

转载请注明出处:http://blog.csdn.net/xiaojimanman/article/details/42804713
数据分类:
对于日常生活中的数据,我们可以大致分为如下三大类:结构化数据、非结构化数据、半结构化数据:
结构化数据:指具有固定格式或有限长度的数据,如数据库行数据:存在数据库中,可以用二维表结构来逻辑表达实现的数据
非结构化数据:指不定长度或者无固定格式的数据,如邮件、word文档、音频、超音频等
半结构化数据:对于这种数据可以按照结构化数据来处理,也可以提取纯文本按照非结构化数据来处理,如xml数据
对于不同的数据当然就需要采取不同的检索方式,结构化数据大家也许都很熟悉,可以用熟悉的sql语句进行检索,如“select * from student where stuno like "2014%"”,这样一条简单的sql语句就可以查找到所有学号以2014开始的学生信息了;那对于非结构化的数据又该如何处理呢?使用sql中的like?这答案显然是否定的,对于非结构化的数据常用的检索方式有顺序扫描、索引(Index),不用测试也可以知道,顺序扫描的效率还是相当差的,下面就重点的介绍一下对非结构化数据的索引检索。
索引步骤:
对于非结构化数据采用索引检索又可以说是全文检索(Full-Text-Search),在索引过程中,我大致给它分成两大步骤:
索引创建(Indexing):将结构化数据或非结构化数据提取信息创建索引的过程,具体如下图左半部分所示:
搜索索引(Search)根据用户的查询条件,检索已创建的索引,返回查询结果的过程,具体如参照下图右半部分所示:
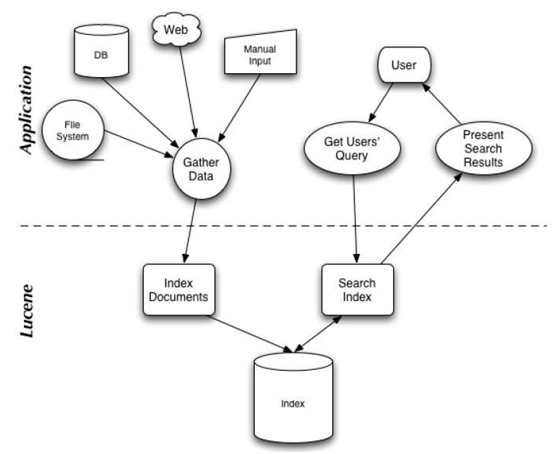
上图左半部分就是索引的创建过程,可以将文件系统数据、数据库数据、web数据等,通过索引的创建,形成最终的索引文件;右半部分是用户检索过程,获取用户查询条件,检索索引库最终返回检索结果。
仔细看下上图,我们很容易会想到下面3个问题:
索引是什么?
如何创建索引?
如何进行索引检索?
下面就对这三个问题做一一解答。
索引是什么
如以前没有接触过索引的话,这部分还是很难理解的众多专业名词的,因此下面就举一个简单的例子来说明下,什么是索引:

对于上图中的三个小图片我想大家并不会太陌生,那现在大家就开回忆一下,我们在使用新华字典去查找一个汉子解释的这个过程:通过音节索引或者部首索引查找到想要查找的汉子所在的页码数-->翻到对应的页码,查看该汉字的解释。下面我们想一下,如果没有这些音节索引或者部首索引,我们这次检索过程是不是会花费很长的时间?不知道到现在,你是不是对索引有了一个大概的了解。
其实上图中间的部分,就相当于我们这里提到的索引,这种由字符串到文件的映射是文件到字符串映射的反向过程,我们就称这种信息为反向索引。
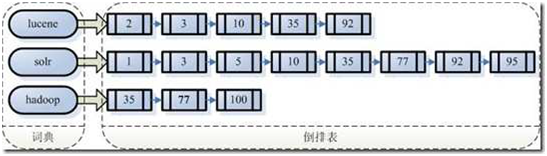
上图中左半部分保存的信息,我们一般称为字典,左侧每一个字符串指向右侧的文档链接,此文档链表称为倒排表。关于新华字典的例子如何和反向索引对应起来这个就自己思考下。
如何创建索引
对于索引的创建,我对其总结出一个三步曲:需要检索的数据(Document)、分词技术(Analyzer)、索引组建(Indexer),可以简单的参照下图:
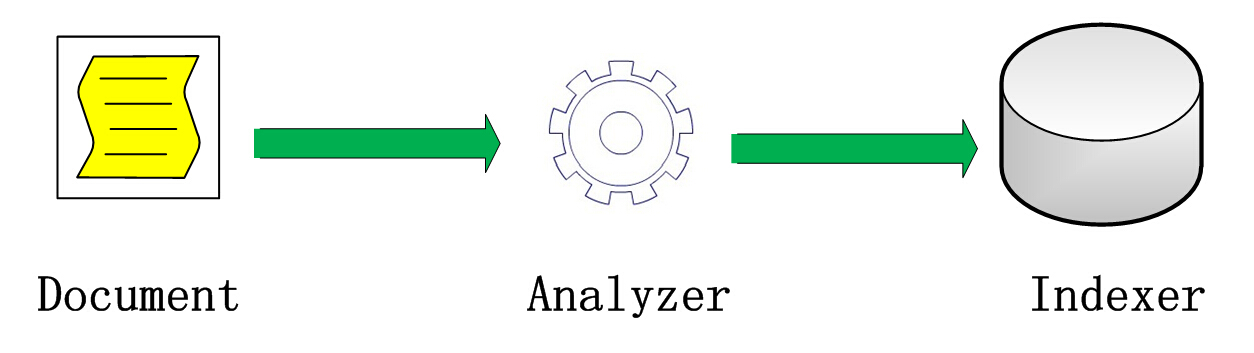
我们还是通过简单的例子来介绍这个过程
第一步数据:Document事例数据:
你好!我是小李。
中国在哪里?
你是谁?
lucene基础知识学习课程。
你在中石油上学?
中石油在哪里?
第二步:分词技术,这里采用StandarAnalyzer(标准分词)
你|好|我|是|小|李|
中|国|在|哪|里|
你|是|谁|
lucene|基|础|知|识|学|习|课|程|
你|在|中|石|油|上|学|
中|石|油|在|哪|里|
第三步:索引创建字典:
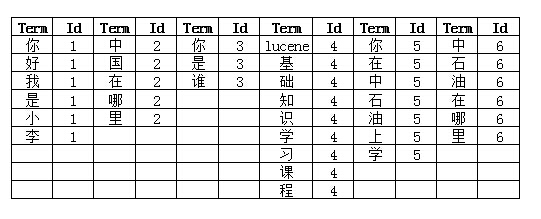
第三步:索引组建合并词成倒排表:
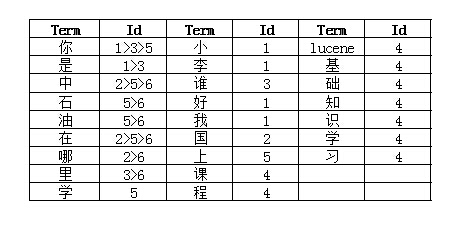
到现在,索引文件就已经创建完成。
如何搜索
对索引的检索过程,我对其总结出四步曲:获取检索词(KeyWords)、分词技术(Analyzer)、检索索引(Aearch)、返回结果列表,可以简单参照下图:
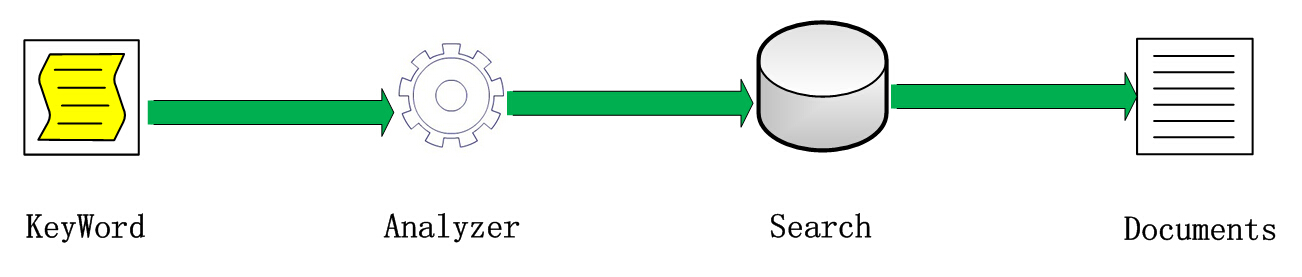
同样我们还是继续接上述事例去说搜索过程
第一步:KeyWord事例数据
中石油
第二步:分词技术(因为创建索引的时候,采用的是标准分词,索引在搜索的过程,也应该采用该分词技术)
中|石|油|
第三步:检索索引搜索记录:
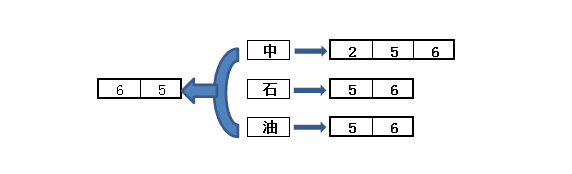
第四步:返回结果列表
中石油在哪里?
你在中石油上学?
上述三个问题,都已经通过具体的事例进行了解答,由于自己接触lucene的时间也只是短短的两年时间,好多原理自己也不是太清楚,所以自己的这系列的博客不会涉及太多的具体原理,如果想做深入的了解,建议还是买一本参考书对其做系统的了解。