

7.4 жӯЈеҲҷиҫҫиҫҫзӨәдёӯзҡ„жЁЎејҸдҝ®жӯЈз¬Ұ
жҲ‘们йҖҡиҝҮе…ғеӯ—з¬Ұе’ҢеҺҹеӯҗе®ҢжҲҗдәҶжӯЈеҲҷиЎЁиҫҫејҸзҡ„е…Ҙй—ЁгҖӮдҪҶжңүдёҖдәӣзү№ж®Ҡжғ…еҶөжҲ‘们дҫқ然йңҖиҰҒжқҘеӨ„зҗҶгҖӮ
еҰӮжһңabcеңЁз¬¬дәҢиЎҢзҡ„ејҖе§ӢеӨ„еҰӮдҪ•еҢ№й…Қпјҹ
жҲ‘дёҚеёҢжңӣжӯЈеҲҷиЎЁиҫҫзӨәзү№еҲ«иҙӘе©Әзҡ„еҢ№й…Қе…ЁйғЁпјҢеҸӘеҢ№й…ҚдёҖйғЁеҲҶжҖҺд№ҲеҠһпјҹ
иҝҷдёӘж—¶еҖҷпјҢжҲ‘们е°ұйңҖиҰҒз”ЁеҲ°дёӢйқўзҡ„иҝҷдәӣжЁЎејҸеҢ№й…ҚжқҘеўһејәжӯЈеҲҷзҡ„еҠҹиғҪгҖӮ
еёёз”Ёзҡ„жЁЎејҸеҢ№й…Қз¬Ұжңүпјҡ
| жЁЎејҸеҢ№й…Қз¬Ұ | еҠҹиғҪ |
|---|---|
| i | жЁЎејҸдёӯзҡ„еӯ—з¬Ұе°ҶеҗҢж—¶еҢ№й…ҚеӨ§е°ҸеҶҷеӯ—жҜҚ. |
| m | еӯ—з¬ҰдёІи§ҶдёәеӨҡиЎҢ |
| s | е°Ҷеӯ—з¬ҰдёІи§ҶдёәеҚ•иЎҢ,жҚўиЎҢз¬ҰдҪңдёәжҷ®йҖҡеӯ—з¬Ұ. |
| x | е°ҶжЁЎејҸдёӯзҡ„з©әзҷҪеҝҪз•Ҙ. |
| A | ејәеҲ¶д»…д»Һзӣ®ж Үеӯ—з¬ҰдёІзҡ„ејҖеӨҙејҖе§ӢеҢ№й…Қ. |
| D | жЁЎејҸдёӯзҡ„зҫҺе…ғе…ғеӯ—з¬Ұд»…еҢ№й…Қзӣ®ж Үеӯ—з¬ҰдёІзҡ„з»“е°ҫ. |
| U | еҢ№й…ҚжңҖиҝ‘зҡ„еӯ—з¬ҰдёІ. |
жЁЎејҸеҢ№й…Қз¬Ұзҡ„з”Ёжі•еҰӮдёӢпјҡ
/ жӯЈеҲҷиЎЁиҫҫзӨә/жЁЎејҸеҢ№й…Қз¬Ұ
жЁЎејҸеҢ№й…Қз¬ҰжҳҜж”ҫеңЁиҝҷеҸҘиҜқзҡ„жңҖеҗҺзҡ„гҖӮдҫӢеҰӮпјҡ
/w+/s
ж јејҸжҲ‘们清жҘҡдәҶпјҢжҺҘдёӢжқҘжңҖдё»иҰҒзҡ„жҳҜеҠ ејәеҜ№дәҺжЁЎејҸеҢ№й…Қз¬ҰдҪҝз”Ёзҡ„зҗҶи§Је’Ңи®°еҝҶгҖӮжҲ‘们йҖҡиҝҮд»Јз ҒжқҘзҗҶи§ЈеҠ дёҠе’ҢдёҚеҠ жЁЎејҸеҢ№й…Қз¬ҰжңүдҪ•еҢәеҲ«гҖӮ
i дёҚеҢәеҲҶеӨ§е°ҸеҶҷ
<?php
//еңЁеҗҺйқўеҠ дёҠдәҶдёҖдёӘi
$pattern = "/ABC/i";
$string = "8988abc12313";
$string1 = "11111ABC2222";
if(preg_match($pattern, $string, $matches)){
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($matches);
}else{
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
?>
з»“и®әпјҢдёҚи®әжҳҜ$stringиҝҳжҳҜ$string1е…ЁйғҪеҢ№й…ҚжҲҗеҠҹдәҶгҖӮеӣ жӯӨпјҢеңЁеҗҺйқўеҠ дёҠдәҶiд№ӢеҗҺпјҢеңЁеҢ№й…Қзҡ„ж—¶еҖҷеҸҜд»ҘдёҚеҢәеҲҶеӨ§е°ҸеҶҷгҖӮ
m и§ҶдёәеӨҡиЎҢ
жӯЈеҲҷеңЁеҢ№й…Қзҡ„ж—¶еҖҷпјҢиҰҒеҢ№й…Қзҡ„зӣ®ж Үеӯ—з¬ҰдёІжҲ‘们йҖҡеёёи§ҶдёәдёҖиЎҢгҖӮ
вҖңиЎҢиө·е§ӢвҖқе…ғеӯ—з¬ҰпјҲ^пјүд»…д»…еҢ№й…Қеӯ—з¬ҰдёІзҡ„иө·е§ӢпјҢвҖңиЎҢз»“жқҹвҖқе…ғеӯ—з¬ҰпјҲ$пјүд»…д»…еҢ№й…Қеӯ—з¬ҰдёІзҡ„з»“жқҹгҖӮ
еҪ“и®ҫе®ҡдәҶжӯӨдҝ®жӯЈз¬ҰпјҢвҖңиЎҢиө·е§ӢвҖқе’ҢвҖңиЎҢз»“жқҹвҖқйҷӨдәҶеҢ№й…Қж•ҙдёӘеӯ—з¬ҰдёІејҖеӨҙе’Ңз»“жқҹеӨ–пјҢиҝҳеҲҶеҲ«еҢ№й…Қе…¶дёӯзҡ„жҚўиЎҢз¬Ұзҡ„д№ӢеҗҺе’Ңд№ӢеүҚгҖӮ
жіЁж„ҸпјҡеҰӮжһңиҰҒеҢ№й…Қзҡ„еӯ—з¬ҰдёІдёӯжІЎжңүвҖң вҖқеӯ—з¬ҰжҲ–иҖ…жЁЎејҸдёӯжІЎжңү ^ жҲ– $пјҢеҲҷи®ҫе®ҡжӯӨдҝ®жӯЈз¬ҰжІЎжңүд»»дҪ•ж•ҲжһңгҖӮ
жҲ‘们йҖҡиҝҮе®һйӘҢе’Ңд»Јз ҒжқҘйӘҢиҜҒдёҖдёӢиҝҷдёӘзү№зӮ№пјҡ
第дёҖж¬ЎеҢ№й…ҚпјҢдҪ дјҡеҸ‘зҺ°еҢ№й…ҚдёҚжҲҗеҠҹпјҡ
<?php
$pattern = "/^ad+/";
$string = "жҲ‘зҡ„жңӘжқҘеңЁиҮӘе·ұжүӢдёӯжҲ‘йңҖиҰҒдёҚж–ӯзҡ„еҠӘеҠӣ
a9жҳҜдёҖдёӘдёҚй”ҷзҡ„еӯ—з¬ҰиЎЁзӨә
жҖҺд№ҲеҠһе‘ўпјҢе…¶е®һйңҖиҰҒдёҚж–ӯеҘӢиҝӣ";
if (preg_match($pattern, $string, $matches)) {
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($matches);
} else {
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
第дәҢж¬ЎеҢ№й…ҚпјҢжҲ‘们еҠ дёҠm иҜ•иҜ•пјҡ
<?php
$pattern = "/^ad+/m";
$string = "жҲ‘зҡ„жңӘжқҘеңЁиҮӘе·ұжүӢдёӯжҲ‘йңҖиҰҒдёҚж–ӯзҡ„еҠӘеҠӣ
a9жҳҜдёҖдёӘдёҚй”ҷзҡ„еӯ—з¬ҰиЎЁзӨә
жҖҺд№ҲеҠһе‘ўпјҢе…¶е®һйңҖиҰҒдёҚж–ӯеҘӢиҝӣ";
if (preg_match($pattern, $string, $matches)) {
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($matches);
} else {
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
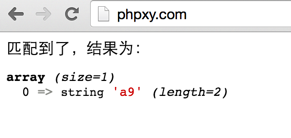
з»“жһңпјҡ
е“ҰиҖ¶пјҒеҢ№й…ҚжҲҗеҠҹдәҶгҖӮ/^ad+/ еҢ№й…Қзҡ„еҶ…е®№жҳҜa9пјҢеҝ…йЎ»еҫ—еңЁиЎҢејҖе§ӢеӨ„гҖӮеңЁз¬¬дәҢиЎҢд№ҹиў«еҢ№й…ҚжҲҗеҠҹдәҶгҖӮ
s и§ҶдёәдёҖиЎҢ
еҰӮжһңи®ҫе®ҡдәҶжӯӨдҝ®жӯЈз¬ҰпјҢжЁЎејҸдёӯзҡ„еңҶзӮ№е…ғеӯ—з¬ҰпјҲ.пјүеҢ№й…ҚжүҖжңүзҡ„еӯ—з¬ҰпјҢеҢ…жӢ¬жҚўиЎҢз¬ҰгҖӮ
第дёҖж¬ЎпјҢдёҚеҠ жЁЎејҸеҢ№й…Қз¬Ұsпјҡ
<?php
$pattern = "/ж–°зҡ„жңӘжқҘ.+d+/";
$string = "ж–°зҡ„жңӘжқҘ
987654321";
if (preg_match($pattern, $string, $matches)) {
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($matches);
} else {
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
?>
第дәҢж¬ЎпјҢеңЁжӯЈеҲҷиЎЁиҫҫзӨәеҗҺйқўеҠ дёҠжЁЎејҸеҢ№й…Қз¬Ұs:
<?php
$pattern = "/ж–°зҡ„жңӘжқҘ.+d+/s";
$string = "ж–°зҡ„жңӘжқҘ
987654321";
if (preg_match($pattern, $string, $matches)) {
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($matches);
} else {
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
?>
з»“жһңеҰӮдёӢпјҢеҢ№й…ҚжҲҗеҠҹпјҒ
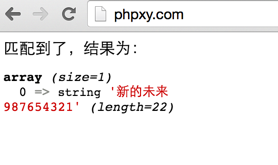
з»“и®әпјҡ
- еӣ дёәеңЁж–°зҡ„жңӘжқҘпјҢжңӘжқҘеҗҺйқўжңүдёҖдёӘжҚўиЎҢ
- иҖҢ.(зӮ№)жҳҜеҢ№й…Қйқһз©әзҷҪеӯ—з¬Ұд»ҘеӨ–зҡ„жүҖжңүеӯ—з¬ҰгҖӮеӣ жӯӨпјҢ第дёҖж¬ЎдёҚжҲҗеҠҹ
- 第дәҢж¬ЎпјҢеҠ дёҠдәҶsжЁЎејҸеҢ№й…Қз¬ҰгҖӮеӣ дёәпјҢеҠ дёҠеҗҺ.пјҲзӮ№пјүиғҪеҢ№й…ҚжүҖжңүеӯ—з¬ҰгҖӮ
x еҝҪз•Ҙз©әзҷҪеӯ—з¬Ұ
- еҰӮжһңи®ҫе®ҡдәҶжӯӨдҝ®жӯЈз¬ҰпјҢжЁЎејҸдёӯзҡ„з©әзҷҪеӯ—з¬ҰйҷӨдәҶиў«иҪ¬д№үзҡ„жҲ–еңЁеӯ—з¬Ұзұ»дёӯзҡ„д»ҘеӨ–е®Ңе…Ёиў«еҝҪз•ҘгҖӮ
- жңӘиҪ¬д№үзҡ„еӯ—з¬Ұзұ»еӨ–йғЁзҡ„#еӯ—з¬Ұе’ҢдёӢдёҖдёӘжҚўиЎҢз¬Ұд№Ӣй—ҙзҡ„еӯ—з¬Ұд№ҹиў«еҝҪз•ҘгҖӮ
жҲ‘们е…ҲжқҘе®һйӘҢдёҖдёӢеҝҪз•Ҙз©әзҷҪиЎҢзӯүзү№жҖ§пјҡ
<?php
$pattern = "/a b c /x";
$string = "еӯҰиӢұиҜӯиҰҒд»ҺabcејҖе§Ӣ";
if (preg_match($pattern, $string, $matches)) {
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($matches);
} else {
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
?>
иҝҷж ·д№ҹиғҪеҢ№й…ҚжҲҗеҠҹгҖӮ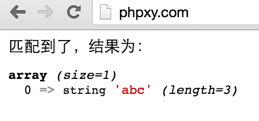
еңЁ$patternйҮҢйқўжңүз©әж јпјҢжҜҸдёӘabcеҗҺйқўжңүдёҖдёӘз©әж јгҖӮиҖҢ$stringйҮҢйқўжІЎжңүз©әж јгҖӮ
жүҖд»ҘxеҝҪз•Ҙз©әзҷҪеӯ—з¬ҰгҖӮ
иҖҢ第дәҢеҸҘиҜқд»Һеӯ—йқўдёҠжҜ”иҫғйҡҫзҗҶи§ЈпјҢ
<?php
//йҮҚзӮ№и§ӮеҜҹиҝҷдёҖиЎҢ
$pattern = "/a b c #жҲ‘жқҘеҶҷдёҖдёӘжіЁйҮҠ
/x";
$string = "еӯҰиӢұиҜӯиҰҒд»ҺabcејҖе§Ӣ";
if (preg_match($pattern, $string, $matches)) {
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($matches);
} else {
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
?>
з»“жһңд№ҹеҢ№й…ҚжҲҗеҠҹдәҶпјҒ
жҲ‘们еҸ‘зҺ°пјҢxзҡ„第дәҢдёӘзү№жҖ§жҳҜеҝҪз•Ҙпјҡ#еӯ—з¬Ұе’ҢдёӢдёҖдёӘжҚўиЎҢз¬Ұд№Ӣй—ҙзҡ„еӯ—з¬Ұд№ҹиў«еҝҪз•ҘгҖӮ
e е°ҶеҢ№й…ҚйЎ№жүҫеҮәжқҘпјҢиҝӣиЎҢжӣҝжҚў
eжЁЎејҸд№ҹеҸ«йҖҶеҗ‘еј•з”ЁгҖӮдё»иҰҒзҡ„еҠҹиғҪжҳҜе°ҶжӯЈеҲҷиЎЁиҫҫејҸжӢ¬еҸ·йҮҢзҡ„еҶ…е®№еҸ–еҮәжқҘпјҢж”ҫеҲ°жӣҝжҚўйЎ№йҮҢйқўжӣҝжҚўеҺҹеӯ—з¬ҰдёІгҖӮ
дҪҝз”ЁиҝҷдёӘжЁЎејҸеҢ№й…Қз¬ҰеүҚеҝ…йЎ»иҰҒдҪҝз”ЁеҲ°preg_replace()гҖӮ
mixed preg_replace ( mixed $жӯЈеҲҷеҢ№й…ҚйЎ№ , mixed $жӣҝжҚўйЎ№ , mixed $жҹҘжүҫеӯ—з¬ҰдёІ)
preg_replaceзҡ„еҠҹиғҪпјҡдҪҝз”Ё$жӯЈеҲҷеҢ№й…ҚйЎ№еҸҳпјҢжүҫеҲ°$жҹҘжүҫеӯ—з¬ҰдёІеҸҳйҮҸгҖӮ然еҗҺз”Ё$жӣҝжҚўйЎ№еҸҳйҮҸиҝӣиЎҢжӣҝжҚўгҖӮ
еңЁжӯЈејҸи®Іи§ЈеүҚжҲ‘们еӣһйЎҫдёҖдёӢд№ӢеүҚзҡ„зҹҘиҜҶпјҢжҲ‘们故ж„ҸжҠҠжҜҸдёӘиҰҒеҢ№й…Қзҡ„еҺҹеӯҗеӨ–йқўйғҪеҠ дёҠжӢ¬еҸ·пјҡ
<?php
//еҠ дёҠдәҶжӢ¬еҸ·
$pattern = "/(d+)([a-z]+)(d+)/";
$string = "987abc321";
if (preg_match($pattern, $string, $match)) {
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($match);
} else {
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
?>
жҲ‘们жқҘзңӢзңӢз»“жһңпјҡ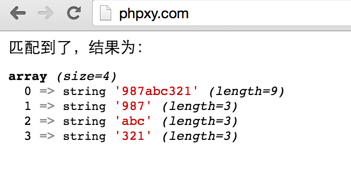
иҝҷжҳҜжҲ‘们д№ӢеүҚи®ІжӢ¬еҸ·зҡ„ж—¶еҖҷпјҡеҢ№й…ҚеҲ°зҡ„еҶ…е®№еӨ–йқўжңүжӢ¬еҸ·гҖӮдјҡжҠҠжӢ¬еҸ·йҮҢйқўзҡ„еҶ…е®№пјҢд№ҹж”ҫеҲ°ж•°з»„зҡ„е…ғзҙ йҮҢйқўгҖӮеҰӮеӣҫдёӯзҡ„пјҡ987гҖҒabcгҖҒ321гҖӮ
жҲ‘们жҺҘдёӢжқҘзңӢжӯЈеҲҷиЎЁиҫҫзӨәдёӯзҡ„eжЁЎејҸпјҡ
<?php
$string = "{April 15, 2003}";
//"w"еҢ№й…Қеӯ—жҜҚпјҢж•°еӯ—е’ҢдёӢеҲ’зәҝпјҢ"d"еҢ№й…Қ0-99ж•°еӯ—пјҢ"+"е…ғеӯ—з¬Ұ规е®ҡе…¶еүҚеҜјеӯ—з¬Ұеҝ…йЎ»еңЁзӣ®ж ҮеҜ№иұЎдёӯиҝһз»ӯеҮәзҺ°дёҖж¬ЎжҲ–еӨҡж¬Ў
$pattern = "/{(w+) (d+), (d+)}/i";
$replacement = "$2";
//еӯ—з¬ҰдёІиў«жӣҝжҚўдёәдёҺ第 n дёӘиў«жҚ•иҺ·зҡ„жӢ¬еҸ·еҶ…зҡ„еӯҗжЁЎејҸжүҖеҢ№й…Қзҡ„ж–Үжң¬
echo preg_replace($pattern, $replacement, $string);
?>
жҲ‘们зңӢзңӢжү§иЎҢз»“жһңпјҡ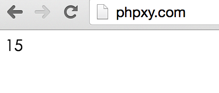
з»“и®әпјҡ
- дёҠдҫӢдёӯ$2 жҢҮеҗ‘зҡ„жҳҜжӯЈеҲҷиЎЁиҫҫзӨәзҡ„第дёҖдёӘ(d+)гҖӮзӣёеҪ“дәҺжҠҠ15еҸҲеҸ–еҮәжқҘдәҶ
- жӣҝжҚўзҡ„ж—¶еҖҷпјҢжҲ‘еҶҷдёҠ$2гҖӮе°ҶеҢ№й…ҚйЎ№еҸ–еҮәжқҘпјҢз”ЁжқҘеҶҚж¬ЎжӣҝжҚўеҢ№й…Қзҡ„з»“жһңгҖӮ
U иҙӘе©ӘжЁЎејҸжҺ§еҲ¶
жӯЈеҲҷиЎЁиҫҫејҸй»ҳи®ӨжҳҜиҙӘе©Әзҡ„пјҢд№ҹе°ұжҳҜе°ҪеҸҜиғҪзҡ„жңҖеӨ§йҷҗеәҰеҢ№й…ҚгҖӮ
жҲ‘们жқҘзңӢзңӢжӯЈеҲҷиЎЁиҫҫзӨәжҳҜеҰӮдҪ•иҙӘе©Әзҡ„пјҡ
<?php
$pattern = "/<div>.*</div>/";
$string = "<div>дҪ еҘҪ</div><div>жҲ‘жҳҜ</div>";
if (preg_match($pattern, $string, $match)) {
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($match);
} else {
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
?>
жҲ‘们жқҘзңӢзңӢз»“жһңпјҢеҫ—еҲ°еҰӮдёӢз»“и®әгҖӮе®ғд»ҺвҖң
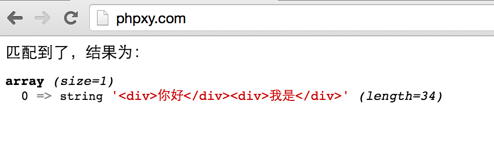
еҗҢж ·дёҖж®өд»Јз ҒжҲ‘们еҶҚеҠ еӨ§еҶҷзҡ„UпјҢеҶҚзңӢзңӢж•Ҳжһңпјҡ
<?php
$pattern = "/<div>.*</div>/U";
$string = "<div>дҪ еҘҪ</div><div>жҲ‘жҳҜ</div>";
if (preg_match($pattern, $string, $match)) {
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($match);
} else {
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
?>
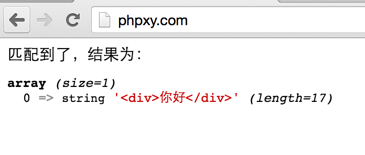
жҲ‘们еҸ‘зҺ°пјҢеҸӘеҢ№й…ҚеҮәжқҘдәҶпјҡ
<div>дҪ еҘҪ</div>
иҝҷж ·пјҢжҠҠжӯЈеҲҷзҡ„иҙӘе©Әзү№жҖ§еҸ–ж¶ҲжҺүгҖӮи®©е®ғжүҫеҲ°дәҶжңҖиҝ‘зҡ„еҢ№й…ҚпјҢе°ұOKдәҶгҖӮ
A д»Һзӣ®ж Үеӯ—з¬ҰдёІзҡ„ејҖеӨҙејҖе§ӢеҢ№й…Қ
жӯӨжЁЎејҸзұ»дјјдәҺе…ғеӯ—з¬Ұдёӯзҡ„^пјҲжҠ‘жү¬з¬Ұпјүж•ҲжһңгҖӮ
<?php
$pattern = "/this/A";
$string = "hello this is a ";
//$string1 = "this is a ";
if (preg_match($pattern, $string, $match)) {
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($match);
} else {
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
?>
з»“и®әпјҡ
- еҰӮжһңеҠ AжЁЎејҸдҝ®жӯЈз¬Ұзҡ„ж—¶еҖҷеҢ№й…ҚдёҚеҮәжқҘ$stringпјҢдёҚеҠ ж—¶иғҪеҢ№й…ҚеҮәжқҘ
- еҰӮжһңеҠ дёҠдәҶAжЁЎејҸдҝ®жӯЈз¬Ұзҡ„ж—¶еҖҷиғҪеҢ№й…ҚеҮәжқҘ$string1,еӣ дёәеҝ…йЎ»иҰҒд»ҺејҖе§ӢеӨ„ејҖе§ӢеҢ№й…Қ
D з»“жқҹ$з¬ҰеҗҺдёҚеҮҶжңүеӣһиҪҰ
еҰӮжһңи®ҫе®ҡдәҶжӯӨдҝ®жӯЈз¬ҰпјҢжЁЎејҸдёӯзҡ„зҫҺе…ғе…ғеӯ—з¬Ұд»…еҢ№й…Қзӣ®ж Үеӯ—з¬ҰдёІзҡ„з»“е°ҫгҖӮжІЎжңүжӯӨйҖүйЎ№ж—¶пјҢеҰӮжһңжңҖеҗҺдёҖдёӘеӯ—з¬ҰжҳҜжҚўиЎҢз¬Ұзҡ„иҜқпјҢзҫҺе…ғз¬ҰеҸ·д№ҹдјҡеҢ№й…ҚжӯӨеӯ—з¬Ұд№ӢеүҚгҖӮ
<?php
$pattern = "/w+this$/";
//$pattern1 = "/w+this$/D";
$string = "hellothis
";
if (preg_match($pattern, $string, $match)) {
echo "еҢ№й…ҚеҲ°дәҶпјҢз»“жһңдёәпјҡ";
var_dump($match);
} else {
echo "жІЎжңүеҢ№й…ҚеҲ°";
}
?>
з»“жһңеұ•зӨәпјҡ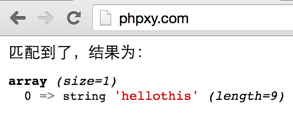
з»“и®әпјҡ
- еҰӮpattern еңЁеҢ№й…Қ$stringзҡ„ж—¶еҖҷпјҢ$stringзҡ„еӯ—з¬ҰдёІthisеҗҺжңүдёҖдёӘеӣһиҪҰгҖӮеңЁжІЎжңүеҠ DеҢ№й…Қз¬Ұзҡ„ж—¶еҖҷд№ҹиғҪеҢ№й…ҚжҲҗеҠҹ
- еҰӮpattern еңЁеҢ№й…Қ$stringзҡ„ж—¶еҖҷпјҢеҠ дёҠдәҶDгҖӮ$stringзҡ„еӯ—з¬ҰдёІthisеҗҺжңүз©әж јпјҢеҢ№й…ҚдёҚжҲҗеҠҹгҖӮ