

ељТеєґжОТеЇПйЗЗзФ®еИЖж≤їзЪДжЦєж≥ХгАВ
еѓєељТеєґжОТеЇПжЭ•иѓіпЉЪ
е¶ВжЮЬеѓєMergeзЪДжѓПдЄ™йАТељТи∞ГзФ®йГље£∞жШОдЄАдЄ™дЄіжЧґжХ∞зїДпЉМйВ£дєИдїїдЄАжЧґеИїеПѓиГљдЉЪжЬЙlogNдЄ™дЄіжЧґжХ∞зїДе§ДдЇОжіїеК®жЬЯ,ињЩеѓєе∞ПеЖЕе≠ШжЬЇеЩ®жШѓиЗіеСљзЪДгАВеП¶дЄАжЦєйЭҐпЉМе¶ВжЮЬMergeеК®жАБеИЖйЕНеєґйЗКжФЊжЬАе∞ПйЗПдЄіжЧґз©ЇйЧіпЉМйВ£дєИзФ±mallocеН†зФ®зЪДжЧґйЧідЉЪеЊИе§ЪгАВзФ±дЇОMergeдљНдЇОMSortзЪДжЬАеРОдЄАи°МпЉМеПѓдї•еЬ®MergeSortдЄ≠еїЇзЂЛиѓ•дЄіжЧґжХ∞зїДгАВеЫ†ж≠§еЬ®дїїдЄАжЧґеИїеП™йЬАи¶БдЄАдЄ™дЄіжЧґжХ∞зїДжіїеК®пЉМиАМдЄФеПѓдї•дљњзФ®иѓ•дЄіжЧґжХ∞зїДзЪДдїїжДПйГ®еИЖпЉЫжИСдїђе∞ЖдљњзФ®еТМиЊУеЕ•жХ∞зїДarrayзЫЄеРМзЪДйГ®еИЖгАВињЩж†ЈзЪДиѓЭпЉМиѓ•зЃЧж≥ХзЪДз©ЇйЧіеН†зФ®дЄЇNпЉМNжШѓеЊЕжОТеЇПзЪДжХ∞зїДеЕГзі†дЄ™жХ∞гАВ
/*
tmp_array[]пЉЪиЊЕеК©жХ∞зїДгАВ
left_posпЉЪжХ∞зїДеЈ¶еНКйГ®еИЖзЪДжЄЄж†З
left_endпЉЪеЈ¶иЊєжХ∞зїДзЪДеП≥зХМйЩР
*/
void Merge(int array[], int tmp_array[], int left_pos, int right_pos, int right_end) {
int i, left_end, num_elements, tmp_pos;
left_end = right_pos - 1;
tmp_pos = left_pos;
num_elements = right_end - left_pos + 1;
while (left_pos <= left_end && right_pos <= right_end)
if (array[left_pos] <= array[right_pos])
tmp_array[tmp_pos++] = array[left_pos++];
else
tmp_array[tmp_pos++] = array[right_pos++];
while (left_pos <= left_end)
tmp_array[tmp_pos++] = array[left_pos++];
while (right_pos <= right_end)
tmp_array[tmp_pos++] = array[right_pos++];
for (i = 0; i < num_elements; i++, right_end--)
array[right_end] = tmp_array[right_end];
}
void MSort(int array[], int tmp_array[], int left, int right) {
int center;
if (left < right) {
center = (left + right) / 2;
MSort(array, tmp_array, left, center);
MSort(array, tmp_array, center + 1, right);
Merge(array, tmp_array, left, center + 1, right);
}
}
void MergeSort(int array[], int n) {
int *tmp_array;
//дЄКйЭҐжЦЗе≠ЧйГ®еИЖзїЩеЗЇдЇЖдЄЇдїАдєИеЬ®MergeSortдЄ≠еїЇзЂЛдЄіжЧґжХ∞зїДtmp_array
 tmp_array = (int *)malloc(n * sizeof(int));
if (tmp_array != NULL) {
MSort(array, tmp_array, 0, n - 1);
free(tmp_array);
}
else
cout << "malloc failed" << endl;
}
иЩљзДґељТеєґжОТеЇПзЪДжЧґйЧідЄЇO(NlogN)пЉМдљЖжШѓеЃГеЊИйЪЊзФ®дЇОдЄїе≠ШжОТеЇПпЉМеЫ†дЄЇеРИеєґдЄ§дЄ™жОТеЇПзЪДи°®йЬАи¶БзЇњжАІйЩДеК†еЖЕе≠ШпЉМжХідЄ™зЃЧж≥ХдЄ≠ињШи¶БиК±иієе∞ЖжХ∞жНЃжЛЈиіЭеИ∞дЄіжЧґжХ∞зїДеЖНжЛЈиіЭеЫЮжЭ•ињЩж†ЈзЪДйЩДеК†еЈ•дљЬпЉМињЩдЄ•йЗНељ±еУНжОТеЇПзЪДйАЯеЇ¶гАВ
еѓєдЇОйЗНи¶БзЪДеЖЕйГ®жОТеЇПеЇФзФ®иАМи®АпЉМеЊАеЊАйАЙжЛ©ењЂйАЯжОТеЇПгАВеРИеєґзЪДжЦєж≥ХжШѓе§Іе§ЪжХ∞е§ЦйГ®жОТеЇПзЃЧж≥ХзЪДеЯЇзЯ≥гАВ
------------------------------------------------------еИЖеЙ≤------------------------------------------------------------------
з©ЇйЧіе§НжЭВеЇ¶дЄЇo(1)зЪДељТеєґжОТеЇПдї£з†БпЉЪgithubпЉИзВєеЗїжЙУеЉАйУЊжО•пЉЙ
жСШељХе¶ВдЄЛпЉЪ
//з©ЇйЧіе§НжЭВеЇ¶дЄЇO(1)зЪДељТеєґжОТеЇП
#include <iostream>
using namespace std;
void reverse_array(int a[], int n) {
int i = 0;
int j = n - 1;
while (i < j) {
swap(a[i], a[j]);
++i;
--j;
}
}
void exchange(int a[], int length, int length_left) {
reverse_array(a, length_left);
reverse_array(a + length_left, length - length_left);
reverse_array(a, length);
}
void Merge(int a[], int begin, int mid, int end) {
while (begin < mid && mid <= end) {
int step = 0;
while (begin < mid && a[begin] <= a[mid])
++begin;
while (mid <= end && a[mid] <= a[begin]) {
++mid;
++step;
}
exchange(a + begin, mid - begin, mid - begin - step);
}
}
void MergeCore(int a[], int left, int right) {
if (left < right) {
int mid = (left + right) / 2;
MergeCore(a, left, mid);
MergeCore(a, mid + 1, right);
Merge(a, left, mid + 1, right);
}
}
void MergeSort(int a[], int length) {
if (a == NULL || length < 1)
return;
MergeCore(a, 0, length - 1);
}
int main() {
int a[] = {1,0,2,9,3,8,4,7,6,5,11,99,22,88,11};
int length = sizeof(a) / sizeof(int);
MergeSort(a, length);
for (int i = 0; i < length; i++)
cout << a[i] << " ";
cout << endl;
return 0;
}
дЄЛйЭҐзЪДжЦЗзЂ†зїЩеЗЇдЇЖеЬ®з©ЇйЧіе§НжЭВеЇ¶O(1)зЪДжЭ°дїґдЄЛеЃЮзО∞ељТеєґжОТеЇП
еОЯжЦЗе¶ВдЄЛпЉЪ
зђђдЄАпЉЪеѓєдЄАдЄ™L1,L2,зЪДе≠РеЇПеИЧпЉМеИЖеИЂйХњеЇ¶дЄЇпЉМm,n.еПѓдї•зФ®min(m,n)зЪДз©ЇйЧіеНПеК©ињЫи°МељТеєґжОТ
еЇПпЉМдЄФдїЕеѓєиѓ•йҐЭе§Цз©ЇйЧізЪДеАЉеЊЧй°ЇеЇПжЬЙељ±еУНгАВиѓ¶зїЖеПВиІБsara basseзЪДйВ£жЬђзЃЧж≥Хдє¶.
зђђдЇМпЉЪеѓєдЇОдЄАдЄ™еЈ≤зїПжОТеЇПзЪДL1,L2,жАїйХњеЇ¶еБЗеЃЪдЄЇu,дЄЇдЇЖжЦєдЊњеИЖжЮР,еБЗеЃЪL1зЪДйХњеЇ¶=L2зЪДйХњеЇ¶=u/2,еИЗеИЖжИРsqrt(u)зЪДдЄ™
еЭЧпЉМжѓПдЄ™ењЂжЬЙsqrt(u)дЄ™жХ∞пЉМзДґеРОеѓєL1,зЪДжЬАеРОдЄАеЭЧеТМL2зЪДжЬАеРОдЄАеЭЧељТеєґпЉМL2зЪДжЬАеРОдЄА
еЭЧе≠ШжФЊеЕ®йГ®жХ∞жНЃзЪДжЬАе§ІжХ∞жНЃпЉМеРМжЧґдєЯжШѓеИ©зФ®L2зЪДињЩдЄ™жЬАеРОдЄАеЭЧдљЬдЄЇдЄЛйЭҐељТеєґзЪДйҐЭе§Цз©ЇйЧігАВ
зђђдЄЙпЉЪеѓєеЙ©дљЩзЪДеЭЧ(йЩ§L2жЬАеРОдЄАеЭЧ,йВ£еЭЧе≠ШжФЊжЬАе§ІеЕГзі†зЪДйВ£еЭЧ),жМЙзЕІеЭЧзЪДжЬАе∞ПеЕГзі†жОТеЇПпЉМдєЛеРОдЊЭжђ°ељТеєґзЫЄйВїеЭЧгАВ
зђђеЫЫпЉЪеѓєжЬАеРОдЄАеЭЧињЫи°МжОТеЇПпЉМеЫ†дЄЇдїЦдљЬдЄЇйҐЭе§Цз©ЇйЧіпЉМеПВдЄОдЇЖдЄ§дЄ§зЫЄйВїзЪДеЭЧжОТеЇП,иЗ™еЈ±зЪДй°ЇеЇПдЄНиГљдњЭиѓБ,жЙАдї•жЬАеРОињШи¶БжОТеЇПдЄАжђ°гАВ
ињЩзІНжЦєж≥ХзЪДж≠£з°ЃжАІеПѓдї•ињЩж†ЈжЭ•зЃАеНХиІ£йЗК
зФ±дЇОжЬАеРОзЪДеИЖеЭЧйГљжШѓдїОL1жИЦиАЕL2дЄ≠еИЗдЄЛжЭ•зЪДгАВ
йВ£дєИзђђiеЭЧпЉМзђђi+1еЭЧеТМзђђi+2еЭЧпЉИе¶ВжЮЬжМЙзЕІжЬАе∞ПеЕГзі†жОТеЇПзЪДиѓЭпЉЙ
дЄН嶮еБЗеЃЪзђђiеЭЧжЭ•иЗ™L1пЉМзђђi+1еЭЧжЭ•иЗ™L2гАВпЉИiпЉМi+1пЉМi+2пЉМжШѓеИЗдЄЛжЭ•еРОзЪДзЉЦеПЈпЉМдЊЛе¶ВдЊЛе≠РдЄ≠зђђ1еЭЧжШѓ1 4 6 15жШѓL1зЪДзђђдЄАеЭЧпЉМзђђ2еЭЧ2 3 4 16жШѓL2зЪДзђђ1еЭЧпЉЙ
йВ£дєИi+2еЭЧеПѓиГљжЭ•иЗ™еУ™йЗМеСҐпЉЯи¶БдєИжШѓеОЯL1еЭЧеЬ®зђђiеЭЧеРОйЭҐпЉМи¶БдєИжШѓеОЯL2еЭЧеЬ®i+1еЭЧеРОйЭҐзЪДеЭЧгАВдєЯе∞±жШѓзђђi+1еЭЧиЗ≥е∞СжѓФNдЄ™жХ∞и¶Бе§ІпЉИNдЄЇеЭЧеЖЕжХ∞зЫЃпЉЙпЉМжНҐи®АдєЛiеТМi+1еЭЧељТеєґеРОзЪДжЬАе∞ПеЭЧi"еЭЧеЭЗжѓФi+1еЭЧе∞ПпЉМињЩдЄАзВєжШѓжЬђзЃЧж≥ХзЪДйЪЊзВєпЉМжГ≥жШОзЩљеРОпЉМе∞±дЄНйЪЊзРЖиІ£дЇЖгАВ
еЫ†ж≠§iеТМi+1ињЩдЄ§еЭЧељТеєґеРОзЪДiвАШеЭЧзЪДжЬАе§ІеЕГзі†пЉМдЄАеЃЪжѓФi+1еЭЧзЪДжЬАе∞ПеЕГзі†и¶Бе∞ПпЉМеЫ†ж≠§ж≠£з°ЃжАІеПѓдї•дњЭиѓБгАВ
зФїдЄ™еЫЊжЭ•дЄЊдЊЛпЉЪ
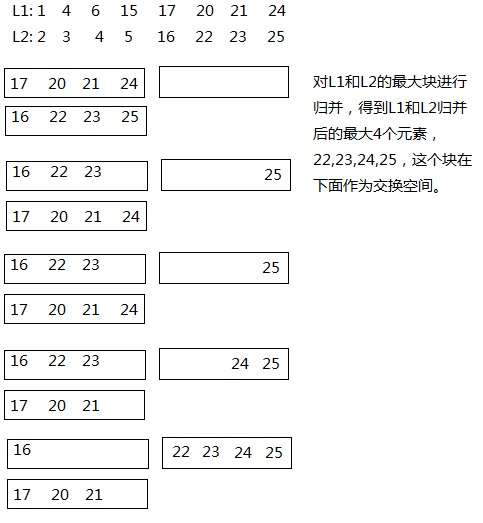
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†еЫЊ1 йАЪињЗеѓєL1еТМL2зЪДжЬАе§ІеЭЧињЫи°МељТеєґпЉМзФ®дЄАдЄ™4дЄ™еЕГзі†зЪДдЇ§жНҐз©ЇйЧіпЉМеЊЧеИ∞L1&L2зЪДжЬАе§ІеЭЧ22 23 24 25

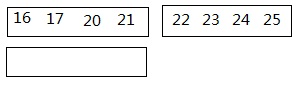
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† еЫЊ2 е∞ЖељТеєґй°ЇеЇПжМЙзЕІеЭЧжЬАе∞ПеЕГзі†зЪДй°ЇеЇПињЫи°МељТеєґпЉМеєґеИ©зФ®дЇ§жНҐз©ЇйЧі
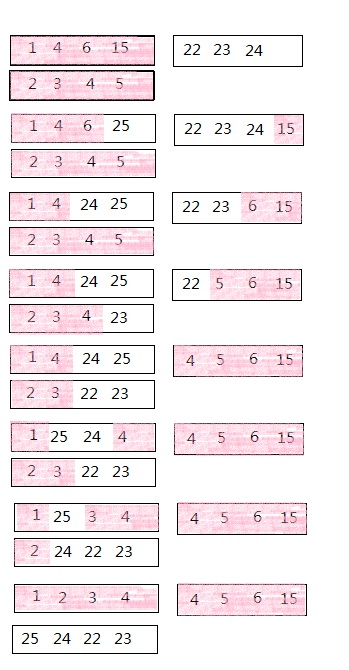
еЫЊ3 еИ©зФ®дЇ§жНҐз©ЇйЧіељТеєґзЪДињЗз®ЛпЉМж≥®жДПељТеєґеРОдЇ§жНҐз©ЇйЧізЪДжХ∞дЊЭзДґжШѓ22 23 24 25пЉМдљЖй°ЇеЇПеЈ≤зїПеПШдЇЖпЉМеЫ†ж≠§еЬ®ељТеєґеИ∞жЬАеРОињШйЬАи¶БеЖНжОТеЇПдЄАжђ°
4 5 6 15 еТМ¬†16 17 20¬†21зЪДељТеєґдЄНеЖНеЫЊз§ЇгАВ