

жң¬е®һйӘҢзҡ„зӣ®зҡ„жҳҜеӯҰд№ ParzenзӘ—дј°и®Ўе’ҢkжңҖиҝ‘йӮ»дј°и®Ўж–№жі•гҖӮеңЁд№ӢеүҚзҡ„жЁЎејҸиҜҶеҲ«з ”究дёӯпјҢжҲ‘们еҒҮи®ҫжҰӮзҺҮеҜҶеәҰеҮҪж•°зҡ„еҸӮж•°еҪўејҸе·ІзҹҘпјҢеҚіеҲӨеҲ«еҮҪж•°J(.)зҡ„еҸӮж•°жҳҜе·ІзҹҘзҡ„гҖӮжң¬иҠӮдҪҝз”ЁйқһеҸӮж•°еҢ–зҡ„ж–№жі•жқҘеӨ„зҗҶд»»ж„ҸеҪўејҸзҡ„жҰӮзҺҮеҲҶеёғиҖҢдёҚеҝ…дәӢе…ҲиҖғиҷ‘жҰӮзҺҮеҜҶеәҰзҡ„еҸӮж•°еҪўејҸгҖӮеңЁжЁЎејҸиҜҶеҲ«дёӯжңүиәІеңЁд»Өдәәж„ҹе…ҙи¶Јзҡ„йқһеҸӮж•°еҢ–ж–№жі•пјҢParzenзӘ—дј°и®Ўе’ҢkжңҖиҝ‘йӮ»дј°и®Ўе°ұжҳҜдёӨз§Қз»Ҹе…ёзҡ„дј°и®Ўжі•гҖӮ
еҸӮиҖғд№ҰзұҚпјҡгҖҠжЁЎејҸеҲҶзұ»гҖӢВ
дҪңиҖ…пјҡRichardO.DudaпјҢPeterE.HartпјҢDavidG.Stork
дёҖгҖҒеҹәжң¬еҺҹзҗҶ
1.йқһеҸӮж•°еҢ–жҰӮзҺҮеҜҶеәҰзҡ„дј°и®Ў
еҜ№дәҺжңӘзҹҘжҰӮзҺҮеҜҶеәҰеҮҪж•°зҡ„дј°и®Ўж–№жі•пјҢе…¶ж ёеҝғжҖқжғіжҳҜпјҡдёҖдёӘеҗ‘йҮҸxиҗҪеңЁеҢәеҹҹRдёӯзҡ„жҰӮзҺҮеҸҜиЎЁзӨәдёәпјҡ
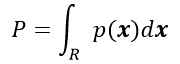
е…¶дёӯпјҢPжҳҜжҰӮзҺҮеҜҶеәҰеҮҪж•°p(x)зҡ„е№іж»‘зүҲжң¬пјҢеӣ жӯӨеҸҜд»ҘйҖҡиҝҮи®Ўз®—PжқҘдј°и®ЎжҰӮзҺҮеҜҶеәҰеҮҪж•°p(x)пјҢеҒҮи®ҫnдёӘж ·жң¬x1,x2,вҖҰ,xnпјҢжҳҜж №жҚ®жҰӮзҺҮеҜҶеәҰеҮҪж•°p(x)зӢ¬з«ӢеҗҢеҲҶеёғзҡ„жҠҪеҸ–еҫ—еҲ°пјҢиҝҷж ·пјҢжңүkдёӘж ·жң¬иҗҪеңЁеҢәеҹҹRдёӯзҡ„жҰӮзҺҮжңҚд»Һд»ҘдёӢеҲҶеёғпјҡ
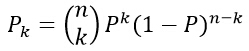
е…¶дёӯkзҡ„жңҹжңӣеҖјдёәпјҡ
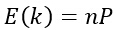
kзҡ„еҲҶеёғеңЁеқҮеҖјйҷ„иҝ‘жңүзқҖйқһеёёжҳҫи‘—зҡ„жіўеі°пјҢеӣ жӯӨиӢҘж ·жң¬дёӘж•°nи¶іеӨҹеӨ§ж—¶пјҢдҪҝз”Ёk/nдҪңдёәжҰӮзҺҮPзҡ„дёҖдёӘдј°и®Ўе°ҶйқһеёёеҮҶзЎ®гҖӮеҒҮи®ҫp(x)жҳҜиҝһз»ӯзҡ„пјҢдё”еҢәеҹҹRи¶іеӨҹе°ҸпјҢеҲҷжңүпјҡ
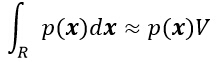
еҰӮдёӢеӣҫжүҖзӨәпјҢд»ҘдёҠе…¬ејҸдә§з”ҹдёҖдёӘзү№е®ҡеҖјзҡ„зӣёеҜ№жҰӮзҺҮпјҢеҪ“nи¶Ӣиҝ‘дәҺж— з©·еӨ§ж—¶пјҢжӣІзәҝзҡ„еҪўзҠ¶йҖјиҝ‘дёҖдёӘОҙеҮҪж•°пјҢиҜҘеҮҪж•°еҚіжҳҜзңҹе®һзҡ„жҰӮзҺҮгҖӮе…¬ејҸдёӯзҡ„VжҳҜеҢәеҹҹRжүҖеҢ…еҗ«зҡ„дҪ“з§ҜгҖӮз»јдёҠжүҖиҝ°пјҢеҸҜд»Ҙеҫ—еҲ°е…ідәҺжҰӮзҺҮеҜҶеәҰеҮҪж•°p(x)зҡ„дј°и®Ўдёәпјҡ
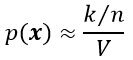
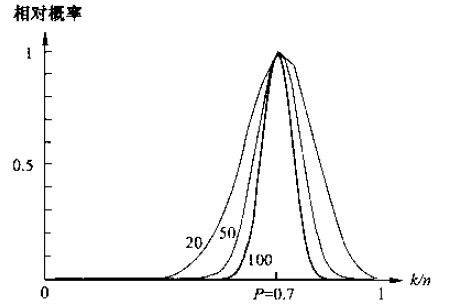
еңЁе®һйҷ…дёӯпјҢдёәдәҶдј°и®ЎxеӨ„зҡ„жҰӮзҺҮеҜҶеәҰеҮҪж•°пјҢйңҖиҰҒжһ„йҖ еҢ…еҗ«зӮ№xзҡ„еҢәеҹҹR1,R2,вҖҰ,RnгҖӮ第дёҖдёӘеҢәеҹҹдҪҝз”Ё1дёӘж ·жң¬пјҢ第дәҢдёӘеҢәеҹҹдҪҝз”Ё2дёӘж ·жң¬пјҢд»ҘжӯӨзұ»жҺЁгҖӮи®°VnдёәRnзҡ„дҪ“з§ҜгҖӮknдёәиҗҪеңЁеҢәй—ҙRnдёӯзҡ„ж ·жң¬дёӘж•°пјҢиҖҢpn (x)иЎЁзӨәдёәеҜ№p(x)зҡ„第nж¬Ўдј°и®Ўпјҡ
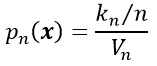
ж¬Іж»Ўи¶іpn(x)收ж•ӣпјҡpn(x)вҶ’p(x)пјҢйңҖиҰҒж»Ўи¶ід»ҘдёӢдёүдёӘжқЎд»¶пјҡ
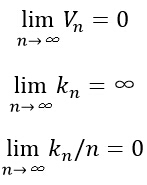
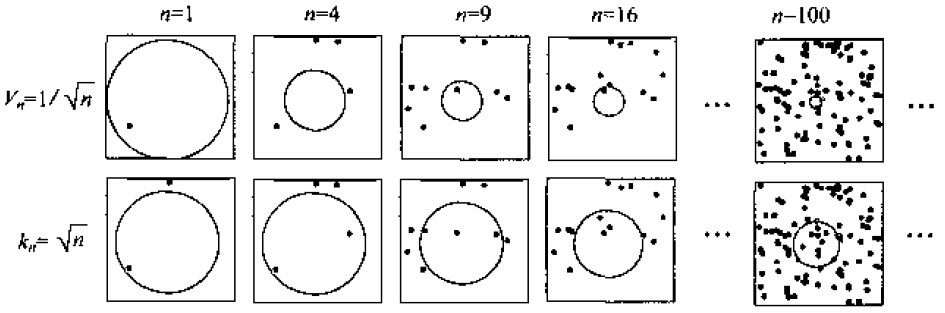
жңүдёӨз§Қз»ҸеёёйҮҮз”Ёзҡ„иҺ·еҫ—иҝҷз§ҚеҢәеҹҹеәҸеҲ—зҡ„йҖ”еҫ„пјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮе…¶дёӯвҖңParzenзӘ—ж–№жі•вҖқе°ұжҳҜж №жҚ®жҹҗдёҖдёӘзЎ®е®ҡзҡ„дҪ“з§ҜеҮҪж•°пјҢжҜ”еҰӮVn=1/вҲҡnжқҘйҖҗжёҗ收缩дёҖдёӘз»ҷе®ҡзҡ„еҲқе§ӢеҢәй—ҙгҖӮиҝҷе°ұиҰҒжұӮйҡҸжңәеҸҳйҮҸknе’Ңkn/nиғҪеӨҹдҝқиҜҒpn (x)иғҪ收ж•ӣеҲ°p(x)гҖӮ第дәҢз§ҚвҖңk-иҝ‘йӮ»жі•вҖқеҲҷжҳҜе…ҲзЎ®е®ҡknдёәnзҡ„жҹҗдёӘеҮҪж•°пјҢеҰӮkn=вҲҡnгҖӮиҝҷж ·пјҢдҪ“з§ҜйңҖиҰҒйҖҗжёҗз”ҹй•ҝпјҢзӣҙеҲ°жңҖеҗҺиғҪеҢ…еҗ«иҝӣxзҡ„knдёӘзӣёйӮ»зӮ№гҖӮ
2.ParzenзӘ—дј°и®Ўжі•
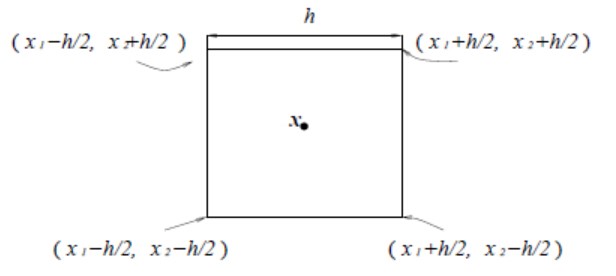
е·ІзҹҘжөӢиҜ•ж ·жң¬ж•°жҚ®x1,x2,вҖҰ,xnпјҢеңЁдёҚеҲ©з”Ёжңүе…іж•°жҚ®еҲҶеёғзҡ„е…ҲйӘҢзҹҘиҜҶпјҢеҜ№ж•°жҚ®еҲҶеёғдёҚйҷ„еҠ д»»дҪ•еҒҮе®ҡзҡ„еүҚжҸҗдёӢпјҢеҒҮи®ҫRжҳҜд»Ҙxдёәдёӯеҝғзҡ„и¶…з«Ӣж–№дҪ“пјҢhдёәиҝҷдёӘи¶…з«Ӣж–№дҪ“зҡ„иҫ№й•ҝпјҢеҜ№дәҺдәҢз»ҙжғ…еҶөпјҢж–№еҪўдёӯжңүйқўз§ҜV=h^2пјҢеңЁдёүз»ҙжғ…еҶөдёӯз«Ӣж–№дҪ“дҪ“з§ҜV=h^3пјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
ж №жҚ®д»ҘдёӢе…¬ејҸпјҢиЎЁзӨәxжҳҜеҗҰиҗҪе…Ҙи¶…з«Ӣж–№дҪ“еҢәеҹҹдёӯпјҡ
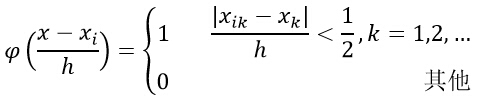
дј°и®Ўе®ғзҡ„жҰӮзҺҮеҲҶеёғпјҡ
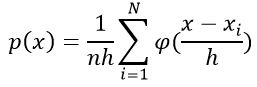
е…¶дёӯnдёәж ·жң¬ж•°йҮҸпјҢhдёәйҖүжӢ©зҡ„зӘ—зҡ„й•ҝеәҰпјҢПҶ(.)дёәж ёеҮҪж•°пјҢйҖҡеёёйҮҮз”Ёзҹ©еҪўзӘ—е’Ңй«ҳж–ҜзӘ—гҖӮ
3.kжңҖиҝ‘йӮ»дј°и®Ў
еңЁParzenз®—жі•дёӯпјҢзӘ—еҮҪж•°зҡ„йҖүжӢ©еҫҖеҫҖжҳҜдёӘйңҖиҰҒжқғиЎЎзҡ„й—®йўҳпјҢk-жңҖиҝ‘йӮ»з®—жі•жҸҗдҫӣдәҶдёҖз§Қи§ЈеҶіж–№жі•пјҢжҳҜдёҖз§Қйқһеёёз»Ҹе…ёзҡ„йқһеҸӮж•°дј°и®Ўжі•гҖӮеҹәжң¬жҖқи·ҜжҳҜпјҡе·ІзҹҘи®ӯз»ғж ·жң¬ж•°жҚ®x1,x2,вҖҰ,xnиҖҢдј°и®Ўp(x)пјҢд»ҘзӮ№xдёәдёӯеҝғпјҢдёҚж–ӯжү©еӨ§дҪ“з§ҜVnпјҢзӣҙеҲ°еҢәеҹҹеҶ…еҢ…еҗ«kдёӘж ·жң¬зӮ№дёәжӯўпјҢе…¶дёӯkжҳҜе…ідәҺnзҡ„жҹҗдёҖдёӘзү№е®ҡеҮҪж•°пјҢиҝҷдәӣж ·жң¬иў«з§°дёәзӮ№xзҡ„kдёӘжңҖиҝ‘йӮ»зӮ№гҖӮ
еҪ“ж¶үеҸҠеҲ°йӮ»зӮ№ж—¶пјҢйҖҡеёёйңҖиҰҒи®Ўз®—и§ӮжөӢзӮ№й—ҙзҡ„и·қзҰ»жҲ–е…¶д»–зҡ„зӣёдјјжҖ§еәҰйҮҸпјҢиҝҷдәӣеәҰйҮҸиғҪеӨҹж №жҚ®иҮӘеҸҳйҮҸеҫ—еҮәгҖӮиҝҷйҮҢжҲ‘们йҖүз”ЁжңҖеёёи§Ғзҡ„и·қзҰ»еәҰйҮҸж–№жі•пјҡ欧еҮ йҮҢеҫ·и·қзҰ»гҖӮ
жңҖз®ҖеҚ•зҡ„жғ…еҶөжҳҜеҪ“k=1зҡ„жғ…еҶөпјҢиҝҷж—¶жҲ‘们еҸ‘зҺ°и§ӮжөӢзӮ№е°ұжҳҜжңҖиҝ‘зҡ„пјҲжңҖиҝ‘йӮ»пјүгҖӮдёҖдёӘжҳҫи‘—зҡ„дәӢе®һжҳҜпјҡиҝҷжҳҜз®ҖеҚ•зҡ„гҖҒзӣҙи§Ӯзҡ„гҖҒжңүеҠӣзҡ„еҲҶзұ»ж–№жі•пјҢе°Өе…¶еҪ“жҲ‘们зҡ„и®ӯз»ғйӣҶдёӯи§ӮжөӢзӮ№зҡ„ж•°зӣ®nеҫҲеӨ§зҡ„ж—¶еҖҷгҖӮеҸҜд»ҘиҜҒжҳҺпјҢkжңҖиҝ‘йӮ»дј°и®Ўзҡ„иҜҜеҲҶжҰӮзҺҮдёҚй«ҳдәҺеҪ“зҹҘйҒ“жҜҸдёӘзұ»зҡ„зІҫзЎ®жҰӮзҺҮеҜҶеәҰеҮҪж•°ж—¶иҜҜеҲҶжҰӮзҺҮзҡ„дёӨеҖҚгҖӮ
дәҢгҖҒе®һйӘҢеҹәжң¬жӯҘйӘӨ
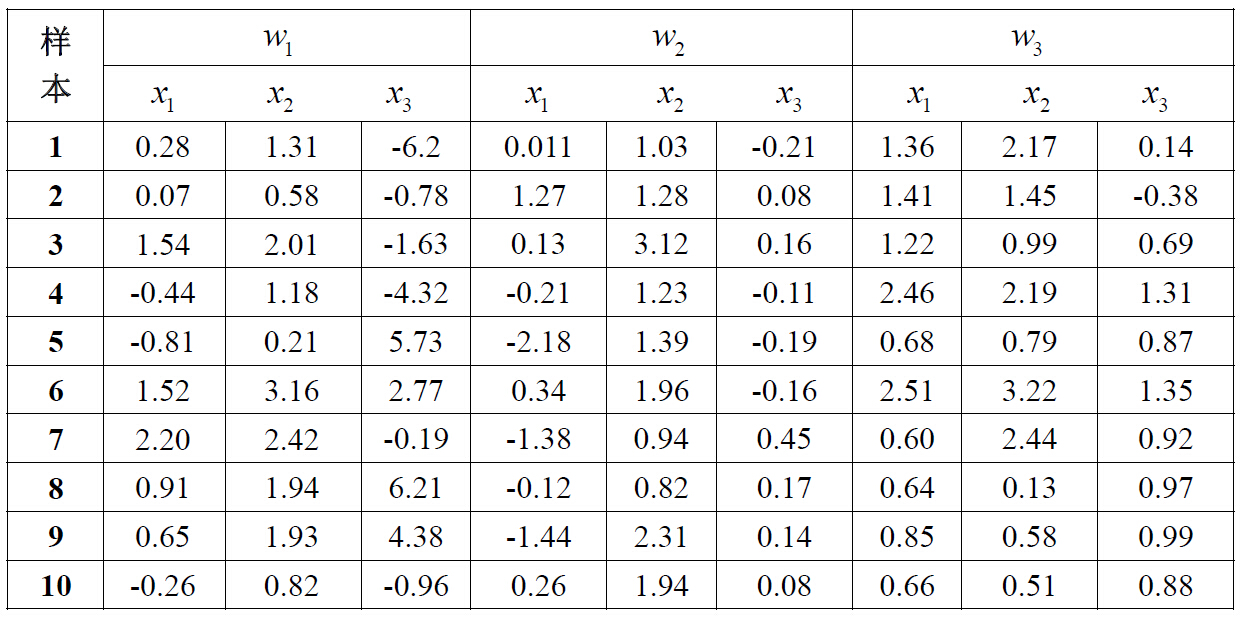
第дёҖйғЁеҲҶпјҢеҜ№иЎЁж јдёӯзҡ„ж•°жҚ®пјҢиҝӣиЎҢParzen зӘ—дј°и®Ўе’Ңи®ҫи®ЎеҲҶзұ»еҷЁпјҢжң¬е®һйӘҢзҡ„зӘ—еҮҪж•°дёәдёҖдёӘзҗғеҪўзҡ„й«ҳж–ҜеҮҪж•°пјҢеҰӮдёӢпјҡ
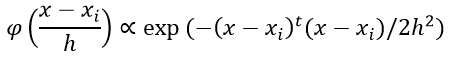
1) зј–еҶҷзЁӢеәҸпјҢдҪҝз”ЁParzen зӘ—дј°и®Ўж–№жі•еҜ№дёҖдёӘд»»ж„Ҹзҡ„жөӢиҜ•ж ·жң¬зӮ№x иҝӣиЎҢеҲҶзұ»гҖӮеҜ№еҲҶзұ»еҷЁзҡ„и®ӯз»ғеҲҷдҪҝз”ЁиЎЁж ј 3дёӯзҡ„дёүз»ҙж•°жҚ®гҖӮеҗҢж—¶пјҢд»Өh =1пјҢеҲҶзұ»ж ·жң¬зӮ№дёә(0.5,1.0,0.0)пјҢ(0.31,1.51,-0.50)пјҢ(-0.3,0.44,-0.1)иҝӣиЎҢе®һйӘҢгҖӮ
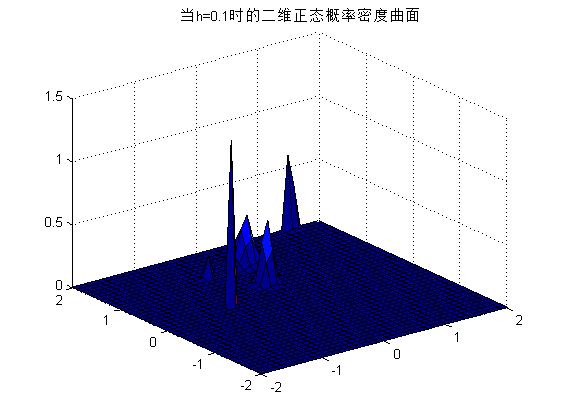
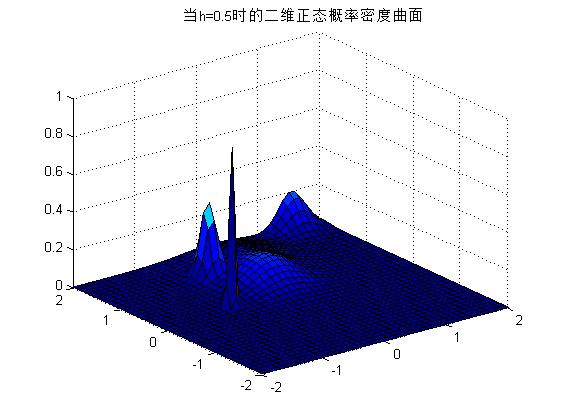
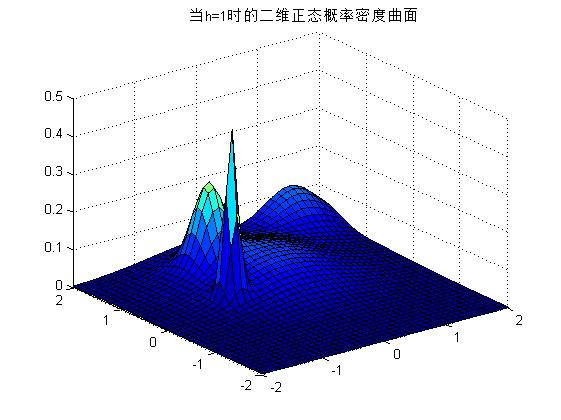
2) еҸҜд»Ҙж”№еҸҳhзҡ„еҖјпјҢдёҚеҗҢзҡ„hе°ҶеҜјиҮҙдёҚеҗҢзҡ„жҰӮзҺҮеҜҶеәҰжӣІзәҝпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
h=0.1ж—¶пјҡ
h=0.5ж—¶пјҡ
h=1ж—¶пјҡ
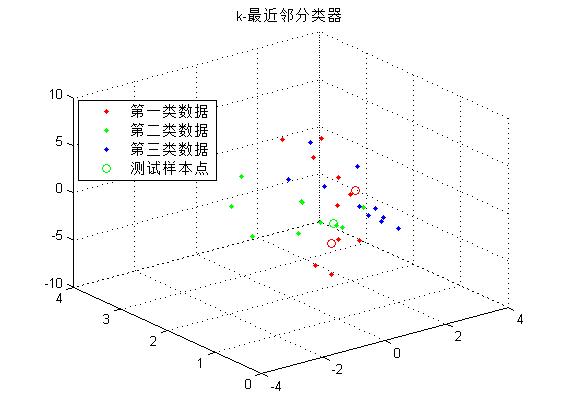
第дәҢйғЁеҲҶзҡ„е®һйӘҢзӣ®зҡ„жҳҜеӯҰд№ е’ҢжҺҢжҸЎйқһеҸӮж•°дј°и®Ўпјҡk-иҝ‘йӮ»жҰӮзҺҮеҜҶеәҰдј°и®Ўж–№жі•гҖӮеҜ№еүҚйқўиЎЁж јдёӯзҡ„ж•°жҚ®иҝӣиЎҢk-иҝ‘йӮ»жҰӮзҺҮеҜҶеәҰдј°и®Ўж–№жі•е’Ңи®ҫи®ЎеҲҶзұ»еҷЁгҖӮ
зј–еҶҷзЁӢеәҸпјҢеҜ№иЎЁж јдёӯзҡ„3дёӘзұ»еҲ«зҡ„дёүз»ҙзү№еҫҒпјҢдҪҝз”Ёk-иҝ‘йӮ»жҰӮзҺҮеҜҶеәҰдј°и®Ўж–№жі•гҖӮ并且еҜ№дёӢеҲ—зӮ№еӨ„зҡ„жҰӮзҺҮеҜҶеәҰиҝӣиЎҢдј°и®Ўпјҡ(-0.41,0.82,0.88)пјҢ(0.14,0.72, 4.1) пјҢ(-0.81,0.61,-0.38)гҖӮ
е®һйӘҢд»Јз ҒеҰӮдёӢпјҡ
% ParzenзӘ—з®—жі•
% wпјҡcзұ»и®ӯз»ғж ·жң¬
% xпјҡжөӢиҜ•ж ·жң¬
% hпјҡеҸӮж•°
% иҫ“еҮәpпјҡжөӢиҜ•ж ·жң¬xиҗҪеңЁжҜҸдёӘзұ»зҡ„жҰӮзҺҮ
function p = Parzen(w,x,h)
[xt,yt,zt] = size(w);
p = zeros(1,zt);
for i = 1:zt
hn = h;
for j = 1:xt
hn = hn / sqrt(j);
p(i) = p(i) + exp(-(x - w(j,:,i))*(x - w(j,:,i))"/ (2 * power(hn,2))) / (hn * sqrt(2*3.14));
end
p(i) = p(i) / xt;
end
% k-жңҖиҝ‘йӮ»з®—жі•
% wпјҡcзұ»и®ӯз»ғж ·жң¬
% xпјҡжөӢиҜ•ж ·жң¬
% kпјҡеҸӮж•°
function p = kNearestNeighbor(w,k,x)
% w = [w(:,:,1);w(:,:,2);w(:,:,3)];
[xt,yt,zt] = size(w);
wt = [];%zeros(xt*zt, yt);
if nargin==2
p = zeros(1,zt);
for i = 1:xt
for j = 1:xt
dist(j,i) = norm(wt(i,:) - wt(j,:));
end
t(:,i) = sort(dist(:,i));
m(:,i) = find(dist(:,i) <= t(k+1,i)); % жүҫеҲ°kдёӘжңҖиҝ‘йӮ»зҡ„зј–еҸ·
end
end
if nargin==3
for q = 1:zt
wt = [wt; w(:,:,q)];
[xt,yt] = size(wt);
end
for i = 1:xt
dist(i) = norm(x - wt(i,:));
end
t = sort(dist); % 欧ж°Ҹи·қзҰ»жҺ’еәҸ
[a,b] = size(t);
m = find(dist <= t(k+1)); % жүҫеҲ°kдёӘжңҖиҝ‘йӮ»зҡ„зј–еҸ·
num1 = length(find(m>0 & m<11));
num2 = length(find(m>10 & m<21));
num3 = length(find(m>20 & m<31));
if yt == 3
plot3(w(:,1,1),w(:,2,1),w(:,3,1), "r.");
hold on;
grid on;
plot3(w(:,1,2),w(:,2,2),w(:,3,2), "g.");
plot3(w(:,1,3),w(:,2,3),w(:,3,3), "b.");
if (num1 > num2) || (num1 > num3)
plot3(x(1,1),x(1,2),x(1,3), "ro");
disp(["зӮ№пјҡ[",num2str(x),"]еұһдәҺ第дёҖзұ»"]);
elseif (num2 > num1) || (num2 > num3)
plot3(x(1,1),x(1,2),x(1,3), "go");
disp(["зӮ№пјҡ[",num2str(x),"]еұһдәҺ第дәҢзұ»"]);
elseif (num3 > num1) || (num3 > num2)
plot3(x(1,1),x(1,2),x(1,3), "bo");
disp(["зӮ№пјҡ[",num2str(x),"]еұһдәҺ第дёүзұ»"]);
else
disp("ж— жі•еҲҶзұ»");
end
end
if yt == 2
plot(w(:,1,1),w(:,2,1), "r.");
hold on;
grid on;
plot(w(:,1,2),w(:,2,2), "g.");
plot(w(:,1,3),w(:,2,3), "b.");
if (num1 > num2) || (num1 > num3)
plot(x(1,1),x(1,2), "ro");
disp(["зӮ№пјҡ[",num2str(x),"]еұһдәҺ第дёҖзұ»"]);
elseif (num2 > num1) || (num2 > num3)
plot(x(1,1),x(1,2), "go");
disp(["зӮ№пјҡ[",num2str(x),"]еұһдәҺ第дәҢзұ»"]);
elseif (num3 > num1) || (num3 > num2)
plot(x(1,1),x(1,2), "bo");
disp(["зӮ№пјҡ[",num2str(x),"]еұһдәҺ第дёүзұ»"]);
else
disp("ж— жі•еҲҶзұ»");
end
end
end
title("k-жңҖиҝ‘йӮ»еҲҶзұ»еҷЁ");
legend("第дёҖзұ»ж•°жҚ®",...
"第дәҢзұ»ж•°жҚ®",...
"第дёүзұ»ж•°жҚ®",...
"жөӢиҜ•ж ·жң¬зӮ№");
clear;
close all;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% ParzenзӘ—дј°и®Ўе’ҢkжңҖиҝ‘йӮ»дј°и®Ў
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
w1(:,:,1) = [ 0.28 1.31 -6.2;...
0.07 0.58 -0.78;...
1.54 2.01 -1.63;...
-0.44 1.18 -4.32;...
-0.81 0.21 5.73;...
1.52 3.16 2.77;...
2.20 2.42 -0.19;...
0.91 1.94 6.21;...
0.65 1.93 4.38;...
-0.26 0.82 -0.96];
w1(:,:,2) = [0.011 1.03 -0.21;...
1.27 1.28 0.08;...
0.13 3.12 0.16;...
-0.21 1.23 -0.11;...
-2.18 1.39 -0.19;...
0.34 1.96 -0.16;...
-1.38 0.94 0.45;...
-0.12 0.82 0.17;...
-1.44 2.31 0.14;...
0.26 1.94 0.08];
w1(:,:,3) = [ 1.36 2.17 0.14;...
1.41 1.45 -0.38;...
1.22 0.99 0.69;...
2.46 2.19 1.31;...
0.68 0.79 0.87;...
2.51 3.22 1.35;...
0.60 2.44 0.92;...
0.64 0.13 0.97;...
0.85 0.58 0.99;...
0.66 0.51 0.88];
x(1,:) = [0.5 1 0];
x(2,:) = [0.31 1.51 -0.5];
x(3,:) = [-0.3 0.44 -0.1];
% йӘҢиҜҒhзҡ„дәҢз»ҙж•°жҚ®
w2(:,:,1) = [ 0.28 1.31 ;...
0.07 0.58 ;...
1.54 2.01 ;...
-0.44 1.18 ;...
-0.81 0.21 ;...
1.52 3.16 ;...
2.20 2.42 ;...
0.91 1.94 ;...
0.65 1.93 ;...
-0.26 0.82 ];
w2(:,:,2) = [0.011 1.03 ;...
1.27 1.28 ;...
0.13 3.12 ;...
-0.21 1.23 ;...
-2.18 1.39 ;...
0.34 1.96 ;...
-1.38 0.94 ;...
-0.12 0.82 ;...
-1.44 2.31 ;...
0.26 1.94 ];
w2(:,:,3) = [1.36 2.17 ;...
1.41 1.45 ;...
1.22 0.99 ;...
2.46 2.19 ;...
0.68 0.79 ;...
2.51 3.22 ;...
0.60 2.44 ;...
0.64 0.13 ;...
0.85 0.58 ;...
0.66 0.51 ];
y(1,:) = [0.5 1];
y(2,:) = [0.31 1.51];
y(3,:) = [-0.3 0.44];
h = .1; % йҮҚиҰҒеҸӮж•°
p = Parzen(w1,x(1,:),h);
num = find(p == max(p));
disp(["зӮ№пјҡ[",num2str(x(1,:)),"]иҗҪеңЁдёүдёӘзұ»еҲ«зҡ„жҰӮзҺҮеҲҶеҲ«дёәпјҡ",num2str(p)]);
disp(["зӮ№пјҡ[",num2str(x(1,:)),"]иҗҪеңЁз¬¬",num2str(num),"зұ»"]);
% з»ҷе®ҡдёүзұ»дәҢз»ҙж ·жң¬пјҢз”»еҮәдәҢз»ҙжӯЈжҖҒжҰӮзҺҮеҜҶеәҰжӣІйқўеӣҫйӘҢиҜҒhзҡ„дҪңз”Ё
num =1; % 第numзұ»зҡ„дәҢз»ҙжӯЈжҖҒжҰӮзҺҮеҜҶеәҰжӣІйқўеӣҫпјҢеҸ–еҖјдёә1пјҢ2пјҢ3
draw(w2,h,num);
str1="еҪ“h=";str2=num2str(h);str3="ж—¶зҡ„дәҢз»ҙжӯЈжҖҒжҰӮзҺҮеҜҶеәҰжӣІйқў";
SC = [str1,str2,str3];
title(SC);
% kиҝ‘йӮ»з®—жі•и®ҫи®Ўзҡ„еҲҶзұ»еҷЁ
% x1е’Ңy1дёәжөӢиҜ•ж ·жң¬
x1 = [-0.41,0.82,0.88];
x2 = [0.14,0.72, 4.1];
x3 = [-0.81,0.61,-0.38];
y(1,:) = [0.5 1];
y(2,:) = [0.31 1.51];
y(3,:) = [-0.3 0.44];
w = w1;
%w = w1(:,1,3);
k = 5;
kNearestNeighbor(w,k,x1);
kNearestNeighbor(w,k,x2);
kNearestNeighbor(w,k,x3);