

иҪ¬иҪҪиҜ·жіЁжҳҺеҮәеӨ„пјҡhttp://blog.csdn.net/xiaojimanman/article/details/42916755
еңЁluceneеҲӣе»әзҙўеј•зҡ„иҝҮзЁӢдёӯпјҢж•°жҚ®дҝЎжҒҜзҡ„еӨ„зҗҶжҳҜдёҖдёӘеҚҒеҲҶйҮҚиҰҒзҡ„иҝҮзЁӢпјҢеңЁиҝҷдёҖиҝҮзЁӢдёӯпјҢдё»иҰҒзҡ„йғЁеҲҶе°ұжҳҜиҝҷдёҖзҜҮеҚҡе®ўзҡ„дё»йўҳпјҡеҲҶиҜҚеҷЁгҖӮеңЁдёӢйқўз®ҖеҚ•зҡ„demoдёӯпјҢд»Ӣз»ҚдәҶ7дёӯжҜ”иҫғеёёи§Ғзҡ„еҲҶиҜҚжҠҖжңҜпјҢеҚіпјҡCJKAnalyzerгҖҒKeywordAnalyzerгҖҒSimpleAnalyzerгҖҒStopAnalyzerгҖҒWhitespaceAnalyzerгҖҒStandardAnalyzerгҖҒIKAnalyzerпјӣиҮӘе·ұеҸҜд»ҘйҖҡиҝҮжіЁйҮҠзҡ„еҪўејҸдёҖдёҖйӘҢиҜҒгҖӮжәҗзЁӢеәҸеҰӮдёӢпјҡ
AnalyzerеҲҶиҜҚdemo
/**
*@Description: еҲҶиҜҚжҠҖжңҜdemo
*/
package com.lulei.lucene.study;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.analysis.core.KeywordAnalyzer;
import org.apache.lucene.analysis.core.SimpleAnalyzer;
import org.apache.lucene.analysis.core.StopAnalyzer;
import org.apache.lucene.analysis.core.WhitespaceAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class AnalyzerStudy {
public static void main(String[] args) throws Exception {
//йңҖиҰҒеӨ„зҗҶзҡ„жөӢиҜ•еӯ—з¬ҰдёІ
String str = "иҝҷжҳҜдёҖдёӘеҲҶиҜҚеҷЁжөӢиҜ•зЁӢеәҸпјҢеёҢжңӣеӨ§е®¶з»§з»ӯе…іжіЁжҲ‘зҡ„дёӘдәәзі»еҲ—еҚҡе®ўпјҡеҹәдәҺLuceneзҡ„жЎҲдҫӢејҖеҸ‘пјҢиҝҷйҮҢеҠ дёҖзӮ№еёҰз©әж јзҡ„ж Үзӯҫ LUCENE java еҲҶиҜҚеҷЁ";
Analyzer analyzer = null;
//ж ҮеҮҶеҲҶиҜҚеҷЁпјҢеҰӮжһңз”ЁжқҘеӨ„зҗҶдёӯж–ҮпјҢе’ҢChineseAnalyzerжңүдёҖж ·зҡ„ж•ҲжһңпјҢиҝҷд№ҹи®ёе°ұжҳҜд№ӢеҗҺзҡ„зүҲжң¬ејғз”ЁChineseAnalyzerзҡ„дёҖдёӘеҺҹеӣ
analyzer = new StandardAnalyzer(Version.LUCENE_43);
//第дёүж–№дёӯж–ҮеҲҶиҜҚеҷЁпјҢжңүдёӢйқў2дёӯжһ„йҖ ж–№жі•гҖӮ
analyzer = new IKAnalyzer();
analyzer = new IKAnalyzer(false);
analyzer = new IKAnalyzer(true);
//з©әж јеҲҶиҜҚеҷЁпјҢеҜ№еӯ—з¬ҰдёІдёҚеҒҡеҰӮдҪ•еӨ„зҗҶ
analyzer = new WhitespaceAnalyzer(Version.LUCENE_43);
//з®ҖеҚ•еҲҶиҜҚеҷЁпјҢдёҖж®өдёҖж®өиҜқиҝӣиЎҢеҲҶиҜҚ
analyzer = new SimpleAnalyzer(Version.LUCENE_43);
//дәҢеҲҶжі•еҲҶиҜҚеҷЁпјҢиҝҷдёӘеҲҶиҜҚж–№ејҸжҳҜжӯЈеҗ‘йҖҖдёҖеҲҶиҜҚ(дәҢеҲҶжі•еҲҶиҜҚ)пјҢеҗҢдёҖдёӘеӯ—дјҡе’Ңе®ғзҡ„е·Ұиҫ№е’ҢеҸіиҫ№з»„еҗҲжҲҗдёҖдёӘж¬ЎпјҢжҜҸдёӘдәәеҮәзҺ°дёӨж¬ЎпјҢйҷӨдәҶйҰ–еӯ—е’Ңжң«еӯ—
analyzer = new CJKAnalyzer(Version.LUCENE_43);
//е…ій”®еӯ—еҲҶиҜҚеҷЁпјҢжҠҠеӨ„зҗҶзҡ„еӯ—з¬ҰдёІеҪ“дҪңдёҖдёӘж•ҙдҪ“
analyzer = new KeywordAnalyzer();
//иў«еҝҪз•Ҙзҡ„иҜҚеҲҶиҜҚеҷЁ
analyzer = new StopAnalyzer(Version.LUCENE_43);
//дҪҝз”ЁеҲҶиҜҚеҷЁеӨ„зҗҶжөӢиҜ•еӯ—з¬ҰдёІ
StringReader reader = new StringReader(str);
TokenStream tokenStream = analyzer.tokenStream("", reader);
tokenStream.reset();
CharTermAttribute term = tokenStream.getAttribute(CharTermAttribute.class);
int l = 0;
//иҫ“еҮәеҲҶиҜҚеҷЁе’ҢеӨ„зҗҶз»“жһң
System.out.println(analyzer.getClass());
while(tokenStream.incrementToken()){
System.out.print(term.toString() + "|");
l += term.toString().length();
//еҰӮжһңдёҖиЎҢиҫ“еҮәзҡ„еӯ—ж•°еӨ§дәҺ30пјҢе°ұжҚўиЎҢиҫ“еҮә
if (l > 30) {
System.out.println();
l = 0;
}
}
}
}
жіЁпјҡдёҠиҝ°зЁӢеәҸеҜ№analyzerиҝӣиЎҢдәҶ9ж¬ЎиөӢеҖјпјҢиҮӘе·ұеҸҜд»ҘйҖҡиҝҮдёҖдёҖжіЁи§Јзҡ„еҪўејҸжҹҘзңӢжҜҸдёҖз§ҚеҲҶиҜҚжҠҖжңҜзҡ„еҲҶиҜҚж•ҲжһңгҖӮ
еҲҶиҜҚеҷЁд»Ӣз»Қ
дёӢйқўе°ҶдјҡеҜ№иҝҷдәӣеҲҶиҜҚеҷЁеҒҡдёҖдәӣз®ҖеҚ•зҡ„д»Ӣз»ҚпјҢд»ҘеҸҠдёҠиҝ°зЁӢеәҸеңЁиҜҘеҲҶиҜҚеҷЁдёӢзҡ„иҝҗиЎҢжҲӘеӣҫпјҡ
StandardAnalyzer
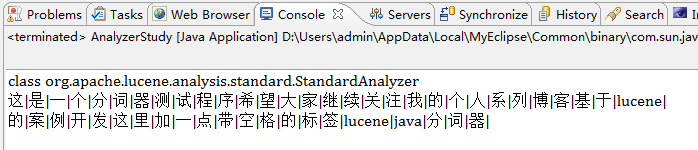
StandardAnalyzerж ҮеҮҶеҲҶиҜҚеҷЁпјҢеҰӮжһңз”ЁжқҘеӨ„зҗҶдёӯж–ҮпјҢе’ҢChineseAnalyzerжңүдёҖж ·зҡ„ж•ҲжһңпјҢиҝҷд№ҹи®ёе°ұжҳҜд№ӢеҗҺзҡ„зүҲжң¬ејғз”ЁChineseAnalyzerзҡ„дёҖдёӘеҺҹеӣ гҖӮз”ЁStandardAnalyzerеӨ„зҗҶиӢұж–Үж•ҲжһңиҝҳдёҚй”ҷпјҢдҪҶжҳҜеҜ№дёӯж–Үзҡ„еӨ„зҗҶеҸӘжҳҜе°Ҷе…¶еҲҶжҲҗеҚ•дёӘжұүеӯ—пјҢ并дёҚеӯҳеңЁд»»дҪ•иҜӯд№үжҲ–иҜҚжҖ§пјҢеҰӮжһңе®һеңЁжІЎжңүе…¶д»–зҡ„еҲҶиҜҚеҷЁпјҢз”ЁStandardAnalyzerжқҘеӨ„зҗҶдёӯж–ҮиҝҳжҳҜеҸҜд»Ҙзҡ„пјҢдёҠиҝ°дәӢдҫӢдҪҝз”ЁStandardAnalyzerеҲҶиҜҚжҠҖжңҜзҡ„иҝҗиЎҢз»“жһңеҰӮдёӢеӣҫпјҡ
IKAnalyzer
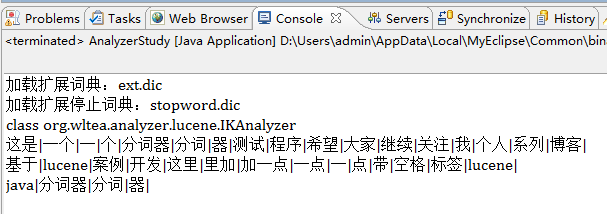
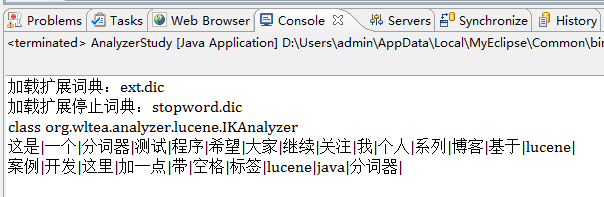
IKAnalyzerжҳҜеҹәдәҺLuceneзҡ„第дёүж–№дёӯж–ҮеҲҶиҜҚжҠҖжңҜпјҢиҜҘеҲҶиҜҚжҠҖжңҜеҹәдәҺзҺ°жңүзҡ„дёӯж–ҮиҜҚеә“е®һзҺ°зҡ„пјҢеңЁжһ„йҖ AnalyzerеҜ№иұЎж—¶жңүдёӨз§Қжһ„йҖ ж–№жі•пјҢж— еҸӮжһ„йҖ зӯүеҗҢдәҺnew IKAnalyzer(false) пјҢеңЁд»Ӣз»Қtrue/falseдёӨз§ҚеҸӮж•°дёӢеҲҶиҜҚеҷЁзҡ„дёҚеҗҢд№ӢеүҚе…ҲзңӢзңӢиҝҷдёӨз§Қжғ…еҶөдёӢзҡ„дәӢдҫӢиҝҗиЎҢз»“жһңпјҡ
falseиҝҗиЎҢз»“жһңеҰӮдёӢеӣҫпјҡ
trueиҝҗиЎҢз»“жһңеҰӮдёӢеӣҫпјҡ
д»ҺдёҠиҝ°дәӢдҫӢдёӯпјҢжҲ‘们еҸҜд»Ҙз®ҖеҚ•зҡ„зңӢеҮәпјҢfalseзҡ„жғ…еҶөдёӢдјҡеҜ№е·ІеҲҶзҡ„иҜҚиҝӣиЎҢеҶҚеҲҶпјҢеҰӮжһңеӯҳеңЁй•ҝеәҰиҫғе°Ҹзҡ„иҜҚе…ғпјҢд№ҹе°Ҷе…¶дҪңдёәдёҖдёӘеҲҶиҜҚз»“жһңгҖӮIKAnalyzerжҳҜдёҖз§ҚжҜ”иҫғеёёз”Ёзҡ„дёӯж–ҮеҲҶиҜҚжҠҖжңҜпјҢдҪҶжҳҜе…¶еҲҶиҜҚж•ҲжһңиҝҮдәҺдҫқиө–еӯ—е…ёпјҢжүҖд»ҘиҰҒдҪҝе…¶иҫҫеҲ°жӣҙеҘҪзҡ„ж•ҲжһңпјҢйңҖиҰҒдёҚж–ӯзҡ„еҚҮзә§иҮӘе·ұзҡ„еӯ—е…ёгҖӮ
WhitespaceAnalyzer
WhitespaceAnalyzerз©әж јеҲҶиҜҚпјҢиҝҷдёӘеҲҶиҜҚжҠҖжңҜе°ұзӣёеҪ“дәҺжҢүз…§з©әж јз®ҖеҚ•зҡ„еҲҮеҲҶеӯ—з¬ҰдёІпјҢеҜ№еҪўжҲҗзҡ„еӯҗдёІдёҚеҒҡе…¶д»–зҡ„ж“ҚдҪңпјҢз»“жһңеҗҢstring.split(" ")зҡ„з»“жһңзұ»дјјгҖӮдёҠиҝ°дәӢдҫӢеңЁWhitespaceAnalyzerеҲҶиҜҚжҠҖжңҜдёӢзҡ„иҝҗиЎҢз»“жһңеҰӮдёӢеӣҫпјҡ

иҝҷз§ҚеҲҶиҜҚжҠҖжңҜд№ҹи®ёдҪ дјҡз»қеҜ№жІЎжңүеӨӘеӨ§зҡ„дҪңз”ЁпјҢе®ғеҜ№иҫ“е…Ҙзҡ„еӯ—з¬ҰдёІеҮ д№ҺжІЎжңүеҒҡеӨӘеӨҡзҡ„еӨ„зҗҶпјҢеҜ№иҜӯеҸҘзҡ„еӨ„зҗҶз»“жһңд№ҹдёҚжҳҜеӨӘеҘҪпјҢеҰӮжһңиҝҷж ·жғіе°ұй”ҷдәҶпјҢдёӢйқўе°ұз®ҖеҚ•зҡ„жғідёҖдёӢиҝҷдёӘй—®йўҳпјҢиҝҷзҜҮеҚҡе®ўзҡ„ж ҮзӯҫжҳҜ luceneгҖҒjavaгҖҒеҲҶиҜҚеҷЁпјҢйӮЈиҝҷдёүдёӘиҜҚеңЁзҙўеј•дёӯеҸҲиҜҘеҰӮдҪ•зҡ„еӯҳеӮЁпјҢйҮҮз”ЁдҪ•з§ҚеҲҶиҜҚжҠҖжңҜе‘ўпјҹиҝҷйҮҢдёҚеҒҡд»»дҪ•и§Јзӯ”пјҢиҮӘе·ұжҖқиҖғдёӢпјҢеңЁд»ҘеҗҺзҡ„е°ҸиҜҙжЎҲдҫӢдёӯдјҡеҜ№ж ҮзӯҫиҝҷдёӘеҹҹжҸҗеҮәе…·дҪ“зҡ„и§ЈеҶіж–№жЎҲгҖӮ
SimpleAnalyzer
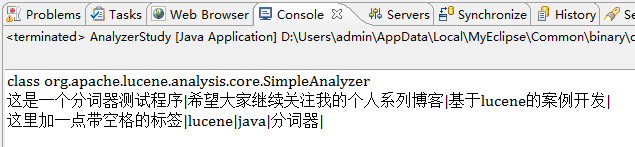
SimpleAnalyzerз®ҖеҚ•еҲҶиҜҚеҷЁпјҢдёҺе…¶иҜҙжҳҜдёҖж®өиҜқиҝӣиЎҢеҲҶиҜҚпјҢдёҚеҰӮиҜҙжҳҜдёҖеҸҘиҜқе°ұжҳҜдёҖдёӘиҜҚпјҢйҒҮеҲ°ж ҮзӮ№гҖҒз©әж јзӯүпјҢе°ұе°Ҷе…¶д№ӢеүҚзҡ„еҶ…е®№еҪ“дҪңдёҖдёӘиҜҚгҖӮдёҠиҝ°дәӢдҫӢеңЁSimpleAnalyzerеҲҶиҜҚжҠҖжңҜдёӢзҡ„иҝҗиЎҢз»“жһңеҰӮдёӢеӣҫпјҡ
CJKAnalyzer
CJKAnalyzerжҳҜдәҢеҲҶжі•еҲҶиҜҚеҷЁпјҢиҝҷдёӘеҲҶиҜҚж–№ејҸжҳҜжӯЈеҗ‘йҖҖдёҖеҲҶиҜҚ(дәҢеҲҶжі•еҲҶиҜҚ)пјҢеҗҢдёҖдёӘеӯ—дјҡе’Ңе®ғзҡ„е·Ұиҫ№е’ҢеҸіиҫ№з»„еҗҲжҲҗдёҖдёӘж¬ЎпјҢжҜҸдёӘдәәеҮәзҺ°дёӨж¬ЎпјҢйҷӨдәҶйҰ–еӯ—е’Ңжң«еӯ—пјҢд№ҹе°ұжҳҜиҜҙдјҡе°Ҷд»»дҪ•дёӨдёӘзӣёйӮ»зҡ„жұүеӯ—еҪ“дҪңжҳҜдёҖдёӘиҜҚпјҢиҝҷз§ҚеҲҶиҜҚжҠҖжңҜдјҡдә§з”ҹеӨ§йҮҸзҡ„ж— з”ЁиҜҚз»„гҖӮдёҠиҝ°дәӢдҫӢеңЁCJKAnalyzerеҲҶиҜҚжҠҖжңҜдёӢзҡ„иҝҗиЎҢз»“жһңеҰӮдёӢеӣҫпјҡ
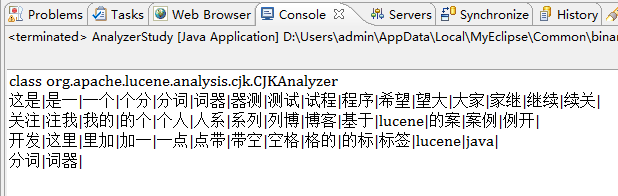
KeywordAnalyzer
KeywordAnalyzerе…ій”®еӯ—еҲҶиҜҚеҷЁпјҢжҠҠеӨ„зҗҶзҡ„еӯ—з¬ҰдёІеҪ“дҪңдёҖдёӘж•ҙдҪ“пјҢиҝҷдёӘеҲҶиҜҚеҷЁпјҢеңЁluceneд№ӢеүҚзҡ„зүҲжң¬дёӯжҲ–и®ёиҝҳжңүзӮ№дҪңз”ЁпјҢдҪҶжңҖиҝ‘зҡ„еҮ дёӘзүҲжң¬дёӯпјҢLuceneеҜ№еҹҹзҡ„зұ»еһӢеҒҡдәҶз»ҶеҲҶпјҢе®ғзҡ„дҪңз”Ёе°ұдёҚжҳҜеӨӘеӨ§дәҶпјҢдёҚеҒҡеңЁlukeдёӯпјҢиҝҳжҳҜзӣёеҪ“йҮҚиҰҒзҡ„гҖӮдёҠиҝ°дәӢдҫӢеңЁKeywordAnalyzerеҲҶиҜҚжҠҖжңҜдёӢзҡ„иҝҗиЎҢз»“жһңеҰӮдёӢеӣҫпјҡ

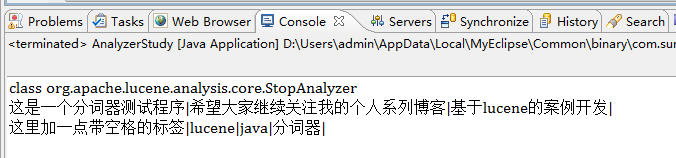
StopAnalyzer
StopAnalyzerиў«еҝҪз•Ҙзҡ„иҜҚеҲҶиҜҚеҷЁпјҢиў«еҝҪз•Ҙзҡ„иҜҚе°ұжҳҜеңЁеҲҶиҜҚз»“жһңдёӯпјҢиў«дёўејғзҡ„еӯ—з¬ҰдёІпјҢеҰӮж ҮзӮ№гҖҒз©әж јзӯүгҖӮдёҠиҝ°дәӢдҫӢеңЁStopAnalyzerеҲҶиҜҚжҠҖжңҜдёӢзҡ„иҝҗиЎҢз»“жһңеҰӮдёӢеӣҫпјҡ
дёҠиҝ°зҡ„7з§ҚеҲҶиҜҚжҠҖжңҜйғҪеҸҜд»ҘеҜ№дёӯж–ҮеҒҡеӨ„зҗҶпјҢеҜ№еӨ–ж–ҮпјҲйқһиӢұиҜӯпјүзҡ„еӨ„зҗҶжңүд»ҘдёӢеҮ з§ҚеҲҶиҜҚжҠҖжңҜпјҡ
BrazilianAnalyzer е·ҙиҘҝиҜӯиЁҖеҲҶиҜҚВ
CzechAnalyzer жҚ·е…ӢиҜӯиЁҖеҲҶиҜҚ
DutchAnalyzer иҚ·е…°иҜӯиЁҖеҲҶиҜҚ
FrenchAnalyzer жі•еӣҪиҜӯиЁҖеҲҶиҜҚ
GermanAnalyzer еҫ·еӣҪиҜӯиЁҖеҲҶиҜҚ
GreekAnalyzer еёҢи…ҠиҜӯиЁҖеҲҶиҜҚ
RussianAnalyzer дҝ„зҪ—ж–ҜиҜӯиЁҖеҲҶиҜҚ
ThaiAnalyzer жі°еӣҪиҜӯиЁҖеҲҶиҜҚ