

иҪ¬иҪҪиҜ·жіЁжҳҺеҮәеӨ„пјҡhttp://blog.csdn.net/xiaojimanman/article/details/43982653
http://www.llwjy.com/blogdetail/63d4c488a2cccb5851c0498d374951c9.html
дёӘдәәзҡ„еҚҡе®ўе°Ҹз«ҷд№ҹжҗӯе»әжҲҗеҠҹпјҢзҪ‘еқҖпјҡwww.llwjy.comВ пјҢж¬ўиҝҺеӨ§е®¶жқҘеҗҗж§Ҫ~
еҹәжң¬еҺҹзҗҶ
еңЁеүҚйқўзҡ„еҚҡе®ўдёӯд№ҹиҜҙиҝҮпјҢзЁӢеәҸеҲқе§ӢиҜқзҙўеј•ж–Ү件жҳҜеҚҒеҲҶж¶ҲиҖ—зі»з»ҹиө„жәҗзҡ„пјҢеӣ жӯӨиҰҒжғіе®һзҺ°е®һж—¶зҙўеј•е°ұдёҚиғҪе®һж—¶зҡ„еҺ»дҝ®ж”№зҙўеј•ж–Ү件гҖҒйҮҚж–°еҠ иҪҪзҙўеј•ж–Ү件пјҢе°ұеҝ…йЎ»иҖғиҷ‘еҰӮдҪ•дҪҝз”ЁеҶ…еӯҳжқҘе®һзҺ°иҝҷе®һж—¶зҙўеј•пјӣеңЁLucene4.3.1зүҲжң¬пјҲд№ӢеүҚзҡ„зүҲжң¬д№ҹжңүпјҢдҪҶжҳҜеңЁеҗҺйқўзҡ„зүҲжң¬дёӯе°ұе°ҶNRTзӣёе…ізҡ„зұ»еҲ йҷӨдәҶпјүдёӯNRTзӣёе…ізұ»е°ұжҸҗдҫӣдәҶеҲӣе»әе®һж—¶зҙўеј•пјҲдјӘе®һж—¶зҙўеј•пјүзҡ„зӣёе…іж–№жі•пјҢе°ҶIndexWriteзҡ„зӣёе…іж“ҚдҪң委жүҳз»ҷTrackingIndexWriterжқҘеӨ„зҗҶпјҢе®һзҺ°дәҶеҶ…еӯҳзҙўеј•е’ҢзЎ¬зӣҳзҙўеј•зҡ„з»“еҗҲпјҢйҖҡиҝҮNRTManagerдёәеӨ–йғЁжҸҗдҫӣеҸҜз”Ёзҡ„зҙўеј•пјҢеҪ“然пјҢеңЁжү§иЎҢcommitпјҲд№ӢеүҚеҲӣе»әзҙўеј•дёӯжңүзӣёе…ід»Ӣз»Қпјүж“ҚдҪңд№ӢеүҚпјҢж“ҚдҪңзҡ„ж•°жҚ®йғҪжҳҜеӯҳеңЁеҶ…еӯҳдёӯпјҢдёҖж—Ұе®•жңәжҲ–иҖ…жңҚеҠЎйҮҚпјҢиҝҷдәӣж•°жҚ®йғҪе°ҶдёўеӨұпјҢеӣ жӯӨе°ұйңҖиҰҒиҮӘе·ұж·»еҠ дёҖдёӘе®ҲжҠӨзәҝзЁӢеҺ»дёҚж–ӯзҡ„жү§иЎҢcommitж“ҚдҪңпјҲcommitж“ҚдҪңеҚҒеҲҶж¶ҲиҖ—зі»з»ҹиө„жәҗпјҢзҙўеј•дёҚеҸҜиғҪжҜҸдёҖж¬Ўдҝ®ж”№йғҪеҺ»жү§иЎҢиҜҘж“ҚдҪңпјүгҖӮдёӢйқўе°ұйҖҡиҝҮеҮ дёӘз®ҖеҚ•зҡ„еӣҫжқҘд»Ӣз»ҚдёҖдёӢе®һж—¶зҙўеј•зҡ„е®һзҺ°еҺҹзҗҶпјҡ
еңЁзі»з»ҹеҲҡеҗҜеҠЁж—¶еҖҷпјҢеӯҳеңЁдёӨдёӘзҙўеј•пјҡеҶ…еӯҳзҙўеј•гҖҒзЎ¬зӣҳзҙўеј•пјҢеҪ“然жӯӨж—¶еҶ…еӯҳзҙўеј•дёӯжҳҜжІЎжңүд»»дҪ•ж•°жҚ®зҡ„пјҢз»“жһ„еҰӮдёӢеӣҫжүҖзӨәпјҡ

еңЁзі»з»ҹиҝҗиЎҢиҝҮзЁӢдёӯпјҢдёҖж—Ұжңүзҙўеј•зҡ„еўһеҠ гҖҒеҲ йҷӨгҖҒдҝ®ж”№зӯүж“ҚдҪңпјҢиҝҷдәӣж“ҚдҪңйғҪжҳҜж“ҚдҪңеҶ…еӯҳзҙўеј•пјҢиҖҢдёҚжҳҜзЎ¬зӣҳзҙўеј•пјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
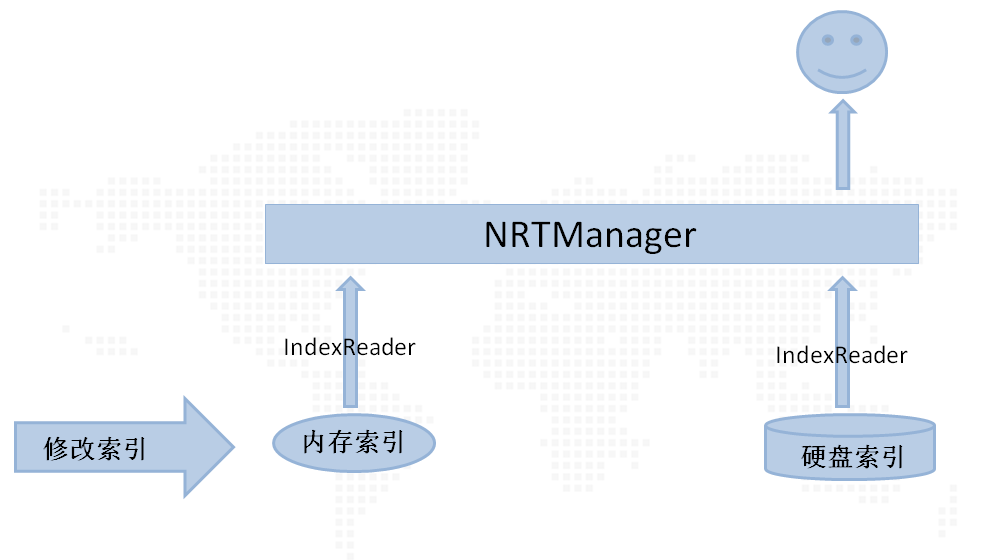
еҪ“зЁӢеәҸдё»еҠЁжү§иЎҢcommitж“ҚдҪңж—¶пјҢиҝҷжҳҜдјҡе°ҶеҶ…еӯҳзҙўеј•еӨҚеҲ¶дёҖд»ҪпјҢжҲ‘们称д№ӢдёәеҗҲ并зҙўеј•пјҢеҗҢж—¶е°ҶеҶ…еӯҳзҙўеј•жё…з©әпјҢз”ЁдәҺд№ӢеҗҺзҡ„зҙўеј•ж“ҚдҪңпјҢжӯӨж—¶зі»з»ҹдёӯе°ұеӯҳеңЁеҶ…еӯҳзҙўеј•гҖҒеҗҲ并зҙўеј•гҖҒзЎ¬зӣҳзҙўеј•пјҢеңЁжғіеӨ–жҸҗдҫӣжңҚеҠЎзҡ„еҗҢж—¶пјҢд№ҹдјҡе°ҶеҗҲ并зҙўеј•дёӯзҡ„ж•°жҚ®еҶҷе…ҘзЎ¬зӣҳпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
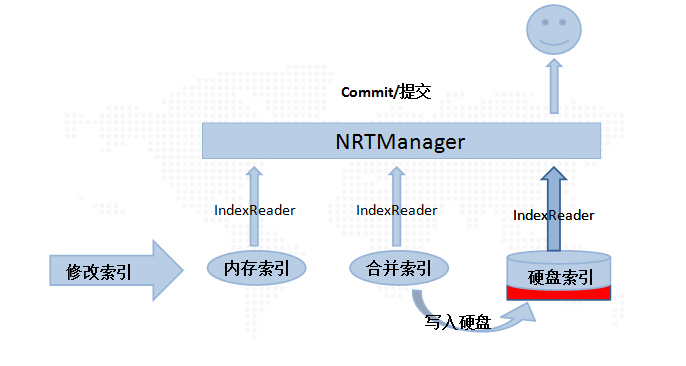
еҪ“еҗҲ并зҙўеј•дёӯзҡ„ж•°жҚ®е·Із»Ҹе…ЁйғЁеҶҷе…ҘзЎ¬зӣҳд№ӢеҗҺпјҢзЁӢеәҸдјҡеҜ№зЎ¬зӣҳзҙўеј•йҮҚиҜ»пјҢеҪўжҲҗж–°зҡ„IndexReaderпјҢеңЁж–°зҡ„зЎ¬зӣҳIndexReaderжӣҝжҚўж—§зҡ„зЎ¬зӣҳIndexReaderж—¶пјҢеҲ йҷӨеҗҲ并зҙўеј•зҡ„IndexReaderпјҢиҝҷж ·зі»з»ҹеҸҲйҮҚж–°еӣһеҲ°жңҖеҲқзҡ„зҠ¶жҖҒпјҲеҪ“然жӯӨж—¶еҶ…еӯҳзҙўеј•дёӯеҸҜиғҪдјҡжңүж•°жҚ®пјүпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
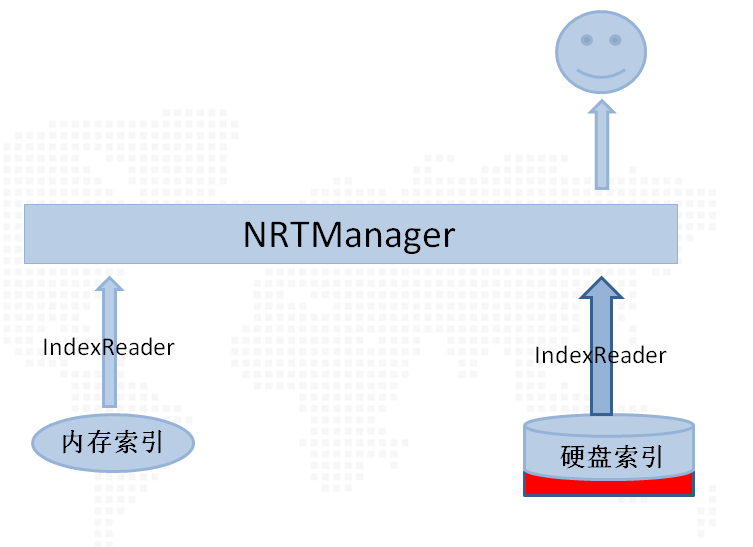
еҰӮжӯӨеҸҚеӨҚпјҢдёҖдёӘе®һж—¶зҙўеј•зҡ„зі»з»ҹд№ҹе°ұз®—е®ҢжҲҗдәҶпјҢеҪ“然иҝҷйҮҢд№ҹдјҡжңүдёҖе®ҡзҡ„йЈҺйҷ©пјҢе°ұжҳҜеңЁе®•жңәж—¶еҸҜиғҪдјҡдёўеӨұдёҖйғЁеҲҶзҡ„ж•°жҚ®гҖӮе…ідәҺиҝҷдёӘй—®йўҳпјҢеҰӮжһңж•°жҚ®еҮҶзЎ®еәҰиҰҒжұӮдёҚжҳҜеӨӘй«ҳзҡ„иҜқеҸҜд»ҘеҝҪз•ҘпјҢжҜ•з«ҹиҝҷз§Қжғ…еҶөеҸ‘з”ҹзҡ„жҰӮзҺҮеӨӘе°ҸдәҶпјӣеҰӮжһңеҜ№ж•°жҚ®зҡ„еҮҶзЎ®еәҰиҰҒжұӮзү№еҲ«й«ҳзҡ„иҜқпјҢеҸҜд»ҘйҖҡиҝҮж·»еҠ иҫ“еҮәж—Ҙеҝ—жқҘе®ҢжҲҗгҖӮ
psпјҡLuceneеҶ…йғЁзҡ„е®һзҺ°йҖ»иҫ‘жҜ”дёҠйқўеӨҚжқӮзҡ„еӨҡпјҢиҝҷйҮҢеҸӘжҳҜз®ҖеҚ•зҡ„д»Ӣз»ҚдёҖдёӢе®һзҺ°еҺҹзҗҶпјҢеҰӮиҰҒж·ұе…ҘдәҶи§ЈпјҢиҝҳиҜ·иҜҰз»Ҷйҳ…иҜ»зӣёе…ід№ҰзұҚгҖҒжәҗз ҒгҖӮ
й…ҚзҪ®зұ»
еңЁиҝҷзҜҮеҚҡе®ўдёӯе°ұе…ҲжҠҠиҝҷдёӘзі»еҲ—зҡ„е®һж—¶зҙўеј•зҡ„й…ҚзҪ®зұ»д»Ӣз»Қд»ҘдёӢпјҢеҗҺйқўе°ұдёҚеҶҚд»Ӣз»ҚдәҶгҖӮ
ConfigBean
ConfigBeanзұ»дёӯпјҢе®ҡд№үдәҶдёҖдәӣзҙўеј•зҡ„еҹәжң¬еұһжҖ§пјҢеҰӮпјҡзҙўеј•еҗҚгҖҒзЎ¬зӣҳеӯҳеӮЁдҪҚзҪ®гҖҒйҮҮз”Ёзҡ„еҲҶиҜҚеҷЁгҖҒcommitж“ҚдҪңжү§иЎҢйў‘зҺҮгҖҒеҶ…еӯҳзҙўеј•йҮҚиҜ»йў‘зҺҮзӯүпјҢе…·дҪ“д»Јз ҒеҰӮдёӢпјҡ
/**
*@Description: зҙўеј•еҹәзЎҖй…ҚзҪ®еұһжҖ§
*/
package com.lulei.lucene.index.model;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.util.Version;
public class ConfigBean {
// еҲҶиҜҚеҷЁ
private Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_43);
// зҙўеј•ең°еқҖ
private String indexPath = "/index/";
private double indexReopenMaxStaleSec = 10;
private double indexReopenMinStaleSec = 0.025;
// зҙўеј•commitж—¶й—ҙ
private int indexCommitSeconds = 60;
// зҙўеј•еҗҚз§°
private String indexName = "index";
//commitж—¶жҳҜеҗҰиҫ“еҮәзӣёе…ідҝЎжҒҜ
private boolean bprint = true;
public Analyzer getAnalyzer() {
return analyzer;
}
public void setAnalyzer(Analyzer analyzer) {
this.analyzer = analyzer;
}
public String getIndexPath() {
return indexPath;
}
public void setIndexPath(String indexPath) {
if (!(indexPath.endsWith("") || indexPath.endsWith("/"))) {
indexPath += "/";
}
this.indexPath = indexPath;
}
public double getIndexReopenMaxStaleSec() {
return indexReopenMaxStaleSec;
}
public void setIndexReopenMaxStaleSec(double indexReopenMaxStaleSec) {
this.indexReopenMaxStaleSec = indexReopenMaxStaleSec;
}
public double getIndexReopenMinStaleSec() {
return indexReopenMinStaleSec;
}
public void setIndexReopenMinStaleSec(double indexReopenMinStaleSec) {
this.indexReopenMinStaleSec = indexReopenMinStaleSec;
}
public int getIndexCommitSeconds() {
return indexCommitSeconds;
}
public void setIndexCommitSeconds(int indexCommitSeconds) {
this.indexCommitSeconds = indexCommitSeconds;
}
public String getIndexName() {
return indexName;
}
public void setIndexName(String indexName) {
this.indexName = indexName;
}
public boolean isBprint() {
return bprint;
}
public void setBprint(boolean bprint) {
this.bprint = bprint;
}
}
В
IndexConfig
еңЁдёҖдёӘзі»з»ҹдёӯ并дёҚдёҖе®ҡеҸӘеӯҳеңЁдёҖдёӘзҙўеј•пјҢд№ҹеҸҜиғҪдјҡжҳҜеӨҡдёӘпјҢжүҖд»ҘеҸҲж·»еҠ дәҶдёҖдёӘIndexConfigзұ»пјҢе…·дҪ“д»Јз ҒеҰӮдёӢпјҡ
/**
*@Description: зҙўеј•зҡ„зӣёе…ій…ҚзҪ®еҸӮж•°
*/
package com.lulei.lucene.index.model;
import java.util.HashSet;
public class IndexConfig {
//й…ҚзҪ®еҸӮж•°
private static HashSet<ConfigBean> configBean = null;
//й»ҳи®Өзҡ„й…ҚзҪ®
private static class LazyLoadIndexConfig {
private static final HashSet<ConfigBean> configBeanDefault = new HashSet<ConfigBean>();
static {
ConfigBean configBean = new ConfigBean();
configBeanDefault.add(configBean);
}
}
public static HashSet<ConfigBean> getConfigBean() {
//еҰӮжһңжңӘеҜ№IndexConfigеҲқе§ӢеҢ–пјҢеҲҷдҪҝз”Ёй»ҳи®Өй…ҚзҪ®
if (configBean == null) {
configBean = LazyLoadIndexConfig.configBeanDefault;
}
return configBean;
}
public static void setConfigBean(HashSet<ConfigBean> configBean) {
IndexConfig.configBean = configBean;
}
}
ps:жңҖиҝ‘еҸ‘зҺ°е…¶д»–зҪ‘з«ҷеҸҜиғҪдјҡеҜ№еҚҡе®ўиҪ¬иҪҪпјҢдёҠйқўе№¶жІЎжңүжәҗй“ҫжҺҘпјҢеҰӮжғіжҹҘзңӢжӣҙеӨҡе…ідәҺ еҹәдәҺluceneзҡ„жЎҲдҫӢејҖеҸ‘ иҜ·зӮ№еҮ»иҝҷйҮҢгҖӮжҲ–и®ҝй—®зҪ‘еқҖhttp://blog.csdn.net/xiaojimanman/article/category/2841877 жҲ–В http://www.llwjy.com/