测试环境: VS2010旗舰版。Intel i3处理器(2.94Ghz),2.93G内存,32位操作系统。
一、随机产生的十个数
对以上前四个算法、三种版本有效性测试:
int main() {
int max = 10;
int i = 0;
vector<int> ivec1, ivec12, ivec2, ivec3;
srand((unsigned int)time(0));
while (i < max) {
i++;
int value = rand();
ivec1.push_back(value);
ivec12.push_back(value);
ivec2.push_back(value);
ivec3.push_back(value);
}
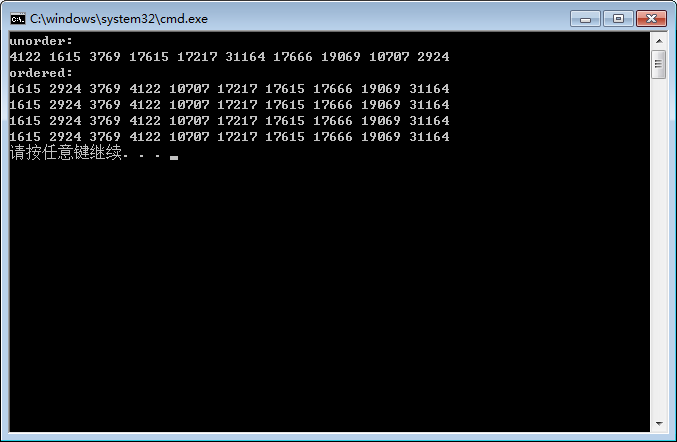
cout << "unorder: " << endl;
PrintValue(ivec1);
cout << "ordered: " << endl;
QuickSort1(ivec1, 0, ivec1.size() - 1);
PrintValue(ivec1);
QuickSort12(ivec12, 0, ivec12.size() - 1);
PrintValue(ivec12);
QuickSort2(ivec2, 0, ivec2.size() - 1);
PrintValue(ivec2);
QuickSort3(ivec3, 0, ivec3.size() - 1);
PrintValue(ivec3);
}
二、大量随机数测试
(1)某次随机产生的10,000,000(一千万)个数测试
输出各个算法用时(ms):
int main() {
int max = 10000000;
int i = 0;
vector<int> ivec1, ivec12, ivec2, ivec3, ivec4, ivec5;
srand((unsigned int)time(0));
while (i < max) {
i++;
int value = rand();
ivec1.push_back(value);
ivec12.push_back(value);
ivec2.push_back(value);
ivec3.push_back(value);
ivec4.push_back(value);
ivec5.push_back(value);
}
clock_t time1 = clock();
QuickSort1(ivec1, 0, ivec1.size() - 1);
clock_t time2 = clock();
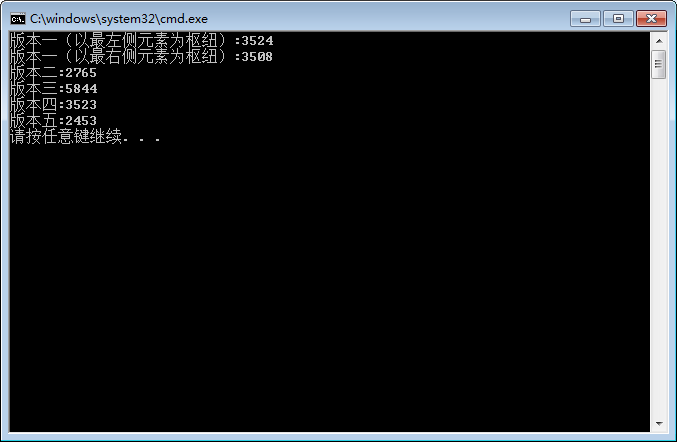
cout << "版本一(以最左侧元素为枢纽):" << time2 - time1 << endl;
QuickSort12(ivec12, 0, ivec12.size() - 1);
clock_t time3 = clock();
cout << "版本一(以最右侧元素为枢纽):" << time3 - time2 << endl;
QuickSort2(ivec2, 0, ivec2.size() - 1);
clock_t time4 = clock();
cout << "版本二:" << time4 - time3 << endl;
QuickSort3(ivec3, 0, ivec3.size() - 1);
clock_t time5 = clock();
cout << "版本三:" << time5 - time4 << endl;
QuickSort4(ivec4, 0, ivec4.size() - 1);
clock_t time6 = clock();
cout << "版本四:" << time6 - time5 << endl;
QuickSort5(ivec5, 0, ivec5.size() - 1);
clock_t time7 = clock();
cout << "版本五:" << time7 - time6 << endl;
}
(2)随机产生一百万个数,连续测试10次
如下图所示:每一行依次是某个算法10次测试所有时间,最后一列为各个算法耗时的平均值。
//vec_time用于记录所有算法的十次耗时
//每个元素表示一种算法
vector< vector<int> > vec_time(10);
//进行十次测试
for (int a = 0; a < 10; ++a) {
int max = 1000000; //每次测试的都是随机的一百万个数
int i = 0;
vector<int> ivec1, ivec1_none, ivec12, ivec2, ivec3, ivec4, ivec5;
srand((unsigned int)time(0));
while (i < max) {
i++;
int value = rand();
ivec1.push_back(value);
ivec1_none.push_back(value);
ivec12.push_back(value);
ivec2.push_back(value);
ivec3.push_back(value);
ivec4.push_back(value);
ivec5.push_back(value);
}
clock_t time1 = clock();
QuickSort1(ivec1, 0, ivec1.size() - 1);
clock_t time2 = clock();
//cout << "版本一(左侧枢纽):" << time2 - time1 << endl;
vec_time[0].push_back(time2 - time1);
clock_t time_none1 = clock();
QuickSort1NoRecursion(ivec1_none, 0, ivec1_none.size() - 1);
clock_t time_none2 = clock();
//cout << "版本一(非递归法):" << time_none2 - time_none1 << endl;
//PrintValue(ivec1_none);
vec_time[1].push_back(time_none2 - time_none1);
clock_t time31 = clock();
QuickSort12(ivec12, 0, ivec12.size() - 1);
clock_t time3 = clock();
//cout << "版本一(右侧枢纽):" << time3 - time31 << endl;
vec_time[2].push_back(time3 - time31);
clock_t time41 = clock();
QuickSort2(ivec2, 0, ivec2.size() - 1);
clock_t time4 = clock();
//cout << "版本二(直接交换):" << time4 - time41 << endl;
vec_time[3].push_back(time4 - time41);
clock_t time51 = clock();
QuickSort3(ivec3, 0, ivec3.size() - 1);
clock_t time5 = clock();
//cout << "版本三(单向划分):" << time5 - time51 << endl;
vec_time[4].push_back(time5 - time51);
clock_t time61 = clock();
QuickSort4(ivec4, 0, ivec4.size() - 1);
clock_t time6 = clock();
//cout << "版本四(随机枢纽):" << time6 - time61 << endl;
vec_time[5].push_back(time6 - time61);
clock_t time71 = clock();
QuickSort5(ivec5, 0, ivec5.size() - 1);
clock_t time7 = clock();
//cout << "版本五(三数取中):" << time7 - time71 << endl;
vec_time[6].push_back(time7 - time71);
}
//下列输出的各行依次是下列各个算法的函数
cout << "版本一(左侧枢纽) " << "版本一(非递归法) " << "版本一(右侧枢纽) " << endl;
cout << "版本二(直接交换) " << "版本三(单向划分) " << "版本四(随机枢纽) " << "版本五(三数取中)" << endl;
for (int j = 0; j < 7; ++j) {
int sum = 0;
vector<int>::iterator iter = vec_time[j].begin();
while (iter != vec_time[j].end()) {
cout << *iter << " ";
sum += *iter;
++iter;
}
cout << (double)sum / 10;
cout << endl;
}
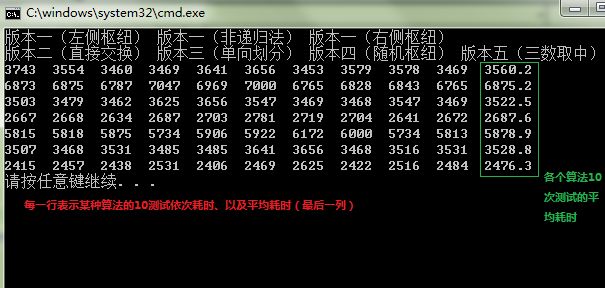
分析:
从上图可以得出如下结论:
(1)版本一以左侧元素或右侧元素作为枢纽时,两种方式的递归算法性能相当;
但是使用STL的栈适配器的非递归算法性能很差,几乎是递归算法时间的二倍。这是所有算法中性能最差的算法;这原因可能是STL实现的栈比较耗时。一百万随机数排序平均时间为6.8秒。
(2)版本二:Hore算法(每次直接交换)性能略微优于版本一(产生空穴)。
(3)版本三:单向划分(两个指针都从待排序数组一侧开始移动)性能较差,仅次于上述的非递归算法。
(4)版本四:随机枢纽算法性能和版本一的非递归算法性能类似。
(5)版本五:三数取中算法是所有算法中性能最好的。一百万随机数平均时间只有2.5秒。
(3)随机产生一千万个数,连续测试10次
采用和上一节同样的方式测试,只是测试数据量提高了一个数量级:由一百万个数提升到一千万个。
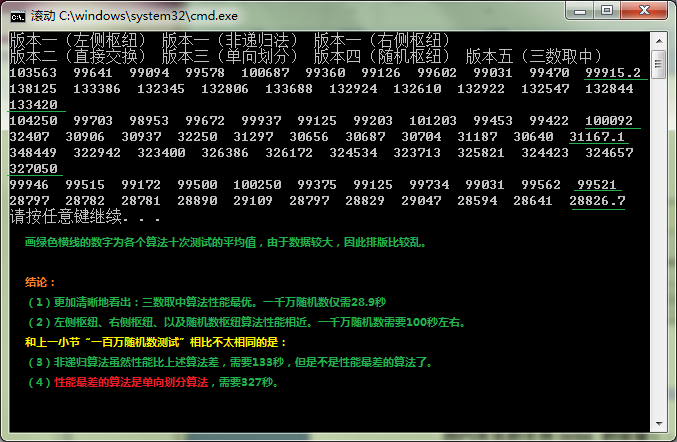
分析:
(1)对比一百万数据测试和一千万数据测试可以看出,同样是快速排序,其性能差距也会很大:
一百万随机数时最慢算法(非递归算法)时间几乎是最快的算法(三数取中)的时间的2.7倍;
一千万随机数测试时,最慢算法(单向划分算法)的时间是最快的算法(三数取中)时间的11倍还多。
(2)一百万个数据时,Hore算法(每次直接交换)性能略微优于版本一(产生空穴);在一千万个数据时,Hore算法(每次直接交换)性能远优于版本一(产生空穴),后者时间是前者的3倍还多。
(2)一百万数据测试的最差算法是非递归,一千万算法测试最差算法是单向划分。其实一百万数据测试时,单向划分的表现就不佳。
三、已经有序数组排序测试
使用有序的数组测试排序性能,已经知道,在数组有序的情况下,快速排序的性能退化为O(n ^ 2)。因此不能如随机数据测试那样,测试百万、千万级别的数据。
事实上,当已排序数组元素超过5000个(大概数值)时,我的程序就崩溃了(在初始数组有序(或逆序)情况下,栈深度为O(n),栈溢出,所以程序崩溃。参考基础排序算法总结)。
测试程序和随机数的类似,只是初始化是将数组元素初始化为有序的,而不是随机的:
//有序数据测试的代码片段
//将数组初始化为4000个元素的有序数组
for (int a = 0; a < 10; ++a) {
int max = 100; //每次测试的都是随机的一百万个数
int i = 0;
vector<int> ivec1, ivec1_none, ivec12, ivec2, ivec3, ivec4, ivec5;
for (i = 0; i < 4000; i++) {
int value = i;
ivec1.push_back(value);
ivec1_none.push_back(value);
ivec12.push_back(value);
ivec2.push_back(value);
ivec3.push_back(value);
ivec4.push_back(value);
ivec5.push_back(value);
}
(1) 2000个数
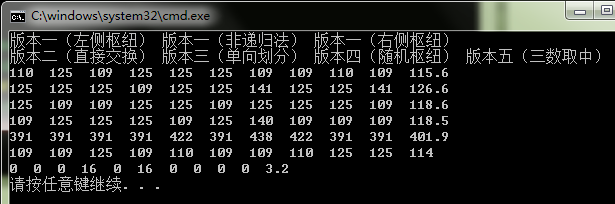
(2)3000个数
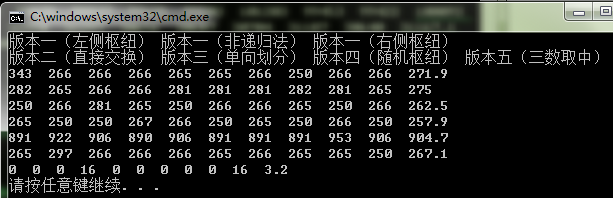
(3) 4000个数
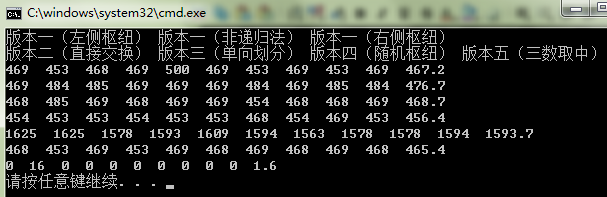
分析:
虽然测试数据比较少,但是仍可以看出:单向划分算法性能较差。三数取中算法性能占绝对优势。
结论:
(1)采用待排序序列第一个或最后一个元素作为枢纽的算法性能:在平均情况下不错,可以从随机数的测试中看出来,但是当待排序的数组序列基本有序或逆序时,请算法性能退化为O(n ^ 2)。其中非递归版本算法性能没有递归版本好,可能是STL栈实现性能不够好。
(2)三数取中枢纽法的性能是最优解法的,它不仅可以避免初始序列基本有序或逆序的最坏情况,相反,在初始序列基本有序或逆序时,该算法达到的是最好的性能:每次枢纽将待排序序列划分为等长的两个子序列,此时栈空间最小,仅为longn,所需时间也最少。
(3)单向划分的性能不佳,采用待排序序列第一个或最后一个元素作为枢纽的非递归版本性能也不佳。