目录
资料库通常是用来储存庞大数量的资料,这也是它最善长跟主要的工作,所以查询并计算资料的统计分析资讯也是一种很常见的需求:

你也可能会进一步的查询更详细的统计与分析资讯:
3.1 群组函式
想要完成上列讨论的统计与分析查询,你会用到下列的「群组函式」:
- MAX(运算式):最大值
- MIN(运算式):最小值
- SUM(运算式):合计
- AVG(运算式):平均
- COUNT([DISTINCT]|运算式):使用「DISTINCT」时,重复的资料不会计算;使用[]时,计算表格纪录的数量:使用[运算式]时,计算的数量不会包含「NULL」值
使用上列的群组函式可以很容易的查询需要的统计与分析资讯:

这些函式套用在数值资料时会比较明确一些,把它们用在日期资料也是可以完成「员工最早和最晚进公司的日期」的查询需求:

在这些群组函式中,「COUNT」函式的用法会比较不一样:

利用「COUNT」函式的特性,也可以查询一些特别的资讯:

3.2 GROUP_CONCAT函式
「GROUP_CONCAT」函式是比较特别的一个群组函式,它用来将一些字串资料「串接」起来。在执行一般查询的时候,会根据查询的资料,将许多纪录传回来给你:
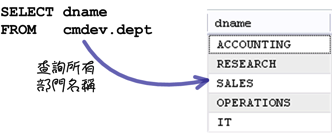
使用「GROUP_CONCAT」函式的话,只会回传一笔纪录,这笔纪录包含所有字串资料串接起来的内容:

下列是「GROUP_CONCAT」函式的语法:
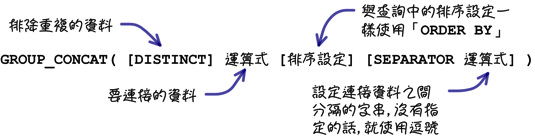
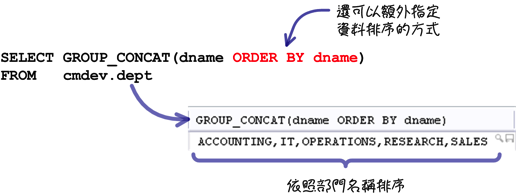
上列的范例是「GROUP_CONCAT」函式最简单的用法,你还可以在函式中使用与「ORDER BY」子句一样的用法来指定资料的排列顺序:
「GROUP_CONCAT」函式连接字串的时候,预设是使用逗号分隔资料,你可以自己指定分隔的字串:

在「GROUP_CONCAT」函式中还可以使用类似在「基础查询、限制查询」中讨论过的「DISTINCT」来排除重复的资料,例如:
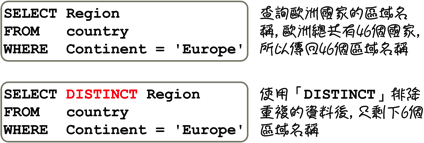
在「GROUP_CONCAT」函式中使用「DISTINCT」也会有同样的效果:

3.3 GROUP BY与HAVING子句
在上列使用群组函式的所有范例中,都是将「FROM」子句中指定的表格当成是一整个「群组」,群组函式所处理的资料是表格中所有的纪录。如果希望依照指定的资料来计算分组统计与分析资讯,在执行查询的时候,可能会有下列几种不同的结果:
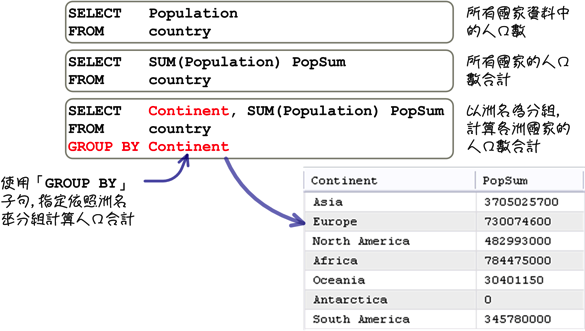
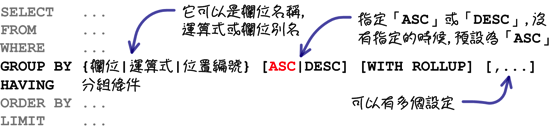
上列的范例使用「GROUP BY」子句指定分组的设定,下列是分组查询中的语法:
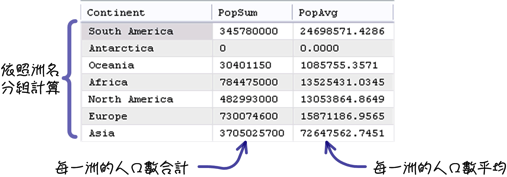
「GROUP BY」子句指定是依照你自己的需求来决定的,同样以人口数量合计来说,不同的指定可以得到不同的统计资讯:

使用不同的群组函式,就可以得不同的资讯:
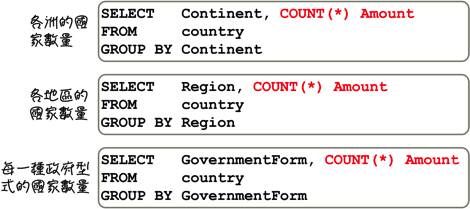
如果需要的话,你可以在一个查询中,一次取得所有需要的统计与分析资讯:

在查询群组统计与分析资讯的时候,你可以指定多个群组设定取得更详细的资讯:
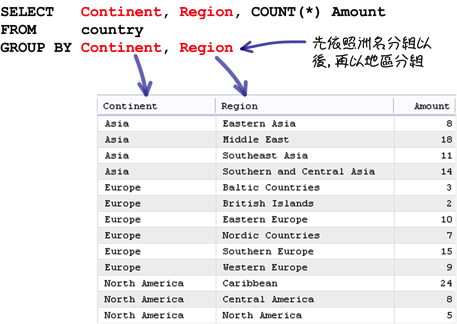
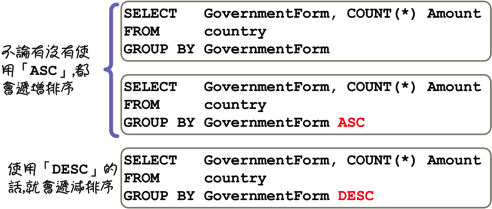
使用「GROUP BY」指定群组的设定以后,回传的群组查询资料都会依照指定的群组排序,预设定排序方式是递增排序,使用「DESC」关键字可以指定排序的方式为递减排序:
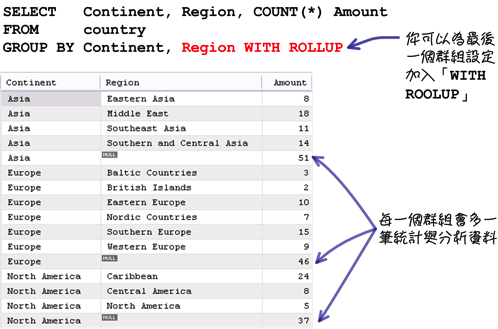
使用「GROUP BY」子句的时候可以搭配「WITH ROLLUP」:

使用「WITH ROLLUP」以后,效果会作用在查询中的每一个群组函式:

在「GROUP BY」子句中有多个群组设定的时候,你可以在最后面加入「WITH ROLLUP」:
在执行群组查询的时候,一般的条件设定同样使用「WHERE」子句就可以了:

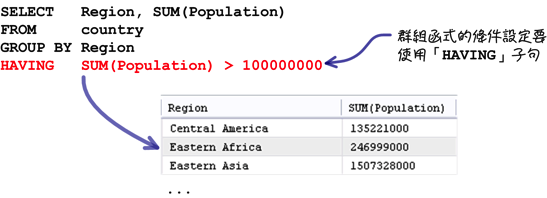
可是以类似上列的查询来说,把查询条件从「亚洲的地区」换成「人口合计大于一亿的地区」,如果还是把条件设定放在「WHERE」子句的话:

包含群组函式的条件设定就一定要放在「HAVING」子句中
依照需求在执行群组查询的时候,应该不会出现下列的查询叙述:
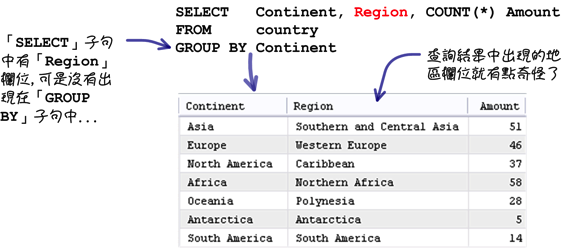
MySQL资料库在执行上列的查询叙述后,并不会产生任何错误,为了预防这样的状况,你可以执行下列的设定:
SET sql_mode = "ONLY_FULL_GROUP_BY"
在「sql_mode」的设定中加入「ONLY_FULL_GROUP_BY」,表示多了下列的规定:

如果查询叙述违反「ONLY_FULL_GROUP_BY」的规定,就会产生错误讯息:
