对象序列化的一个重要限制是它只是Java的解决方案:只有Java程序才能反序列化这种对象。一种更具操作性的解决方案是将数据转化为XML格式,这可以使其被各种各样的平台和语言使用。
1.简介
DOM 是用与平台和语言无关的方式表示XML文档的官方 W3C 标准。DOM 是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构, 然后才能做任何工作。 由于它是基于信息层次的,因而 DOM 被认为是基于树或基于对象的。DOM 以及广义的基于树的处理具有几个优点。首先,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改。
下面我们介绍一个具体的XML例子。
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book category="Java">
<title lang="chi">Java多线程编程核心技术</title>
<author>高洪岩</author>
<year>2015</year>
<price>69.00</price>
</book>
<book category="C++">
<title lang="en">Effective C++: 55 Specific Ways to Improve Your Programs and Designs</title>
<author>Scott Meyers</author>
<year>2006</year>
<price>58.00</price>
</book>
<book category="Web">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
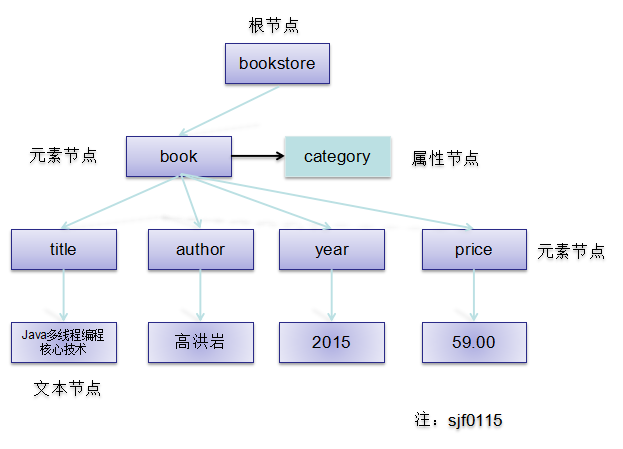
在上面的 XML 中,根节点是 。文档中的所有其他节点都被包含在 中。
根节点 有三个 节点。
第一个 节点有四个节点:, , 以及 ,其中每个节点都包含一个文本节点,"Java多线程编程核心技术", "高洪岩", "2015" 以及 "69.00"。
根据 DOM规定,XML 文档中的每个成分都是一个节点。
- 整个文档是一个文档节点
- 每个 XML 标签是一个元素节点
- 包含在 XML 元素中的文本是文本节点
- 每一个 XML 属性是一个属性节点
| 节点类型 | NodeType | Named Constant | NodeName的返回值 | NodeValue的返回值 |
|---|---|---|---|---|
| 元素节点 | 1 | ElEMENT_NODE | 元素节点名称(例如:title) | null |
| 属性节点 | 2 | ATTRIBUTE_NODE | 属性名称(例如:category) | 属性值(例如:Java) |
| 文本节点 | 3 | TEXT_NODE | #text | 节点内容 |
举例说明:
<title lang="chi">Java多线程编程核心技术</title>
以上可以得到一个元素节点(NodeType=1),调用getNodeName()方法得到节点名称"title",调用getNodeValue()方法得到null,而不是我们想象中的"Java多线程编程核心技术"。从元素节点得到一个子节点---文本节点(NodeType=3),调用getNodeName()方法得到"#text",调用getNodeValue方法得到"Java多线程编程核心技术"。另外,我们也可以通过元素节点得到属性节点(NodeType=2),调用getNodeName()方法得到"lang",调用getNodeValue方法得到"chi"。
注意:
文本总是存储在文本节点中。 在 DOM 处理中一个普遍的错误是,认为元素节点包含文本。实际上元素节点的文本是存储在文本节点中的。 在上面例子中:<title lang="chi">Java多线程编程核心技术</title> ,<title>是一个元素节点 ,并且拥有一个值为 "Java多线程编程核心技术" 的文本节点。不要误认为"Java 多线程编程核心技术" 是 <title> 元素节点的值。 |
2.节点树
DOM 把 XML 文档视为一种树结构(节点树)。我们可以通过这棵树访问所有节点,并且可以修改或删除它们的内容,也可以创建新的元素。节点树展示了节点的集合,以及它们之间的联系。
3.解析
(1)通过抽象工厂类DocumentBuilderFactory的静态方法newInstance获得一个工厂实例对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
(2)通过工厂实例对象获得一个DocumentBuilder对象
DocumentBuilder builder = factory.newDocumentBuilder();
(3)通过DocumentBuilder对象的parse方法加载XML文件进行解析转换为Document对象(注意:org.w3c.dom.Document)
Document document = builder.parse("D:ookstore.xml");
(4)通过Document对象的getElementsByTagName()方法获得元素节点集合
NodeList bookList = document.getElementsByTagName("book");
(5)通过元素节点集合获得元素节点
Node bookNode = bookList.item(i);
(6)通过元素节点可以获取元素节点所附属的属性节点集合以及属性节点
NamedNodeMap attriMap = bookNode.getAttributes();
// 通过item方法获取元素节点的属性节点
Node attriNode = attriMap.item(j);
(7)通过节点(元素节点,属性节点,文本节点)获得节点名称和节点值
// 获取元素节点类型
node.getNodeType();
// 获取元素节点名称
node.getNodeName();
// 获取元素节点值
node.getNodeValue();
我们解析上面XML文件:
package com.qunar.xml;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DomXmlCode {
public static void main(String[] args){
try {
// 创建一个DocumentBuilderFactory对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 创建DocumentBuilder对象
DocumentBuilder builder = factory.newDocumentBuilder();
// 解析XML文件获取Document对象(注意:org.w3c.dom.Document)
Document document = builder.parse("D:ookstore.xml");
// 获取所有book元素节点集合
NodeList bookList = document.getElementsByTagName("book");
// 遍历每一个book元素节点
int size = bookList.getLength();
System.out.println("一共有" + size + "本书籍...");
// 元素节点
for(int i = 0;i < size;++i){
// 通过item方法获取每一个book元素节点
Node bookNode = bookList.item(i);
// 获取book元素节点所有属性节点集合
NamedNodeMap attriMap = bookNode.getAttributes();
System.out.println("第" + (i+1) + "本书籍:");
int attriSize = attriMap.getLength();
System.out.println("---共有" + attriSize + "个属性");
// 属性
for(int j = 0;j < attriSize;++j){
// 通过item方法获取元素节点的属性节点
Node attriNode = attriMap.item(j);
// 获取属性节点属性类型
System.out.print("------type:" + attriNode.getNodeType());
// 获取属性节点属性名称
System.out.print(" name:" + attriNode.getNodeName());
// 获取属性节点属性值
System.out.println(" value:" + attriNode.getNodeValue());
}//for
// 如果知道元素节点有几个属性
/*Element element = (Element)bookList.item(i);
String attriValue = element.getAttribute("category");
System.out.println(" value:" + attriValue);*/
// 获取book元素节点的子节点集合
NodeList childNodeList = bookNode.getChildNodes();
int childSize = childNodeList.getLength();
System.out.println("---共有" + childSize + "个子节点(元素节点和文本节点):");
for(int k = 0;k < childSize;++k){
// 获取子节点
Node childNode = childNodeList.item(k);
// 区分Elemet类型节点和Text类型节点
if(childNode.getNodeType() == Node.ELEMENT_NODE){
// 获取元素子节点类型
System.out.print("------type:" + childNode.getNodeType());
// 获取元素子节点名称
System.out.print(" name:" + childNode.getNodeName());
// 获取元素子节点值
System.out.print(" value:" + childNode.getNodeValue());
// 我们误以为是子节点的值 其是是子节点的一个文本节点
System.out.print(" (sub-name:" + childNode.getFirstChild().getNodeName());
System.out.print(" sub-type:" + childNode.getFirstChild().getNodeType());
System.out.println(" sub-value:" + childNode.getFirstChild().getNodeValue() + ")");
}//if
}//for
}//for
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:
一共有3本书籍... 第1本书籍: ---共有1个属性 ------type:2 name:category value:Java ---共有9个子节点(元素节点和文本节点): ------type:1 name:title value:null (sub-name:#text sub-type:3 sub-value:Java多线程编程核心技术) ------type:1 name:author value:null (sub-name:#text sub-type:3 sub-value:高洪岩) ------type:1 name:year value:null (sub-name:#text sub-type:3 sub-value:2015) ------type:1 name:price value:null (sub-name:#text sub-type:3 sub-value:69.00) 第2本书籍: ---共有1个属性 ------type:2 name:category value:C++ ---共有9个子节点(元素节点和文本节点): ------type:1 name:title value:null (sub-name:#text sub-type:3 sub-value:Effective C++: 55 Specific Ways to Improve Your Programs and Designs) ------type:1 name:author value:null (sub-name:#text sub-type:3 sub-value:Scott Meyers) ------type:1 name:year value:null (sub-name:#text sub-type:3 sub-value:2006) ------type:1 name:price value:null (sub-name:#text sub-type:3 sub-value:58.00) 第3本书籍: ---共有1个属性 ------type:2 name:category value:Web ---共有9个子节点(元素节点和文本节点): ------type:1 name:title value:null (sub-name:subtitle sub-type:1 sub-value:null) ------type:1 name:author value:null (sub-name:#text sub-type:3 sub-value:Erik T. Ray) ------type:1 name:year value:null (sub-name:#text sub-type:3 sub-value:2003) ------type:1 name:price value:null (sub-name:#text sub-type:3 sub-value:39.95) |
注意:
com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: 1 字节的 UTF-8 序列的字节 1 无效。 at com.sun.org.apache.xerces.internal.impl.io.UTF8Reader.invalidByte(Unknown Source) at com.sun.org.apache.xerces.internal.impl.io.UTF8Reader.read(Unknown Source) at com.sun.org.apache.xerces.internal.impl.XMLEntityScanner.load(Unknown Source) at com.sun.org.apache.xerces.internal.impl.XMLEntityScanner.skipChar(Unknown Source) at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(Unknown Source) at com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(Unknown Source) at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(Unknown Source) at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(Unknown Source) at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(Unknown Source) at com.sun.org.apache.xerces.internal.parsers.XMLParser.parse(Unknown Source) at com.sun.org.apache.xerces.internal.parsers.DOMParser.parse(Unknown Source) at com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderImpl.parse(Unknown Source) at javax.xml.parsers.DocumentBuilder.parse(Unknown Source) at com.qunar.xml.DomXmlCode.main(DomXmlCode.java:24) 这个问题的主要原因是xml文件中声明的编码与xml文件本身保存时的编码不一致。比如你的声明是<?xml version="1.0" encoding="UTF-8"?> 但是却以ANSI格式编码保存,尽管并没有乱码出现,但是xml解析器是无法解析的。解决办法就是重新设置xml文件保存时的编码与声明的一致 |
childNode.getFirstChild().getNodeName()
我们也可以:
childNode.getTextContent()
但是以上两者还是有一定的区别:
对于一下XML解析时:
<title lang="en"><subtitle>XML</subtitle>Learning XML</title>
第一种方法(getFirstChild)会得到null,而第二种方法会得到XML Learning XML。
4.添加节点
(1)通过Document对象创建一个节点
Element bookNode = document.createElement("book");
(2)为节点设置属性
// 添加属性
bookNode.setAttribute("category", "Java");
还有另外一种方法,先创建一个属性节点,然后为元素节点设置属性节点
// 添加节点title
Element titleNode = document.createElement("title");
// 添加属性(第二种方法:先创建一个属性节点,设置名称和值)
Attr langAttr = document.createAttribute("lang");
langAttr.setNodeValue("chi");
titleNode.setAttributeNode(langAttr);
(3)把创建的节点添加到根节点中
// 获取根节点
Element rootNode = document.getDocumentElement();
// bookNode节点插入节点树中
rootNode.appendChild(bookNode);
具体实例:
package com.qunar.xml;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Attr;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.xml.sax.SAXException;
public class DomXmlCode {
public static void outputToXml(Node node, String filename) {
try {
TransformerFactory transFactory = TransformerFactory.newInstance();
Transformer transformer = transFactory.newTransformer();
// 设置各种输出属性
transformer.setOutputProperty("encoding", "utf-8");
transformer.setOutputProperty("indent", "yes");
DOMSource source = new DOMSource();
// 将待转换输出节点赋值给DOM源模型的持有者(holder)
source.setNode(node);
StreamResult result = new StreamResult();
if (filename == null) {
// 设置标准输出流为transformer的底层输出目标
result.setOutputStream(System.out);
}//if
else {
result.setOutputStream(new FileOutputStream(filename));
}//else
// 执行转换从源模型到控制台输出流
transformer.transform(source, result);
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
public static void main(String[] args){
try {
// 创建一个DocumentBuilderFactory对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 创建DocumentBuilder对象
DocumentBuilder builder = factory.newDocumentBuilder();
// 解析XML文件获取Document对象(注意:org.w3c.dom.Document)
Document document = builder.parse("D:ookstore.xml");
// 获取根节点
Element rootNode = document.getDocumentElement();
// 1. 添加节点book
Element bookNode = document.createElement("book");
// 添加属性
bookNode.setAttribute("category", "Java");
// 添加节点title
Element titleNode = document.createElement("title");
// 添加属性(第二种方法:先创建一个属性节点,设置名称和值)
Attr langAttr = document.createAttribute("lang");
langAttr.setNodeValue("chi");
titleNode.setAttributeNode(langAttr);
// 设置文本内容
titleNode.setTextContent("Java并发编程实战");
// 设置为bookNode的子节点
bookNode.appendChild(titleNode);
// 添加节点author
Element authorNode = document.createElement("author");
// 设置文本内容
authorNode.setTextContent("Brian Goetz");
// 设置为bookNode的子节点
bookNode.appendChild(authorNode);
// 添加节点price
Element priceNode = document.createElement("price");
// 设置文本内容
priceNode.setTextContent("69.00");
// 设置为bookNode的子节点
bookNode.appendChild(priceNode);
// bookNode节点插入节点树中
rootNode.appendChild(bookNode);
outputToXml(rootNode,"D:ookstore.xml");
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:
<?xml version="1.0" encoding="utf-8"?><bookstore>
<book category="Java">
<title lang="chi">Java多线程编程核心技术</title>
<author>高洪岩</author>
<year>2015</year>
<price>69.00</price>
</book>
<book category="C++">
<title lang="en">Effective C++: 55 Specific Ways to Improve Your Programs and Designs</title>
<author>Scott Meyers</author>
<year>2006</year>
<price>58.00</price>
</book>
<book category="Web">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="Java">
<title lang="chi">Java并发编程实战</title>
<author>Brian Goetz</author>
<price>69.00</price>
</book>
</bookstore>
我们可以看到添加了一个book元素节点。
5.查找修改节点
package com.qunar.xml;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Attr;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DomXmlCode {
public static void outputToXml(Node node, String filename) {
try {
TransformerFactory transFactory = TransformerFactory.newInstance();
Transformer transformer = transFactory.newTransformer();
// 设置各种输出属性
transformer.setOutputProperty("encoding", "utf-8");
transformer.setOutputProperty("indent", "yes");
DOMSource source = new DOMSource();
// 将待转换输出节点赋值给DOM源模型的持有者(holder)
source.setNode(node);
StreamResult result = new StreamResult();
if (filename == null) {
// 设置标准输出流为transformer的底层输出目标
result.setOutputStream(System.out);
}//if
else {
result.setOutputStream(new FileOutputStream(filename));
}//else
// 执行转换从源模型到控制台输出流
transformer.transform(source, result);
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
public static void main(String[] args){
try {
// 创建一个DocumentBuilderFactory对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 创建DocumentBuilder对象
DocumentBuilder builder = factory.newDocumentBuilder();
// 解析XML文件获取Document对象(注意:org.w3c.dom.Document)
Document document = builder.parse("D:ookstore.xml");
// 获取根节点
Element rootNode = document.getDocumentElement();
// book集合
NodeList bookList = document.getElementsByTagName("book");
// 第四本书
Node bookNode = bookList.item(3);
// 修改属性
NamedNodeMap attrMap = bookNode.getAttributes();
Node attrNode = attrMap.item(0);
attrNode.setNodeValue("Hadoop");
// title子节点集合
NodeList titleList = document.getElementsByTagName("title");
// title子节点
Node titleNode = titleList.item(3);
titleNode.setTextContent("Hadoop权威指南");
// author子节点集合
NodeList authorList = document.getElementsByTagName("author");
// author子节点
Node authorNode = authorList.item(3);
authorNode.setTextContent("周敏奇");
// price子节点集合
NodeList priceList = document.getElementsByTagName("price");
// price子节点
Node priceNode = priceList.item(3);
priceNode.setTextContent("79");
outputToXml(rootNode,"D:ookstore.xml");
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:
<?xml version="1.0" encoding="utf-8"?><bookstore>
<book category="Java">
<title lang="chi">Java多线程编程核心技术</title>
<author>高洪岩</author>
<year>2015</year>
<price>69.00</price>
</book>
<book category="C++">
<title lang="en">Effective C++: 55 Specific Ways to Improve Your Programs and Designs</title>
<author>Scott Meyers</author>
<year>2006</year>
<price>58.00</price>
</book>
<book category="Web">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="Hadoop">
<title lang="chi">Hadoop权威指南</title>
<author>周敏奇</author>
<price>79</price>
</book>
</bookstore>
6.删除节点
package com.qunar.xml;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Attr;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class DomXmlCode {
public static void outputToXml(Node node, String filename) {
try {
TransformerFactory transFactory = TransformerFactory.newInstance();
Transformer transformer = transFactory.newTransformer();
// 设置各种输出属性
transformer.setOutputProperty("encoding", "utf-8");
transformer.setOutputProperty("indent", "yes");
DOMSource source = new DOMSource();
// 将待转换输出节点赋值给DOM源模型的持有者(holder)
source.setNode(node);
StreamResult result = new StreamResult();
if (filename == null) {
// 设置标准输出流为transformer的底层输出目标
result.setOutputStream(System.out);
}//if
else {
result.setOutputStream(new FileOutputStream(filename));
}//else
// 执行转换从源模型到控制台输出流
transformer.transform(source, result);
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
public static void main(String[] args){
try {
// 创建一个DocumentBuilderFactory对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 创建DocumentBuilder对象
DocumentBuilder builder = factory.newDocumentBuilder();
// 解析XML文件获取Document对象(注意:org.w3c.dom.Document)
Document document = builder.parse("D:ookstore.xml");
// 获取根节点
Element rootNode = document.getDocumentElement();
// book集合
NodeList bookList = document.getElementsByTagName("book");
// 第三本书
Node book3Node = bookList.item(2);
// year节点集合
NodeList yearList = document.getElementsByTagName("year");
// 删除第三本书的第三个子节点(year)
book3Node.removeChild(yearList.item(2));
// 第四本书
Node book4Node = bookList.item(3);
// 删除第四本书
rootNode.removeChild(book4Node);
outputToXml(rootNode,"D:ookstore.xml");
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:
<?xml version="1.0" encoding="utf-8"?><bookstore>
<book category="Java">
<title lang="chi">Java多线程编程核心技术</title>
<author>高洪岩</author>
<year>2015</year>
<price>69.00</price>
</book>
<book category="C++">
<title lang="en">Effective C++: 55 Specific Ways to Improve Your Programs and Designs</title>
<author>Scott Meyers</author>
<year>2006</year>
<price>58.00</price>
</book>
<book category="Web">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<price>39.95</price>
</book>
</bookstore>