

15.2 иЗ™еЃЪдєЙgetжЦєж≥ХжКУеПЦзљСй°µ
еБЗиЃЊжИСдїђдљњзФ®getжЦєж≥ХиѓЈж±ВдЄАдЄ™зљСй°µпЉМеЊЧеИ∞зљСй°µеЖЕеЃєеРОеПѓдї•еМєйЕНеЗЇеѓєеЇФзЪДеЖЕеЃєгАВ
жИСдїђеПѓдї•дљњзФ®curlе∞Би£ЕдЄАдЄ™еЗљжХ∞пЉМеБЗиЃЊеЗљжХ∞еРНе∞±дЄЇgetгАВдЉ†еЕ•urlе∞±иГљиѓЈж±ВжМЗеЃЪзЪДзљСй°µпЉМе∞ЖжМЗеЃЪзљСй°µзЪДHTMLдї£з†БињФеЫЮеЫЮжЭ•гАВдї£з†Бе¶ВдЄЛпЉЪ
function get($url) {
//еИЭдљњеМЦcurl
$ch = curl_init();
//иѓЈж±ВзЪДurlпЉМзԱ嚥еПВдЉ†еЕ•
curl_setopt($ch, CURLOPT_URL, $url);
//е∞ЖеЊЧеИ∞зЪДжХ∞жНЃињФеЫЮ
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
//дЄНе§ДзРЖе§ідњ°жБѓ
curl_setopt($ch, CURLOPT_HEADER, 0);
//ињЮжО•иґЕињЗ10зІТиґЕжЧґ
curl_setopt($ch, CURLOPT_TIMEOUT, 10);
//жЙІи°Мcurl
$output = curl_exec($ch);
//еЕ≥йЧ≠иµДжЇР
curl_close($ch);
//ињФеЫЮеЖЕеЃє
return $output;
}
жИСдїђзО∞еЬ®дљњзФ®жИСдїђжЙАеЖЩзЪДgetжЦєж≥ХпЉМиѓЈж±ВзљСжШУзЪДдЄАдЄ™еИЧи°®пЉМе∞Жж†ЗйҐШеТМurlжКУеПЦеЗЇжЭ•гАВ
жИСдїђеПѓдї•еЕИзФ®getжЦєж≥ХдЄ≠дЉ†еЕ•дЄАдЄ™URLгАВеЊЧеИ∞ињЩдЄ™зљСеЭАжЙАеѓєеЇФзљСй°µзЪДhtmlгАВ
зљСеЭАдЄЇжЦ∞е™ТдљУиІВеѓЯзљСзЪДжЦ∞йЧїеИЧи°®й°µпЉЪhttp://www.xmtnews.com/events
гАВ
е∞ЖзЇҐиЙ≤еМЇеЯЯйЗЗйЫЖдЄЛжЭ•пЉЪ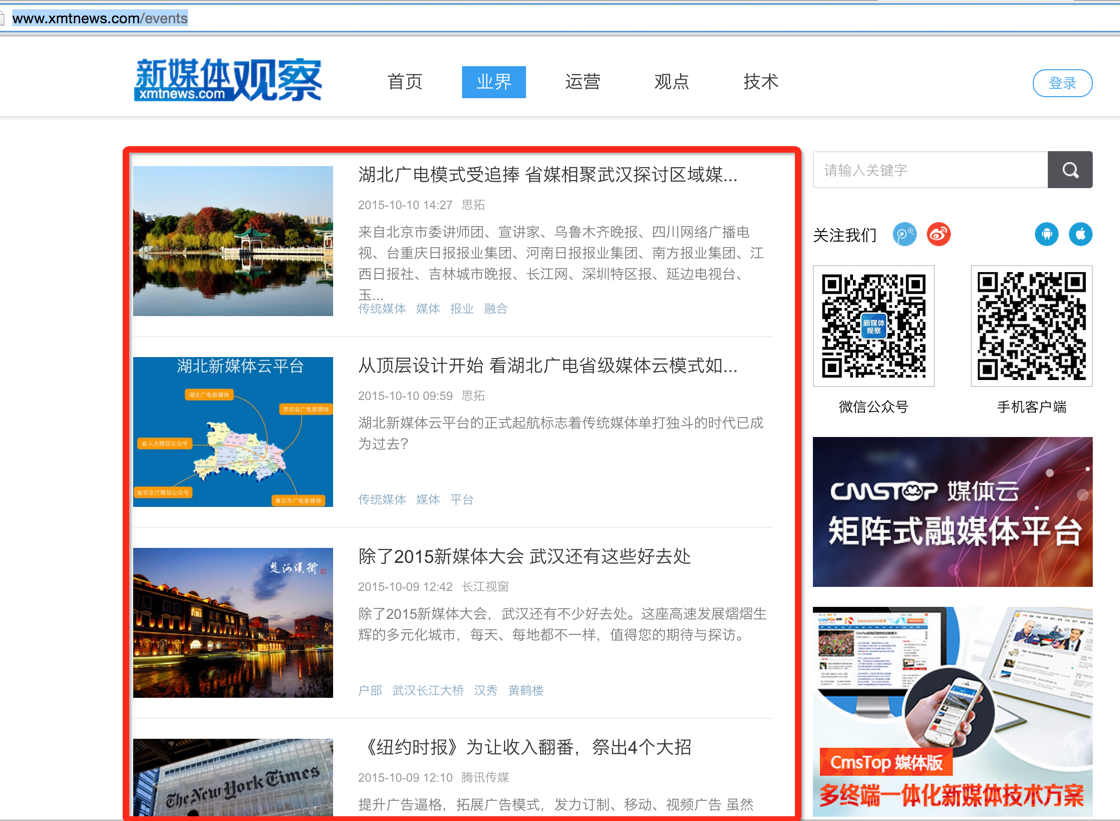
дЄАгАБеЊЧеИ∞ељ©зЇҐиЙ≤еМЇйЧізЪДhtml
ињЩдЄ™еМЇйЧідїОдЄЛйЭҐзЪДHTMLдї£з†БеЉАеІЛпЉЪ
<section class="ov">
еЬ®дї•дЄЛдї£з†БзїУжЭЯпЉЪ
<div class="hr-10"></div>
дљњзФ®preg_matchеЖЩдЄАдЄ™ж≠£еИЩи°®иЊЊз§Їе∞±еМєйЕНе∞±еЊЧеИ∞дЇЖзЇҐиЙ≤еМЇйЧізЪДHTMLгАВе∞ЖеМєйЕНеИ∞зЪДHTMLиµЛеАЉзїЩеПШйЗП$areaгАВ
еМєйЕНзЪДж≠£еИЩи°®иЊЊз§Їе¶ВдЄЛпЉЪ
<section class="ov">(.*?)<div class="hr-10"></div>/mis"
дЇМгАБеЬ®зЇҐиЙ≤еМЇеЯЯеМєйЕНж†ЗйҐШеТМж†ЗйҐШзЪДURL
жИСдїђеПСзО∞жЙАжЬЙзЪДж†ЗйҐШйГљеЬ®<h3>ж†Зз≠ЊйЗМйЭҐгАВжИСдїђдљњзФ®preg_match_allеЖЩдЄАдЄ™ж≠£еИЩи°®иЊЊз§ЇгАВ
preg_match_all("/<h3><a href="(.*?)" title=".*?" class="headers" target="_blank">(.*?)</a></h3>/mis", $area, $find);
е∞ЖurlеТМеЖЕеЃєеМєйЕНеЗЇжЭ•зЪДеЖЕеЃєжФЊзљЃеИ∞$findдЄ≠пЉМе∞Ж$findжХ∞зїДпЉМжЙУеН∞еЗЇжЭ•е∞±еПѓдї•зЬЛеИ∞еМєйЕНзЪДзїУжЮЬдЇЖгАВ
е¶ВжЮЬйЬАи¶БпЉМдєЯеПѓдї•еЊ™зОѓиѓїеПЦжШЊз§ЇжѓПдЄАи°Мж†ЗйҐШеТМжѓПдЄАи°МURLгАВ
еЕ®йГ®дї£з†БжЉФз§Їе¶ВдЄЛпЉЪ
<?php
$content = get("http://www.xmtnews.com/events");
preg_match("/<section class="ov">(.*?)<div class="hr-10"></div>/mis", $content, $match);
//е∞Жж≠£еИЩеМєйЕНеИ∞зЪДеЖЕеЃєиµЛеАЉзїЩ$area
$area = $match[1];
preg_match_all("/<h3><a href="(.*?)" title=".*?" class="headers" target="_blank">(.*?)</a></h3>/", $area, $find);
var_dump($find);
function get($url) {
//еИЭдљњеМЦcurl
$ch = curl_init();
//иѓЈж±ВзЪДurlпЉМзԱ嚥еПВдЉ†еЕ•
curl_setopt($ch, CURLOPT_URL, $url);
//е∞ЖеЊЧеИ∞зЪДжХ∞жНЃињФеЫЮ
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
//дЄНе§ДзРЖе§ідњ°жБѓ
curl_setopt($ch, CURLOPT_HEADER, 0);
//ињЮжО•иґЕињЗ10зІТиґЕжЧґ
curl_setopt($ch, CURLOPT_TIMEOUT, 10);
//жЙІи°Мcurl
$output = curl_exec($ch);
//еЕ≥йЧ≠иµДжЇР
curl_close($ch);
//ињФеЫЮеЖЕеЃє
return $output;
}