转载请注明出处:http://blog.csdn.net/xiaojimanman/article/details/44854719
http://www.llwjy.com/blogdetail/ddcad68eeb91034247ffa331eb461213.html
个人博客站已经上线了,网址 www.llwjy.com ~欢迎各位吐槽~
在上两篇博客中,已经介绍了纵横中文小说的更新列表页和简介页内容的采集,这篇将介绍从简介页采集获得的下一跳章节列表页的信息采集,事例地址:http://book.zongheng.com/showchapter/362857.html
页面分析
通过对页面的分析,我们可以确定下图中的部分就是我们需要采集信息及下一跳的地址。

这里当我们想用鼠标右键--查看网页源代码的时候发现页面已经把鼠标右键这个操作屏蔽了,因此我们只能采用另一种办法来查看源代码,对页面进行分析。在当前页面,按下F12,会出现一个新窗口,也就是之前博客中提到的审查元素出现的窗口,选中Network选项卡,按下 Ctrl + F5,会出现如下画面:
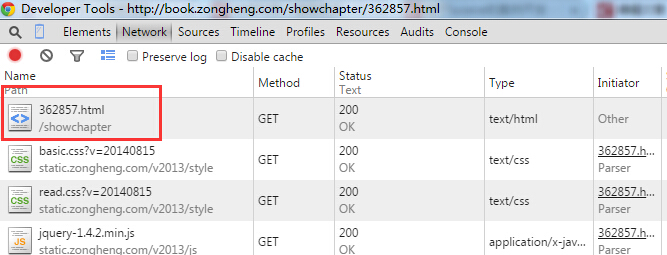
鼠标单机红色选中部分,即可查看网页源代码,效果图如下:
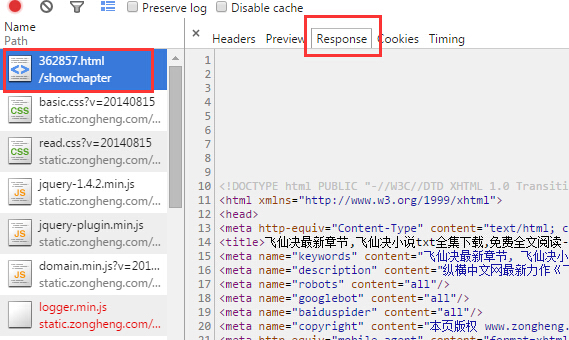
对网页源代码做简单的分析,我们很容易找到章节信息所在的部分,如下图:

每一个章节信息都存储在td标签内,因此对这部分信息我们确定最后的正则表达式为“
”。对于章节列表也信息的采集我们采用和简介页相同的方法,创建一个CrawlBase子类,用它来完成相关信息的采集。对于请求伪装等操作参照更新列表页中的介绍,这里只介绍DoRegex类中的一个方法:
List<String[]> getListArray(String dealStr, String regexStr, int[] array)
第一个参数是需要查询的字符串,第二个参数是正则表达式,第三个是需要提取的信息在正则表达式中的定位,函数的整体功能是返回字符串中所有满足条件的信息。
/**
*@Description: 章节列表页
*/
package com.lulei.crawl.novel.zongheng;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import com.lulei.crawl.CrawlBase;
import com.lulei.util.DoRegex;
public class ChapterPage extends CrawlBase {
private static final String CHAPTER = "<td class="chapterBean" chapterId="d*" chapterName="(.*?)" chapterLevel="d*" wordNum="(.*?)" updateTime="(.*?)"><a href="(.*?)" title=".*?">";
private static final int []ARRAY = {1, 2, 3, 4};
private static HashMap<String, String> params;
/**
* 添加相关头信息,对请求进行伪装
*/
static {
params = new HashMap<String, String>();
params.put("Referer", "http://book.zongheng.com");
params.put("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36");
}
public ChapterPage(String url) throws IOException {
readPageByGet(url, "utf-8", params);
}
public List<String[]> getChaptersInfo() {
return DoRegex.getListArray(getPageSourceCode(), CHAPTER, ARRAY);
}
public static void main(String[] args) throws IOException {
ChapterPage chapterPage = new ChapterPage("http://book.zongheng.com/showchapter/362857.html");
for (String []ss : chapterPage.getChaptersInfo()) {
for (String s : ss) {
System.out.println(s);
}
System.out.println("---------------------------------------------------- ");
}
}
}
ps:最近发现其他网站可能会对博客转载,上面并没有源链接,如想查看更多关于 请。或访问网址 或