

(дЄА)пЉЪеЯЇз°АдЄОжХ∞жНЃ
еОЯжЦЗеЗЇе§ДпЉЪhttp://www.infoq.com/cn/articles/laxcus-introduction-part1
дљЬиАЕпЉЪжҐБз•ЦйВ¶
еЙНи®А
LAXCUSжШѓдЄАе•ЧжХ∞жНЃзЃ°зРЖиљѓдїґпЉМеЇФзФ®дЇОе§ІиІДж®°жХ∞жНЃе≠ШеВ®еТМиЃ°зЃЧзОѓеҐГгАВињЩжШѓдЄАдЄ™зЛђзЂЛеТМеЃМжХізЪДдЇІеУБпЉМиЮНеРИдЇЖеМЕжЛђжХ∞жНЃе≠ШеВ®гАБзљСзїЬйАЪдњ°гАБзљСзїЬиЃ°зЃЧгАБжХ∞жНЃеЃЙеЕ®гАБзљСзїЬеЃЙеЕ®гАБдїїеК°и∞ГеЇ¶гАБеЃєйФЩе§ДзРЖгАБиЗ™еК®еМЦзЃ°зРЖгАБдЇЇжЬЇдЇ§дЇТжО•еП£гАБеЇФзФ®еЉАеПСз≠Йе§ЪжЦєйЭҐзЪДжКАжЬѓгАВLAXCUSйЗЗзФ®JAVAиѓ≠и®АзЉЦеЖЩпЉМжФѓжМБи°М/еИЧдЄ§зІНжХ∞жНЃе≠ШеВ®пЉМйАЪињЗзїИзЂѓжИЦиАЕеЇФзФ®жО•еП£еµМеЕ•жЦєеЉПжО•еЕ•пЉМжЙІи°МSQLеТМз±їSQLжУНдљЬгАВдЇІеУБеЄГзљ≤дљњзФ®ењЂжНЈзЃАеНХпЉМйБµеЊ™LGPLеНПиЃЃпЉМеЉАжФЊжЇРдї£з†БпЉМињРи°МеЬ®LINUXеє≥еП∞гАВ
1.1 еЯЇдЇОзО∞зКґзЪДдЄАдЇЫжАЭиАГ
еЬ®ињЗеОїеНБеЗ†еєійЗМпЉМйЪПзЭАдЇТиБФзљСзїЬеТМеРДзІНжЦ∞еЕіжКАжЬѓзЪДењЂйАЯеПСе±ХпЉМжХ∞е≠Чдњ°жБѓе≠ШйЗПеСИзИЖзВЄжАІеҐЮйХњдєЛеКњгАВйЭҐеѓєе¶Вж≠§еЇЮе§ІзЪДжХ∞жНЃпЉМе¶ВдљХеЃЮзО∞йЂШжХИзЪДе≠ШеВ®еТМиЃ°зЃЧпЉМйАЪеЄЄйЗЗзФ®зЪДжПРйЂШCPUжАІиГљеТМжФєзФ®жЫіе§ІеЃєйЗПз£БзЫШзЪДеБЪж≥ХпЉМеЈ≤зїПеПШеЊЧиґКжЭ•иґКеЫ∞йЪЊгАВеЬ®ињЩзІНиГМжЩѓдЄЛпЉМдї•зљСзїЬеТМзљСзїЬйАЪдњ°жКАжЬѓдЄЇдЊЭжЙШпЉМе∞ЖеИЖжХ£еЬ®дЄНеРМеЬ∞зРЖдљНзљЃзЪДиЃ°зЃЧжЬЇињЮжО•иµЈжЭ•пЉМзїДжИРз©ЇйЧідЄКеИЖжХ£гАБйАїиЊСдЄКзїЯдЄАзЪДжХ∞жНЃе≠ШеВ®еТМиЃ°зЃЧйЫЖзЊ§пЉМжИРдЄЇељУеЙНеЃЮзО∞е§ІиІДж®°жХ∞жНЃе§ДзРЖзЪДдЄїи¶БйАЙжЛ©гАВ
йЫЖзЊ§иЃ°зЃЧзЪДдЉШеКњеЬ®дЇОпЉЪеЃГеЉЇи∞ГжАїдљУзЪДе§ДзРЖиГљеКЫпЉМжѓПеП∞иЃ°зЃЧжЬЇеБЪдЄЇеНХдЄ™иКВзВєеПВдЄОиЃ°зЃЧињЗз®ЛпЉМжЙњжЛЕеЕґдЄ≠дЄАйГ®еИЖиЃ°зЃЧдїїеК°пЉМе§ДзРЖиГљеКЫзЪДеЉЇеЉ±зФ±еЕ®йГ®иКВзВєеЕ±еРМеЖ≥еЃЪгАВињЩзІНеЈ•дљЬж®°еЉПжЮБе§ІеЬ∞еПСжМ•еЗЇзљСзїЬзЪДиГљйЗПпЉМдљњеЊЧеНХеП∞иЃ°зЃЧжЬЇзЪДе§ДзРЖжАІиГљеПШеЊЧдЄНеЖНйЗНи¶БгАВеєґдЄФзФ±дЇОзљСзїЬзЪДињЮжО•пЉМжѓПеП∞иЃ°зЃЧжЬЇйЪПжЧґеПѓдї•еК†еЕ•жИЦиАЕжТ§з¶їиЃ°зЃЧињЗз®ЛгАВињЩзІНз±їдЉЉиЃ°зЃЧжЬЇвАЬеН≥жПТеН≥зФ®вАЭзЪДеКЯиГљпЉМдљњеЊЧйЫЖзЊ§еЬ®ињРи°МињЗз®ЛдЄ≠еПѓдї•еК®жАБеЬ∞и∞ГжХіиЗ™еЈ±зЪДиЃ°зЃЧиГљеКЫпЉМиµЛдЄОдЇЖйЫЖзЊ§иЃ°зЃЧињСдєОжЧ†йЩРеҐЮйХњзЪДеПѓиГљпЉМињЩжШѓдЉ†зїЯзЪДйЫЖдЄ≠еЉПиЃ°зЃЧжЧ†ж≥ХжѓФжЛЯзЪДгАВеРМжЧґзФ±дЇОдЄНеЖНињљж±ВеНХеП∞иЃ°зЃЧжЬЇзЪДе§ДзРЖжАІиГљпЉМйЗЗиі≠з°ђдїґиЃЊе§ЗжЧґпЉМеПѓдї•ж†єжНЃеЃЮйЩЕеЇФзФ®йЬАж±ВйЕМжГЕиАГйЗПпЉМдЄЇиКВзЇ¶жИРжЬђжКХеЕ•жПРдЊЫдЇЖйАЙжЛ©зЪДз©ЇйЧігАВ
дљЖжШѓењЕй°їзЬЛеИ∞пЉМж≠£е¶Вз°ђеЄБзЪДдЄ§йЭҐдЄАж†ЈпЉМйЫЖзЊ§иЃ°зЃЧеЬ®жПРдЊЫдЇЖеЙНжЙАжЬ™жЬЙзЪДе§ДзРЖиГљеКЫзЪДеРМжЧґпЉМдєЯжЬЙзЭАеЃГдЄОзФЯдњ±жЭ•зЪДиЃЄе§ЪйЧЃйҐШгАВ
й¶ЦеЕИзФ±дЇОињЮжО•зЪДиКВзВєдЉЧе§ЪдЄФеИЖжХ£пЉМйЫЖзЊ§зїДзїЗзїУжЮДеПШеЊЧеЇЮе§ІгАВдЄ™дљУз°ђдїґеУБиі®иЙѓиО†дЄНдЄАпЉМзљСзїЬзЇњиЈѓгАБйАЪдњ°иЃЊе§ЗгАБиЃ°зЃЧжЬЇдєЛйЧізЪДињЮжО•еТМйАЪдњ°ињЗз®Ле≠ШеЬ®зЭАдЄНз°ЃеЃЪжАІпЉМз°ђдїґиЃЊе§ЗеЖЕйГ®гАБиЃЊе§ЗдЄОиЃЊе§ЗгАБиЃЊе§ЗдЄОе§ЦзХМзОѓеҐГпЉМељЉж≠§дЇТзЫЄдЇ§еПЙељ±еУНгАВеЬ®ињЩж†ЈзЪДжЭ°дїґдЄЛпЉМдњЭиѓБжѓПеП∞иЃЊе§ЗеЃМеЕ®з®≥еЃЪињРи°МеЈ≤жЧ†еПѓиГљпЉМиІ£еЖ≥йЫЖзЊ§зїДзїЗдЄНеЃЙеЃЪзКґжАБдЄЛзЪДз®≥еЃЪиЃ°зЃЧжИРдЄЇй¶Ци¶БйЧЃйҐШгАВ
еП¶е§ЦпЉМдЄОйЫЖдЄ≠иЃ°зЃЧдЄНеРМзЪДжШѓпЉМйЫЖзЊ§зЪДжХ∞жНЃе§ДзРЖжШѓдЄАдЄ™еИЖжХ£зЪДиЃ°зЃЧињЗз®ЛгАВеЃГзЪДеЙНзЂѓеПЧзРЖе§ІйЗПзЪДиѓЈж±ВдїїеК°пЉМзДґеРОе∞ЖињЩдЇЫдїїеК°еИЖйЕНеИ∞еРОзЂѓдЉЧе§ЪзЪДиЃ°зЃЧжЬЇдЄКеОїжЙІи°МгАВдЄАдЄ™йЂШжХИеєґдЄФеРИзРЖзЪДеИЖеЄГиЃ°зЃЧзЃЧж≥ХжИРдЄЇењЕй°їгАВзЃЧж≥ХйЬАи¶БиІ£еЖ≥зЪДйЧЃйҐШеМЕжЛђпЉЪдїїеК°еИЖйЕНгАБињЗз®Ли∞ГеЇ¶гАБжХЕйЪЬеЃєйФЩгАБжХ∞жНЃз≠ЫйАЙгАБжХ∞жНЃеє≥и°°гАБжХ∞жНЃж±ЗжАїз≠ЙиѓЄе§ЪзОѓиКВзЪДеЈ•дљЬпЉМжЬАзїИ嚥жИРдЄОйЫЖдЄ≠иЃ°зЃЧдЄАж†ЈзЪДе§ДзРЖзїУжЮЬгАВињЩдЄ™ињЗз®ЛеНБеИЖе§НжЭВгАВ
жХ∞жНЃзЃ°зРЖзЫКеПШеЊЧйЗНи¶БгАВеЬ®дЄАдЄ™е§ІиІДж®°зЪДжХ∞жНЃе≠ШеВ®еЇПеИЧдЄ≠пЉМи¶БдњЭиѓБеЃМеЕ®ж≠£з°ЃзЪДе§ДзРЖзїУжЮЬпЉМдїїдљХеНХзВєдЄКзЪДжХ∞жНЃйГљдЄНиГљйБЧжЉПгАВињЩйЬАи¶БжДЯзЯ•жѓПдЄ™жХ∞жНЃзЪДе≠ШеЬ®пЉМз°ЃеЃЪжХ∞жНЃзЪДзЙ©зРЖдљНзљЃпЉМиГље§Яй™МиѓБжХ∞жНЃзЪДеПѓзФ®жАІеТМж≠£з°ЃжАІпЉМеН≥дљњеЬ®жХЕйЪЬзКґжАБдЄЛпЉМдїНзДґйЬАи¶Бз°ЃдњЭиЃ°зЃЧињЗз®ЛзЪДж≠£еЄЄињЫи°МгАВињЩжШѓеѓєжХ∞жНЃе§ДзРЖзЪДеЯЇжЬђи¶Бж±ВгАВ
жЫійЗНи¶БзЪДжШѓзФ®жИЈдљУй™МгАВж≤°жЬЙдЇЇдЉЪеЦЬ搥дЄАдЄ™е§НжЭВгАБзєБзРРгАБйЪЊдї•зїіжК§зЪДз≥їзїЯгАВзЫЄеПНпЉМдЄАдЄ™дЇЇжЬЇзХМйЭҐеПЛе•љгАБеЃєжШУжУНдљЬзЪДдЇІеУБжЫіеЃєжШУеПЧеИ∞зФ®жИЈйЭТзЭРгАВињЩйЬАи¶БеЬ®дЇІеУБиЃЊиЃ°жЧґеБЪеЊИе§ЪеЈ•дљЬпЉМзїЉеРИиАГйЗПдЇІеУБзЪДеЇФзФ®иМГеЫігАБе§ДзРЖжХИзОЗгАБињРиР•жИРжЬђпЉМдї•еПКзФ®жИЈзЪДдљњзФ®и°МдЄЇеТМдє†жГѓпЉМеБЪеЗЇењЕи¶БзЪДеПЦиИНпЉМиЊЕдї•жКАжЬѓеЃЮзО∞пЉМжЙНиГљдЇІзФЯиЙѓе•љзЪДдљњзФ®дљУй™МгАВ
ељУиГље§ЯжПРдЊЫзЪДз°ђдїґеЯЇз°АиЃЊжЦљеЈ≤зїПеЫЇеЃЪпЉМеРДзІНеЇФзФ®йЬАж±ВињШеЬ®дЄНжЦ≠еПСе±ХеТМеПШеМЦпЉМе¶ВдљХйАВеЇФињЩзІНеПШйЭ©дЄ≠зЪДиґЛеКњпЉМдї•дЄКзІНзІНпЉМйГљжШѓиљѓдїґиЃЊиЃ°йЬАи¶БжАЭиАГзЪДйЧЃйҐШгАВ
1.2 дЇІеУБзЙєзВє
зФ±дЇОжЦ∞зЪДз≥їзїЯеЯЇдЇОзљСзїЬзОѓеҐГпЉМйЬАи¶БйАВеЇФжХ∞жНЃеЬ®е≠ШеВ®йЗПеТМиЃ°зЃЧиГљеКЫдЄКзЪДеПѓи∞ГиКВзЪДеҐЮеЗПпЉМињЩзІНињРи°МдЄ≠еК®жАБж≥ҐеК®зЪДжХ∞жНЃиЃ°зЃЧпЉМеЃМеЕ®дЄНеРМдЄОдЉ†зїЯзЪДе§ДзРЖжЦєеЉПгАВдЄАз≥їеИЧжЦ∞зЪДеПШеМЦдњГдљњжИСйЗНжЦ∞еЃ°иІЖдЇІеУБзЪДеЃЪдљНеТМиЃЊиЃ°пЉМињЩдЇЫеЫ†зі†еП†еК†еЬ®дЄАиµЈпЉМжЬАзїИ嚥жИРдЇЖдЄОдї•еЊАеЃМеЕ®дЄНеРМзЪДзїУжЮЬгАВ
1.2.1 дї•жЩЃйАЪз°ђдїґдЄЇж†ЗеЗЖзЪДеК®жАБеПѓдЉЄзЉ©зЪДеЃєйФЩе§ДзРЖ
LAXCUSе∞ЖйЫЖзЊ§иЃЊе§ЗзЪДз°ђдїґеПВиАГж†ЗеЗЖеЃЪдљНдЄЇжЩЃйАЪзЪДдЄ™дЇЇиЃ°зЃЧжЬЇгАВињЩзІНиЃЊиЃ°жЬЙдЄ§дЄ™е•ље§ДпЉЪ1.е∞ЖзФ®жИЈзЪДз°ђдїґиЃЊе§ЗжКХеЕ•жИРжЬђйЩНеИ∞иґ≥е§ЯдљОпЉЫ2.йЬАи¶БеЕЕеИЖиАГиЩСз°ђдїґзЪДдЄНз®≥еЃЪжАІгАВеЬ®дЇІеУБиЃЊиЃ°еТМеЃЮзО∞дЄ≠пЉМз°ђдїґзЪДдЄНз®≥еЃЪзФ±иљѓдїґйАЪињЗзЫСжОІеТМжХЕйЪЬеЖЧзБЊжЬЇеИґжЭ•еЉ•и°•жБҐе§НпЉМдїїдљХиЃЊе§ЗеТМиЃЊе§ЗзїДдїґзЪД姱жХИ襀иІЖдЄЇж≠£еЄЄжГЕеЖµпЉМиАМдЄНжШѓеЉВеЄЄгАВиЃЊе§ЗжХЕйЪЬйАЪињЗиЗ™ж£АжК•еСКеТМзЃ°зРЖжЬНеК°еЩ®ињљиЄ™жЭ•жДЯзЯ•гАВеПСзФЯеТМеПСзО∞жХЕйЪЬеРОпЉМжХЕйЪЬзВєе∞Ж襀йЪФз¶їпЉМеРМжЧґйАЪзЯ•з≥їзїЯзЃ°зРЖеСШгАВиЃЊе§ЗзЪДжХЕйЪЬжБҐе§Н襀иІЖдЄЇжЦ∞иЃЊе§ЗеК†еЕ•гАВжХЕйЪЬиЃЊе§ЗдЄ≠зЪДжХ∞жНЃйАЪињЗе§ЪжЬЇеЖЧдљЩе§ЗдїљеТМе§НеИґжЬЇеИґжЭ•дњЭиѓБжЬЙжХИе≠ШеЬ®гАВ
1.2.2 еЉ±дЄ≠ењГеМЦзЃ°зРЖ
иІБеЫЊ1.1пЉМињРи°МдЄ≠зЪДйЫЖзЊ§зФ±иКВзВєжЮДжИРгАВиКВзВєжМЙеКЯиГљеИТеИЖдЄЇзЃ°зРЖиКВзВєеТМдїїеК°иКВзВєпЉМTOPеТМHOMEжШѓзЃ°зРЖиКВзВєпЉМеЕґеЃГйГљжШѓдїїеК°иКВзВєгАВзЃ°зРЖиКВзВєжШѓжХідЄ™йЫЖзЊ§зЪДж†ЄењГпЉМжЙњжЛЕзЭАзЫСзЭ£еТМзЃ°зРЖдїїеК°иКВзВєдљЬзФ®гАВдЄОеЉЇи∞ГзЃ°зРЖиКВзВєзЪДдЄ≠ењГеЕ®иі£зЫСзЃ°зЪДзРЖењµдЄНеРМпЉМLAXCUSйЗЗеПЦдЇЖеЉ±дЄ≠ењГеМЦзЪДзЃ°зРЖиЃЊиЃ°жО™жЦљгАВеЬ®LAXCUSйЫЖзЊ§дЄ≠пЉМзЃ°зРЖиКВзВєеП™жЙњжЛЕе∞СйЗПеТМйЗНи¶БзЪДзЃ°зРЖдїїеК°пЉМдїїеК°иКВзВєеЬ®иіЯиі£еЕЈдљУеЈ•дљЬзЪДеРМжЧґпЉМдєЯйЬАи¶БзЫСиІЖиЗ™иЇЂзЪДеЈ•дљЬи°МдЄЇгАВињЩзІНиЗ™зїіжМБзЪДеЈ•дљЬжЦєеЉПпЉМеПѓдї•еЗПе∞СдЄОзЃ°зРЖиКВзВєзЪДйАЪдњ°гАВеЄ¶жЭ•зЪДдЉШеКње∞±жШѓпЉЪзЃ°зРЖиКВзВєзЪДеОЛеКЫеЗПиљїпЉМиГље§ЯиЕЊеЗЇжЫіе§ЪиЃ°зЃЧиГљеКЫе§ДзРЖдЄїи¶БзЪДдїїеК°пЉМдїїеК°е§ДзРЖйАЯеЇ¶еПѓдї•жЫіењЂпЉМжЬНеК°еЩ®з°ђдїґйЕНзљЃеЫ†ж≠§еПѓдї•йЩНдљОгАВдїїеК°иКВзВєзФ±дЇОиЗ™зїіжМБзЪДзЙєзВєпЉМжЧҐдљњеЬ®зЃ°зРЖиКВзВєеЃХжЬЇжГЕеЖµдЄЛпЉМдєЯиГљзїіжМБдЄАжЃµжЧґйЧізЪДж≠£еЄЄињРи°МпЉМзЫіеИ∞еЖНжђ°еПСиµЈеѓєзЃ°зРЖиКВзВєзЪДиѓЈж±ВгАВиАМињЩжЃµжЧґйЧіеЖЕпЉМзЃ°зРЖиКВзВєеПѓиГљеЈ≤зїПжБҐе§НгАВеЉ±дЄ≠ењГеМЦзЃ°зРЖеҐЮеЉЇдЇЖйЫЖзЊ§зЪДз®≥еЃЪжАІгАВ
1.2.3 е§ЪйЫЖдљУзЊ§зЪДеНПеРМеЈ•дљЬж®°еЉП
иІБеЫЊ1.1зЪДLAXCUSйЫЖзЊ§зїУжЮДеЫЊпЉМеЕґдЄ≠еМЕжЛђдЄ§дЄ™HOMEйЫЖзЊ§пЉМTOPиКВзВєдљНдЇОдЄ§дЄ™HOMEйЫЖзЊ§дЄКгАВињЩжШѓдЄАдЄ™еЕЄеЮЛзЪДе§ЪйЫЖзЊ§зїУжЮДж®°еЮЛпЉМLAXCUSжЬАжШЊиСЧзЙєзВєдєЛдЄАпЉМе∞±жШѓиГље§ЯжФѓжМБе§ЪдЄ™йЫЖзЊ§иЈ®еЬ∞еЯЯеНПеРМеЈ•дљЬпЉМињЩдЄОеНХйЫЖзЊ§е§ДзРЖз≥їзїЯжЬЙзЭАж†єжЬђзЪДдЄНеРМгАВеЬ®дЉ†зїЯзЪДеНХйЫЖзЊ§з≥їзїЯдЄ≠пЉМзЃ°зРЖиКВзВєжЙњжЛЕзЭАзЃ°зРЖзїіжК§жХідЄ™йЫЖзЊ§ињРи°МзЪДеЈ•дљЬдїїеК°пЉМе¶ВжЮЬдЄАеС≥жПРйЂШйЫЖзЊ§дЄ≠иЃ°зЃЧжЬЇзЪДжХ∞йЗПпЉМе∞±дЉЪеҐЮеК†зЃ°зРЖиКВзВєзЪДе§ДзРЖеОЛеКЫпЉМдїОиАМељ±еУНеИ∞йЫЖзЊ§зЪДз®≥еЃЪињРи°МгАВйЗЗзФ®е§ЪйЫЖзЊ§еНПеРМеЈ•дљЬжЦєеЉПеРОпЉМе∞ЖжѓПдЄ™йЫЖзЊ§зЪДиЃ°зЃЧжЬЇжХ∞йЗПйЩРеИґеЬ®дЄАеЃЪиІДж®°пЉМеИЩиГље§ЯжЬЙжХИеМЦиІ£ињЩдЄ™еПѓиГљжИРдЄЇзУґйҐИзЪДйЧЃйҐШгАВеП¶дЄАжЦєйЭҐпЉМзФ±дЇОе§ЪйЫЖзЊ§зїУжЮДжШѓжХ∞дЄ™е≠РйЫЖзЊ§зЪДзїДеРИпЉМжѓПдЄ™е≠РйЫЖзЊ§еПѓдї•еИЖжХ£еЬ®дЄНеРМзФЪиЗ≥йБ•ињЬзЪДеЬ∞зРЖдљНзљЃпЉМеП™и¶БиГље§ЯйАЪињЗVPNжИЦиАЕдЇТиБФзљСзїЬеЃЮзО∞ињЮжО•пЉМе∞±иГље§ЯеЃЮзО∞жЫіе§ІиІДж®°зЪДзљСзїЬиЃ°зЃЧпЉМжИРеАНеҐЮеК†йЫЖзЊ§зЪДжХ∞жНЃе§ДзРЖиГљеКЫпЉМињЫдЄАж≠•жПРеНЗеЈ•дљЬжХИзОЗгАВ
1.2.4 дї•жФѓжМБе§ІиІДж®°ж£А糥/жЈїеК†дЄЇдЄїпЉМеЕЉй°Ње∞ПжЙєйЗПеИ†йЩ§/жЫіжЦ∞зЪДжХ∞жНЃе§ДзРЖ
еЬ®дЇІеУБиЃЊиЃ°еЙНпЉМйАЪињЗеѓєе§ІйЗПжХ∞жНЃжУНдљЬи°МдЄЇзЪДињљиЄ™еТМеИЖжЮРеПСзО∞пЉМжХ∞жНЃжУНдљЬдЄїи¶БйЫЖдЄ≠еЬ®жЈїеК†еТМж£А糥йШґжЃµпЉМеИ†йЩ§еТМжЫіжЦ∞жЮБе∞СеПСзФЯпЉМеЕґдЄ≠ж£А糥и°МдЄЇеПИињЬињЬиґЕињЗжЈїеК†гАВињЩдЄ™зО∞и±°дњГдљњжИСеѓєжХ∞жНЃе≠ШеВ®иЃЊиЃ°дЇІзФЯдЇЖдЄНеРМдї•еЊАзЪДеЃЪдљНпЉМе∞ЖжХідЄ™е≠ШеВ®жЦєж°ИйЗНзВєеЫізїХзЭАж£А糥е±ХеЉАпЉМеєґжНЃж≠§еИґеЃЪдЇЖдї•дЄЛзЪДжЙІи°Мз≠ЦзХ•пЉЪй¶ЦеЕИпЉМдЄЇдњЭиѓБе§ІжХ∞йЗПйЂШйҐСеЇ¶зЪДж£А糥жУНдљЬпЉМзїУеРИеИ∞иЃ°зЃЧжЬЇеЖЕзЪДCPUгАБеЖЕе≠ШгАБз£БзЫШеРДдЄїи¶БеЈ•дљЬйГ®дїґзЪДжАІиГљпЉМеЬ®дњЭжМБжХ∞жНЃзЪДжЬАе§ІеРЮеРРйЗПдЄКпЉМжµБеЉПе§ДзРЖжХИзОЗжЬАйЂШгАВеєґи°МзЪДжХ∞жНЃеЖЩеЕ•еЬ®ињЫеЕ•е≠ШеВ®е±ВйЭҐжЧґпЉМж±ЗжµБдЄЇдЄ≤и°Мж®°еЉПгАВж£А糥жУНдљЬзЪДжЬАзїИзЫЃж†ЗжШѓз£БзЫШпЉИжЄ©ељїжЦѓзЙєз°ђзЫШпЉЙпЉМз£БзЫШж£А糥еПЧеИґдЇОз£БзЫШзЙ©зРЖзЙєжАІзЪДељ±еУНпЉМеЬ®жХ∞жНЃиЃ°зЃЧињЗз®ЛдЄ≠пЉМдЄ•йЗНжЛЦжїЮдЇЖжХідљУжАІиГљзЪДеПСжМ•пЉМдЄЇжПРйЂШжХ∞жНЃе§ДзРЖжАІиГљпЉМйЬАи¶БеЬ®ж£А糥еЙНеѓєжХ∞жНЃињЫи°МдЉШеМЦпЉМе¶ВеЕ≥иБФеТМиБЪеЗСпЉМеРМжЧґжПРдЊЫдЄАжЙєдЉШеМЦиІДеИЩзїЩзФ®жИЈпЉМиЃ©зФ®жИЈиГље§ЯжМЙзЕІиЗ™еЈ±зЪДжДПжДњеОїзїДзїЗеТМж£А糥жХ∞жНЃгАВеИ†йЩ§дЄНжФєеПШжХ∞жНЃжЬђиЇЂпЉМеП™еѓєжХ∞жНЃеБЪжЧ†жХИиЃ∞ељХгАВжХ∞жНЃжЫіжЦ∞еИЖиІ£дЄЇеИ†йЩ§еТМжЈїеК†дЄ§ж≠•жУНдљЬпЉМеЕґзЫЃзЪДеЬ®дЇОзЃАеМЦеТМеЖЕиБЪжХ∞жНЃе§ДзРЖжµБз®ЛпЉМеРМжЧґйБњеЕНеПСзФЯе§Ъжђ°з£БзЫШиѓїеЖЩзО∞и±°гАВ
1.2.5 жХ∞жНЃеН≥жЧґе≠ШеПЦ
еН≥жЧґе≠ШеПЦжШѓи°°йЗПз≥їзїЯжШѓеР¶жФѓжМБеЃЮжЧґе§ДзРЖзЪДеЕ≥йФЃжАІжМЗж†ЗгАВеЕґи°®зО∞жШѓжХ∞жНЃдЄАжЧ¶ињЫеЕ•е≠ШеВ®зОѓеҐГпЉМзЂЛеН≥зФЯжХИеєґдЄФеПѓдї•дљњзФ®пЉМиАМдЄНжШѓдєЛеРОзЪДжЯРдЄАдЄ™жЧґжЃµжЙНиГљзФЯжХИеТМдљњзФ®гАВзФ±дЇОеЃЮзО∞дЇЖеН≥жЧґе≠ШеПЦпЉМLAXCUSеПѓдї•дњЭиѓБеЬ®дїїдљХжЧґйЧідїїдљХиМГеЫіеЖЕеѓєеЕ®зљСжХ∞жНЃжЙІи°МжЧ†йБЧжЉПзЪДж£А糥пЉМиЊЊеИ∞дЄОеЕ≥з≥їжХ∞жНЃеЇУеРМз≠ЙзЪДеУНеЇФиГљеКЫгАВеН≥жЧґе≠ШеПЦйЭЮеЄЄйЗНи¶БпЉМжШѓиЃЄе§ЪеЕ≥йФЃдЄЪеК°е§ДзРЖењЕй°їжї°иґ≥зЪДдЄАй°єеКЯиГљгАВ
1.2.6 SQL
LAXCUSйЗЗзФ®SQLеБЪдЄЇз≥їзїЯзЪДдЇЇжЬЇдЇ§дЇТжО•еП£гАВйЗЗзФ®SQLзЪДеОЯеЫ†дЄїи¶БжЬЙдЇМпЉЪдї•еЕ≥з≥їдї£жХ∞дЄЇеРОзЫЊзЪДзРЖиЃЇеЯЇз°АпЉМдЉШзІАзЪДз±їиЗ™зДґиѓ≠и®Аи°®ињ∞иГљеКЫгАВеЕ≥з≥їдї£жХ∞е∞ЖжХ∞жНЃе§ДзРЖеТМе§ДзРЖзїУжЮЬзЪДдЄ•и∞®жАІеЊЧдї•дљУзО∞пЉМз±їиЗ™зДґиѓ≠и®АдљњеЊЧSQLзБµжіїзЃАеНХгАБжШУе≠¶жШУзФ®пЉМињШжЬЙеЕґдЄ∞еѓМзЪДеКЯиГљгАБиѓ≠ж≥ХиІДиМГж†ЗеЗЖеМЦгАБ襀жЩЃйБНжО•еПЧзЪДз®ЛеЇ¶гАБзЃ°зРЖзїіжК§жИРжЬђдљОпЉМињЩдЇЫйГљжШѓдњГжИРLAXCUSйЗЗзФ®SQLзЪДеОЯеЫ†гАВжЫійЗНи¶БзЪДжШѓпЉМеЬ®SQLеПСе±ХзЪДеЫЫеНБеєійЗМпЉМеЕґи°НзФЯеЗЇзЪДеРДзІНжХ∞жНЃиЃЊиЃ°жАЭжГ≥еТМдљњзФ®зїПй™МпЉМељ±еУНеїґзї≠еИ∞дїК姩пЉМеН≥дљњеЬ®ињЩдЄ™е§ІиІДж®°жХ∞жНЃе§ДзРЖжЧґдї£пЉМдєЯжШѓеПѓдї•еАЯйЙіеТМеЉ•иґ≥зПНиіµзЪДгАВ
дљЖжШѓе§ІиІДж®°жХ∞жНЃе§ДзРЖеТМдї•SQLдЄЇдї£и°®зЪДеЕ≥з≥їжХ∞жНЃеЇУзЪДеЇФзФ®йЬАж±ВжѓХзЂЯжЬЙ姙е§ЪдЄНеРМпЉМжЙАдї•жЬђзЭАжЙђеЉГзЪДеОЯеИЩпЉМLAXCUSдњЭзХЩдЇЖе§ІйГ®еИЖSQLеКЯиГљпЉМеПЦжґИдЇЖдЄАдЇЫдЄНеРИйАВе§ІиІДж®°жХ∞жНЃе§ДзРЖзЪДеЃЪдєЙпЉМеѓєеЕґдЄ≠дЄАдЇЫеЃЪдєЙдЄ≠зЪДеЕГзі†еТМж¶ВењµињЫи°МдЇЖи∞ГжХіпЉМеРМжЧґеЉХеЕ•дЇЖдЄАжЙєжЦ∞зЪДж¶ВењµеТМжУНзЇµиѓ≠еП•гАВињЩдЇЫеПШеМЦпЉМйГљжШѓдЄЇдЇЖйАВеЇФе§ІиІДж®°жХ∞жНЃе§ДзРЖжЧґдї£жЙАеБЪзЪДжКЙжЛ©гАВ
жЬЙеЕ≥SQLзЪДжЫіе§ЪдїЛзїНпЉМе∞ЖеЬ®зђђ6зЂ†йШРињ∞гАВ
1.2.7 зљСзїЬиЃ°зЃЧеПѓзЉЦз®ЛжО•еП£
дЄЇдЇЖжї°иґ≥еРДзІНе§ІиІДж®°жХ∞жНЃиЃ°зЃЧдЄЪеК°йЬАи¶БпЉМжЦєдЊњзФ®жИЈеЉАеПСLAXCUSдЄКињРи°МзЪДзљСзїЬиЃ°зЃЧдЄ≠йЧідїґз®ЛеЇПпЉМLAXCUSдЄЇз®ЛеЇПеСШжПРдЊЫдЇЖдЄАе•ЧзїПињЗжКљи±°е§ДзРЖзЪДзљСзїЬиЃ°зЃЧеПѓзЉЦз®ЛжО•еП£гАВжО•еП£е∞ЖзљСзїЬиЃ°зЃЧжµБз®ЛиІДиМГеМЦпЉМе±ПиФљдЇЖз≥їзїЯзЪДжЬНеК°йГ®еИЖпЉМеСИзО∞зїЩз®ЛеЇПеСШзЪДжШѓдЄАзїДеПѓжіЊзФЯзЪДжО•еП£з±їгАВињЩж†Је∞±дљњз®ЛеЇПеСШдЄНењЕиАГиЩСзљСзїЬиЃ°зЃЧињЗз®ЛдЄ≠зЪДдїїеК°еИЖйЕНеТМи∞ГеЇ¶йЧЃйҐШпЉМеП™йЬАи¶Бе∞Жз≤ЊеКЫйЫЖдЄ≠еИ∞дЄЪеК°иІДеИЩзЪДзЉЦз®ЛеЃЮзО∞дЄКгАВеЃМжИРеРОжЙУеМЕеПСеЄГпЉМеЙ©дЄЛзЪДеЈ•дљЬпЉМе∞ЖдЇ§зїЩйЫЖзЊ§еОїжЙШзЃ°е§ДзРЖгАВзФ®жИЈеПѓдї•йАЪињЗзїИзЂѓпЉМдљњзФ®SQLеТМз±їSQLиѓ≠еП•жУНдљЬдЄ≠йЧідїґињРи°МгАВLAXCUSе∞ЖйЫЖзЊ§зОѓеҐГдЄЛзЪДе§ІиІДж®°иЃ°зЃЧдїїеК°зЃАеНХеМЦпЉМйЩНдљОдЇЖз®ЛеЇПеСШзЪДеЉАеПСйЪЊеЇ¶еТМзФ®жИЈеЄГзљ≤дљњзФ®зЪДеОЛеКЫпЉМдєЯеЗПе∞СдЇЖжХЕйЪЬеПСзФЯж¶ВзОЗгАВдЄЇйШ≤ж≠ҐињРи°МдЄ≠зЪДйФЩиѓѓпЉМLAXCUSињШжПРдЊЫдЇЖдЄАе•ЧйФЩиѓѓж£А糥жЬЇеИґпЉМеЄЃеК©ењЂйАЯеЃЪдљНеТМж£АжЯ•йФЩиѓѓпЉМе∞љеПѓиГљдЄНељ±еУНз≥їзїЯињРи°МгАВ еЗЇдЇОеЃЙеЕ®зЪДиАГиЩСпЉМињЩдЇЫдЄ≠йЧідїґз®ЛеЇП襀йЩРеИґеЬ®вАЬж≤ЩзЃ±вАЭж°ЖжЮґеЖЕеЈ•дљЬпЉМйБњеЕНеЫ†дЄЇжБґжДПз†іеЭПжИЦиАЕиґКжЭГжУНдљЬељ±еУНеИ∞з≥їзїЯж≠£еЄЄињРи°МгАВ
1.3 жЮґжЮД
е¶ВеЫЊ1.1жЙАз§ЇпЉМLAXCUSжШѓдЄАдЄ™зФ±е§ЪзІНз±їеЮЛиКВзВєзїДжИРпЉМйАЪињЗзљСзїЬеЃЮзО∞ињЮжО•пЉМжЬЙдїїжДПе§ЪдЄ™е≠РйЫЖзЊ§еРМжЧґињРи°МзЪДжХ∞жНЃе≠ШеВ®еТМиЃ°зЃЧзЪДйЫЖзЊ§гАВиКВзВєеЬ®ињЩйЗМжШѓдЄАдЄ™йАїиЊСеНХдљНж¶ВењµпЉМжѓПдЄ™иКВзВєйГљдЄ•ж†ЉйБµеЃИиЃЊиЃ°иІДеЃЪзЪДеЈ•дљЬиМГеЫігАВзРЖиЃЇдЄКпЉМдЄАеП∞зЙ©зРЖиЃ°зЃЧжЬЇдЄКеПѓдї•жЛ•жЬЙдїїжДПдЄ™иКВзВєпЉМеМЕжЛђзїДзїЗжИРдЄЇдЄАдЄ™йЫЖзЊ§гАВиКВзВєдїОеЈ•дљЬе±ЮжАІжЭ•зЬЛпЉМеЕЈжЬЙеПМйЗНиЇЂдїљпЉМеН≥жШѓжЬНеК°еЩ®еПИжШѓеЃҐжИЈзЂѓгАВељУеЃГеБЪдЄЇжЬНеК°еЩ®дљњзФ®жЧґпЉМжО•еПЧжЭ•иЗ™еЕґеЃГиКВзВєзЪДдїїеК°и∞ГеЇ¶пЉЫељУеБЪдЄЇеЃҐжИЈзЂѓдљњзФ®жЧґпЉМдЉЪеРСеЕґеЃГиКВзВєеПСйАБе§ДзРЖеСљдї§гАВиКВзВєжМЙеКЯиГљеИЖдЄЇзЃ°зРЖиКВзВєеТМеЈ•дљЬиКВзВєгАВзЃ°зРЖиКВзВєеЬ®жЙАе±ЮйЫЖзЊ§еЖЕеПѓдї•еРМжЧґе≠ШеЬ®е§ЪдЄ™пЉМдљЖжШѓеП™иГљжЬЙдЄАдЄ™е§ДдЇОињРи°МжЬНеК°зКґжАБпЉМиБМиі£жШѓзЫСзЭ£еТМжОІеИґжЙАе±ЮиМГеЫіеЖЕзЪДиКВзВєињРи°МгАВеЕґеЃГзЃ°зРЖиКВзВєе§ДдЇОе§ЗзФ®зКґжАБпЉМзЫСзЭ£ињЩдЄ™ињРи°МиКВзВєзЪДеЈ•дљЬпЉМељУињРи°МиКВзВєжХЕйЪЬ姱жХИжЧґпЉМйАЪињЗеНПеХЖжЦєеЉПжО®йАЙеЗЇдЄАдЄ™жЦ∞зЪДиКВзВєпЉМжЭ•жО•жЫњжХЕйЪЬиКВзВєзїІзї≠еЃЮжЦљзЫСзЭ£еТМжОІеИґеЈ•дљЬгАВеЈ•дљЬиКВзВєеПѓдї•жЬЙдїїжДПе§ЪдЄ™пЉМжХ∞йЗПдЄКж≤°жЬЙйЩРеИґпЉМиІЖзФ®жИЈйЬАж±ВеЖ≥еЃЪгАВеРДиКВзВєдєЛйЧійАЪињЗзљСзїЬињЫи°МдїїеК°еИЖйЕНеТМи∞ГзФ®пЉМ嚥жИРеИЖжХ£дЄФеНПеРМзЪДеЈ•дљЬж®°еЉПгАВиљѓдїґе±ВйЭҐдЄКпЉМиКВзВєеЃЮиі®жШѓLINUXз≥їзїЯж†єзФ®жИЈдЄЛзЪДдЄАдЄ™ињЫз®ЛпЉМж≤°жЬЙжУНдљЬзХМйЭҐпЉМеЬ®еРОеП∞ињРи°МпЉМеРѓеК®жЧґињРи°МдЄАдЄ™зљСзїЬйАЪдњ°жЬНеК°еЩ®дњЭжМБдЄОе§ЦзХМеѓєиѓЭгАВ
(зВєеЗїеЫЊеГПжФЊе§І)
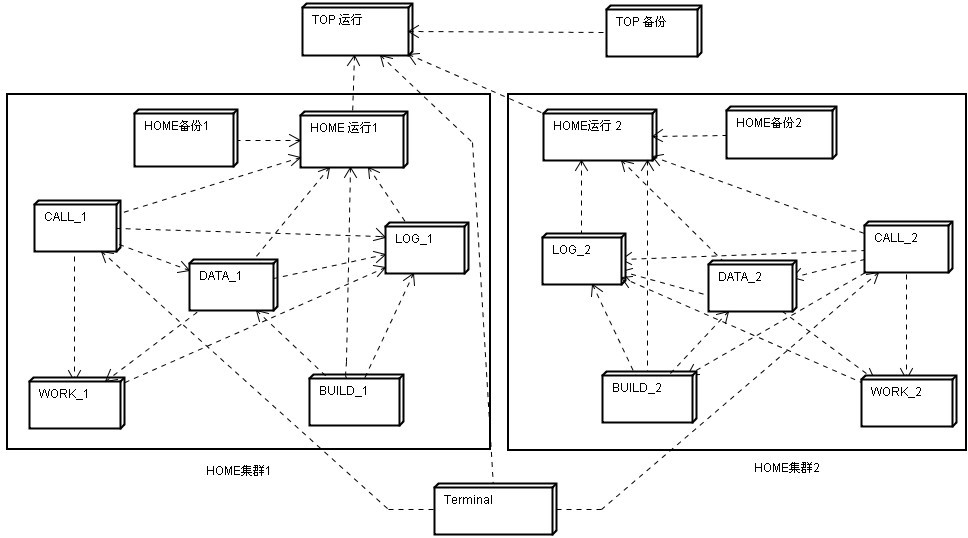
еЫЊ1.1 LAXCUSйЫЖзЊ§
1.3.1 TOPиКВзВє
TOPжШѓзЃ°зРЖиКВзВєпЉМжШѓLAXCUSйЫЖзЊ§зЪДеЯЇз°Аж†ЄењГиКВзВєпЉМењЕй°їдњЭиѓБжЬЙжХИе≠ШеЬ®гАВеЕґеЃГз±їеЮЛзЪДиКВзВєйГљжШѓTOPиКВзВєзЪДдЄЛе±ЮиКВзВєпЉМTOPиКВзВєеЬ®еЕґеЃГиКВзВєеЙНеРѓеК®пЉМеЬ®еЕґеЃГиКВзВєеЕ®йГ®еБЬж≠ҐеРОжЙНиГљеБЬж≠ҐгАВTOPиКВзВєзЪДзЃ°зРЖиМГеЫіеМЕжЛђпЉЪжО•еПЧгАБдњЭе≠ШгАБж£АжЯ•гАБеИЖйЕНжЙАе±ЮзЪДзФ®жИЈзЩїељХиі¶еПЈгАБжУНдљЬжЭГйЩРгАБжХ∞жНЃеЇУйЕНзљЃгАБзљСзїЬиµДжЇРпЉМеРМжЧґжО•еПЧHOMEиКВзВєеТМзїИзЂѓзЪДж≥®еЖМпЉМдї•еПКзЫСжµЛеЃГдїђзЪДињРи°МгАВе¶ВдЄКйЭҐжЙАињ∞пЉМTOPиКВзВєеБЪдЄЇзЃ°зРЖиКВзВєи¶Бж±ВжЬЙе§ЪдЄ™пЉМдљЖжШѓйАЪеЄЄи¶Бж±ВдЄАдЄ™ињРи°МиКВзВєеТМжЬАе∞СдЄАдЄ™е§ЗдїљиКВзВєпЉМеЫ†дЄЇTOPиКВзВєжХЕйЪЬдЉЪйА†жИРжХідЄ™йЫЖзЊ§зЪДињРи°МзЃ°зРЖжЈЈдє±пЉМйЪПжЧґдњЭжМБжЬАе∞СдЄАдЄ™е§ЗдїљиКВзВєжЫњдї£жХЕйЪЬиКВзВєжШѓењЕй°їзЪДгАВTOPе§ЗдїљиКВзВєеЬ®е§ЗзФ®жЬЯйЧіпЉМйЩ§дЇЖзЫСжµЛињРи°МдЄ≠зЪДTOPиКВзВєпЉМињШдЉЪйАЪињЗзљСзїЬеЃЪжЧґе§НеИґеЃГзЪДзЃ°зРЖиµДжЦЩеТМињРи°МжХ∞жНЃгАВељУињРи°МиКВзВєеПСзФЯжХЕйЪЬеРОпЉМеНПеХЖйАЙдЄЊеЗЇзЪДжЦ∞зЪДињРи°МиКВзВєдЉЪйАЪзЯ•еОЯжЭ•зЪДHOMEиКВзВєеТМзїИзЂѓпЉМйЗНжЦ∞ж≥®еЖМеИ∞еЃГзЪДзОѓеҐГдЄЛгАВ
йАЪеЄЄжГЕеЖµдЄЛпЉМTOPиКВзВєеП™зїіжМБдЄНе§ЪзЪДHOMEиКВзВєеТМзїИзЂѓ/еЇФзФ®жО•еП£зЪДйАЪдњ°пЉМжЙАдї•еЃГзЪДзЃ°зРЖдїїеК°еєґдЄНзєБйЗНгАВ
1.3.2 HOMEиКВзВє
HOMEиКВзВєжШѓLAXCUSе≠РйЫЖзЊ§(дєЯзІ∞HOMEйЫЖзЊ§)зЪДзЃ°зРЖиКВзВєпЉМжШѓHOMEйЫЖзЊ§зЪДж†ЄењГгАВеѓєдЄКпЉМеРСTOPиКВзВєж≥®еЖМпЉМжО•еПЧTOPиКВзВєзЪДзЃ°зРЖпЉЫеѓєдЄЛпЉМжО•еПЧжЙАе±ЮйЫЖзЊ§иКВзВєзЪДж≥®еЖМпЉМзЫСжОІеТМеНПи∞ГеЃГдїђињРи°МгАВLAXCUSдЄ≠еЃЪдєЙзЪДеЈ•дљЬиКВзВєеЕ®йГ®ињРи°МеЬ®HOMEйЫЖзЊ§еЖЕгАВHOMEиКВзВєзЪДзЃ°зРЖиМГеЫіеМЕжЛђпЉЪж±ЗжАїеЈ•дљЬиКВзВєзЪДеЕГдњ°жБѓгАБињљиЄ™еЈ•дљЬиКВзВєзЪДињРи°МзКґжАБгАБж£АжµЛзљСзїЬжХЕйЪЬеТМжХЕйЪЬиКВзВєгАБжОІеИґжХ∞жНЃеЭЧеИЖеПСгАБеНПи∞ГйЫЖзЊ§иіЯиљљеЭЗи°°гАВдЄОTOPиКВзВєдЄАж†ЈпЉМHOMEйЫЖзЊ§дєЯи¶Бж±ВдЄАдЄ™ињРи°МиКВзВєеТМжЬАе∞СдЄАдЄ™е§ЗдїљиКВзВєпЉМе§ЗдїљиКВзВєеЃЪжЧґе§НеИґињРи°МиКВзВєдЄКзЪДињРи°МжХ∞жНЃгАВ
1.3.3 LOGиКВзВє
еЬ®жХідЄ™ињРи°МињЗз®ЛдЄ≠пЉМLOGиКВзВєеФѓдЄАзЪДеЈ•дљЬе∞±жШѓжО•жФґеТМдњЭе≠ШеЕґеЃГиКВзВєеПСжЭ•зЪДжЧ•ењЧдњ°жБѓгАВеѓєињЩдЇЫиКВзВєпЉМLOGиКВзВєе∞Жж†єжНЃеЃГдїђзЪДиКВзВєз±їеЮЛеТМиКВзВєеЬ∞еЭАеїЇзЂЛзЫЃељХпЉМжЧ•ењЧжЦЗдїґеРНжШѓељУеЙНжУНдљЬз≥їзїЯжЧ•жЬЯгАВжЧ•ењЧдЄ≠зЪДдЄїи¶Бдњ°жБѓжШѓеРДиКВзВєзЪДеЈ•дљЬжµБз®ЛеТМињРи°МйФЩиѓѓпЉМињЩдЇЫдњ°жБѓиГље§ЯдЄЇеИЖеЄГзКґжАБдЄЛзЪДжХ∞жНЃињљиЄ™еТМеИЖжЮРгАБз®ЛеЇПи∞ГиѓХгАБеЃЪдљНеТМеИ§жЦ≠иКВзВєињРи°МжХЕйЪЬжПРдЊЫйЗНи¶БдЊЭжНЃпЉМжЙАдї•LOGиКВзВєзЪДеЈ•дљЬиЩљзДґзЃАеНХпЉМдљЖжШѓйЭЮеЄЄйЗНи¶БгАВ
1.3.4 CALLиКВзВє
CALLиКВзВєдїЛдЇОLAXCUSйЫЖзЊ§зЪДдЄ≠зїІзОѓиКВпЉМиµЈеИ∞з±їдЉЉиЈѓзФ±еЩ®зЪДдљЬзФ®гАВеѓєе§ЦпЉМеЃГжО•еПЧзїИзЂѓеТМеЇФзФ®жО•еП£зЪДи∞ГзФ®пЉЫеѓєеЖЕпЉМеЃГеЃЪжЧґжФґйЫЖDATAгАБWORKгАБBUILDиКВзВєзЪДињРи°Мдњ°жБѓпЉМжККзїИзЂѓеТМеЇФзФ®жО•еП£зЪДжМЗдї§иљђжНҐжИРеЕЈдљУзЪДжУНдљЬдїїеК°пЉМеИЖжіЊзїЩDATAгАБWORDгАБBUILDиКВзВєжЙІи°МпЉМеєґдЄФеЬ®дЄ≠йЧіеНПи∞ГзљСзїЬиЃ°зЃЧињЗз®ЛпЉМе∞ЖжЬАеРОзЪДиЃ°зЃЧзїУжЮЬињФеЫЮзїЩдїїеК°еПСиµЈжЦєгАВCALLиКВзВєйАЪеЄЄеБЪдЄЇдЄАдЄ™ж†єзФ®жИЈињЫз®ЛзЛђзЂЛињРи°МпЉМдєЯеПѓдї•жШѓдЄАдЄ™WEBжЬНеК°еЩ®пЉИе¶ВTOMCATпЉЙзЪДе≠РињЫз®ЛпЉМзїСеЃЪеЬ®WEBжЬНеК°еЩ®дЄКињРи°МгАВCALLињШжШѓйЫЖзЊ§дЄ≠йЩ§TOPиКВзВєе§ЦпЉМеФѓдЄАдЄОе§ЦзХМдњЭжМБиБФзїЬзЪДиКВзВєгАВ
1.3.5 WORKиКВзВє
WORKиКВзВєеЬ®жХідЄ™ињРи°МињЗз®ЛдЄ≠еП™еБЪдЄАдїґдЇЛпЉЪжО•еПЧCALLиКВзВєи∞ГзФ®пЉМжЙІи°МеЕЈдљУзЪДжХ∞жНЃиЃ°зЃЧгАВеЬ®еЃЮйЩЕеЇФзФ®дЄ≠пЉМWORKиКВзВєзЪДеЈ•дљЬйЗПдЉЪеЊИе§ІпЉМзїПеЄЄеПСзФЯз°ђдїґйГ®дїґдљњзФ®иЊЊиЗ≥жЮБйЩРзЪДиґЕиљљзО∞и±°(е¶ВCPUзЪДдљњзФ®зОЗиЊЊеИ∞100%)гАВе¶ВжЮЬињЩзІНзО∞и±°жМБзї≠е≠ШеЬ®пЉМWORKиКВзВєдЉЪйАЪзЯ•CALLиКВзВєпЉМеЗПе∞СеѓєиЗ™еЈ±зЪДи∞ГзФ®гАВ
1.3.6 DATAиКВзВє
DATAиКВзВєжПРдЊЫжХ∞жНЃе≠ШеВ®жЬНеК°пЉМеЃГзЪДжХ∞жНЃзЃ°зРЖиМГеЫіеМЕжЛђпЉЪеїЇзЂЛгАБж£АжЯ•гАБеЫЮжФґжХ∞жНЃз©ЇйЧіпЉМжО•еПЧSQLжУНзЇµпЉМжЈїеК†гАБж£А糥гАБеИ†йЩ§гАБиљђеПСгАБж£АжЯ•гАБдЉШеМЦжХ∞жНЃгАВDATAиКВзВєжЬЙвАЬзЇІеИЂвАЭж¶ВењµпЉМеИЖдЄЇвАЬдЄїиКВзВєвАЭпЉИPRIME SITEпЉЙеТМвАЬдїОиКВзВєвАЭпЉИSLAVE SITEпЉЙпЉМеЃГдїђзЪДеМЇеИЂеЬ®дЇОжХ∞жНЃе§ДзРЖиМГеЫідЄНеРМгАВдЄїиКВзВєеЕЈжЬЙвАЬиѓї/еЖЩвАЭиГљеКЫпЉМиіЯиі£жХ∞жНЃзЪДжЈїеК†гАБеИ†йЩ§гАБжЫіжЦ∞гАБж£А糥гАБдЉШеМЦеЈ•дљЬпЉМдїОиКВзВєеП™жЙІи°МиѓїжУНдљЬпЉМжЙњжЛЕж£А糥еТМжЭ•иЗ™дЄїиКВзВєзЪДжХ∞жНЃе§ЗдїљеЈ•дљЬгАВзљСзїЬиЃ°зЃЧзЪДеИЭеІЛжХ∞жНЃдєЯдїОDATAиКВзВєдЄКдЇІзФЯпЉМжХ∞жНЃжЭ•жЇРдЄАиИђжШѓSQL SELECTзЪДж£А糥зїУжЮЬпЉМжИЦиАЕж†єжНЃдЄЪеК°иІДеИЩзФЯжИРзЪДдњ°жБѓпЉМињЩдЇЫжХ∞жНЃе∞ЖжПРдЊЫзїЩеРОзї≠зЪДWORKиКВзВєдљњзФ®гАВ
1.3.7 BUILDиКВзВє
BUILDиКВзВєзЪДеЈ•дљЬжШѓе§ДзРЖETLдЄЪеК°(extraceгАБtransformгАБload)пЉМеЃГеЬ®жЙІи°МеЙНдЉЪжФґйЫЖDATAиКВзВєзЪДжХ∞жНЃпЉМзДґеРОжЙІи°МETLе§ДзРЖгАВдЄАиИђзїПињЗBUILDиКВзВєе§ДзРЖеРОзЪДжХ∞жНЃиЃ°зЃЧжХИзОЗдЉЪжЫійЂШгАВз≥їзїЯжПРдЊЫдЇЖдЄАе•ЧAPIжО•еП£пЉМжФѓжМБETLдЄЪеК°жЬНеК°гАВзФ®жИЈйЬАи¶БжіЊзФЯжО•еП£еЃЮзО∞иЗ™еЈ±зЪДдЄЪеК°жµБз®ЛгАВдЄОеЕґеЃГиКВзВєдЄНеРМзЪДжШѓпЉМBUILDиКВзВєеП™еЬ®жФґеИ∞зФ®жИЈжИЦиАЕзЃ°зРЖиКВзВєзЪДдљЬдЄЪжМЗдї§еРОжЙНињЫи°МеЈ•дљЬпЉМйАЪеЄЄжГЕеЖµдЄЛйГље§ДдЇОз©ЇйЧ≤зКґжАБгАВ
1.3.8 зїИзЂѓ
зїИзЂѓжШѓзФ±зФ®жИЈй©±еК®зЪДзХМйЭҐиЊУеЕ•жО•еП£пЉМдЄЇзФ®жИЈжПРдЊЫSQLеТМз±їSQLиѓ≠еП•зЪДињЬз®ЛжУНжОІиГљеКЫгАВ еЃГиГље§ЯеЬ®дїїдљХеПѓдї•иБФзљСзЪДдљНзљЃињРи°МпЉМжШѓдЄАдЄ™зЇѓеЃҐжИЈзЂѓзЪДж¶ВењµгАВжЙАдї•пЉМдїОињЩдЄАзВєдЄ•ж†ЉеЬ∞иѓіпЉМзїИзЂѓеєґдЄНе±ЮдЇОйЫЖзЊ§иМГзХігАВдЄЇйАВеЇФдЄНеРМжУНдљЬз≥їзїЯеТМзФ®жИЈзЪДдљњзФ®дє†жГѓпЉМLAXCUSжПРдЊЫдЇЖдЄ§зІНж®°еЉПзЪДзїИзЂѓпЉЪеЯЇдЇОе≠Чзђ¶зХМйЭҐзЪДLAXCUS ConsoleеТМеЯЇдЇОеی嚥зХМйЭҐзЪДLAXCUS TerminalпЉМе¶ВеЫЊ1.2еТМеЫЊ1.3гАВеی嚥зХМйЭҐзЪДзїИзЂѓдЄїи¶БжШѓиАГиЩСдЇЖWINDOWSзФ®жИЈзЪДйЬАж±ВпЉМиАМдЄУдЄЪзЪДLINUXзФ®жИЈеПѓиГљжЫіеЦЬ搥䚜зФ®е≠Чзђ¶зХМйЭҐгАВдЄ§зІНзїИзЂѓзЪДжУНдљЬжМЗдї§жШѓеЃМеЕ®дЄАж†ЈзЪДгАВ
еЫЊ1.2 LAXCUSе≠Чзђ¶зїИзЂѓ
еЫЊ1.3 LAXCUSеی嚥зїИзЂѓ
ељУеЙНеПСзФЯзЪДеЊИе§Ъе§ІиІДж®°жХ∞жНЃиЃ°зЃЧпЉМдЄАжђ°иЃ°зЃЧй©±еК®еЗ†дЄ™GBзЪДжХ∞жНЃеЈ≤зїПжШѓеНБеИЖжЩЃйБНзЪДзО∞и±°гАВињЩзІНеЬ®зљСзїЬйЧідЉ†йАТпЉМжХ∞йЗПе§ІгАБеПСзФЯйҐСеЇ¶йЂШзЪДжХ∞жНЃе§ДзРЖпЉМйЬАи¶БдњЭиѓБжХ∞жНЃеЕЈжЬЙиґ≥е§ЯзЪДз®≥еЃЪжАІеТМеПѓйЭ†жАІпЉМжЙНиГљж≠£з°ЃеЃМжИРиЃ°зЃЧдїїеК°гАВињЩжШѓдЄАдЄ™е§НжЭВзЪДеЈ•дљЬпЉМењЕй°їеЕЉй°Ње•љжѓПдЄАдЄ™зОѓиКВгАВеЬ®ињЩдЄАзЂ†йЗМпЉМе∞ЖдїОжХ∞жНЃзЪДе≠ШеВ®гАБзїДзїЗгАБеИЖйЕНгАБзїіжК§з≠Йе§ЪдЄ™иІТеЇ¶еОїйШРињ∞жХ∞жНЃзЪДиЃЊиЃ°еТМзЃ°зРЖпЉМдї•еПКе¶ВдљХдЉШеМЦеЃГдїђгАВ
2.1 жХ∞жНЃеЭЧ
еЬ®еЃЮйЩЕзЪДжХ∞жНЃеЇФзФ®дЄ≠пЉМдЄАдЄ™еНХдљНзЪДжХ∞жНЃе∞ЇеѓЄеЊАеЊАжЬЙеЊИе§ІзЪДйЪПжЬЇжАІгАВе∞ПиАЕеПѓиГљжШѓеЗ†еНБдЄ™е≠ЧиКВпЉМе§ІиАЕеПѓиГљиЊЊеИ∞жХ∞еНБеЕЖпЉМзФЪиЗ≥жХ∞зЩЊеЕЖгАВељУдЄАдЄ™йЫЖзЊ§йЗМзЪДиЃ°зЃЧжЬЇпЉМжѓПеП∞иЃ°зЃЧжЬЇзЪДжХ∞жНЃе≠ШеВ®йЗПиЊЊеИ∞TBиІДж®°пЉМжѓП姩еПѓиГље§ДзРЖзЪДжХ∞жНЃиґЕињЗPBйЗПзЇІзЪДжЧґеАЩпЉМеН≥дљњз£БзЫШжЦЗдїґз≥їзїЯжФѓжМБињЩзІНеНХдљНзЪДе≠ШеВ®пЉМдєЯе∞Ждљњз£БзЫШињРи°МдЄН写йЗНиіЯпЉМињЩжШѓжУНдљЬз≥їзїЯдЄНиГљжО•еПЧзЪДпЉМеєґдЄФеЫ†ж≠§дЇІзФЯзЪДз£БзЫШзҐОзЙЗдєЯжШѓеѓєз£БзЫШз©ЇйЧізЪДжЮБе§Іжµ™иієгАВ
йТИеѓєињЩзІНзО∞зКґпЉМLAXCUSиЃЊиЃ°дЇЖдЄАе•ЧжЦ∞зЪДжХ∞жНЃе≠ШеВ®жµБз®ЛпЉМжЭ•дњЭйЪЬйЂШжХИзЪДжХ∞жНЃе§ДзРЖгАВй¶ЦеЕИпЉМеЬ®еЖЕе≠ШзЪДиЗ™зФ±еМЇеЯЯеЉАиЊЯеЗЇдЄАеЭЧеЫЇеЃЪйХњеЇ¶зЪДз©ЇйЧіпЉМж≠§еРОзЪДжѓПдЄАжЙєжХ∞жНЃпЉМз≥їзїЯйГљдї•жµБеЉПзЪДдЄ≤и°МињљеК†жЦєеЉПеЖЩеЕ•гАВињЩж†ЈеН≥дљњељУжЧґжЬЙе§ЪдЄ™еЖЩеЕ•иАЕпЉМеЫ†дЄЇеЖЕе≠Ше§ДзРЖжХИзОЗйҐЗйЂШеТМдЄ≤и°МеЖЩеЕ•зЪДеОЯеЫ†пЉМеЬ®еЖЩеЕ•ињЗз®ЛдЄ≠еЗ†дєОж≤°жЬЙеїґињЯжИЦиАЕеЊИе∞ПпЉМдєЯдЄНдЉЪдЇІзФЯеЖЩеЕ•еЖ≤з™БгАВељУеЖЕе≠Шз©ЇйЧізЪДжХ∞жНЃйЗПиЊЊеИ∞иІДеЃЪйШАеАЉзЪДжЧґеАЩпЉМз≥їзїЯе∞ЖеЖЕе≠Шз©ЇйЧіеЕ≥йЧ≠пЉМеєґдЄФжЙІи°МдЄАз≥їеИЧзЪДжХ∞жНЃдЉШеМЦжО™жЦљпЉМеМЕжЛђеОЛзЉ©еТМйЗНзїДињЩж†ЈзЪДе§ДзРЖпЉМжЬАеРОе∞ЖињЩзЙЗеЖЕе≠ШжХ∞жНЃдї•жЦЗ俴嚥еЉПдЄАжђ°жАІеЖЩеЕ•з£БзЫШгАВињЩдЄ™ињЫеЕ•з£БзЫШзЪДжЦЗдїґпЉМ襀зІ∞дЄЇвАЬжХ∞жНЃеЭЧвАЭгАВ
LAXCUSе∞Жй©їзХЩеЬ®еЖЕе≠ШжЧґзЪДжХ∞жНЃзІ∞дЄЇжХ∞жНЃеЭЧзЪДвАЬCACHEвАЭзКґжАБпЉМеЖЩеЕ•з£БзЫШеРОпЉМ襀зІ∞дЄЇжХ∞жНЃеЭЧзЪДвАЬCHUNKвАЭзКґжАБгАВз≥їзїЯиЃЊзљЃзЪДеЖЕе≠ШжХ∞жНЃеМЇеЯЯзЪДж†ЗеЗЖйШАеАЉжШѓ64MпЉМињЩдЄ™еПВжХ∞дєЯеПѓдї•зФ±зФ®жИЈеЃЪдєЙпЉМжЬАе§ІдЄНиГљиґЕињЗ4GгАВеѓєдЇОиґЕе§Іе∞ЇеѓЄзЪДеЖЕе≠ШжХ∞жНЃеМЇеЯЯпЉМз≥їзїЯе∞ЖиІЖз£БзЫШжЦЗдїґз≥їзїЯеТМеПѓзФ®еЖЕе≠Шз©ЇйЧіиАМеЃЪпЉМе¶ВжЮЬдЄНиГљжФѓжМБпЉМе∞ЖиЗ™еК®и∞ГжХіеИ∞еРИйАВзЪДе∞ЇеѓЄгАВ
дЄЇдЇЖиГље§ЯеМЇеИЖеЖЕе≠ШеТМз£БзЫШдЄКзЪДжѓПдЄАдЄ™жХ∞жНЃеЭЧпЉМз≥їзїЯдЉЪеЬ®жѓПдЄ™жХ∞жНЃеЭЧзФЯжИРжЧґпЉМдЄЇеЃГиЃЊзљЃдЄАдЄ™64дљНзЪДжЧ†зђ¶еПЈйХњжХіжХ∞пЉМеБЪдЄЇеФѓдЄАж†ЗиѓЖеЃГзЪДзЉЦеПЈгАВзЉЦеПЈзФ±TOPињРи°МиКВзВєжПРдЊЫпЉМдњЭиѓБйЫЖзЊ§дЄ≠еФѓдЄАпЉМдЄНдЉЪйЗНе§НгАВжХ∞жНЃеЖЩеЕ•з£БзЫШеРОпЉМињЩдЄ™зЉЦеПЈдєЯжШѓжХ∞жНЃеЭЧзЪДжЦЗдїґеРНгАВ
дЊЭжНЃ1.3.6иКВеѓєDATAиКВзВєзЪДеЃЪдєЙпЉМжХ∞жНЃеЭЧеП™дњЭе≠ШеЬ®DATAиКВзВєдЄКпЉМеєґдЄФдЊЭдїОDATAиКВзВєзЪДдЄїдїОеЕ≥з≥їгАВжЙАжЬЙдЄїиКВзВєдЄКдњЭжЬЙзЪДжХ∞жНЃеЭЧйГљжШѓдЄїеЭЧ(PRIME CHUNK)пЉМдїОиКВзВєдњЭе≠ШдїОеЭЧ(SLAVE CHUNK)гАВжХ∞жНЃеЭЧзЪДдЄїдїОиІТиЙ≤дЉЪж†єжНЃжЙАе±ЮDATAиКВзВєзЇІеИЂеПСзФЯеПШеМЦгАВдЄАдЄ™йЫЖзЊ§дЄКпЉМеРМиі®жХ∞жНЃеЭЧеП™еЕБиЃЄжЛ•жЬЙдЄАдЄ™дЄїеЭЧпЉМеЕґеЃГйГљжШѓдїОеЭЧгАВеЖЩжХ∞жНЃзЪДдЉ†еЕ•пЉМзФ±CALLиКВзВєиіЯиі£еЃЮжЦљпЉМеРСзЫЄеЕ≥зЪДDATAдЄїиКВзВєеЭЗеМАжО®йАБпЉМињЩж†ЈеПѓдї•дљњињЩдЇЫDATAдЄїиКВзВєпЉМеЬ®еРДиЗ™жЛ•жЬЙзЪДжХ∞жНЃйЗПдЄКдњЭжМБдЄАдЄ™зЫЄеѓєеЭЗи°°зЪДзКґжАБгАВ
з≥їзїЯдЄНдЉЪеЬ®йЭЮDATAиКВзВєдЄКзЉУе≠ШжХ∞жНЃпЉМињЩдЄ™иЃЊиЃ°жШѓеПВиАГдЇЖе§ІйЗПеЃЮдЊЛеРОеБЪзЪДеЖ≥еЃЪгАВзїПзїЯиЃ°пЉМеНХдљНжЧґйЧіеЖЕзЪДзљСзїЬиЃ°зЃЧпЉМдЄАдЄ™жМЗ俧襀йЗНе§НжЙІи°МзЪДж¶ВзОЗжЮБдљОпЉМињЩе∞±ињЮеЄ¶ељ±еУНеИ∞жХ∞жНЃзЪДйЗНе§НеСљдЄ≠зОЗпЉМдљњеЊЧеЬ®еЖЕе≠ШйЗМзЉУе≠ШжХ∞жНЃж≤°жЬЙжДПдєЙпЉМеєґдЄФзЉУе≠ШжХ∞жНЃдЉЪеН†зФ®е§ІйЗПеЃЭиіµзЪДеЖЕе≠Шз©ЇйЧіпЉМжШЊеЊЧеЊЧдЄНеБње§±гАВ
жХ∞жНЃеЭЧзЪДйЗЗзФ®пЉМеЊИе•љеЬ∞жґИйЩ§дЇЖз£БзЫШзҐОзЙЗзЪДзО∞и±°пЉМдєЯеЗПиљїжХ∞жНЃиЊУеЕ•з£БзЫШжЧґзЪДеЖЩе§ДзРЖеОЛеКЫгАВжМЙзЕІжХ∞жНЃеЭЧж†ЗеЗЖзЪД64MиЃ°зЃЧпЉМжХ∞жНЃеЖЩеЕ•з£БзЫШзЪДжЧґйЧідЄНдЉЪиґЕињЗ1зІТгАВж£А糥жХ∞жНЃжЧґпЉМе∞ЖжМЙзЕІдЉШеМЦиІДеИЩдїОз£БзЫШиѓїеПЦжХ∞жНЃпЉМињЩж†ЈдєЯйЩНдљОдЇЖжХ∞жНЃиЊУеЗЇињЗз®ЛзЪДиѓїе§ДзРЖеОЛеКЫгАВ
2.2 е≠ШеВ®ж®°еЮЛ
е≠ШеВ®ж®°еЮЛжШѓжХ∞жНЃеЬ®з£БзЫШдЄКзЪДзЙ©зРЖзїДзїЗзїУжЮДгАВеЬ®иЃЄе§ЪдїЛзїНжХ∞жНЃеЇУзЪДдє¶з±НйЗМпЉМе≠ШеВ®ж®°еЮЛеПИ襀зІ∞дЄЇеЖЕж®°еЮЛгАВеЃГеЬ®еЊИе§Із®ЛеЇ¶дЄКеЖ≥еЃЪдЇЖжХ∞жНЃзЪДеПѓеЇФзФ®иМГеЫіпЉМжШѓи°°йЗПжХ∞жНЃе≠ШеПЦжАІиГљзЪДйЗНи¶БжМЗж†ЗдєЛдЄАгАВ
LAXCUSеЬ®жХ∞жНЃеЭЧзЪДеЯЇз°АдЄКеЃЮзО∞дЇЖи°Ме≠ШеВ®ж®°еЮЛ(NSM)еТМеИЧе≠ШеВ®ж®°еЮЛ(DSM)гАВеЫ†дЄЇдЄ§зІНе≠ШеВ®ж®°еЮЛзЪДзїДзїЗзїУжЮДеЃМеЕ®дЄНеРМпЉМдї•дЄЛе∞ЖзїУеРИеЫЊ2.1еТМжХ∞жНЃињРдљЬжµБз®ЛпЉМжЭ•йШРињ∞ињЩдЄ§зІНе≠ШеВ®ж®°еЮЛзЪДзЙєзВєеПКдЉШеК£гАВ
ињЩжШѓдЄАдЄ™зљСзїЬйЯ≥дєРжЦЗдїґи°®пЉМзФ±6дЄ™е±ЮжАІзїДжИРгАВеЫЊ2.1еЈ¶дЊІжШѓи°Ме≠ШеВ®ж®°еЮЛпЉМжѓПдЄАи°МзФ±дЄНеРМе±ЮжАІзЪДеИЧеАЉзїДжИРпЉМжХ∞жНЃжШѓдїОеЈ¶еИ∞еП≥гАБдїОдЄКеИ∞дЄЛзЪДжОТеИЧпЉМ嚥жИРи°МдЄОи°МињЮжО•зЪДеЄГе±АгАВеЫЊ2.1еП≥дЊІжШѓеИЧе≠ШеВ®ж®°еЮЛпЉМеРМе±ЮжАІзЪДеИЧеАЉиҐЂзїДзїЗеЬ®дЄАиµЈпЉМжИРдЄЇеИЧзЪДйЫЖеРИпЉМжХ∞жНЃжШѓдїОдЄКеРСдЄЛгАБдїОеЈ¶еИ∞еП≥зЪДжОТеИЧпЉМ嚥жИРеИЧйЫЖеРИдЄОеИЧйЫЖеРИињЮжО•зЪДеЄГе±АгАВ
е¶В2.1иКВжЙАињ∞пЉМи°М/еИЧе≠ШеВ®ж®°еЮЛйГљжШѓеїЇзЂЛеЬ®жХ∞жНЃеЭЧзЪДеЯЇз°АдЄКгАВCACHEзКґжАБжЧґпЉМжХ∞жНЃзЪДиѓї/еЖЩе§ДзРЖйГљеЬ®еЖЕе≠ШдЄ≠ињЫи°МпЉМиЩљзДґдЄ§зІНе≠ШеВ®ж®°еЮЛзЪДзїДзїЗзїУжЮДдЄНе∞љзЫЄеРМпЉМдљЖжШѓеЫ†дЄЇеЖЕе≠Ше§ДзРЖжХИзОЗйҐЗйЂШпЉМињЩдЄ™йЧЃйҐШеЬ®йАЯеЇ¶йЭҐеЙНе∞±жШЊз§ЇеЊЧеЊЃдЄНиґ≥йБУгАВжФЊеИ∞еЃЮйЩЕзОѓеҐГдЄ≠ж£Ай™МпЉМйАЪињЗињљиЄ™дЄ§дЄ™е≠ШеВ®ж®°еЮЛзЪДжХ∞жНЃе§ДзРЖжµБз®ЛпЉМеПСзО∞еЃГдїђзЪДе§ДзРЖжХИзОЗзЪДз°Ѓж≤°жЬЙеЈЃеИЂпЉМжЙАдї•дЄ§зІНе≠ШеВ®ж®°еЮЛиЩљзДґзїУжЮДдЄНеРМпЉМдљЖжШѓеЬ®CACHEзКґжАБеПѓдї•еЃМеЕ®ењљзХ•гАВ
еЈЃеЉВдЄїи¶БдљУзО∞еЬ®жХ∞жНЃеЭЧзЪДCHUNKзКґжАБгАВињЫи°МCHUNKзКґжАБеРОпЉМжХ∞жНЃе§ДзРЖе∞ЖеЬ®з£БзЫШдЄКжЙІи°МгАВи°Ме≠ШеВ®жШѓдї•и°МдЄЇеНХдљНпЉМиЛ•жХіи°МиѓїеПЦпЉМйВ£дєИи°Ме≠ШеВ®жХИзОЗеЊИйЂШпЉЫе¶ВжЮЬиѓїеПЦе§Ъи°МпЉМжЬАе•љеЬ®жХ∞жНЃеЖЩеЕ•еЙНе∞Ж襀ж£А糥зЪДжХ∞жНЃжОТеИЧеЬ®дЄАиµЈпЉМињЩж†ЈеП™йЬАи¶Беѓєз£БзЫШеБЪдЄАжђ°еЃЪдљНеТМиѓїеПЦгАВеРМж†ЈзЪДпЉМеИЧе≠ШеВ®жШѓдї•еИЧйЫЖеРИдЄЇеНХдљНпЉМеЃГйАВеРИеѓєеНХеИЧињЮзї≠жХ∞жНЃзЪДиѓїеПЦпЉМе¶ВжЮЬиѓїеПЦе§ЪеИЧжХ∞жНЃпЉМе∞±йЬАи¶БжЙЂжППдЄНеРМзЪДз£БзЫШдљНзљЃпЉМињЩдЉЪйЩНдљОз£БзЫШж£А糥жХИзОЗгАВ
жХ∞жНЃеЭЧCHUNKзКґжАБзЪДеЖЩе§ДзРЖпЉМеП™дЉЪеПСзФЯеИ†йЩ§еТМжЫіжЦ∞жУНдљЬгАВеЫ†дЄЇжЫіжЦ∞襀еИЖиІ£дЄЇеИ†йЩ§еТМињљеК†пЉМжЙАдї•еЃЮиі®дїНзДґжШѓеИ†йЩ§жУНдљЬгАВеИ†йЩ§жУНдљЬдЄНдЉЪе∞ЖжХ∞жНЃдїОз£БзЫШдЄ≠жЄЕйЩ§пЉМеП™еЬ®жХ∞жНЃзЪДжЯРдЄ™дљНзљЃеБЪдЄАдЄ™жЧ†жХИж†ЗиЃ∞гАВе¶ВжЮЬжШѓжЙєйЗПеИ†йЩ§пЉМе∞±йЬАи¶БеИЖеИЂеБЪе§ЪдЄ™жЧ†жХИж†ЗиЃ∞пЉМињЩзІНжУНдљЬеѓєз£БзЫШжАІиГљељ±еУНеЊИе§ІгАВ
дљЖжШѓеЬ®еЃЮйЩЕеЇФзФ®жЧґдЄНжШѓињЩж†ЈгАВж†єжНЃз£БзЫШ(жЄ©ељїжЦѓзЙєз°ђзЫШ)еЈ•дљЬзЙєжАІпЉМдЄАдЄ™еЃМжХізЪДиѓї/еЖЩе§ДзРЖпЉМеИЖдЄЇз£Бе§іеЃЪдљНгАБз≠ЙеЊЕгАБжХ∞жНЃдЉ†иЊУдЄЙдЄ™йШґжЃµгАВдїОзЫЃеЙНз£БзЫШжАІиГљзЪДеПСе±ХиґЛеКњжЭ•зЬЛпЉМеЄ¶еЃљйАЯзОЗзЪДжПРеНЗдЉШдЇОз£Бе§іеЃЪдљНпЉМеЖµдЄФзО∞еЬ®иЃ°зЃЧжЬЇзЪДеЖЕе≠ШеЃєйЗПеЈ≤зїПиґ≥е§Яе§ІпЉМзЉУе≠ШдЄАдЇЫжХ∞жНЃдєЯзї∞зї∞жЬЙдљЩгАВж†єжНЃињЩзІНжГЕеЖµпЉМеЃЮйЩЕзЪДиѓї/еЖЩе§ДзРЖпЉМжШѓе∞ЖйЬАи¶БзЪДжХ∞жНЃдЄАжђ°жАІи∞ГеЕ•еЖЕе≠ШпЉМеЬ®еЖЕе≠ШдЄ≠еЃМжИРе§ДзРЖеРОеЖНиЊУеЗЇгАВињЩзІНе§ДзРЖжЦєеЉПпЉМйЭЮеЄЄжЬЙеК©дЇОжПРйЂШз£БзЫШе§ДзРЖжХИзОЗгАВ
еЬ®еЕґеЃГжЦєйЭҐпЉМеИЧе≠ШеВ®ж®°еЮЛзЪДжХ∞жНЃжШѓеПѓдї•еОЛзЉ©зЪДпЉМеОЛзЉ©зЪДзЫіжО•дЉШеКње∞±жШѓиГље§ЯиКВзЬБз£БзЫШеТМеЖЕе≠ШзЪДз©ЇйЧігАВжѓФе¶ВељУжЯРдЄАеИЧжЬЙ10дЄ™999зЪДжХіжХ∞жЧґпЉМе∞±дЄНењЕжКК10дЄ™999дЊЭжђ°жОТеИЧпЉМиАМжШѓеЬ®999еЙНйЭҐеК†дЄАдЄ™10пЉМе∞±и°®иЊЊдЇЖ10дЄ™999зЪДеРЂдєЙгАВи°Ме≠ШеВ®ж®°еЮЛеИЩж≤°жЬЙињЩжЦєйЭҐзЪДиГљеКЫгАВеИЧе≠ШеВ®ж®°еЮЛзЪДеАЉињШеПѓдї•иЗ™еК®жИР䪯糥еЉХдљњзФ®пЉМзЬБзХ•дЇЖзФ®жȣ职皁糥еЉХињЩдЄАж≠•й™§пЉМеЕґдЉШеКњйЩ§дЇЖиКВзЬБз£БзЫШеТМеЖЕе≠Шз©ЇйЧіпЉМињШеЫ†дЄЇж≤°жЬЙдЇЖеЕ≥иБФжУНдљЬпЉМзЃАеМЦдЇЖе≠ШеВ®е±ВйЭҐдЄКзЪДиЃ°зЃЧгАВи°Ме≠ШеВ®ж®°еЮЛе¶ВжЮЬдљњзԮ糥еЉХпЉМеИЩйЬАи¶БзФ®жИЈиѓіжШОеЕЈдљУзЪДеИЧпЉМеєґдЄФеЬ®и°МжХ∞жНЃйЫЖеРИдєЛе§ЦеЉАиЊЯдЄАеЭЧ糥еЉХжХ∞жНЃз©ЇйЧіпЉМе§ДзРЖеЙНињЫи°МеЕ≥иБФжЙНиГљзФЯжХИгАВ
зїЉдЄКжЙАињ∞пЉМи°М/еИЧе≠ШеВ®ж®°еЮЛеЬ®CACHEзКґжАБзЪДе§ДзРЖжАІиГљжМБеє≥гАВеЬ®CHUNKзКґжАБпЉМи°Ме≠ШеВ®ж®°еЮЛйАВеРИжХіи°МиѓїеПЦпЉМеИЧе≠ШеВ®ж®°еЮЛйАВеРИеНХеИЧиѓїеПЦгАВCHUNKзКґжАБзЪДеЖЩе§ДзРЖпЉМеЫ†дЄЇжХ∞жНЃеЬ®еЖЕе≠ШињЫи°МпЉМеЃГдїђе§ДзРЖжАІиГљдїНзДґеЯЇжЬђдЄАиЗігАВ
(зВєеЗїеЫЊеГПжФЊе§І)

еЫЊ2.1 и°Ме≠ШеВ®ж®°еЮЛеТМеИЧе≠ШеВ®ж®°еЮЛ
2.3 и°МзЇІйФБ
дїОжХ∞жНЃзїДзїЗзЪДйАїиЊСиІТеЇ¶жЭ•зЬЛпЉМвАЬи°МвАЭжШѓиГље§Яи°®ињ∞дЄАдЄ™еЃМжХідњ°жБѓзЪДжЬАе∞ПеНХдљНгАВдЄЇдЇЖдњЭиѓБжХ∞жНЃдЄАиЗіжАІпЉМйШ≤ж≠Ґе§ЪжЦєжУНдљЬзЂЮзФ®еПѓиГљеЉХиµЈзЪДжХ∞жНЃжЈЈдє±пЉМLAXCUSеЬ®вАЬи°МвАЭињЩдЄ™е±ВзЇІеѓєжХ∞жНЃжЙІи°МйФБеЃЪжУНдљЬпЉМињЩдЄ™иЃЊиЃ°зРЖењµдЄОеЕ≥з≥їжХ∞жНЃеЇУеЃМеЕ®дЄАиЗігАВи°МзЇІйФБжШѓдЄАдЄ™дЇТжЦ•йФБпЉМеЬ®дЄАдЄ™жЧґйЧіеЖЕеП™еЕБиЃЄжЙІи°Ме§ЪиѓїжИЦиАЕеНХеЖЩжУНдљЬгАВеЫ†дЄЇеЃГзЪДз≤ТеЇ¶иґ≥е§ЯзїЖпЉМеП™еѓєеНХдЄ™и°МињЫи°МжУНдљЬпЉМдЄНдЉЪжґЙеПКеИ∞еЕґеЃГи°МпЉМжЙАдї•еЗ†дєОеѓєжХідЄ™йЫЖзЊ§иЃ°зЃЧж≤°жЬЙдїАдєИељ±еУНгАВзЫЃеЙНи°МзЇІйФБеЬ®и°М/еИЧдЄ§дЄ™е≠ШеВ®ж®°еЮЛдЄКйГљеЈ≤зїПеЊЧеИ∞жКАжЬѓеЃЮзО∞гАВ
2.4 еЕГдњ°жБѓ
дЄЇдЇЖењЂйАЯеЃЪдљНеТМиЃ°зЃЧжХ∞жНЃпЉМеЕГдњ°жБѓеБЪдЄЇжХ∞жНЃжУНдљЬиАЕеТМ襀жУНдљЬеѓєи±°дєЛйЧізЪДдЄ≠йЧіе™Тиі®пЉМжЭ•йЕНеРИеЃМжИРињЩй°єеЈ•дљЬгАВеЕГдњ°жБѓзЪДжЬђиі®жШѓеЃЮдљУиµДжЇРзЪДжКљи±°жППињ∞пЉМеМЕжЛђиКВзВєеЕГдњ°жБѓеТМжХ∞жНЃеЕГдњ°жБѓпЉМеЙНиАЕзФ±зљСзїЬеЬ∞еЭАгАБињРи°МеПВжХ∞зїДжИРпЉМеРОиАЕе∞ЖжХ∞жНЃеЭЧзЪДвАЬеИЧвАЭж†ЉеЉПеМЦдЄЇ4иЗ≥16е≠ЧиКВдЄНз≠ЙзЪДжХ∞еАЉпЉМжМЙй°ЇеЇПжОТеИЧгАВ
еЕГдњ°жБѓзЪДжХ∞жНЃйЗПйГљеЊИе∞ПпЉМеЬ®жЙАеЬ®иКВзВєзЪДињРи°МињЗз®ЛдЄ≠дЇІзФЯпЉМйЪПиКВзВєињРи°МеПСзФЯеПШеМЦеТМжЫіжЦ∞гАВињЩдЇЫзЙєзВєдљњеЃГйАВеРИеЬ®еЖЕе≠ШдЄ≠й©їзХЩпЉМжЙІи°МењЂйАЯиЃ°зЃЧгАВдЇІзФЯеЕГдњ°жБѓзЪДиКВзВєдЉЪдЄНеЃЪжЬЯзЪДпЉМеРСеЃГзЪДдЄКзЇІзЃ°зРЖиКВзВєжПРдЇ§еЕГдњ°жБѓпЉМзЃ°зРЖиКВзВєж†єжНЃињЩдЇЫеЕГдњ°жБѓжМЙиІДеИЩињЫи°Мж±ЗжАїеТМжОТеИЧгАВйЬАи¶БеЕГдњ°жБѓзЪДиКВзВєпЉМеРСеЃГзЪДдЄКзЇІзЃ°зРЖиКВзВєзФ≥иѓЈеТМиОЈеПЦпЉМе≠ШеВ®еЬ®жЬђеЬ∞еЖЕе≠ШдЄ≠пЉМеєґе∞ЖеЕГдњ°жБѓйЗНжЦ∞з≠ЫйАЙеТМжОТеИЧпЉМ嚥жИРдЄАзІН籿䊊糥еЉХзЪДжХ∞жНЃзїУжЮДпЉМдЄЇеРОзї≠зЪДжХ∞жНЃиЃ°зЃЧжПРдЊЫењЕи¶БзЪДеИ§жЦ≠еТМеЗЖе§ЗдЊЭжНЃгАВ
2.5 еЖЕе≠Шж®°еЉП
жХ∞жНЃеЭЧе≠ШеВ®еЬ®з£БзЫШдЄКпЉМеПЧеИґдЇОз£БзЫШжАІиГљзЪДйЩРеИґпЉМеЕґиѓїеЖЩжХИзОЗзЫЄиЊГдЇОCPUеТМеЖЕе≠ШдЄ•йЗНжїЮеРОпЉМжЛЦжЕҐдЇЖжХідЄ™иЃ°зЃЧињЗз®ЛгАВе∞§еЕґеЬ®йЭҐеѓєзГ≠зВєжХ∞жНЃеЭЧиѓїеЖЩпЉМжИЦиАЕйЬАи¶БжПРеПЦе§ІйЗПжХ∞жНЃиЃ°зЃЧжЧґпЉМињЩдЄ™ељ±еУНе∞§еЕґжШОжШЊгАВдЄАдЄ™зЃАеНХзЪДеКЮж≥ХжШѓжККжХ∞жНЃеЭЧи∞ГеЕ•еЖЕе≠ШпЉМдљњеЕґдї•жО•ињСCPUзЪДйАЯеЇ¶ињРи°МпЉМеПѓдї•жЬЙжХИеЗПе∞Сз£БзЫШеѓєжХ∞жНЃзЪДељ±еУНгАВ
з≥їзїЯжПРдЊЫдЇЖдЄ§дЄ™еК†иљљжХ∞жНЃеЭЧзЪДжЦєж°ИпЉЪ1.ељУеЖЕе≠Шз©ЇйЧіжѓФиЊГеЕЕи£ХжЧґпЉМзФ±з≥їзїЯеИ§жЦ≠пЉМжККзГ≠зВєжХ∞жНЃеЭЧи∞ГеЕ•еЖЕе≠ШгАВ 2.зФ±зФ®жИЈеЖ≥еЃЪпЉМйАЪињЗзїИзЂѓжИЦиАЕеЇФзФ®жО•еП£еПСйАБжМЗдї§пЉМжМЗеЃЪжЯРдЇЫжИЦиАЕжЯРеП∞иЃ°зЃЧжЬЇдЄКзЪДжХ∞жНЃеЭЧпЉМжККеЃГдїђеК†иљљеИ∞еЖЕе≠ШйЗМгАВеК†иљљжХ∞жНЃзЪДињЗз®ЛдЄ≠пЉМз≥їзїЯдЉЪеИ§жЦ≠иЃ°зЃЧжЬЇзЪДеЃЮйЩЕеЖЕе≠ШеЃєйЗПпЉМеЬ®жО•ињСйЩРеИґеЙНдЉЪеБЬж≠ҐпЉМдЄНдЉЪеПСзФЯеЖЕе≠ШжЇҐеЗЇзЪДзО∞и±°гАВ
е¶ВжЮЬжШѓз≥їзїЯеК†иљљзЪДжХ∞жНЃеЭЧпЉМињЩдЄ™и∞ГзФ®жШѓдЄіжЧґзЪДпЉМзГ≠зВєжХ∞жНЃеЭЧдЉЪжМБзї≠еПЧеИ∞зЫСиІЖпЉМељУдљОдЇОи∞ГзФ®йШАеАЉпЉМжИЦиАЕеЖЕе≠ШжЬЙйЩРпЉМдљњзФ®йҐСзОЗжЫійЂШзЪДжХ∞жНЃеЭЧйЬАи¶БеК†еЕ•жЧґпЉМдЉЪжККеЃГдїОеЖЕе≠ШдЄ≠зІїеЗЇгАВ
зФ®жИЈдєЯеПѓдї•еБЪеПНеРСжУНдљЬпЉМжККжХ∞жНЃеЭЧдїОеЖЕе≠ШдЄ≠йЗКжФЊпЉМеРМж†ЈжШѓйАЪињЗзїИзЂѓжИЦиАЕеЇФзФ®жО•еП£ињЫи°МгАВ
еЖЕе≠Шж®°еЉПдЄНељ±еУНжХ∞жНЃзЪДеЖЩжУНдљЬпЉМе¶ВжЮЬжШѓжЈїеК†гАБеИ†йЩ§гАБжЫіжЦ∞жГЕеЖµпЉМдЉЪеРМж≠•дњЃжФєеЬ®еЖЕе≠ШеТМз£БзЫШзЪДжХ∞жНЃеЭЧгАВ
еЖЕе≠Шж®°еЉПжЫійАВеРИеП™иѓїжУНдљЬпЉМињЩеТМе§ІиІДж®°жХ∞жНЃж£А糥йЬАж±ВеМєйЕНгАВе∞§еЕґеЬ®дїК姩еЊИе§ЪCPUйГљеЈ≤зїПжШѓ64дљНпЉМеѓїеЭАиМГеЫіз™Бз†і4GйЩРеИґзЪДжГЕеЖµдЄЛпЉМеЖЕе≠ШеПѓдї•еЕЕељУдЄАдЄ™дЄіжЧґзЪДжХ∞жНЃдїУеЇУпЉМжШѓдЄАдЄ™жПРеНЗжХ∞жНЃиЃ°зЃЧжХИзОЗзЪДе•љеКЮж≥ХгАВ
2.6 ењЂзЕІеТМе§Здїљ
жѓПдЄАдЄ™CACHEзКґжАБзЪДдЄїжХ∞жНЃеЭЧпЉМеЬ®дЄїиКВзВєдЄКзФЯжИРеРОпЉМдЉЪйАЪињЗзљСзїЬеЃЪеРСйАЪзЯ•еЕґеЃГеЗ†дЄ™еЕ≥иБФиКВзВєпЉМдЇІзФЯзЫЄеРМзЉЦеПЈзЪДCACHEжХ∞жНЃеЭЧгАВж≠§еРОињЩдЄ™дЄїжХ∞жНЃеЭЧпЉМжѓПдЄАжђ°еЖЩжУНдљЬпЉМйГљдЉЪйАЪињЗзљСзїЬеРСеЃГдїђдЉ†йАТељУеЙНжХ∞жНЃзЪДе§НжЬђгАВињЩдЇЫдї•е§Нжܐ嚥еЉПе≠ШеЬ®зЪДCACHEзКґжАБжХ∞жНЃеЭЧпЉМ襀зІ∞дЄЇвАЬењЂзЕІвАЭгАВ
жѓПдЄАдЄ™дЄїжХ∞жНЃеЭЧпЉМдїОCACHEзКґжАБиљђеЕ•CHUNKзКґжАБеРОпЉМдЄїиКВзВєе∞ЖзЂЛеН≥еРѓеК®пЉМйАЪињЗзљСзїЬеИЖеПСињЩдЄ™жХ∞жНЃеЭЧзЪДжХ∞жНЃе§НжЬђгАВињЩдЇЫ襀䊆жТ≠еИ∞дЄНеРМиКВзВєзЪДжХ∞жНЃеЭЧпЉМ襀зІ∞дЄЇвАЬе§ЗдїљвАЭгАВе§ЗдїљдєЯе∞±жШѓ2.1иКВжЙАињ∞зЪДдїОеЭЧгАВ
е§ЗдїљжХ∞жНЃеЭЧдЉ†йАТеЃМжИРеРОпЉМдЄїDATAиКВзВєдЉЪйАЪзЯ•еЕ≥иБФзЪДDATAиКВзВєпЉМе∞ЖCACHEзКґжАБзЪДвАЬењЂзЕІвАЭеИ†йЩ§гАВж≠§еРОзЪДињРи°МињЗз®ЛдЄ≠пЉМе¶ВжЮЬеПСзФЯеЖЩжУНдљЬпЉМCHUNKзКґжАБзЪДдЄїжХ∞жНЃеЭЧдїНдЉЪжЙІи°МдЄОењЂзЕІдЄАж†ЈзЪДе§ДзРЖгАВ
ењЂзЕІеТМе§ЗдїљзЪДеИЖйЕНпЉМе∞Жж†єжНЃйЫЖзЊ§зЪДзљСжЃµеОЯеИЩињЫи°МйАЙжЛ©гАВињЩжШѓдЄАдЄ™з±їдЉЉLINUX TRACEROUTEеСљдї§зЪДе§ДзРЖињЗз®ЛпЉМйАЪињЗеРСдЄНеРМDATAиКВзВєеПСйАБICMPеМЕпЉМжОҐжµЛељУеЙНиКВзВєдЄОзЫЃж†ЗиКВзВєзЪДиЈ≥зВєжХ∞пЉМеИ§жЦ≠зљСжЃµдєЛйЧізЪДиЈЭз¶їпЉМжМЙзЕІзФ±ињЬеПКињСзЪДй°ЇеЇПињЫи°МеИЖйЕНгАВ
з≥їзїЯиІДеЃЪеРМиі®жХ∞жНЃеЭЧзЪДйїШиЃ§е≠ШйЗПжШѓ3пЉМеН≥жЬЙ1дЄ™дЄїеЭЧпЉМ2дЄ™е±ЮдЇОењЂзЕІжИЦиАЕе§ЗдїљзЪДдїОеЭЧгАВдЄїеЭЧеЕБиЃЄжЙІи°Миѓї/еЖЩе§ДзРЖпЉМдїОеЭЧеП™иГљжЙІи°Миѓїе§ДзРЖпЉМеТМжО•еПЧдЄїеЭЧзЪДеОЯеІЛжХ∞жНЃи¶ЖеЖЩжУНдљЬгАВињЩдЄ™еПВжХ∞дєЯеПѓдї•зФ±зФ®жИЈеЃЪдєЙпЉМдљЖеЬ®ињРи°МжЧґе∞ЖеПЧеИ∞еЕЈдљУзОѓеҐГзЪДйЩРеИґпЉМе¶ВжЮЬеЃЮйЩЕиКВзВєе≠ШйЗПдЄНиґ≥пЉМе∞ЖеП™иГљжї°иґ≥еИ∞жЬАе§ІеПѓзФ®жХ∞йЗПи¶Бж±ВгАВ
ењЂзЕІеТМе§ЗдїљдљњеРМиі®жХ∞жНЃеЭЧдєЛйЧідњЭжМБдЇЖеОЯеІЛзЇІзЪДжХ∞жНЃдЄАиЗіжАІпЉМеРМжЧґињШеЃЮзО∞дЇЖеИЖиІ£иѓїе§ДзРЖеОЛеКЫгАБиіЯиљљеє≥и°°гАБеЖЧзБЊжБҐе§НзЪДзЫЃзЪДгАВе¶ВжЮЬељУжЯРдЄ™жХ∞жНЃеЭЧиѓїжУНдљЬеОЛеКЫињЗе§ІжЧґпЉМињЩдЄ™DATAиКВзВєдЉЪеРСHOMEиКВзВєжПРеЗЇиѓЈж±ВпЉМHOMEиКВзВєдЉЪињЫи°МеНПи∞ГпЉМе∞ЖињЩдЄ™жХ∞жНЃеЭЧеИЖеПСеИ∞еЕґеЃГз©ЇйЧ≤DATAиКВзВєдЄКпЉМдї•йЩНдљОиѓЈж±ВиКВзВєзЪДиѓїеПЦеОЛеКЫгАВжИЦиАЕжЯРдЄ™DATAдЄїиКВзВєеПСзФЯињРи°МжХЕйЪЬпЉМHOMEиКВзВєиГље§ЯењЂйАЯжДЯзЯ•пЉМзДґеРОж†єжНЃжХ∞жНЃеЭЧзЉЦеПЈпЉМдїОзЫЄеРМзЪДењЂзЕІжИЦиАЕе§ЗдїљдЄ≠йАЙжЛ©дЄАдЄ™пЉМжККеЃГеИЖеПСеИ∞жЯРдЄ™ж≠£еЄЄзЪДDATAдЄїиКВзВєпЉМеНЗзЇІдЄЇдЄїжХ∞жНЃеЭЧпЉМжЭ•еПЦдї£жХЕйЪЬжХ∞жНЃеЭЧгАВйАЙжЛ©зЪДдЊЭжНЃжШѓжЧґйЧіпЉМеЬ®жЙАжЬЙењЂзЕІжИЦиАЕе§ЗдїљдЄ≠пЉМдї•жЦЗдїґдњЃжФєжЧ•жЬЯжЬАжЦ∞зЪДйВ£дЄ™дЄЇеЗЖгАВ
2.7 еЃМжХіжАІж£АжЯ•
DATAиКВзВєеРѓеК®жЧґпЉМдЉЪеѓєз£БзЫШдЄКзЪДжѓПдЄ™жХ∞жНЃеЭЧињЫи°МжЙЂжППпЉМж£А糥еЃГзЪДжХ∞жНЃеЃМжХіжАІгАВжЙЂжППе∞Жй¶ЦеЕИеИ§жЦ≠жХ∞жНЃеЭЧзЪДе≠ШеВ®ж®°еЮЛпЉМеЖНеИЖеИЂињЫи°Ме§ДзРЖпЉМеЕЈдљУеИ∞жХ∞жНЃеЭЧзЪДжѓПдЄАи°МжИЦиАЕеИЧйЫЖеРИгАВе¶ВжЮЬжЙЂжППињЗз®ЛдЄ≠еПСзО∞йФЩиѓѓпЉМе∞ЖињЫеЕ•жЪВеБЬзКґжАБпЉМйАЪињЗзљСзїЬзФ≥иѓЈдЄАжЃµж≠£з°ЃзЪДжХ∞жНЃе§НжЬђпЉМжЭ•и¶ЖзЫЦйФЩиѓѓзЪДжХ∞жНЃгАВжХ∞жНЃеЭЧзЪДжЙЂжППеЬ®еЖЕе≠ШдЄ≠ињЫи°МпЉМеЃМжИРеРОйЗКжФЊгАВжЙЂжППйЗЗзФ®CRC32ж†°й™МеТМзЃЧж≥ХпЉМињЩдЄ™иЃ°зЃЧињЗз®ЛйЭЮеЄЄењЂпЉМеЬ®32дљНзЪДPENTIUM4 2GиЃ°зЃЧжЬЇдЄКпЉМдЄАдЄ™ж†ЗеЗЖзЪД64MжХ∞жНЃеЭЧзЪДжЙІи°МжЧґйЧідЄНдЉЪиґЕињЗ1зІТгАВйАЪињЗеЃМжХіжАІж£АжЯ•пЉМеПѓдї•еН≥жЧґеИ§жЦ≠жХ∞жНЃеЭЧзЪДжѓПдЄАжЃµжХ∞жНЃйФЩиѓѓпЉМдњЭиѓБеРОзї≠ж≠£з°ЃзЪДжХ∞жНЃе§ДзРЖгАВ
2.8 жХ∞жНЃдЉШеМЦ
жХ∞жНЃеЭЧйХњжЧґйЧіињРи°МеРОпЉМзФ±дЇОеИ†йЩ§еТМжЫіжЦ∞жУНдљЬзЪДеҐЮеК†пЉМдЉЪеѓєжХ∞жНЃеЭЧзЪДдЄНеРМдљНзљЃеБЪеЊИе§ЪжЧ†жХИж†ЗиЃ∞гАВињЩдЇЫжЧ†жХИж†ЗиЃ∞еѓЉиЗідЇЖжХ∞жНЃзҐОзЙЗзЪДдЇІзФЯпЉМйЩ§дЇЖеН†жНЃзЭАз£БзЫШз©ЇйЧіпЉМињШдЄ•йЗНељ±еУНеИ∞з£БзЫШжХ∞жНЃж£А糥жХИзОЗгАВдЄЇдЇЖжґИйЩ§ињЩдЄ™ељ±еУНпЉМжПРйЂШжХ∞жНЃж£А糥жХИзОЗпЉМжЬЙењЕи¶БеѓєжХ∞жНЃеЭЧеБЪдЉШеМЦе§ДзРЖгАВ
з≥їзїЯжПРдЊЫдЇЖдЄАдЄ™жХ∞жНЃдЉШеМЦзЪДеСљдї§пЉМзФ®жИЈеПѓдї•йАЪињЗзїИзЂѓжИЦиАЕеЇФзФ®жО•еП£еПСиµЈжУНдљЬпЉМжИЦиАЕеЃЪдєЙеЬ®жХ∞жНЃе≠ЧеЕЄйЗМпЉМеІФжЙШзїЩTOPиКВзВєзЃ°зРЖпЉМеЃЪжЧґеРѓеК®гАВ
жХ∞жНЃдЉШеМЦеП™дљЬзФ®дЇОDATAдЄїиКВзВєзЪДдЄїжХ∞жНЃеЭЧдЄКгАВеЈ•дљЬеЃМжИРеРОпЉМдЉЪйАЪзЯ•еЕ≥иБФзЪДдїОиКВзВєпЉМжЫіжЦ∞зЫЄеРМзЉЦеПЈзЪДжХ∞жНЃеЭЧгАВеЬ®жХ∞жНЃдЉШеМЦжЬЯйЧіпЉМеЕ®йГ®жХ∞жНЃеЭЧйÚ襀йФБеЃЪпЉМжЙАдї•ињЩдЄ™жЧґеАЩдЄНиГљжЙІи°МдїїдљХжХ∞жНЃжУНдљЬгАВдљЖжШѓдЉШеМЦињЗз®ЛеЃМеЕ®еЬ®еЖЕе≠ШдЄ≠ињЫи°МпЉМиЃ°зЃЧдЄАдЄ™ж†ЗеЗЖзЪД64MжХ∞жНЃеЭЧпЉМжЫіжЦ∞жЧґйЧіе§ІзЇ¶еЬ®1зІТеЈ¶еП≥пЉМжЙАдї•дєЯиГље§ЯиЊГењЂеЃМжИРдїїеК°гАВиАГиЩСеИ∞йЬАи¶БеЫЮйБњж≠£еЄЄиЃ°зЃЧдЄЪеК°еЈ•дљЬзЪДжЧґжЃµпЉМеїЇиЃЃињЩй°єеЈ•дљЬеЬ®з≥їзїЯзЪДз©ЇйЧ≤жЧґйЧіињЫи°МпЉМжѓФе¶Ве§ЬйЧізЪДжЯРдЄ™жЧґеИїпЉМињЩдЇЫжЧґйЧізЪДзФ®жИЈиѓЈж±ВйЗПйАЪеЄЄдЉЪжШЊиСЧеЗПе∞СгАВ
2.9 жХ∞жНЃжЮДеїЇ
жХ∞жНЃдЉШеМЦжШѓеЬ®дЄНдњЃжФєжХ∞жНЃзїУжЮДзЪДеЙНжПРдЄЛпЉМеѓєDATAдЄїиКВзВєдЄЛзЪДжХ∞жНЃеЭЧињЫи°МзЪДжЫіжЦ∞еЈ•дљЬпЉМзЫЃзЪДжШѓжЄЕйЩ§еЮГеЬЊжХ∞жНЃеТМжПРйЂШж£А糥жХИзОЗгАВжХ∞жНЃжЮДеїЇеЬ®ж≠§еЯЇз°АдЄКжЫіињЫдЄАж≠•пЉМдЊЭйЭ†дЄАзІНжИЦиАЕе§ЪзІНжХ∞жНЃзїУжЮДзЪДжХ∞жНЃеЭЧпЉМжПРеПЦеЃГдїђеЕ®йГ®жИЦиАЕйГ®еИЖжХ∞жНЃдњ°жБѓпЉМзїПињЗз≠ЫйАЙгАБеИЖжЮРгАБиЃ°зЃЧпЉМ嚥жИРеМЕжЛђе≠ШеВ®ж®°еЮЛгАБжХ∞жНЃзїУжЮДгАБжХ∞жНЃеЖЕеЃєеЬ®еЖЕзЪДжЦ∞зЪДжХ∞жНЃйЫЖеРИпЉМеєґдЄФеЈ•дљЬдљНзљЃдєЯиљђеИ∞BUILDиКВзВєдЄКињЫи°МгАВ
жХ∞жНЃжЮДеїЇе±ЮдЇОETLжЬНеК°зЪДдЄАйГ®еИЖгАВеЫ†дЄЇжХ∞жНЃжЮДеїЇдЉЪжґЙеПКеИ∞дЄНеРМзЪДдЄЪеК°жЦєж°ИпЉМжЧ†ж≥ХињЫи°МзїЯдЄАе§ДзРЖпЉМжЙАдї•з≥їзїЯжПРдЊЫдЇЖдЄАе•ЧAPIгАВAPIжПРдЊЫдЇЖиІДиМГзЪДжХ∞жНЃе§ДзРЖжµБз®ЛпЉМеЕґдЄ≠еЕЈдљУзЪДдЄЪеК°пЉМзФ±дЇЖиІ£дЄЪеК°зЪДеЈ•дљЬдЇЇеСШжМЙзЕІеЃЮйЩЕйЬАж±ВзЉЦеЖЩиЃ°зЃЧжЬЇдї£з†БгАВзЉЦз†БеЃМжИРеРОпЉМеПСеЄГеИ∞BUILDиКВзВєињРи°МпЉМBUILDиКВзВєдЉЪиЗ™еК®жДЯзЯ•еєґдЄФиѓЖеИЂеЃГдїђгАВ
еРѓеК®жХ∞жНЃжЮДеїЇзЪДеЈ•дљЬзФ±зФ®жИЈйАЪињЗзїИзЂѓжИЦиАЕеЇФзФ®жО•еП£иІ¶еПСпЉМжИЦиАЕдЇ§зФ±TOPиКВзВєдї£дЄЇзЃ°зРЖжЙІи°МгАВBUILDиКВзВєеЬ®жФґеИ∞еСљдї§еРОпЉМжМЙзЕІз≥їзїЯиІДеЃЪзЪДеЈ•дљЬжµБз®Ле§ДзРЖгАВ
жХ∞жНЃжЮДеїЇжШѓе§ІиІДж®°жХ∞жНЃиЃ°зЃЧдЄ≠дЄАй°єеЊИйЗНи¶БзЪДеКЯиГљпЉМеЬ®еЊИе§ЪеЬЇеРИйГљжЬЙеЃЮйЩЕеЇФзФ®гАВдЊЛе¶ВиЃЄе§ЪжХ∞жНЃиЃ°зЃЧдЄЪеК°йГљйЬАи¶БеИЖеИЂйЗЗйЫЖеРДзІНдЄНеРМзЪДжХ∞жНЃпЉМе¶ВжЮЬеЬ®ињРи°МжЧґе§ДзРЖпЉМињЗз®ЛдЉЪзєБзРРпЉМиАЧжЧґйХњпЉМињРзЃЧжИРжЬђйЂШгАВе¶ВжЮЬжПРеЙНдЇІзФЯпЉМдЄАжђ°жАІиОЈеЊЧеЕ®йГ®жХ∞жНЃзїУжЮЬпЉМзДґеРОеЬ®ињЩдЄ™еЯЇз°АдЄКеЖНињЫи°МиЃ°зЃЧпЉМз®ЛеЇПеСШзЪДеЉАеПСеЈ•дљЬеТМжХ∞жНЃе§ДзРЖдЉЪеПШеЊЧзЃАеНХпЉМжЧґйЧідЉЪзЉ©зЯ≠пЉМињРзЃЧжИРжЬђдєЯдЉЪйЩНдљОгАВ
2.10 дЄїеЭЧеЖ≤з™Б
й¶ЦеЕИпЉМдЄїжХ∞жНЃеЭЧеЬ®дїїдљХжЧґйЧіеП™иГљжЬЙдЄАдЄ™гАВељУDATAдЄїиКВзВєеПСзФЯжХЕйЪЬжБҐе§НеРОпЉМдЉЪйЗНжЦ∞еРСHOMEиКВзВєж≥®еЖМпЉМеРМж≠•дЄКдЉ†зЪДињШжЬЙиКВзВєжЙАе±ЮзЪДжХ∞жНЃдњ°жБѓгАВHOMEиКВзВєдЉЪж£АжЯ•жѓПдЄАдЄ™жХ∞жНЃеЕГдњ°жБѓпЉМдЄОеЖЕе≠ШдЄ≠й©їзХЩзЪДжХ∞жНЃеЕГдњ°жБѓињЫи°МжѓФиЊГпЉМињЩжЧґеПѓиГљдЉЪеПСзФЯдЄ§дЄ™зЫЄеРМзЉЦеПЈдЄїжХ∞жНЃеЭЧзЪДжГЕеЖµпЉМињЩе∞±жШѓдЄїеЭЧеЖ≤з™БгАВ
иІ£еЖ≥дЄїеЭЧеЖ≤з™БзЪДеФѓдЄАеКЮж≥ХдїНзДґжШѓжЧґйЧігАВж†єжНЃдЄ§дЄ™дЄїжХ∞жНЃеЭЧжЬАеРОзЪДжЦЗдїґдњЃжФєжЧґйЧіпЉМеИ§жЦ≠еЃГдїђзЪДжХ∞жНЃжЬЙжХИжАІпЉМдї•жЧґйЧіжЬАжЦ∞зЪДйВ£дЄ™дЄїеЭЧдЄЇеЗЖгАВжЧІзЪДдЄїеЭЧе∞ЖдЉЪдїОз£БзЫШеИ†йЩ§пЉМдїОиАМиЊЊеИ∞йШ≤ж≠ҐдЄїеЭЧеЖ≤з™БзЪДзЫЃзЪДгАВ
2.11 иіЯиљљж£АжµЛ
еЬ®з≥їзїЯињРи°МињЗз®ЛдЄ≠пЉМдЄАдЄ™зО∞еЃЮзЪДжГЕеЖµжШѓпЉЪйЪПжЧґдЉЪеЫ†дЄЇйЬАж±ВеҐЮеК†жЬЙе§ІжЙєиЃ°зЃЧдїїеК°еК†еЕ•пЉМеРМжЧґдєЯдЉЪжЬЙдЄ™еИЂиКВзВєеЫ†дЄЇеРДзІНеОЯеЫ†иАМйААеЗЇињРи°МињЗз®ЛгАВеЬ®ињЩзІНж≥ҐеК®зЪДињРи°МзКґжАБйЗМпЉМдЄНеПѓиГљеЃМеЕ®жЭЬзїЭиґЕиљљзО∞и±°пЉМиГљеБЪеИ∞зЪДеП™жШѓе∞љеПѓиГљеЗПе∞СиґЕиљљеПСзФЯйҐСзОЗгАВ
дљњиЃ°зЃЧжЬЇеПСзФЯиґЕиљљзЪДжЇРе§ідЄїи¶БжЬЙдЄ§дЄ™пЉЪCPUгАБз£БзЫШгАВCPUиґЕиљљеОЯеЫ†жШѓе≠ШеЬ®е§ІйЗПжХ∞жНЃиЃ°зЃЧпЉМз£БзЫШиґЕиљљжШѓиѓїеЖЩйҐСзОЗињЗйЂШпЉМеЗПе∞СиґЕиљљзО∞и±°зЪДжЬЙжХИеКЮж≥ХжШѓйЩРеИґиЃ°зЃЧдїїеК°йЗПгАВйАЪињЗLINUXзЪДtopеСљдї§иГље§ЯиІВеѓЯеИ∞CPUеТМз£БзЫШзЪДињРи°МжГЕеЖµгАВељУиґЕиљљзО∞и±°жМБзї≠жЧґпЉМз≥їзїЯе∞ЖеРѓеК®вАЬйФБвАЭжЬЇеИґпЉМйЩРеИґиЃ°зЃЧдїїеК°ињРи°МпЉМеРМжЧґйАЪзЯ•дїїеК°еПСиµЈжЦєпЉМеЗПе∞СеѓєжЬђиКВзВєзЪДи∞ГзФ®йҐСеЇ¶гАВ
еѓєжХ∞жНЃиґЕиљљзЪДж£АжµЛдЉЪеЕЈдљУеИ∞жѓПдЄ™жХ∞жНЃеЭЧпЉМе¶ВжЮЬз≥їзїЯеПСзО∞жЯРдЄ™жХ∞жНЃеЭЧзЪДи∞ГзФ®еЬ®дЄАеЃЪжЧґжЃµеЖЕиґЕињЗйШАеАЉпЉМдЉЪйАЙжЛ©дЄіжЧґеК†иљљеИ∞еЖЕе≠ШжИЦиАЕеИЖеПСеИ∞еЕґеЃГз©ЇйЧ≤зЪДиЃ°зЃЧжЬЇдЄКжЙІи°МпЉМдї•иЊЊеИ∞йЩНиљљзЪДзЫЃзЪДгАВ