
HTTP基本原理(浏览器缓存)
原文:http://blog.csdn.net/hguisu/article/details/8683290
浏览器缓存:包括页面html缓存和图片js,css等资源的缓存。如下图,浏览器缓存是基于把页面信息保存到用户本地电脑硬盘里。
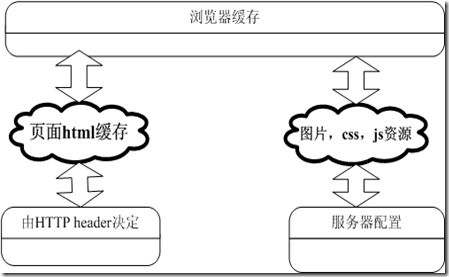
1、缓存的优点:
1)服务器响应更快:因为请求从缓存服务器(离客户端更近)而不是源服务器被相应,这个过程耗时更少,让服务器看上去响应更快。
2)减少网络带宽消耗:当副本被重用时会减低客户端的带宽消耗;客户可以节省带宽费用,控制带宽的需求的增长并更易于管理。
1、缓存工作原理
页面缓存状态是由http header决定的,一个浏览器请求信息,一个是服务器响应信息。主要包括Pragma: no-cache、Cache-Control、 Expires、 Last-Modified、If-Modified-Since。其中Pragma: no-cache由HTTP/1.0规定,Cache-Control由HTTP/1.1规定。
工作原理图:
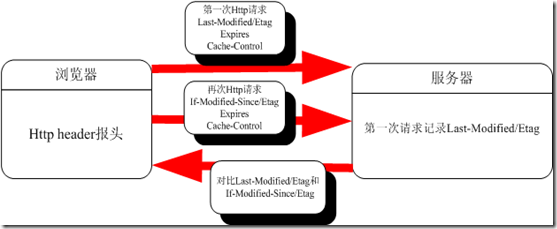
从图中我们可以看到原理主要分三步:
- 第一次请求:浏览器通过http的header报头,附带Expires,Cache-Control,Last-Modified/Etag向服务器请求,此时服务器记录第一次请求的Last-Modified/Etag
- 再次请求:当浏览器再次请求的时候,请求头附带Expires,Cache-Control,If-Modified-Since/Etag向服务器请求
- 服务器根据第一次记录的Last-Modified/Etag和再次请求的If-Modified-Since/Etag做对比,判断是否需要更新,服务器通过这两个头判断本地资源未发生变化,客 户端不需要重新下载,返回304响应。常见流程如下图所示:

声明:该文观点仅代表作者本人,牛骨文系教育信息发布平台,牛骨文仅提供信息存储空间服务。
- 上一篇: Browser caching
- 下一篇: 【缓存技术原理】浏览器端缓存机制详解

copyright © 2008-2026 亿联网络 版权所有 备案号:粤ICP备14031511号-2