

C之奇淫技巧——宏的妙用
一、宏列表
当遇到这样的问题的时候:
有一个标记变量,其中的每个位代表相应的含义。我们需要提供一组函数来访问设置这些位,但是对于每个标记位的操作函数都是相似的。若有32个位,难道要搞32套相似的操作函数么?
你也许会说,用一套操作函数,根据传入的参数来判断对哪个位操作。这样固然可行,但是
①不够直观。例如访问Movable标记位,对于用户来说,is Movable()是很自然的方式,而我们只能提供这样的接口isFlag(Movable)
②扩展性差。若以后增加删改标记位,则需要更改isFlag等函数的代码。
我们想有这样的设计:
在头文件的宏定义中增删标记位的宏,我们为每个标记位设计的操作函数名就自动更改,增加的标记位也自动增加一套操作函数,删除的标记位也自动减去一套操作函数。
这样的设计就太爽了!
但如何实现呢?
首先,每个标记位的宏名一变,我们的操作函数名也要相应改变,这时我们可以想到用带参宏,并用宏的##符,把两个字符串合在一起。(使它们能被宏替换掉)
#define FLAG_ACCESSOR(flag)
bool is##flag() const {
return hasFlags(1 << flag);
}
void set##flag() {
JS_ASSERT(!hasFlags(1 << flag));
setFlags(1 << flag);
}
void setNot##flag() {
JS_ASSERT(hasFlags(1 << flag));
removeFlags(1 << flag);
}
[这一步一般人都能想到的。]
这样,FLAG_ACCESSOR(Movable)就可得到操作Movable标记位的三个函数:is Movable(),set Movable(),setNot Movable()
但是,难道有多少个标记位,我们就要写多少个FLAG_ACCESSOR(flag)么?
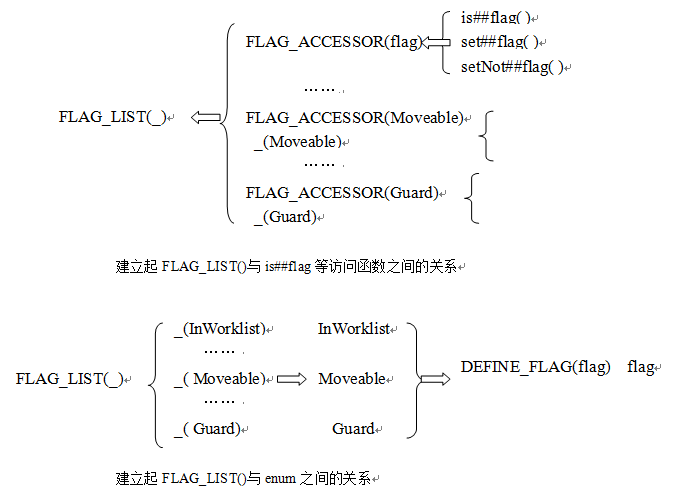
如何用一个式子来扩展成多个种的FLAG_ACCESSOR(flag),提取共性,由于这多个FLAG_ACCESSOR(flag),flag是不同的,宏函数名是相同的。故用宏列表:
#define FLAGLIST()
_(InWorklist)
_(EmittedAtUses)
_(LoopInvariant)
_(Commutative)
_(Movable)
_(Lowered)
_(Guard)
这样一个式子:FLAG_LIST(FLAG_ACCESSOR)就搞定了。
但是,还有一个问题,我们还没有定义InWorklist、EmittedAtUses、LoopInvariant等,需要再用宏来定义这些标记位的名字。
例如:
#define InWorklist 1
#define EmittedAtUses 2
……
这样以来,若以后我们增改标记位的名字 就需要修改两处地方了:宏列表、标记名的宏定义。
我们想要的最好的设计是,只改变一处 处处跟着一起改变。
[yang]若是有新的标记位加入我们只在#define FLAGLIST() 中添加一项就好了。例如,_(Visited) 自动添加#define Visited 8。
自动添加一项宏定义难以实现,那我们考虑有没有替代方案,观察发现此宏定义都是定义的数字,而枚举也有同样的功能。
这样,我们把这些展开的位标记名放在enum枚举中,让其自动赋上1,2,3……等数值,而不必用宏定义一个一个地定义。
现在问题变为:如何使我们在#defineFLAGLIST() 中添加一项,enum枚举中就自动添加相应的一项?
我们只有把FLAGLIST()放入enum枚举中,这样才能一增俱增。
若宏列表:
#define FLAGLIST()
_(InWorklist)
_(EmittedAtUses)
_(LoopInvariant)
能再变为:
InWorklist
EmittedAtUses
LoopInvariant
就好了。
这样,我们在#defineFLAGLIST() 中添加一项_(Visited)。则enum中自动添加Visited。
也就是_(InWorklist)如何展开成InWorklist。这个很简单:#define DEFINE_FLAG(flag)flag,
其具体实现方式如下:
#define FLAGLIST()
_(InWorklist)
_(EmittedAtUses)
_(LoopInvariant)
_(Commutative)
_(Movable)
_(Lowered)
_(Guard)
它定义了一个FLAGLIST宏,这个宏有一个参数称之为 ,这个参数本身是一个宏,它能够调用列表中的每个参数。举一个实际使用的例子可能更能直观地说明问题。假设我们定义了一个宏DEFINE_FLAG,如:
#define DEFINE_FLAG(flag) flag, //注意flag后有逗号
enum Flag {
None = 0,
FLAG_LIST(DEFINE_FLAG)
Total
};
#undef DEFINE_FLAG
对FLAG_LIST(DEFINE_FLAG)做扩展能够得到如下代码:
enum Flag {
None = 0,
DEFINE_FLAG(InWorklist)
DEFINE_FLAG(EmittedAtUses)
DEFINE_FLAG(LoopInvariant)
DEFINE_FLAG(Commutative)
DEFINE_FLAG(Movable)
DEFINE_FLAG(Lowered)
DEFINE_FLAG(Guard)
Total
};
接着,对每个参数都扩展DEFINE_FLAG宏,这样我们就得到了enum如下:
enum Flag {
None = 0,
InWorklist,
EmittedAtUses,
LoopInvariant,
Commutative,
Movable,
Lowered,
Guard,
Total
};
接着,我们可能要定义一些访问函数,这样才能更好的使用flag列表:
#define FLAG_ACCESSOR(flag)
bool is##flag() const {
return hasFlags(1 << flag);
}
void set##flag() {
JS_ASSERT(!hasFlags(1 << flag));
setFlags(1 << flag);
}
void setNot##flag() {
JS_ASSERT(hasFlags(1 << flag));
removeFlags(1 << flag);
}
FLAG_LIST(FLAG_ACCESSOR)
#undef FLAG_ACCESSOR
(这样,我们只在宏列表一处更改增删位操作即可。)
【总结:yang】
一步步的展示其过程是非常有启发性的,如果对它的使用还有不解,可以花一些时间在gcc –E上。
【宏列表的优点有:可以把一个式子扩展成多个式子,且很容易扩展,只要再增加列表项即可。】
二、指定的初始化
很多人都知道像这样来静态地初始化数组:
int fibs[] = {1,2,3,4,5} ;
C99标准实际上支持一种更为直观简单的方式来初始化各种不同的集合类数据(如:结构体,联合体和数组)。
数组的初始化
我们可以指定数组的元素来进行初始化。这非常有用,特别是当我们需要根据一组#define来保持某种映射关系的同步更新时。来看看一组错误码的定义,如:
/ Entries may not correspond to actualnumbers. Some entries omitted. /
define EINVAL 1
define ENOMEM 2
define EFAULT 3
/ ... /
define E2BIG 7
define EBUSY 8
/ ... /
define ECHILD 12
/ ... /
现在,假设我们想为每个错误码提供一个错误描述的字符串。为了确保数组保持了最新的定义,无论头文件做了任何修改或增补,我们都可以用这个数组指定的语法。
char *err_strings[] = {
err_strings[0] = "Success",
err_strings [EINVAL] = "Invalid argument",
err_strings[ENOMEM] = "Not enough memory",
err_strings[EFAULT] = "Bad address",
/ ... /
err_strings[E2BIG ] = "Argument list too long",
err_strings[EBUSY ] = "Device or resource busy",
/ ... /
err_strings[ECHILD] = "No child processes"
/ ... /
};
这样就可以静态分配足够的空间,且保证最大的索引是合法的,同时将特殊的索引初始化为指定的值,并将剩下的索引初始化为0。
(注意:指定元素前面要有数组名,否则报错)
结构体与联合体
用结构体与联合体的字段名称来初始化数据是非常有用的。假设我们定义:
struct point {
int x;
int y;
int z;
} ;
然后我们这样初始化structpoint:
struct point p = {.x = 1, .z = 3}; //x为1,y为0,z为3
当我们不想将所有字段都初始化为0时,这种作法可以很容易的在编译时就生成结构体,而不需要专门调用一个初始化函数。
对联合体来说,我们可以使用相同的办法,只是我们只用初始化一个字段。
三、编译时断言
这其实是使用C语言的宏来实现的非常有“创意”的一个功能。有些时候,特别是在进行内核编程时,在编译时就能够进行条件检查的断言,而不是在运行时进行,这非常有用。不幸的是,C99标准还不支持任何编译时的断言。
但是,我们可以利用预处理来生成代码,这些代码只有在某些条件成立时才会通过编译(最好是那种不做实际功能的命令)。有各种各样不同的方式都可以做到这一点,通常都是建立一个大小为负的数组或结构体。最常用的方式如下:
define STATIC_ZERO_ASSERT(condition)(sizeof(struct { int:-!(condition); }) )
define STATIC_NULL_ASSERT(condition)((void *)STATIC_ZERO_ASSERT(condition) )
// 上面是用两种不同的方式来实现这个效果的,我们任选其中一种方式即可
【原理】
define STATIC_ASSERT(condition)((void)STATIC_ZERO_ASSERT(condition))
如果(condition)计算结果为一个非零值(即C中的真值),即! (condition)为零值,那么代码将能顺利地编译,并生成一个大小为零的结构体。如果(condition)结果为0(在C真为假),那么在试图生成一个负大小的结构体时,就会产生编译错误。
【例子】
它的使用非常简单,如果任何某假设条件能够静态地检查,那么它就可以在编译时断言。例如,在上面提到的标志列表中,标志集合的类型为uint32_t,所以,我们可以做以下断言:
STATIC_ASSERT(Total <= 32)
它扩展为:
(void)sizeof(struct { int:-!(Total <=32) })
现在,假设Total<=32。那么-!(Total <= 32)等于0,所以这行代码相当于:
(void)sizeof(struct { int: 0 })
这是一个合法的C代码。现在假设标志不止32个,那么-!(Total <= 32)等于-1,所以这时代码就相当于:
(void)sizeof(struct { int: -1 } )
因为位宽为负,所以可以确定,如果标志的数量超过了我们指派的空间,那么编译将会失败。
四、在指针中隐藏数据
(这个技术有点变态,大家看看就好)
编写 C 语言代码时,指针无处不在。我们可以稍微额外利用指针,在它们内部暗中存储一些额外信息。为实现这一技巧,我们利用了数据在内存中的自然对齐特性。
假设系统中整型数据和指针大小均为 4 字节。
则指针的数值(即其中包含的地址值),都是4的整数倍,也就是说其二进制数都是以 00 结尾。那么这 2 比特没有承载任何信息。所以就有人脑动大开,利用这两个比特存点信息,在使用指针之前用位操作的方式存储2bit信息到此指针,当要对指针进行解引用操作时,把其原先值提取出来。
void put_data(int *p, unsigned int data)
{
assert(data < 4);
*p |= data;
}
unsigned int get_data(unsigned int p)
{
return (p & 3);
}
void cleanse_pointer(int *p)
{
*p &= ~3;
}
int main(void)
{
unsigned int x = 701;
unsigned int p = (unsigned int) &x;
printf("Original ptr: %un", p);
//把3存储到指针中
put_data(&p, 3);
printf("ptr with data: %un", p);
printf("data stored in ptr: %un", get_data(p)); //获取指针中的数据3
cleanse_pointer(&p); //在解引用指针前,把隐藏的2bit数据抹掉,恢复其原值
printf("Cleansed ptr: %un", p);
printf("Dereferencing cleansed ptr: %un", *(int*)p);
return 0;
}
这也太变态了吧,连这2个bit都不放过,现在是21世纪了,我们还缺这点内存么?
不过,在实际中还真有应用:Linux 内核中红黑树的实现。
树结点定义:
struct rb_node {
unsigned long rb_parent_color;
struct rb_node rb_right;
struct rb_node rb_left;
} attribute__((aligned(sizeof(long))));
此处 unsigned long __rb_parent_color 存储了如下信息:
父节点的地址,结点的颜色
色彩的表示用 0 代表红色,1 代表黑色。
和前面的例子一样,该数据隐藏在父指针“无用的”比特位中。
父指针和色彩信息的获取:
/ in rbtree.h /
define rb_parent(r) *((struct rb_node )((r)->__rb_parent_color & ~3))**
/ in rbtree_augmented.h /
define __rb_color(pc) ((pc) & 1)
define rb_color(rb) __rb_color((rb)->__rb_parent_color)
【参考】