҫҖеҫҖж— жі•ж»Ўи¶іпјҢе°Өе…¶жҳҜеңЁеӨ„зҗҶжө·йҮҸж•°жҚ®зҡ„ж—¶еҖҷпјҢж•°жҚ®йў„еӨ„зҗҶзҡ„д»Јд»·йқһеёёеӨ§гҖӮ
иҒҡзұ»з®—жі•дёӯжңҖз»Ҹе…ёзҡ„еҪ“еұһkеқҮеҖјиҒҡзұ»(K-means clustering)з®—жі•гҖӮиҜҘз®—жі•еҸҲз§°дёәвҖңcеқҮеҖјз®—жі•вҖқпјҢеӣ дёәе®ғзҡ„зӣ®ж Үе°ұжҳҜжүҫеҲ°cдёӘеқҮеҖјеҗ‘йҮҸдҪңдёәиҒҡзұ»дёӯеҝғпјҡОј1,Ој2,вҖҰ,ОјcпјҢе®һйҷ…дёҠkдёҺcжҳҜзӯүд»·зҡ„гҖӮ
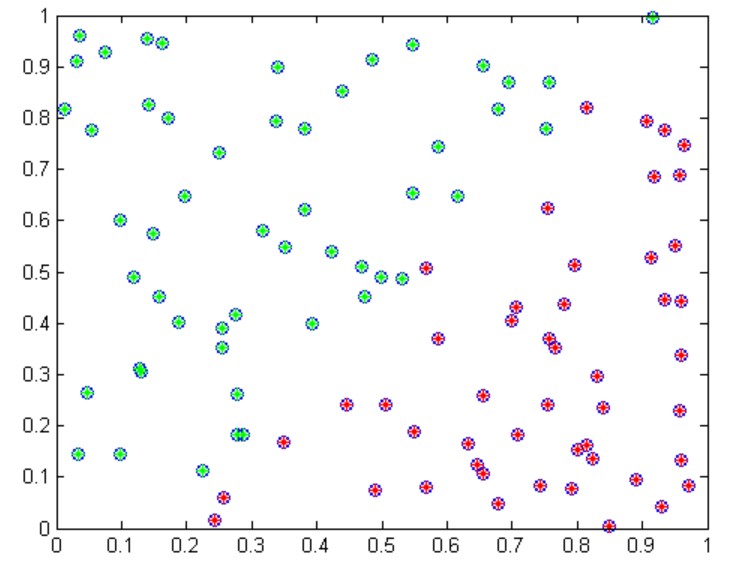
д»ҘдёҠжҳҜеҜ№дәҢз»ҙйҡҸжңәж ·жң¬иҝӣиЎҢиҒҡзұ»зҡ„е®һдҫӢгҖӮ
4.иҒҡзұ»д»»еҠЎзҡ„еҹәжң¬жӯҘйӘӨ
еҒҮи®ҫжүҖжңүжЁЎејҸйғҪз”ЁдёҖз»„зү№еҫҒиЎЁзӨәпјҢжЁЎејҸиў«иЎЁзӨәдёәLз»ҙзҡ„зү№еҫҒзҹўйҮҸгҖӮиҒҡзұ»д»»еҠЎйңҖеҢ…еҗ«д»ҘдёӢжӯҘйӘӨпјҡ
- зү№еҫҒйҖүжӢ©гҖӮйҖүжӢ©зү№еҫҒе°ҪеҸҜиғҪдёҺж„ҹе…ҙи¶Јзҡ„д»»еҠЎзӣёе…ігҖӮзү№еҫҒд№Ӣй—ҙзҡ„дҝЎжҒҜеҶ—дҪҷеәҰиҰҒе°ҪеҸҜиғҪе°ҸгҖӮ
- зӣёдјјжҖ§жөӢеәҰгҖӮдёҖдёӘеҹәжң¬зҡ„дҝқиҜҒжҳҜжүҖжңүйҖүжӢ©зҡ„зү№еҫҒеҜ№зӣёдјјжҖ§жөӢеәҰи®Ўз®—зҡ„иҙЎзҢ®йғҪжҳҜеқҮиЎЎзҡ„пјҢжІЎжңүйӮЈдёҖдёӘзү№еҫҒжҳҜз»қеҜ№еҚ дјҳзҡ„гҖӮ
- иҒҡзұ»еҮҶеҲҷгҖӮиҒҡзұ»еҮҶеҲҷдҫқиө–дәҺ专家еҲӨж–ӯзҡ„еңЁж•°жҚ®йӣҶеҗҲеҶ…йғЁйҡҗеҗ«зұ»зҡ„зұ»еһӢи§ЈйҮҠгҖӮиҒҡзұ»еҮҶеҲҷеҸҜд»Ҙиў«иЎЁзӨәдёәд»Јд»·еҮҪж•°е’Ңе…¶е®ғзұ»еһӢзҡ„规еҲҷгҖӮ
- иҒҡзұ»з®—жі•гҖӮеңЁзЎ®е®ҡзӣёдјјжҖ§жөӢеәҰе’ҢиҒҡзұ»еҮҶеҲҷеҗҺпјҢиҝҷдёҖжӯҘе°ұжҳҜиҰҒйҖүжӢ©дёҖдёӘе…·дҪ“зҡ„з®—жі•ж–№жЎҲе°Ҷж•°жҚ®йӣҶеҗҲеҲҶи§Јдёәзұ»з»“жһ„гҖӮ
- з»“жһ„зҡ„жңүж•ҲжҖ§гҖӮдёҖж—ҰиҒҡзұ»з®—жі•иҺ·еҫ—дәҶз»“жһңпјҢйңҖиҰҒйҮҮз”ЁеҗҲйҖӮзҡ„жЈҖйӘҢж–№жі•жЈҖйӘҢе…¶жӯЈзЎ®жҖ§гҖӮ
- з»“жһңзҡ„и§ЈйҮҠгҖӮеә”з”ЁйўҶеҹҹзҡ„专家еҝ…йЎ»з»“еҗҲе…¶е®ғзҡ„иҜ•йӘҢиҜҒжҚ®е’ҢеҲҶжһҗи§ЈйҮҠиҒҡзұ»з»“жһңпјҢд»Ҙдҫҝеҫ—еҲ°жӯЈзЎ®зҡ„з»“и®әгҖӮ
5.k-еқҮеҖјиҒҡзұ»з®—жі•
k-еқҮеҖјиҒҡзұ»з®—жі•зҡ„зӣ®ж ҮжҳҜжүҫеҲ°kдёӘеқҮеҖјеҗ‘йҮҸжҲ–вҖңиҒҡзұ»дёӯеҝғвҖқгҖӮз®—жі•зҡ„е®һзҺ°жӯҘйӘӨеҰӮдёӢжүҖзӨәпјҢе…¶дёӯnиЎЁзӨәжЁЎејҸзҡ„ж•°йҮҸпјҢcиЎЁзӨәзұ»еҲ«зҡ„ж•°йҮҸпјҢйҖҡеёёзҡ„еҒҡжі•жҳҜд»Һж ·жң¬дёӯйҡҸжңәеҸ–еҮәcдёӘдҪңдёәеҲқе§Ӣзҡ„иҒҡзұ»дёӯеҝғгҖӮеҪ“然пјҢеҲқе§Ӣзҡ„иҒҡзұ»дёӯеҝғд№ҹеҸҜд»ҘйҖҡиҝҮдәәдёәжқҘзЎ®е®ҡпјҡ

иҜҘз®—жі•зҡ„и®Ўз®—еӨҚжқӮеәҰдёәпјҡ
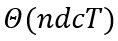
е…¶дёӯdд»ЈиЎЁж ·жң¬зҡ„з»ҙж•°пјҢTжҳҜиҒҡзұ»зҡ„иҝӯд»Јж¬Ўж•°пјҢдёҖиҲ¬жқҘиҜҙпјҢиҝӯд»Јж¬Ўж•°йҖҡеёёиҝңе°‘дәҺж ·жң¬зҡ„ж•°йҮҸгҖӮ
иҜҘз®—жі•жҳҜдёҖз§Қе…ёеһӢзҡ„иҒҡзұ»з®—жі•пјҢжҠҠе®ғеҪ’е…Ҙиҝӯд»ЈдјҳеҢ–з®—жі•зҡ„иҢғз•ҙжҳҜеӣ дёә算法规е®ҡзҡ„cдёӘеқҮеҖјдјҡдёҚж–ӯең°з§»еҠЁпјҢдҪҝеҫ—дёҖдёӘе№іж–№иҜҜе·®еҮҶеҲҷеҮҪж•°жңҖе°ҸеҢ–гҖӮеңЁз®—жі•зҡ„жҜҸдёҖжӯҘиҝӯд»ЈдёӯпјҢжҜҸдёӘж ·жң¬зӮ№еқҮиў«и®ӨдёәжҳҜе®Ңе…ЁеұһдәҺжҹҗдёҖзұ»еҲ«гҖӮ
дәҢгҖҒе®һйӘҢз»“жһңи®Ёи®ә
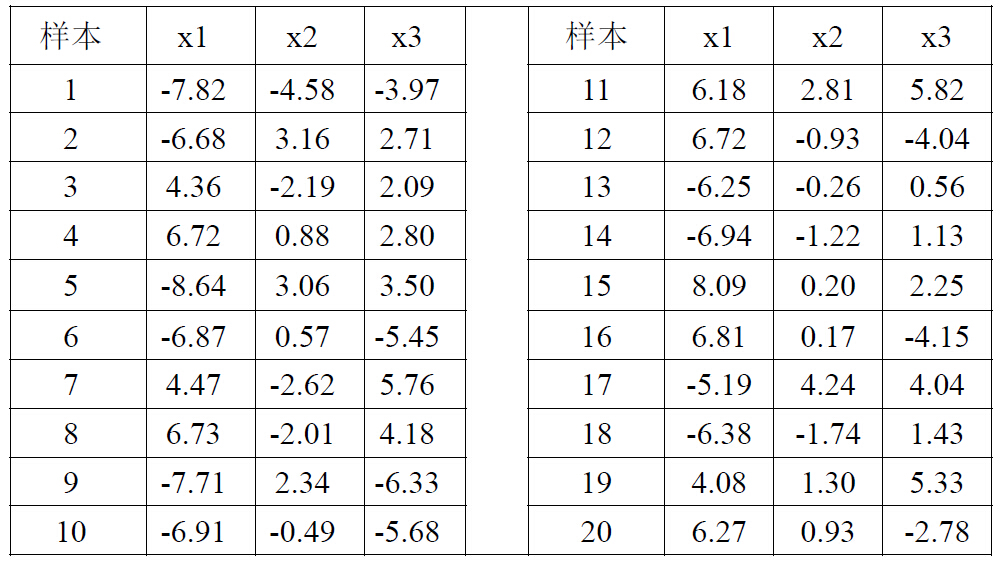
е®һйӘҢжүҖдҪҝз”Ёзҡ„ж ·жң¬пјҡ
и®ҫи®ЎжӯҘйӘӨдё»иҰҒеҢ…жӢ¬д»ҘдёӢеҮ дёӘйғЁеҲҶпјҡ
зј–еҶҷзЁӢеәҸпјҢе®һзҺ°д»ҘдёҠжүҖиҝ°зҡ„k-еқҮеҖјиҒҡзұ»з®—жі•гҖӮе…¶дёӯпјҢеңЁз®—жі•дёӯж ·жң¬дёҺиҒҡзұ»дёӯеҝғзҡ„и·қзҰ»йҮҮ用欧ж°Ҹи·қзҰ»зҡ„еҪўејҸгҖӮ
зұ»еҲ«ж•°зӣ®е’ҢиҒҡзұ»дёӯеҝғеҲқе§ӢеҖјйҖүдёәд»ҘдёӢеҸӮж•°иҝӣиЎҢе®һйӘҢпјҡ
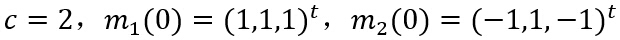
еҶҚе°Ҷзұ»еҲ«ж•°зӣ®е’ҢиҒҡзұ»дёӯеҝғеҲқе§ӢеҖјж”№еҸҳдёәд»ҘдёӢеҸӮж•°иҝӣиЎҢе®һйӘҢгҖӮ
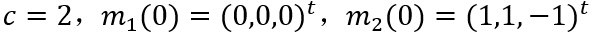
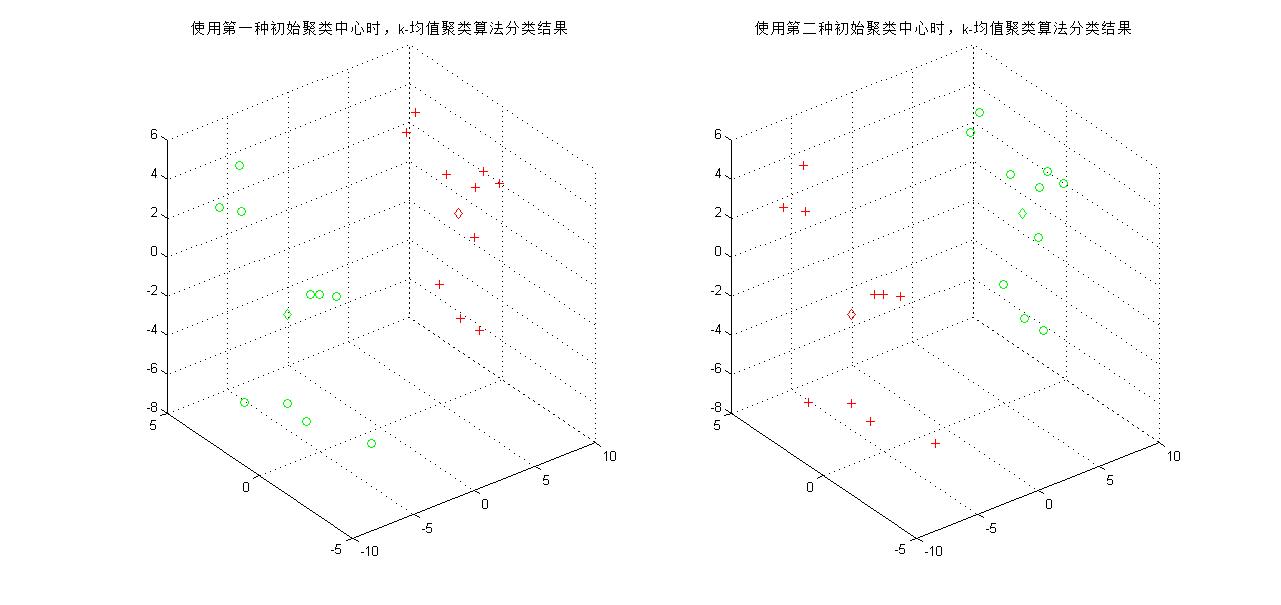
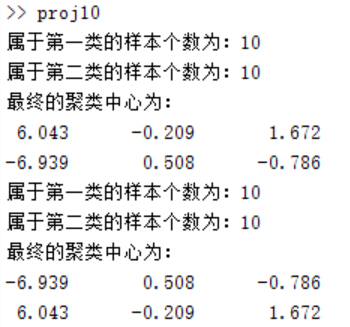
дёӢеӣҫеҫ—еҲ°дёӨж¬ЎиҒҡзұ»зҡ„з»“жһңпјҢеҸҜд»ҘзңӢеҲ°еҪ“еҲҶзұ»зұ»еҲ«дёә2ж—¶пјҢеҲқе§ӢиҒҡзұ»дёӯеҝғеҜ№еҲҶзұ»з»“жһңеҪұе“ҚдёҚеӨ§пјҲиҮіе°‘еҜ№дәҺж ·жң¬е°‘зҡ„жғ…еҶөжҳҜиҝҷж ·зҡ„пјүпјҢжңҖз»ҲдёӨз§Қжғ…еҶөйғҪиғҪеҫ—еҲ°дёҖж ·зҡ„жңҖз»ҲиҒҡзұ»дёӯеҝғгҖӮ
дёӢйқўжөӢиҜ•е°Ҷж ·жң¬еҲҶдёәдёүзұ»зҡ„жғ…еҶөгҖӮе°Ҷзұ»еҲ«ж•°зӣ®е’ҢиҒҡзұ»дёӯеҝғеҲқе§ӢеҖјйҖүдёәд»ҘдёӢеҸӮж•°иҝӣиЎҢе®һйӘҢпјҡ
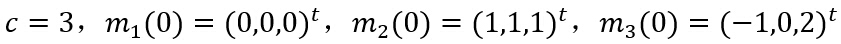
еҶҚе°Ҷзұ»еҲ«ж•°зӣ®е’ҢиҒҡзұ»дёӯеҝғеҲқе§ӢеҖјж”№еҸҳдёәд»ҘдёӢеҸӮж•°иҝӣиЎҢе®һйӘҢпјҡ
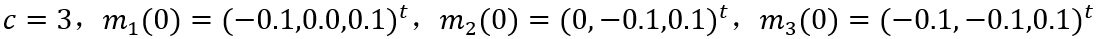
дёӢеӣҫеҫ—еҲ°дёӨж¬ЎиҒҡзұ»зҡ„з»“жһңпјҢеҸҜд»ҘзңӢеҲ°еҪ“еҲҶзұ»зұ»еҲ«дёә3ж—¶пјҢеҲҶзұ»еӨҚжқӮеәҰеўһеҠ пјҢйҡҸзқҖиҒҡзұ»дёӯеҝғзҡ„移еҠЁпјҢеҜ№дәҺеҗҢдёҖз»„жөӢиҜ•ж ·жң¬еҸҜиғҪжңүдёҚеҗҢзҡ„еҲ’еҲҶз»“жһңгҖӮиҷҪ然еҲқе§ӢиҒҡзұ»дёӯеҝғзҡ„дҪңз”ЁеҸӘжҳҜе°Ҷж ·жң¬еҲқжӯҘең°еҲҶдёәеҮ дёӘеҢәеҹҹпјҢдҪҶдәӢе®һдёҠдёҚеҗҢзҡ„еҲқе§Ӣдёӯеҝғдјҡз»ҷеҲҶзұ»з»“жһңеёҰжқҘе·ЁеӨ§зҡ„е·®ејӮгҖӮ
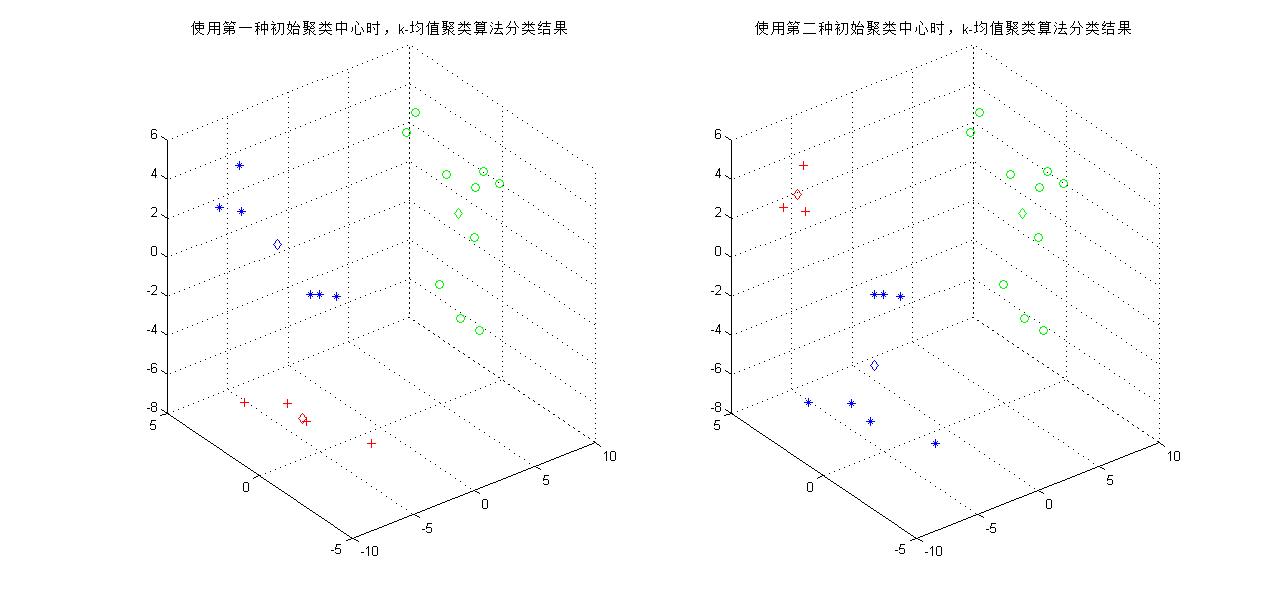
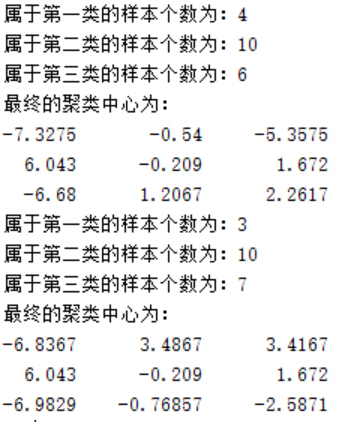
еңЁзЁӢеәҸдёӯпјҢдҪҝ用欧ж°Ҹи·қзҰ»дҪңдёәж ·жң¬еҲ°иҒҡзұ»дёӯеҝғзҡ„и·қзҰ»пјҢдәӢе®һдёҠд№ҹеҸҜд»ҘдҪҝз”Ёе…¶д»–еӨҡз§Қи·қзҰ»еәҰйҮҸиҝӣиЎҢиҝҗз®—пјҢеҰӮиЎ—еҢәи·қзҰ»пјҲ1иҢғж•°пјүгҖҒжЈӢзӣҳи·қзҰ»пјҲвҲһиҢғж•°пјүзӯүзӯүгҖӮ
дёүгҖҒе®Ңж•ҙд»Јз Ғ
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% k-еқҮеҖјиҒҡзұ»еҮҪж•°
% иҫ“е…ҘеҸӮж•°пјҡ
% wпјҡйңҖиҰҒеҲҶзұ»зҡ„ж ·жң¬
% kпјҡеҲҶзұ»ж•°
% mпјҡеҲқе§ӢиҒҡзұ»дёӯеҝғ
% iterationпјҡиҝӯд»Јж¬Ўж•°
% дёӯй—ҙеҸӮж•°пјҡ
% class_idпјҡеӯҳж”ҫеҗ„дёӘж ·жң¬еұһдәҺдёҖзұ»зҡ„дёӢж Ү
% distпјҡи®Ўз®—ж ·жң¬еҲ°иҒҡзұ»дёӯеҝғзҡ„и·қзҰ»
% иҫ“еҮәеҸӮж•°пјҡ
% class_resultпјҡеӯҳж”ҫж ·жң¬зҡ„еҲҶзұ»з»“жһң
% class_numпјҡеӯҳж”ҫиў«еҲҶеҲ°еҗ„зұ»зҡ„ж ·жң¬дёӘж•°
% centerпјҡиҝӯд»Јз»“жқҹж—¶зҡ„иҒҡзұ»дёӯеҝғ
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function [class_result, class_num, center] = kmeans(w, k, m, iteration)
[n,d] = size(w);
class_result = zeros(1,n);
class_num = zeros(1,k);
time = 1;
% д»ҘдёӢжӯҘйӘӨи®Ўз®—жҜҸдёӘж ·жң¬еҲ°иҒҡзұ»дёӯеҝғзҡ„и·қзҰ»
while time < iteration % иҝӯд»Јж¬Ўж•°йҷҗеҲ¶
for i = 1:n
dist = sqrt(sum((repmat(w(i,:), k, 1) - m).^2, 2)); % 欧ж°Ҹи·қзҰ»
% dist = sum(abs(repmat(x(i,:), k, 1) - nc), 2); % иЎ—еҢәи·қзҰ»
[y,class_id] = min(dist); % и®Ўз®—ж ·жң¬еҜ№дёүзұ»дёӯе“ӘдёҖзұ»жңүжңҖе°Ҹи·қзҰ»е№¶еӯҳж”ҫеңЁclass_id
class_result(i) = class_id;
end
for i = 1:k
% жүҫеҲ°жҜҸдёҖзұ»зҡ„жүҖжңүж•°жҚ®пјҢи®Ўз®—е№іеқҮеҖјпјҢе…¶еҖјдҪңдёәж–°зҡ„иҒҡзұ»дёӯеҝғ
class_id = find(class_result == i);
m(i, :) = mean(w(class_id, :)); % жӣҙж–°иҒҡзұ»дёӯеҝғ
% з»ҹи®ЎжҜҸдёҖзұ»ж ·жң¬зҡ„дёӘж•°
class_num(i) = length(class_id);
end
time = time + 1;
end
center = m;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% ж ·жң¬еҲҶзұ»з»“жһңзҡ„з»ҳеӣҫеҮҪж•°
% иҫ“е…ҘеҸӮж•°пјҡ
% wпјҡйңҖиҰҒеҲҶзұ»зҡ„ж ·жң¬
% classпјҡиҒҡзұ»еҗҺзҡ„ж ·жң¬еҲҶзұ»з»“жһң
% flagпјҡеҲҶзұ»зұ»еҲ«ж•°
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%function draw(w, class, center)
[flag x] = size(center);
[n, d] = size(w);
% figure;
if flag == 2 % иӢҘе°Ҷж ·жң¬еҲҶжҲҗдёӨзұ»
for i=1:n
if class(i) == 1
plot3(w(i,1),w(i,2),w(i,3),"r+"); % жҳҫзӨә第дёҖзұ»
hold on;
grid on;
elseif class(i) == 2
plot3(w(i,1),w(i,2),w(i,3),"go"); %жҳҫзӨә第дәҢзұ»
hold on;
grid on;
end
end
for j = 1:flag
if j == 1
plot3(center(j,1),center(j,2),center(j,3),"rd"); % иҒҡзұ»дёӯеҝғ
elseif j == 2
plot3(center(j,1),center(j,2),center(j,3),"gd"); % иҒҡзұ»дёӯеҝғ
end
end
end
if flag == 3 % иӢҘе°Ҷж ·жң¬еҲҶжҲҗдёүзұ»
% жҳҫзӨәеҲҶзұ»з»“жһң
for i = 1:n
if class(i) == 1
plot3(w(i,1),w(i,2),w(i,3),"r+"); % жҳҫзӨә第дёҖзұ»
hold on;
grid on;
elseif class(i) == 2
plot3(w(i,1),w(i,2),w(i,3),"go"); % жҳҫзӨә第дәҢзұ»
hold on;
grid on;
elseif class(i) == 3
plot3(w(i,1),w(i,2),w(i,3),"b*"); % жҳҫзӨә第дёүзұ»
hold on;
grid on;
end
end
for j = 1:flag
if j == 1
plot3(center(j,1),center(j,2),center(j,3),"rd"); % иҒҡзұ»дёӯеҝғ
elseif j == 2
plot3(center(j,1),center(j,2),center(j,3),"gd"); % иҒҡзұ»дёӯеҝғ
elseif j == 3
plot3(center(j,1),center(j,2),center(j,3),"bd"); % иҒҡзұ»дёӯеҝғ
end
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% k-еқҮеҖјиҒҡзұ»зҡ„з ”з©¶дёҺе®һзҺ°дё»еҮҪж•°
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
clear all;
close all;
% жөӢиҜ•ж ·жң¬
w = [-7.82 -4.58 -3.97;...
-6.68 3.16 2.71;...
4.36 -2.19 2.09;...
6.72 0.88 2.80;...
-8.64 3.06 3.50;...
-6.87 0.57 -5.45;...
4.47 -2.62 5.76;...
6.73 -2.01 4.18;...
-7.71 2.34 -6.33;...
-6.91 -0.49 -5.68;...
6.18 2.18 5.28;...
6.72 -0.93 -4.04;...
-6.25 -0.26 0.56;...
-6.94 -1.22 1.33;...
8.09 0.20 2.25;...
6.81 0.17 -4.15;...
-5.19 4.24 4.04;...
-6.38 -1.74 1.43;...
4.08 1.30 5.33;...
6.27 0.93 -2.78];
[n, d] = size(w);
% д»ҘдёӢжҳҜkеқҮеҖјиҒҡзұ»зҡ„еҸӮж•°и®ҫе®ҡпјҲc = 2ж—¶пјү
k = 2;
m = [1 1 1; -1 1 -1]; % еҲқе§ӢиҒҡзұ»дёӯеҝғ
% m = [0 0 0; 1 1 -1]; % еҲқе§ӢиҒҡзұ»дёӯеҝғ
iteration = 200; % kеқҮеҖјиҒҡзұ»зҡ„иҝӯд»Јж¬Ўж•°
% и°ғз”ЁkmeansеҮҪж•°иҝӣиЎҢиҒҡзұ»
[class, class_num, center] = kmeans(w, k, m, iteration);
% з”»еҮәж ·жң¬еҲҶзұ»з»“жһң
figure;subplot(121);draw(w, class, center);
title("дҪҝ用第дёҖз§ҚеҲқе§ӢиҒҡзұ»дёӯеҝғж—¶пјҢk-еқҮеҖјиҒҡзұ»з®—жі•еҲҶзұ»з»“жһң");
% жҳҫзӨәдҝЎжҒҜ
disp(["еұһдәҺ第дёҖзұ»зҡ„ж ·жң¬дёӘж•°дёәпјҡ",num2str(class_num(1))]);
disp(["еұһдәҺ第дәҢзұ»зҡ„ж ·жң¬дёӘж•°дёәпјҡ",num2str(class_num(2))]);
disp("жңҖз»Ҳзҡ„иҒҡзұ»дёӯеҝғдёәпјҡ");
disp(num2str(center));
% д»ҘдёӢжҳҜkеқҮеҖјиҒҡзұ»зҡ„еҸӮж•°и®ҫе®ҡпјҲc = 2ж—¶пјү
k = 2;
% m = [1 1 1; -1 1 -1]; % еҲқе§ӢиҒҡзұ»дёӯеҝғ
m = [0 0 0; 1 1 -1]; % еҲқе§ӢиҒҡзұ»дёӯеҝғ
iteration = 200; % kеқҮеҖјиҒҡзұ»зҡ„иҝӯд»Јж¬Ўж•°
% и°ғз”ЁkmeansеҮҪж•°иҝӣиЎҢиҒҡзұ»
[class, class_num, center] = kmeans(w, k, m, iteration);
% з”»еҮәж ·жң¬еҲҶзұ»з»“жһң
subplot(122);draw(w, class, center);
title("дҪҝ用第дәҢз§ҚеҲқе§ӢиҒҡзұ»дёӯеҝғж—¶пјҢk-еқҮеҖјиҒҡзұ»з®—жі•еҲҶзұ»з»“жһң");
% жҳҫзӨәдҝЎжҒҜ
disp(["еұһдәҺ第дёҖзұ»зҡ„ж ·жң¬дёӘж•°дёәпјҡ",num2str(class_num(1))]);
disp(["еұһдәҺ第дәҢзұ»зҡ„ж ·жң¬дёӘж•°дёәпјҡ",num2str(class_num(2))]);
disp("жңҖз»Ҳзҡ„иҒҡзұ»дёӯеҝғдёәпјҡ");
disp(num2str(center));
% д»ҘдёӢжҳҜkеқҮеҖјиҒҡзұ»зҡ„еҸӮж•°и®ҫе®ҡпјҲc = 3ж—¶пјү
k = 3;
m = [0 0 0; 1 1 1; -1 0 2]; % еҲқе§ӢиҒҡзұ»дёӯеҝғ
% m = [-0.1 0.0 0.1; 0 -0.1 0.1; -0.1 -0.1 0.1]; % еҲқе§ӢиҒҡзұ»дёӯеҝғ
iteration = 200; % kеқҮеҖјиҒҡзұ»зҡ„иҝӯд»Јж¬Ўж•°
% и°ғз”ЁkmeansеҮҪж•°иҝӣиЎҢиҒҡзұ»
[class, class_num, center] = kmeans(w, k, m, iteration);
% з”»еҮәж ·жң¬еҲҶзұ»з»“жһң
figure;subplot(121);draw(w, class, center);
title("дҪҝ用第дёҖз§ҚеҲқе§ӢиҒҡзұ»дёӯеҝғж—¶пјҢk-еқҮеҖјиҒҡзұ»з®—жі•еҲҶзұ»з»“жһң");
% жҳҫзӨәдҝЎжҒҜ
disp(["еұһдәҺ第дёҖзұ»зҡ„ж ·жң¬дёӘж•°дёәпјҡ",num2str(class_num(1))]);
disp(["еұһдәҺ第дәҢзұ»зҡ„ж ·жң¬дёӘж•°дёәпјҡ",num2str(class_num(2))]);
disp(["еұһдәҺ第дёүзұ»зҡ„ж ·жң¬дёӘж•°дёәпјҡ",num2str(class_num(3))]);
disp("жңҖз»Ҳзҡ„иҒҡзұ»дёӯеҝғдёәпјҡ");
disp(num2str(center));
% д»ҘдёӢжҳҜkеқҮеҖјиҒҡзұ»зҡ„еҸӮж•°и®ҫе®ҡпјҲc = 3ж—¶пјү
k = 3;
% m = [0 0 0; 1 1 1; -1 0 2]; % еҲқе§ӢиҒҡзұ»дёӯеҝғ
m = [-0.1 0.0 0.1; 0 -0.1 0.1; -0.1 -0.1 0.1]; % еҲқе§ӢиҒҡзұ»дёӯеҝғ
iteration = 200; % kеқҮеҖјиҒҡзұ»зҡ„иҝӯд»Јж¬Ўж•°
% и°ғз”ЁkmeansеҮҪж•°иҝӣиЎҢиҒҡзұ»
[class, class_num, center] = kmeans(w, k, m, iteration);
% з”»еҮәж ·жң¬еҲҶзұ»з»“жһң
subplot(122);draw(w, class, center);
title("дҪҝ用第дәҢз§ҚеҲқе§ӢиҒҡзұ»дёӯеҝғж—¶пјҢk-еқҮеҖјиҒҡзұ»з®—жі•еҲҶзұ»з»“жһң");
% жҳҫзӨәдҝЎжҒҜ
disp(["еұһдәҺ第дёҖзұ»зҡ„ж ·жң¬дёӘж•°дёәпјҡ",num2str(class_num(1))]);
disp(["еұһдәҺ第дәҢзұ»зҡ„ж ·жң¬дёӘж•°дёәпјҡ",num2str(class_num(2))]);
disp(["еұһдәҺ第дёүзұ»зҡ„ж ·жң¬дёӘж•°дёәпјҡ",num2str(class_num(3))]);
disp("жңҖз»Ҳзҡ„иҒҡзұ»дёӯеҝғдёәпјҡ");
disp(num2str(center));